
This tutorial shows you how to scrape the seller information and prices from Amazon’s Offer Listing page.
The price that you usually see for a product on Amazon is the buy box price. But how is it determined? Few of the biggest factors include fulfillment method, price, and seller rating. Usually, the sellers who use FBA ( Fulfilled by Amazon ) for their products “win” their way to the buy box. If there are multiple sellers who use FBA, the buy box pricing is usually shared or rotated.
Amazon has been seeing a dramatic increase in the number of third-party sellers who partner with them to make up the Amazon Marketplace. Ebay is at number two now and has only 52% merchants as compared to Amazon.
Why scrape prices from Offer Listing Page?
- Understand your share standings and feasibility of approaching the buying box
- To effectively monitor competition, gain insight about seller prices and product movement.
- Analyze distribution channel, track how your products are being sold and detect any harm to your brand
- Learn more about customer behavior so as to align products and pricing towards maximum profit
What data are we extracting?
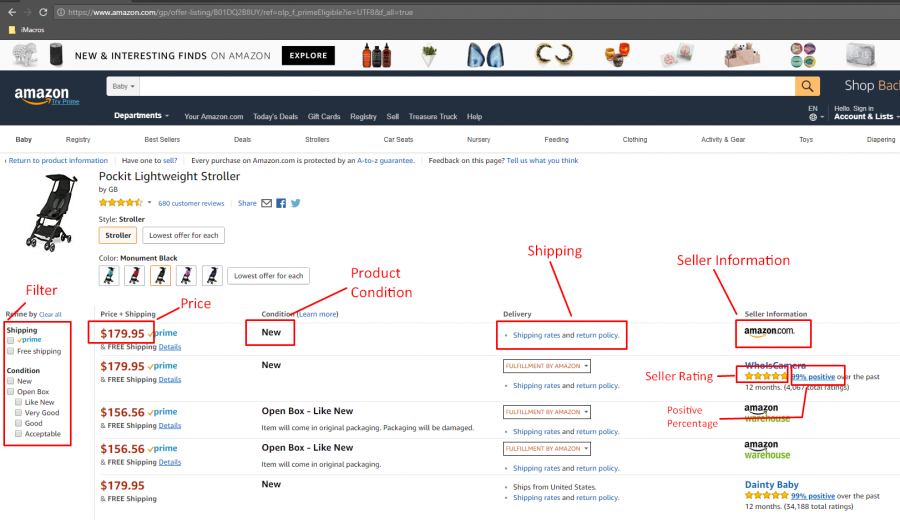
Here is a list of the product details are going to extract:
- Seller Name
- Price
- Product Conditions
- Delivery Options
- Product Shipping
- Seller Rating
- Seller’s Positive Percentage
Below is an annotated screenshot of some of the data fields we will be extracting:

Building the Scraper
You need a computer with Python 3 and PIP installed in it. The code will not run on Python 2.7.
Most UNIX operating systems like Linux and Mac OS comes with Python pre-installed. But, not all the Linux Operating Systems ship with Python 3 by default.
Let’s check your python version. Open a terminal (in Linux and Mac OS) or Command Prompt (on Windows) and type
python -V
and press enter. If the output looks something like Python 3.x.x, you have Python 3 installed. If it says Python 2.x.x you have Python 2. If it prints an error, you don’t probably have python installed. If you don’t have Python 3, install it first.
Install Python 3 and Pip
Here is a guide to install Python 3 in Linux – http://docs.python-guide.org/en/latest/starting/install3/linux/
Mac Users can follow this guide – http://docs.python-guide.org/en/latest/starting/install3/osx/
Windows Users – https://www.scrapehero.com/how-to-install-python3-in-windows-10/
Install Packages
- Python Requests, to make requests and download the HTML content of the pages (http://docs.python-requests.org/en/master/user/install/).
- Python LXML, for parsing the HTML Tree Structure using Xpaths (Learn how to install that here – http://lxml.de/installation.html)
- UnicodeCSV for handling Unicode characters in the output file. Install it using pip install unicodecsv.
- IPython, to check our Xpaths. You can install it using pip install ipython
Constructing the URL
- Identify the product ASIN. In this product – Pockit Lightweight Stroller (https://www.amazon.com/GB-616230013-Pockit-Lightweight-Stroller/dp/B01DQ2B8UY/ref=olp_product_details?_encoding=UTF8&me=), the ASIN is B01DQ2B8UY
- Construct the URL to get the information of other sellers. Open your browser again and go to the Offer Listing page of a product on Amazon.com. The URL of the Offer Listings of a product looks like this: https://www.amazon.com/gp/offer-listing/B01DQ2B8UY/
To find the offer listings of a product you just need to replace the ASIN at the end of the link. This is the URL when you don’t apply any filters. Now, Click on the checkbox for prime eligibility.
The URL changes to this:
https://www.amazon.com/gp/offer-listing/B01DQ2B8UY/ref=olp_f_primeEligible?ie=UTF8&f_all=true&f_primeEligible=true
For constructing the URL based on a Filter: To get the list of products that only have prime eligibility, keep the parameter as https://www.amazon.com/gp/offer-listing/B01DQ2B8UY/f_primeEligible=true Initially, there were ten products for this product but under the Prime Eligibility filter, there is only four.Note
rel=f_primeEligible=true:
Next step is building a scraper that extracts the data from each offer listing – Price, Condition, Delivery, and Seller information according to each filter applied.
Applying Filters:
Each argument is passed through a command line and is obtained and stored. We need arguments for ASIN, product condition, and shipping. The GIF below shows how to get the URL based on the filter applied:
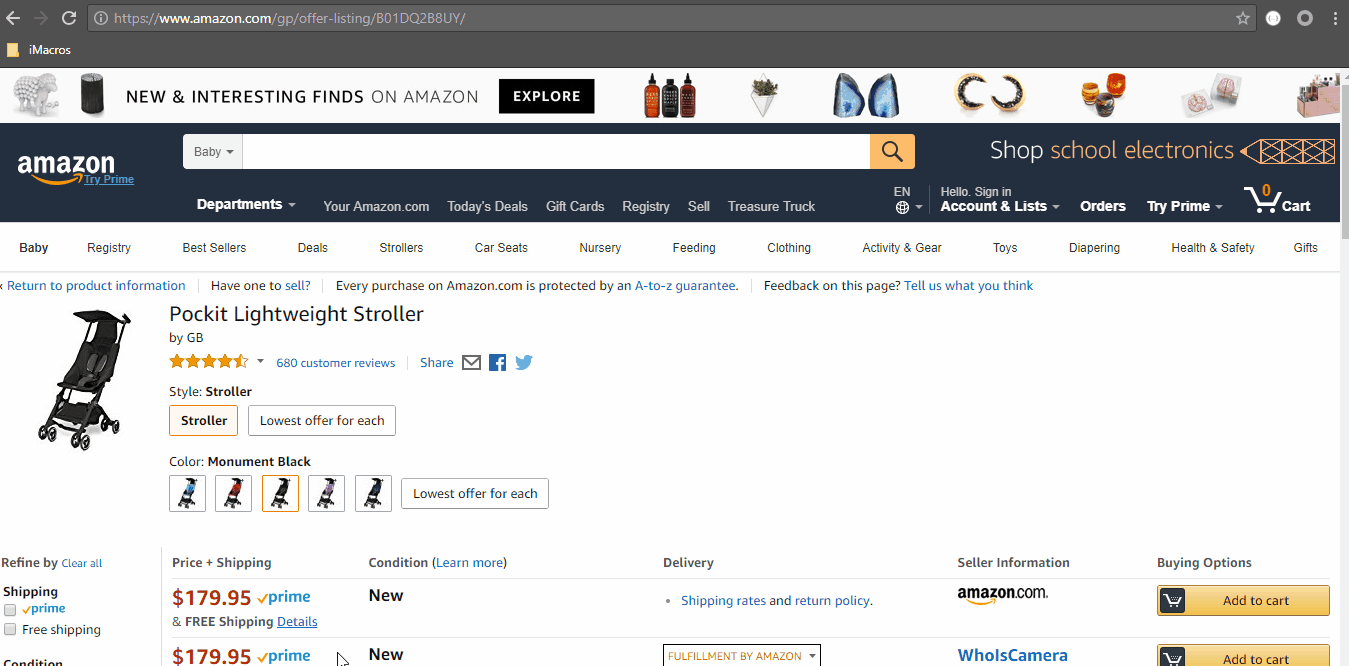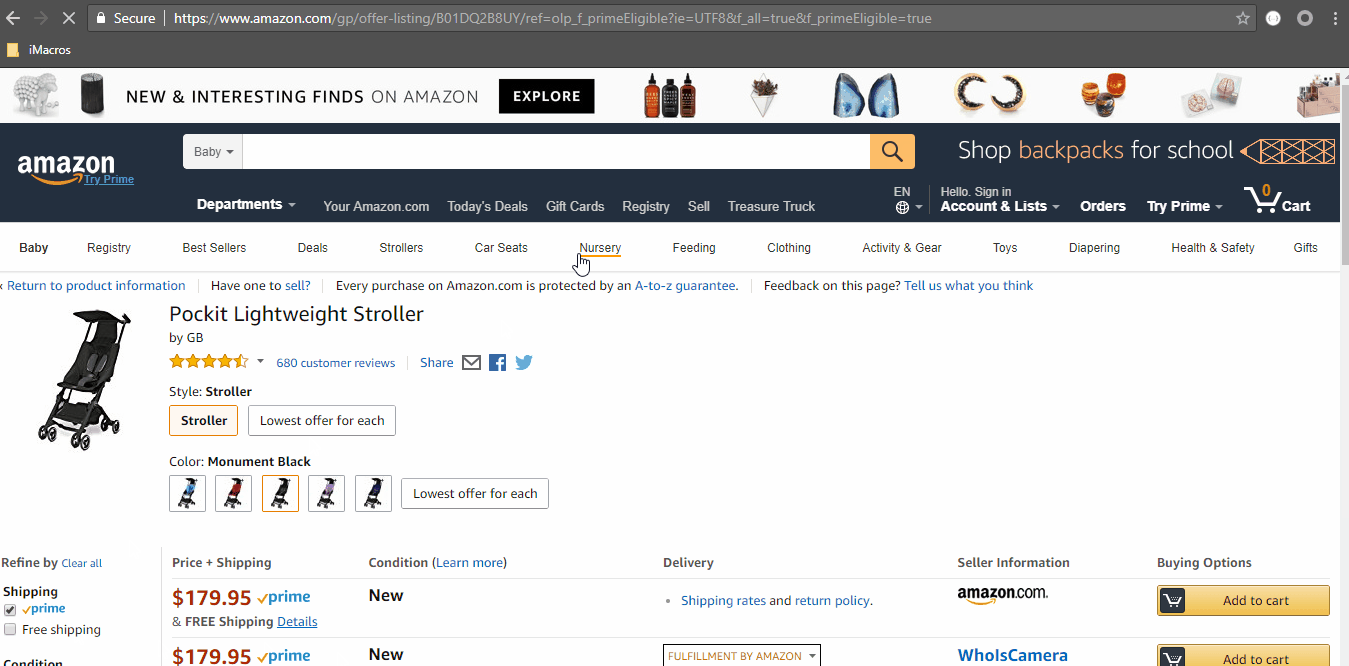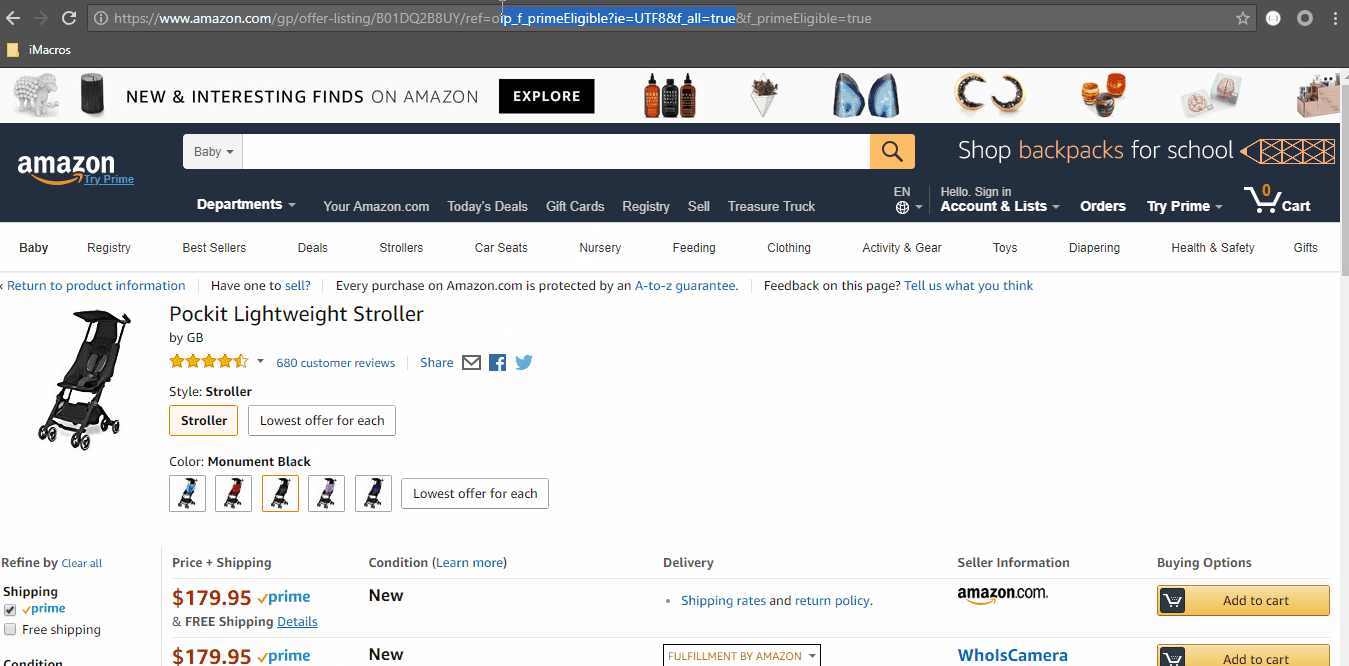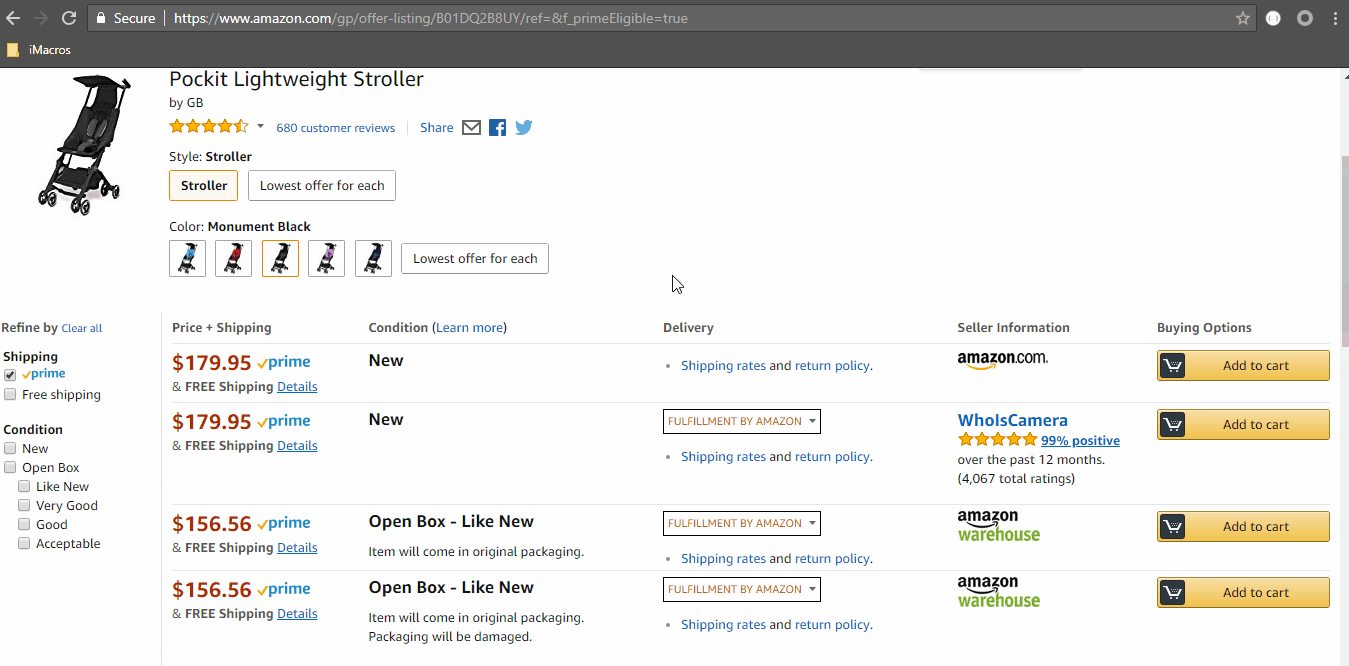
For each filter applied, we have to create a URL. We are going to create a filter to URL mapping.
condition_dict = {'new':'&f_new=true',
'used': '&f_used=true',
'all': '&condition=all',
'like_new':'&f_usedLikeNew=true',
'good':'&f_usedGood=true',
'verygood':'&f_usedVeryGood=true',
'acceptable':'&f_usedAcceptable=true'
}
shipping_dict = {'prime': '&f_primeEligible=true',
'all':'&shipping=all'
}
url = 'https://www.amazon.com/gp/offer-listing/'+asin+'/ref='+condition_dict.get(condition)+shipping_dict.get(shipping)
data = parse_offer_details(url)
parseDetails()
The URL constructed will contain the ASIN, product condition and shipping which will look like this:
https://www.amazon.com/gp/offer-listing/B01DQ2B8UY/ref=&f_new=true&f_primeEligible=true
Finding the XPath
XPaths are used to tell the script where each field we need is present in the HTML. An XPath tells you the location of an element, just like a catalog card does for books. We’ll find XPaths for each of the fields we need and put that into our scraper. After we extract the information, we’ll save it into a CSV file.
Now let’s check our XPaths using IPython:
In [1]: import requests
ln [2]: url="https://www.amazon.com/gp/offer-listing/B00BD741WM"
ln [3]: from lxml import html
In [4]: response = requests.get("https://www.amazon.com/gp/offer-listing/B01DQ2B8UY/")
In [5]: response
Out[5]: Response [200];
The request has succeeded.
In [6]: parser = html.fromstring(response.text)
In [7]: parser
Out[7]: <Element html at 0x1a48a2fd138>
Let’s get the XPath of each listing:
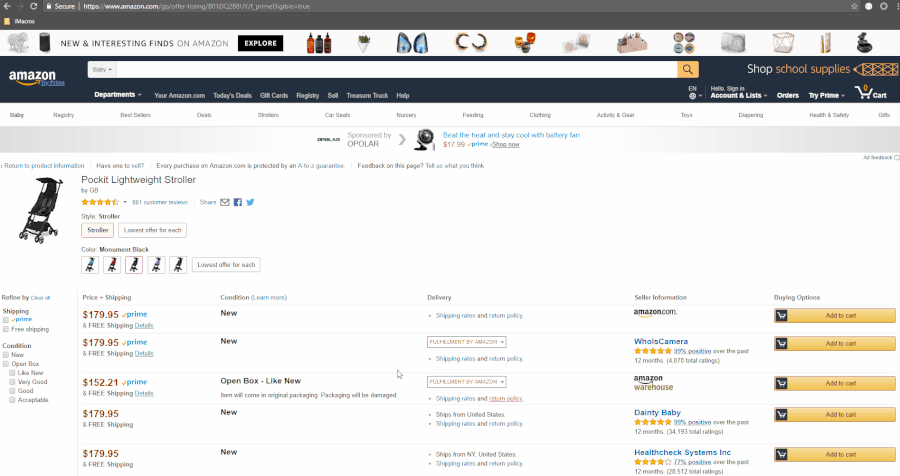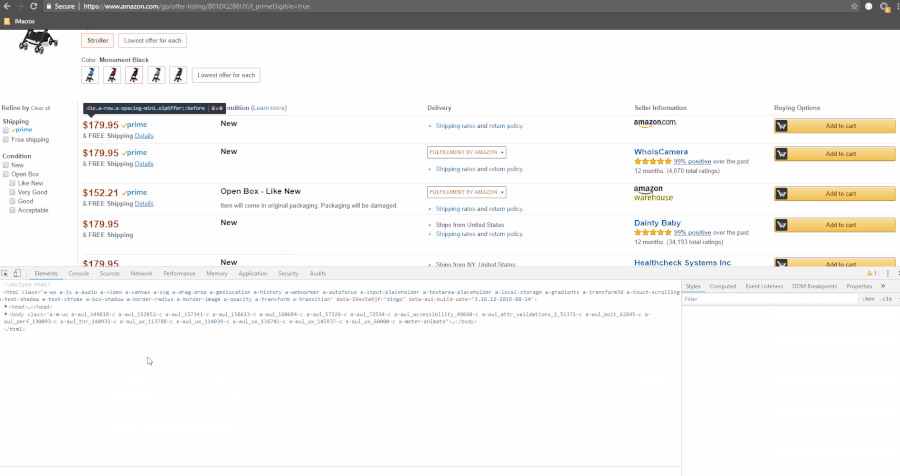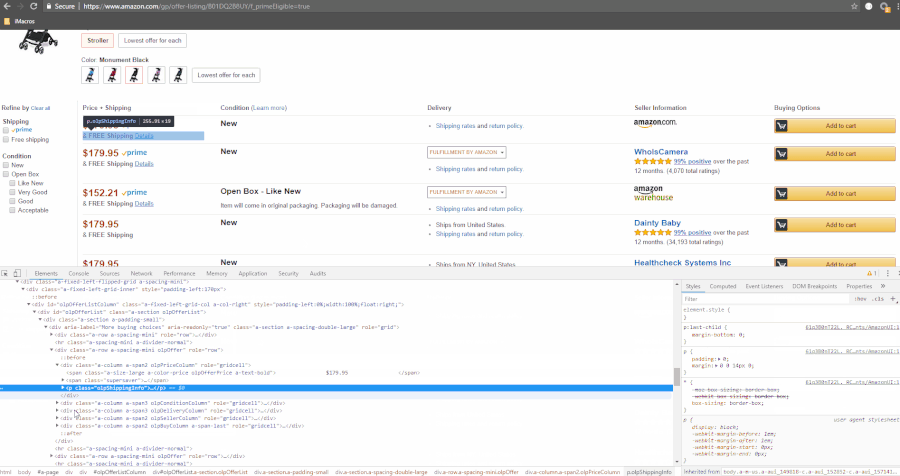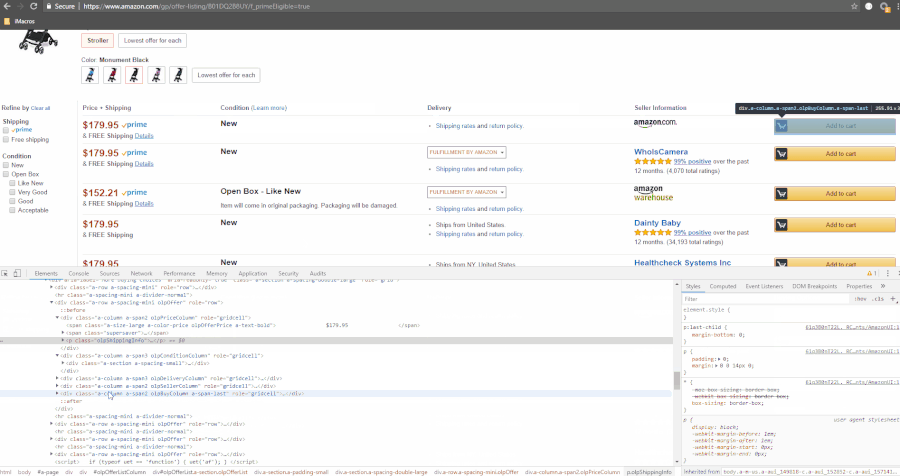
The GIF shows where we’ll find the data present in the HTML.
In [8]: parser.xpath("//div[contains(@class, 'a-row a-spacing-mini olpOffer')]")
Out[8]:
[<Element div at 0x7fea59c10c00>,
<Element div at 0x7fea59bea470>,
<Element div at 0x7fea59bea4c8>,
<Element div at 0x7fea59bea6d8>,
<Element div at 0x7fea59bea730>,
<Element div at 0x7fea59bea788>,
<Element div at 0x7fea59bea7e0>,
<Element div at 0x7fea59bea838>,
<Element div at 0x7fea59bea890>,
<Element div at 0x7fea59bea8e8>]
So now we know there are 10 seller listings for this product. Let’s check the price for the first listing:
In [9] listing[0].xpath(".//span[contains(@class, 'olpOfferPrice')]//text()")
Out [9] ['$152.21']
Getting the Required Data:
Now we can check for a couple of data fields that we need in our scraper to see if the data we need is correct:
Prime Eligibility:
In [12]: listing[0].xpath(".//span[contains(@class, 'a-color-secondary')]//text()")
Out[12]: ['\n\n\n\n\n & ',
'FREE Shipping',
' ',
'Details',
'\n\n ']
Delivery:
In [13]: listing[0].xpath(".//div[contains(@class, 'olpDeliveryColumn')]//text()")
Out[13]: ['\n \n\n\n\n\n\n\n\n\n\n\n\n\n ', '\n \n\n\n\n\n \n\n\n \n', '\n\n\n\n\n\n\n\n ', '\n ', 'Shipping rates', '\n and ', 'return policy', '.\n ', '\n', '\n\n\n\n\n \n\n\n
Seller Name:
In [14]: listing[0].xpath(".//h3[contains(@class, 'olpSellerName')]//img//@alt")
Out[14]: ['Amazon.com']
Iterating the list to get all the seller data:
for listing in listings: XPATH_PRODUCT_PRICE = ".//span[contains(@class, 'olpOfferPrice')]//text()" XPATH_PRODUCT_PRIME = ".//i/@aria-label" XPATH_PRODUCT_SHIPPING = ".//p[contains(@class, 'olpShippingInfo')]//text()" XPATH_PRODUCT_CONDITION = ".//span[contains(@class, 'olpCondition')]//text()" XPATH_PRODUCT_DELIVERY = ".//div[contains(@class, 'olpDeliveryColumn')]//text()" XPATH_PRODUCT_SELLER1 = ".//h3[contains(@class, 'olpSellerName')]//a/text()" XPATH_PRODUCT_SELLER2 = ".//h3[contains(@class, 'olpSellerName')]//img//@alt" XPATH_PRODUCT_SELLER_RATTING = ".//div[contains(@class, 'olpSellerColumn')]//span[contains(@class, 'a-icon-alt')]//text()" XPATH_PRODUCT_SELLER_PERCENTAGE = ".//div[contains(@class, 'olpSellerColumn')]//b/text()" XPATH_PRODUCT_SELLER_URL = ".//h3[contains(@class, 'olpSellerName')]//a/@href" product_price = listing.xpath(XPATH_PRODUCT_PRICE) product_price = product_price[0].strip() product_prime = listing.xpath(XPATH_PRODUCT_PRIME) product_condition = listing.xpath(XPATH_PRODUCT_CONDITION) product_shipping = listing.xpath(XPATH_PRODUCT_SHIPPING) delivery = listing.xpath(XPATH_PRODUCT_DELIVERY) seller1 = listing.xpath(XPATH_PRODUCT_SELLER1) seller2 = listing.xpath(XPATH_PRODUCT_SELLER2) seller_ratting =listing.xpath(XPATH_PRODUCT_SELLER_RATTING) seller_percentage = listing.xpath(XPATH_PRODUCT_SELLER_PERCENTAGE) seller_url = listing.xpath(XPATH_PRODUCT_SELLER_URL)
The Code
import requests
from lxml import html
from lxml.etree import ParserError
import json
from time import sleep
import argparse
import unicodecsv as csv
import traceback
def parse_offer_details(url):
'''
Function to parse seller details from amazon offer listing page
eg:https://www.amazon.com/gp/offer-listing/
:param url:offer listing url
:rtype: seller details as json
'''
# Add some recent user agent to prevent blocking from amazon
headers = {
'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
for retry in range(5):
try:
print("Downloading and processing page :", url)
response = requests.get(url, headers=headers)
if response.status_code == 403:
raise ValueError("Captcha found. Retrying")
response_text = response.text
parser = html.fromstring(response_text)
XPATH_PRODUCT_LISTINGS = "//div[contains(@class, 'a-row a-spacing-mini olpOffer')]"
# Parsing seller list
listings = parser.xpath(XPATH_PRODUCT_LISTINGS)
offer_list = []
if not listings:
print("no sellers found")
return offer_list
# parsing individual seller
for listing in listings:
XPATH_PRODUCT_PRICE = ".//span[contains(@class, 'olpOfferPrice')]//text()"
XPATH_PRODUCT_PRIME = ".//i/@aria-label"
XPATH_PRODUCT_SHIPPING = ".//p[contains(@class, 'olpShippingInfo')]//text()"
XPATH_PRODUCT_CONDITION = ".//span[contains(@class, 'olpCondition')]//text()"
XPATH_PRODUCT_DELIVERY = ".//div[contains(@class, 'olpDeliveryColumn')]//text()"
XPATH_PRODUCT_SELLER1 = ".//h3[contains(@class, 'olpSellerName')]//a/text()"
XPATH_PRODUCT_SELLER2 = ".//h3[contains(@class, 'olpSellerName')]//img//@alt"
product_price = listing.xpath(XPATH_PRODUCT_PRICE)
product_price = product_price[0].strip()
product_prime = listing.xpath(XPATH_PRODUCT_PRIME)
product_condition = listing.xpath(XPATH_PRODUCT_CONDITION)
product_shipping = listing.xpath(XPATH_PRODUCT_SHIPPING)
delivery = listing.xpath(XPATH_PRODUCT_DELIVERY)
seller1 = listing.xpath(XPATH_PRODUCT_SELLER1)
seller2 = listing.xpath(XPATH_PRODUCT_SELLER2)
# cleaning parsed data
product_prime = product_prime[0].strip() if product_prime else None
product_condition = ''.join(''.join(product_condition).split()) if product_condition else None
product_shipping_details = ' '.join(''.join(product_shipping).split()).lstrip("&").rstrip("Details") if product_shipping else None
cleaned_delivery = ' '.join(''.join(delivery).split()).replace("Shipping rates and return policy.", "").strip() if delivery else None
product_seller = ''.join(seller1).strip() if seller1 else ''.join(seller2).strip()
offer_details = {
'price': product_price,
'shipping_detais': product_shipping_details,
'condition': product_condition,
'prime': product_prime,
'delivery': cleaned_delivery,
'seller': product_seller,
'asin': asin,
'url': url
}
offer_list.append(offer_details)
return offer_list
except ParserError:
print("empty page found")
break
except:
print(traceback.format_exc())
print("retying :", url)
if __name__ == '__main__':
# defining arguments
parser = argparse.ArgumentParser()
parser.add_argument('asin', help='unique product id, eg "B01DQ2B8UY"')
parser.add_argument('condition', help='product condition eg "new", "used", "all", "like_new", "verygood", "acceptable", "good"', default="all")
parser.add_argument('shipping', help='product shipping eg "prime", "all"', default="all")
args = parser.parse_args()
asin = args.asin
condition = args.condition
shipping = args.shipping
# for creating url according to the filter applied
condition_dict = {'new': '&f_new=true',
'used': '&f_used=true',
'all': '&condition=all',
'like_new': '&f_usedLikeNew=true',
'good': '&f_usedGood=true',
'verygood': '&f_usedVeryGood=true',
'acceptable': '&f_usedAcceptable=true'
}
shipping_dict = {'prime': '&f_primeEligible=true',
'all': '&shipping=all'
}
url = 'https://www.amazon.com/gp/offer-listing/'+asin+'/ref='+condition_dict.get(condition)+shipping_dict.get(shipping)
data = parse_offer_details(url)
if data:
print ('Writing results to the file: ', asin, '-sellers.csv')
with open(asin+'-sellers.csv', 'wb')as csvfile:
fieldnames = ['seller', 'price', 'prime', 'condition', 'shipping_detais', 'delivery', 'url', 'asin']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames, quoting=csv.QUOTE_ALL)
writer.writeheader()
for row in data:
writer.writerow(row)
Running the Code
Assume the script is named amazon_seller.py. If you type in the script name in command prompt or terminal along with a -h
python amazon_seller.py -h
usage: amazon_seller-final.py [-h] asin condition shipping
positional arguments:
asin unique product id ,eg "B01DQ2B8UY"
condition product condition eg
"new","used","all","like_new","verygood","acceptable","good"
shipping product shipping eg "prime", "all"
optional arguments:
-h, --help show this help message and exit
Here is are some examples for extracting the seller listings with the ASIN ‘B01DQ2B8UY’:
python amazon_seller.py B01DQ2B8UY “all” “all”

To find the seller listings under the condition ‘prime’ and ‘new:
python amazon_seller.py B01DQ2B8UY "new" "prime"

You can download the code at https://github.com/scrapehero/amazon-seller-list
Let us know in the comments below how this scraper worked for you.
If you want to learn how to scrape product pages and reviews on Amazon you can check out our blog posts:
This code should work for extracting details from the first page of the results. If you want to scrape the details of thousands of pages you should read Scalable do-it-yourself scraping – How to build and run scrapers on a large scale. If you need professional help with scraping complex websites, contact us by filling up the form below:
Turn the Internet into meaningful, structured and usable data
Known Limitations
We can help with your data or automation needs



