

With a large number of libraries and a vast community, Python remains the top choice for web scraping. This article teaches you how to scrape Amazon using Python.
Read how to use a combination of Python requests, Selenium, and BeautifulSoup to scrape Amazon prices and product details.
The Environment to Scrape Amazon Product Data Using Python
You need three external Python libraries to run the code shown in this tutorial. These are
- Python requests: Has methods to send and receive HTTP requests for fetching the target web page.
- Selenium: Can interact with a web page using an automated browser.
- BeautifulSoup: Has intuitive methods to parse HTML code and extract data points.
You can install these packages using PIP.
pip install requests selenium beautifulsoup4
The Data Extracted
The code in this tutorial first extracts product URLs from Amazon’s search results page and saves them into a file.
It then extracts six data points from each product page targeted by the URL:
- Name
- Rating
- Rating count
- Price
- Overview
- Features
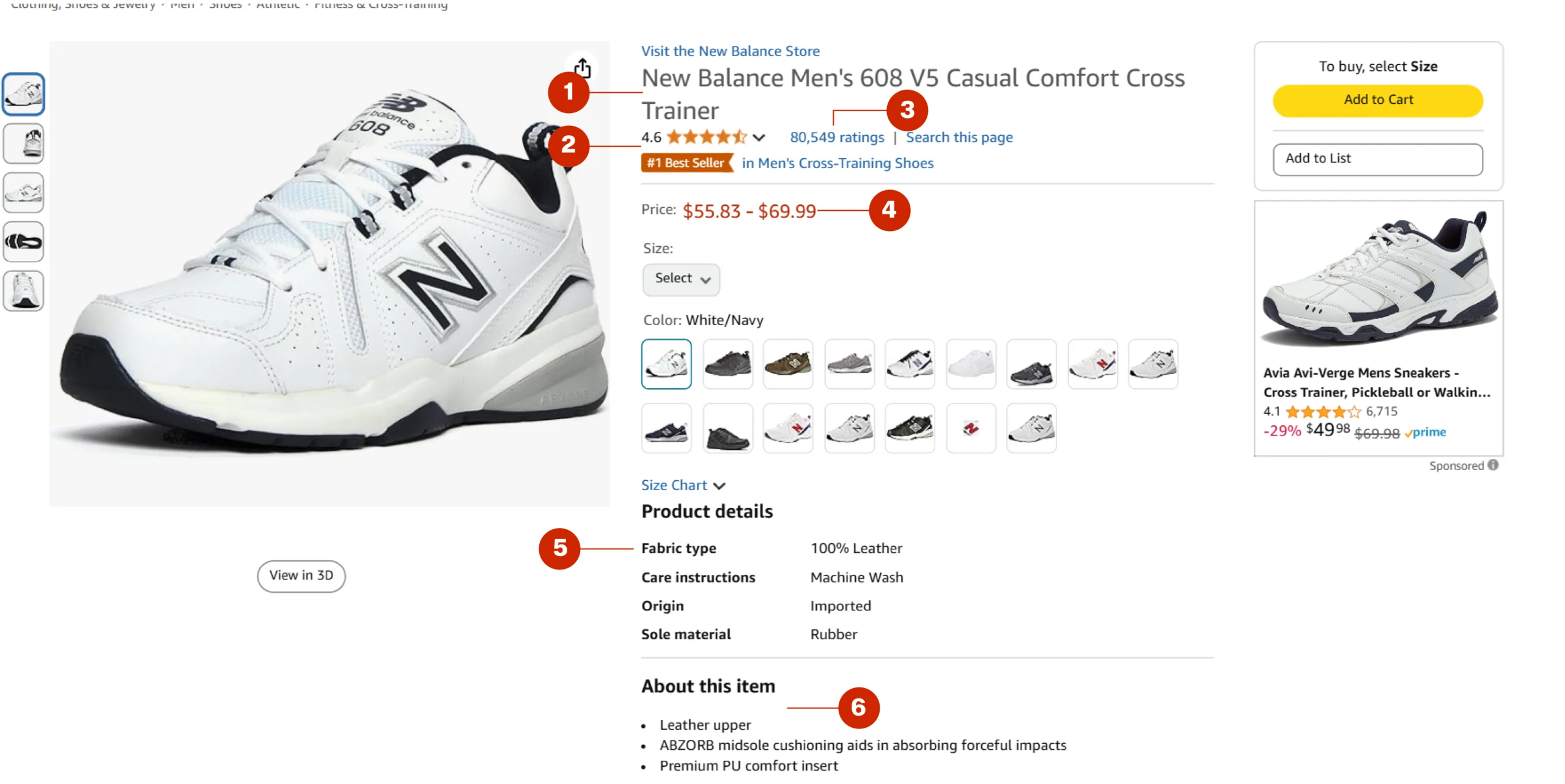
To locate these data points programmatically, you will need to know the elements holding them. To do so, you can use your browser’s inspect feature.
Right-click on a data point and click ‘Inspect’ from the context menu; this will open an inspect panel with the data point’s HTML code.
By analyzing the code, you can determine the HTML elements containing the data points and, thereby, how to uniquely locate these elements using BeautifulSoup.
For example, the product URLs are inside div elements with a role attribute ‘listitem.’
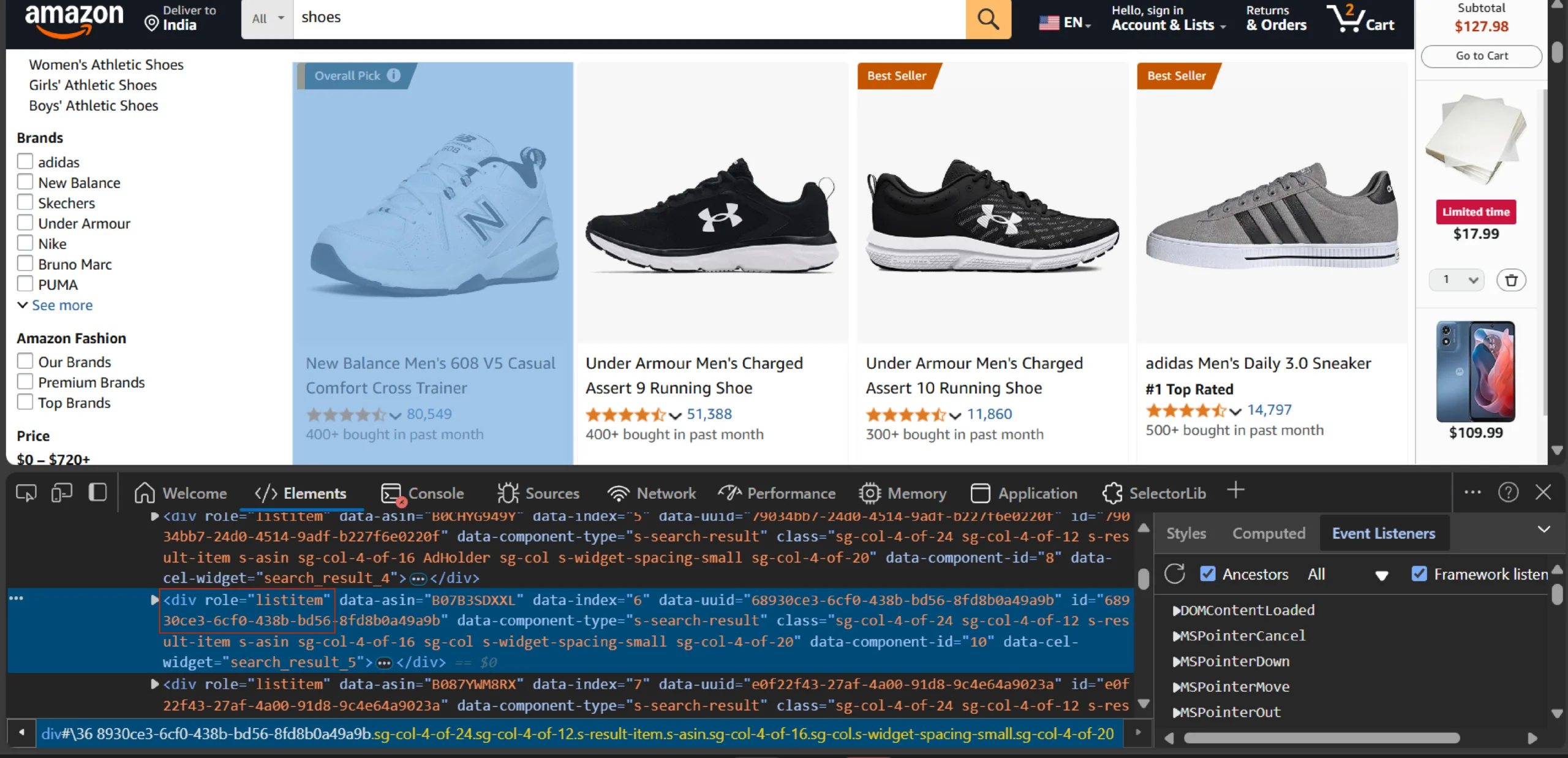
That means you can locate all the div elements using BeautifulSoup’s find_all method.
soup.find_all(‘div’,{‘role’: ‘listitem’})In the above code, soup is a BeautifulSoup object, which contains the method ‘find_all’ mentioned above.
Similarly, you can figure out how to locate the data points on a product page.

The Code to Scrape Amazon Product Data Using Python
The code for Amazon product data scraping with Python starts with importing the required packages.
Besides the packages you saw previously, you also need to import json and time:
- json helps you save the extracted data to a JSON file.
- time has a function, sleep(), that allows you to pause script execution.
from selenium import webdriver
from time import sleep
from bs4 import BeautifulSoup
import json,requestsAfter importing the packages, define the necessary functions. Here, you need three functions:
- clean_list()
- create_url_file()
- scrape_amazon_data()
clean_list()
This function accepts a list and removes unnecessary spaces from each item. It also eliminates empty or unnecessary strings.
def clean_list(lists):
new_list = [item.strip() for item in lists if item.strip() != '' and 'see' not in item.lower() and 'Product details' not in item and 'About this item' not in item]
return new_listcreate_url_file()
This function creates a urls.txt file that contains Amazon product URLs.
It starts by prompting the user for a search term, which the code uses to build Amazon’s SERP URL.
search_term = input("Enter the search term: ")The function then makes an HTTP request to the URL and fetches the HTML code.
response = requests.get(f'https://www.amazon.com/s?k={search_term}',headers=headers)The next step is to parse the HTML code. The code uses BeautifulSoup with lxml for that.
soup = BeautifulSoup(response.text, 'lxml')After parsing, locate and extract the URLs, which are inside an anchor tag inside div elements with an attribute, role= “listitem”
results = soup.find_all('div',{'role':'listitem'})Therefore,
- Find all the div elements with the role attribute ‘listitem’
- Iterate through the elements, and in each iteration
- Extract the anchor tag
- Pull the href attribute of the anchor tab
- Build an absolute URL using the href attribute and append the URL to a list
urls = []
for item in results:
url = item.a['href']
if '/dp/' in url:
urls.append('https://amazon.com'+url.split('ref')[0])Finally, write the list in a text file.
with open('urls.txt','w') as file:
for url in urls:
file.write(url+'\n')scrape_amazon_data()
The scrape_amazon_data() function accepts a product URL and returns a dictionary containing the product details.
First, it launches Selenium in headless mode. A headless browser is necessary here to fetch the HTML code generated using JavaScript.
options = webdriver.ChromeOptions()
options.add_argument("--headless")
browser = webdriver.Chrome(options=options)Next, the function navigates to the URL and waits for 4 seconds. Waiting gives time for the dynamic elements to load.
browser.get(url)
sleep(4)After that, scrape_amazon_data() can use the page_source attribute of the Selenium webdriver to get the HTML code.
source = browser.page_sourceThis HTML code should contain the product details, but the code could also be of an intermediate CAPTCHA page. To check, look for the string ‘captcha’ in the HTML code and return the function early if it exists.
if "captcha" in source:
print("Blocked by captcha")
return {'Failed':'Blocked by captcha'}If ‘captcha’ is not found, the code begins with the next stage: parsing.
As before, the function uses BeautifulSoup with lxml to parse the HTML code, which means it creates a BeautifulSoup object with the code.
soup = BeautifulSoup(source, 'lxml')The function then extracts the required data points from this object:
- Name from a span element inside an h1 tag
- Price from a span element inside another span element with the class ‘a-price’
- Rating details—which contains both the rating and rating count—from a div element with the id ‘averageCustomerReviews.’
- Features from a div element with the id ‘feature-bullets.’
- Overview from a div element with the id ‘productOverview_feature_div’
raw_name = soup.h1.span
raw_price = soup.find('span', {'class': 'a-price'}).find('span')
raw_rating_details = soup.find('div',{'id':'averageCustomerReviews'}).text
raw_features = soup.find('div', {'id':'feature-bullets'})
raw_overview = soup.find('div',{'id':'productOverview_feature_div'})On some product pages, features and overviews are inside a div element with the id ‘productFactsDesktop_feature_div.’
raw_product_details = soup.find('div',{'id':'productFactsDesktop_feature_div'})The above code stores the extracted details in a variable with the prefix ‘raw’; this is because you need to clean the extracted details. The cleaning method depends on the data point.
The name and the price only have extra spaces, which you can remove using strip().
name = raw_name.text.strip() if raw_name else None
price = raw_price.text.strip() if raw_price else NoneThe rating and rating count are inside a string inside the raw_rating_details variable. Separate each word and extract the rating and the count with the appropriate index.
rating_details = raw_rating_details.strip().split()
rating = rating_details[0] if rating_details else None
rating_count = rating_details[6] if rating_details else NoneBefore cleaning features and overview, you need to ensure that the function was able to extract them. Check this using an if statement. If they exist, call clean_list() to clean them; otherwise, extract and clean features and overview from the raw_product_details variable.
if raw_features:
features = clean_list(raw_features.text.split(' '))
overview = clean_list(raw_overview.text.split(' '))
else:
features = [ i for i in raw_product_details.text.split('\n') if 'About this item' in i][0].split(' ')[2]
overview = clean_list(raw_product_details.text.split('\n'))In the above code, the features and overviews are extracted from the raw_product_details variable by splitting the list.
Finally, convert the overview into a dict.
overview_as_dict = {overview[i]:overview[i+1] for i in range(0,len(overview),2)} if overview else NoneAfter extracting and cleaning the data, store them in a dictionary and return them.
data = {
'name': name,
'price': price,
'rating': rating,
'rating count':rating_count,
'overview':overview_as_dict,
'features':features,
'url':url.strip()
}
return dataYou have now defined all the functions; now, it is time to call them.
First, call create_url_file() to build a text file containing a list of Amazon product URLs.
create_url_file()Next, use context managers to handle urls.txt and outfile. Within the context managers:
- Define an empty list to store the extracted data
- Iterate through the URLs and in each iteration:
- Call scrape_amazon_data()
- Append the data returned to the empty list defined previously.
- Save the list as a JSON file.
with open("urls.txt",'r') as urllist, open('output.json','w',encoding ='utf-8') as outfile:
all_data = []
for url in urllist.readlines():
try:
data = scrape_amazon_data(url)
except Exception as e:
print(e)
continue
all_data.append(data)
json.dump(all_data,outfile,indent=4,ensure_ascii=False)The results will look like this.
{
"name": "TECLAST T65Max Tablet, 13\" Android Tablet with 256GB ROM, Helio G99 Octa-core Gaming Tablet, Android 14 tableta, 10000mAh/18W Fast Charge, 13 inch Large Tablets with Widevine L1, 2.4G/5G WiFi, 8+13MP",
"price": "$6806",
"rating": "4.7",
"rating count": "46",
"overview": {
"Brand": "TECLAST",
"Model Name": "T65Max",
"Memory Storage Capacity": "256 GB",
"Screen Size": "13 Inches",
"Display Resolution Maximum": "1920*1200 Pixels"
},
"features": [
"【13 Inch Eye Protection Screen + Widevine L1】 Tablet features a stunning 13 inch eye protection screen, 1920*1200, delivering an immersive visual and entertainment experience. With Widevine L1 certification, enjoy 1080P HD content on Netflix, YouTube, HBO, or Amazon Prime Video. Additionally, this 13” tablet with the blue light certification ensures the tablet minimizes harmful blue light exposure, reducing the potential impact on your sleep and better protecting your eyesight",
"【Helio G99 CPU + 10000mAh Battery】The TECLAST T65Max Android tablet features the powerful MediaTek Helio G99 chip, offering fast and energy-efficient performance, perfect for gaming on its 13 inch screen. Its 10000mAh battery ensures up to 10 hours of uninterrupted use, whether watching movies or listening to music. Plus, the 18W fast charging feature saves you time by quickly recharging your tablet",
"【Android 14 + 256GB ROM】 Running on Android 14 let the tablet more smarter, more secure, and faster. This Android 14 Tablet comes with 8GB of RAM, expandable by an additional 12GB in settings, and offers 256GB of storage with support for up to 1TB via TF card. This ensures ample space for all your favorite apps, photos, videos, and music",
"【4 Speaker System+Parent Control】Enjoy superior audio with the T65Max’s custom-designed 4-speaker system, symmetrically placed for optimal stereo sound. Each speaker is professionally tuned for balanced sound quality. Also, large 13 inch tablet includes a Type-C and a 3.5mm headphone jack, and supports wireless screen mirroring to connect easily to your TV. Give your kids a safe place to learn and play with the TECLAST Parent Control",
"【2.4/5G WiFi+Dual Camera】 Stay connected with the android tablet’s 2.4G/5G dual-band WiFi for fast online experiences. (NOTE:SIM card cannot be used in some areas! ) Ideal for work, study, or travel. the T65MAX is your reliable companion. The dual cameras, 13MP rear camera capture life’s beautiful moments, with a 8MP front camera for clear video calls and face unlock",
"【TECLAST After-Sales】The TECLAST T65Max large screen tablet offers a quad-position satellite navigation system, intelligent noise-reduction dual microphones, Bluetooth 5.2, and more. Built with top-tier hardware, it boasts an AnTuTu score of over 450,000. TECLAST tablets come with a 1-year quality service period; if you have any questions, please tell us, and we will respond within 24 hours",
"›"
],
"url": "https://amazon.com/TECLAST-T65Max-Octa-core-10000mAh-Widevine/dp/B0DLVS8QHY/\n"
}Here’s the complete code to scrape Amazon product data using Python.
from selenium import webdriver
from time import sleep
from bs4 import BeautifulSoup
import json,requests
def clean_list(lists):
new_list = [item.strip() for item in lists if item.strip() != '' and 'see' not in item.lower() and 'Product details' not in item and 'About this item' not in item]
return new_list
def create_url_file():
headers = {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,"
"*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"accept-language": "en-GB;q=0.9,en-US;q=0.8,en;q=0.7",
"dpr": "1",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "none",
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36",
}
search_term = input("Enter the search term: ")
response = requests.get(f'https://www.amazon.com/s?k={search_term}',headers=headers)
soup = BeautifulSoup(response.text, 'lxml')
results = soup.find_all('div',{'role':'listitem'})
urls = []
for item in results:
url = item.a['href']
if '/dp/' in url:
urls.append('https://amazon.com'+url.split('ref')[0])
with open('urls.txt','w') as file:
for url in urls:
file.write(url+'\n')
def scrape_amazon_data(url):
options = webdriver.ChromeOptions()
options.add_argument("--headless")
browser = webdriver.Chrome(options=options)
browser.get(url)
sleep(4)
source = browser.page_source
if "captcha" in source:
print("Blocked by captcha")
return {'Failed':'Blocked by captcha'}
soup = BeautifulSoup(source, 'lxml')
raw_name = soup.h1.span
raw_price = soup.find('span', {'class': 'a-price'}).find('span')
raw_rating_details = soup.find('div',{'id':'averageCustomerReviews'}).text
raw_features = soup.find('div', {'id':'feature-bullets'})
raw_overview = soup.find('div',{'id':'productOverview_feature_div'})
raw_product_details = soup.find('div',{'id':'productFactsDesktop_feature_div'})
name = raw_name.text.strip() if raw_name else None
price = raw_price.text.strip() if raw_price else None
rating_details = raw_rating_details.strip().split()
rating = rating_details[0] if rating_details else None
rating_count = rating_details[6] if rating_details else None
if raw_features:
features = clean_list(raw_features.text.split(' '))
overview = clean_list(raw_overview.text.split(' '))
else:
features = [ i for i in raw_product_details.text.split('\n') if 'About this item' in i][0].split(' ')[2]
overview = clean_list(raw_product_details.text.split('\n'))
overview_as_dict = {overview[i]:overview[i+1] for i in range(0,len(overview),2)} if overview else None
data = {
'name': name,
'price': price,
'rating': rating,
'rating count':rating_count,
'overview':overview_as_dict,
'features':features,
'url':url.strip()
}
return data
if __name__=='__main__':
create_url_file()
with open("urls.txt",'r') as urllist, open('output.json','w',encoding ='utf-8') as outfile:
all_data = []
for url in urllist.readlines():
try:
data = scrape_amazon_data(url)
except Exception as e:
print(e)
continue
all_data.append(data)
json.dump(all_data,outfile,indent=4,ensure_ascii=False)Code Limitations
The code can scrape product data from Amazon SERP; however, it does have some limitations:
- Doesn’t Paginate: The code only gets the product data from the first page of the search results. You need to add additional code to paginate and get the rest of the product links.
- May Break Upon a Change in HTML Structure: Amazon can change the HTML structure at any time. Whenever that happens, you need to figure out new ways to locate the data points.
- Susceptible to Advanced Anti-Scraping Measures: The code doesn’t have methods to bypass advanced anti-scraping measures, making it less suitable for large-scale web scraping.
ScrapeHero Amazon Product Data Scraper: A No-Code Solution
If you don’t want to code, try this Amazon Product Data Scraper from ScrapeHero Cloud.
This no-code scraper doesn’t require any download and can pull product details from Amazon with just a few clicks.
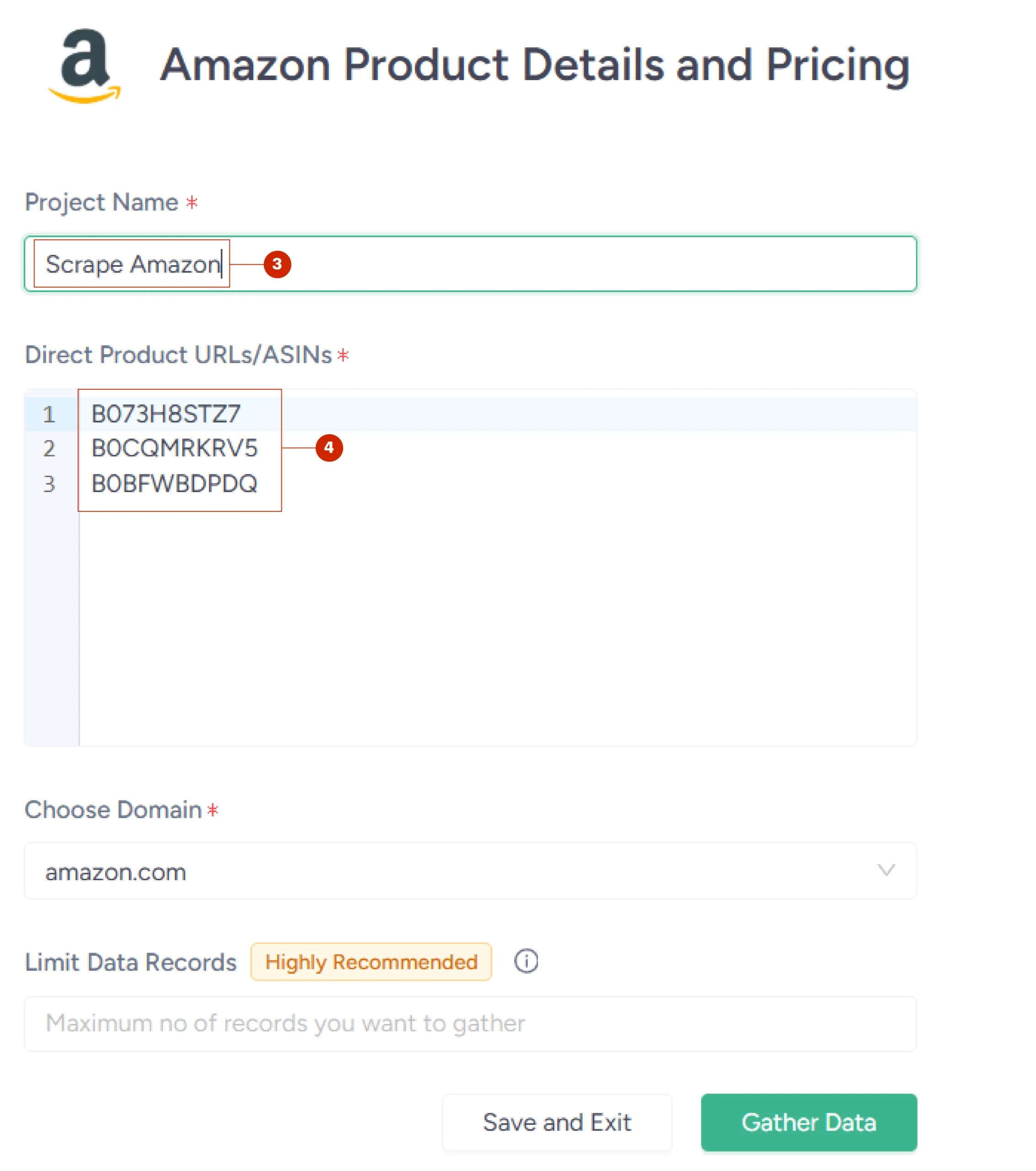
Here’s how to get started for free:
- Go to the scraper’s home page
- Sign in with Google
- Create and name a project
- Add product URLs or ASINS
- Click ‘Gather Data’
Advanced features:
- Scheduling: You can schedule the scraper to run automatically.
- Cloud Storage: You can get this data delivered directly to your preferred cloud storage.
- API Integration: You can seamlessly integrate this scraper with your workflow using an API.
Why Use a Web Scraping Service
While you can scrape Amazon product details using Python, the limitations leave you with three choices: tackle the limitations yourself, use a no-code solution, or delegate that part to someone else, like a web scraping service.
A no-code solution can be excellent if its features align with your requirements. If not, it’s better to choose a web scraping service.
A web scraping service like ScrapeHero can build scrapers in any way you want.
For instance, ScrapeHero can get data from multiple pages of the search results. We can also monitor and address any HTML structure changes and implement anti-scraping measures.
In short, you don’t have to break a sweat to get your much-needed data!
ScrapeHero is an enterprise-grade web scraping service that can fulfill all your data needs, from extracting data to creating custom AI solutions for analysis.


