

Python boasts extensive web scraping libraries. Combined with its vast community, Python makes an excellent programming language for web scraping. Therefore, it makes more sense to learn web scraping with Python if you are already familiar with the language.
This article discusses the basic steps to learn web scraping.
Learn Basic Concepts and Terminology
Getting an overview of basic concepts and terminology makes it easier to learn web scraping with Python. Here are the most important ones:
- HTML (HyperText Markup Language): The standard language for creating web pages. Ensure you are comfortable with reading HTML because analyzing a website’s HTML is one of the steps of web scraping.
- JavaScript: A programming language used by websites to deliver dynamic content. Dynamic content depends on factors such as geography and location, and they are stored inside script tags. The website displays these as HTML after executing a JavaScript code.
- CSS (Cascading Style Sheets): A language used to style the HTML elements. CSS locates an element using a specific set of selectors, which are excellent for locating required elements during web scraping.
- XPath: A syntax used for locating HTML elements during web scraping. XPaths are more powerful than CSS selectors but have a steeper learning curve.
- HTTP Requests: These are messages used to communicate with websites. Several types of requests exist, but web scraping only uses GET requests. In a Python program, the first step is to fetch the HTML source code, and using HTTP requests is one method of doing so.
- Parsing: A process by which a program creates structured out of unstructured HTML source code; data extraction is only possible after parsing.
Now, you can start learning about Python packages for web scraping; they make web scraping possible.
Understand Python Packages for Web Scraping
There are a number of packages available for web scraping in Python:
- Urllib: This package from the Python standard library helps you manage HTTP requests. Learning Urllib allows you to fetch data without installing any external libraries.
- html.parser: This built-in Python package can help you parse data. Although challenging, html.parser makes parsing possible without installing external libraries.
- lxml: A powerful Python library built on top of C libraries (libxml2 and lixbslt) that provides faster parsing and supports XPaths and CSS selectors for locating HTML elements. Learning lxml will help you perform complex web scraping tasks.
- BeautifulSoup: This library makes data extraction easier. It has intuitive methods to locate HTML elements, speeding up scraper development.
- Selenium: A browser automation library you can use to control a web browser. Selenium can interact with websites as a user would, and by learning it, you can execute JavaScript while web scraping.
- Playwright: A browser automation library, like Selenium. However, it is more powerful and challenging to learn.
- Selectorlib: This package makes data extraction easier. It allows you to specify XPaths or CSS in a YAML file. The Selectorlib browser extension can generate this YAML file by clicking on the required data on a webpage.
Learn How to Get the Source Code of an HTML Element
Before starting with the Python code for web scraping, understand how to get the source code of an HTML element. You can do this in two ways.
Using the View Source Option
Use Ctrl + U for Windows/Linux and Command + Option + U for Mac; this will open a new tab with the website’s source code.
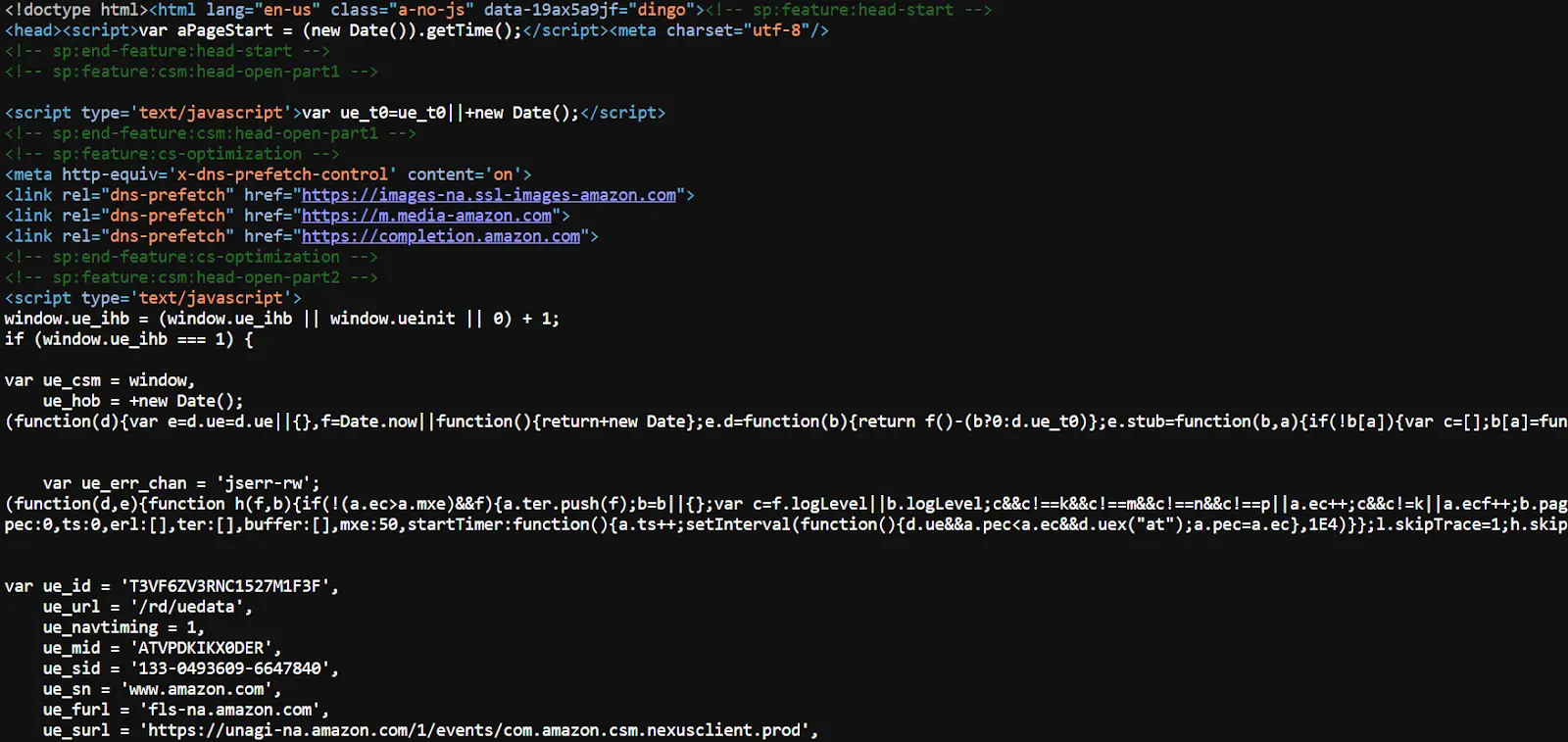
However, locating the elements from the source code can be challenging, which is why using the inspect panel is preferable.
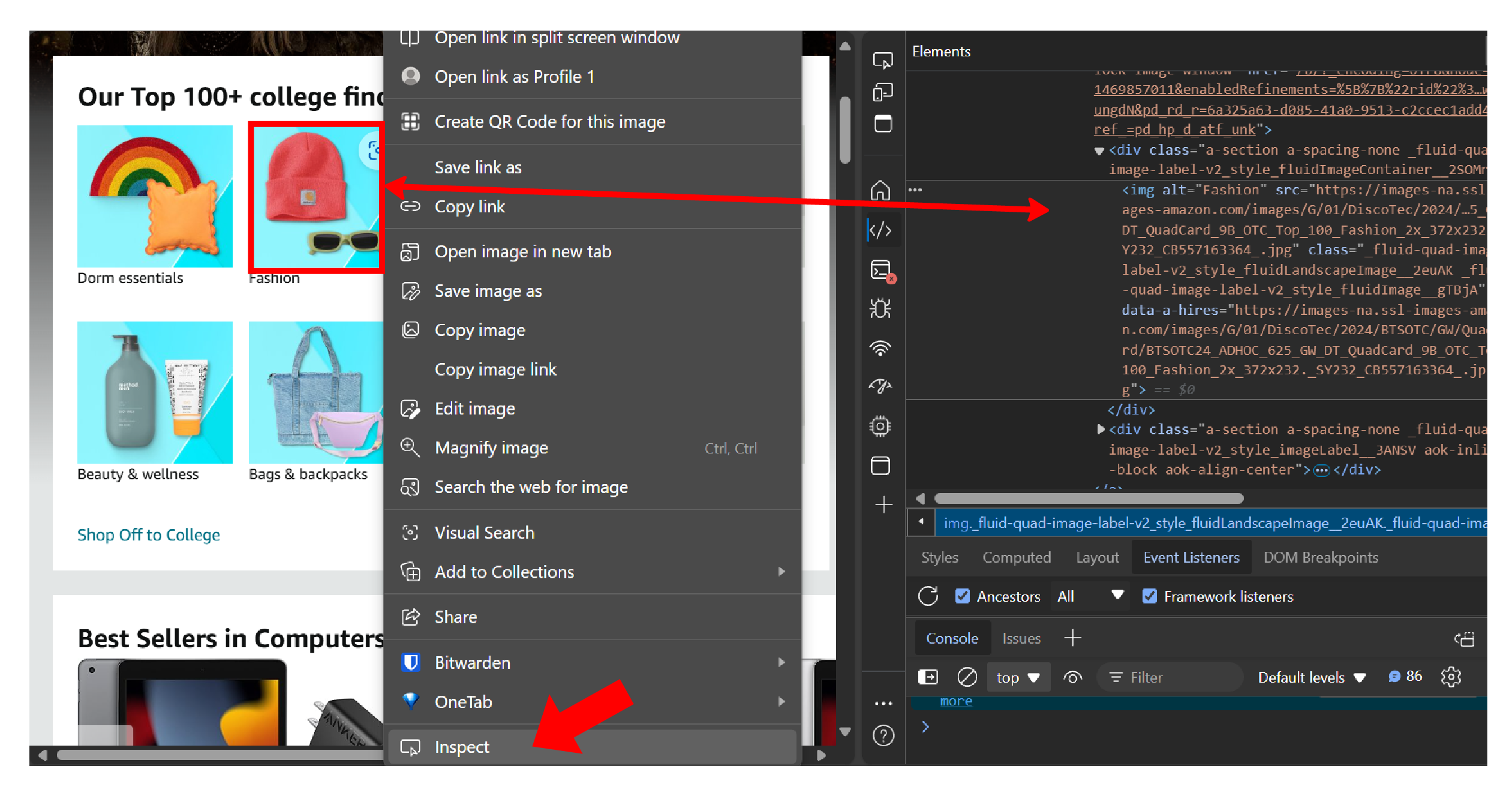
Using the Inspect Panel
You don’t need to sift through the entire source code; right-click on the required data and click the ‘Inspect’ option. This will open a panel on the right with the source code of the element.
Know How to Tell Parsers an Element’s Location
Analyzing the source code will tell you the tags and attributes holding the required data; parsers can use this information to locate the elements. However, giving this information to the parsers depends on the parser.
For example, consider this sample HTML
html_doc = """ <html> <head><title>HTML Parser</title></head> <body> <p>html.parser is a module inside the Python standard library</p> <p>It is extremely cumbersome, hence prone to errors. Learn about it <a href="https://google.com/search?q=html.parser">here</a></p> </body> </html> """
The goal is to extract the title text; each parser will do this differently. Here, you can learn the techniques used by three popular parsers.
HTMLParser
To use HTMLParser, it’s necessary to create a subclass inheriting the parser’s methods. This is because ‘HTMLParser’ does not provide output methods; you must make them in the subclass.
Here is a sample class that inherits HTMLParser and extracts the title.
class titleParser(HTMLParser):
def __init__(self):
super().__init__()
self.title = None
self.intitle = False
def handle_starttag(self, tag, attrs):
if tag == 'title':
self.intitle = True
def handle_endtag(self,tag):
if tag == 'title':
self.intitle = False
def handle_data(self,data):
if self.intitle == True:
self.title = data
parser = titleParser()
parser.feed(html_doc)
print(parser.title)The above code has a class titleParser(). It inherits HTMLParser and consists of four methods.
- __init__() initializes the variables title and intitle
- handle_starttag() changes the value of intitle to ‘True’ if the start tag is ‘title’
- handle_endtag() changes the value of intitle to ‘False’ if the end tag is ‘title’
- handle_data() passes the data between the tags to the variable ‘title’ if the value of intitle is ‘True’
The code
- Creates an object of the titleParser() class.
- Passes the HTML code to this object using the feed() method
- Extracts the title using the title() method
Lxml
In lxml, you can use an XPath expression to achieve the above task.
parser = html.fromstring(html_doc)
title = parser.xpath('//title/text()')
print(title)The above code
- Passes the HTML code to the parser using its html.fromstring() method
- Extracts the title using an XPath expression
BeautifulSoup
Though not technically a parser, it is often considered a parser. BeautifulSoup uses the data parsed by other parsers to create a parser tree and offers intuitive methods to navigate it.
To do the above task, this code uses ‘lxml’ as the parser for BeautifulSoup.
soup = BeautifulSoup(html_doc,'lxml')
title = soup.find('title').text
print(title)The above code:
- Passes the HTML code to the BeautifulSoup constructor to create an object.
- Extracts title using the find() method
Learn How to Code a Basic Python Scraper
You can now learn how to write a basic Python program for web scraping. A basic Python web scraper does three tasks:
- Fetching the HTML source code
- Extracting the required data
- Saving the data to a file
Look at this example that scrapes the name and URL from cars.com. It uses Python requests, BeautifulSoup, and json to do the job.
import requests
import json
from bs4 import BeautifulSoup
# fetching the HTML source code
response = requests.get("https://www.cars.com/shopping/results/?stock_type=all&makes%5B%5D=tesla&models%5B%5D=&maximum_distance=all&zip=")
# extracting car details.
soup = BeautifulSoup(response.text,'lxml')
cars = soup.find_all('div',{'class':'vehicle-details'})
data = []
for car in cars:
rawHref = car.find('a')['href']
href = rawHref if 'https' in rawHref else 'https://cars.com'+rawHref
name = car.find('h2',{'class':'title'}).text
data.append({
"Name":name,
"URL":href,
}
)
# saving the file
with open('Tesla_cars.json','w',encoding='utf-8') as jsonfile:
json.dump(data,jsonfile,indent=4,ensure_ascii=False)The above scraper uses the requests library to fetch the HTML code and BeautifulSoup with lxml for parsing. It follows these steps:
- Imports requests, json, and BeautifulSoup
- Sends a get request to cars.com
- Passes the response to BeautifulSoup
- Extracts details using BeautifulSoup methods find and find_all
- Saves the details to a JSON file
At this point, you must have a rudimentary understanding of web scraping. Now, all you need is consistent practice. Check out these web scraping tutorials for that.
Explore Beyond the Basics of Web Scraping
Explore these topics to take your web scraping skills to the next level.
Anti-Scraping Measures
Websites implement anti-scraping measures, such as CAPTCHAs or IP blocking, to prevent automated access. To overcome these challenges
- Use Proxies: Proxies help you access the target server through a different IP address, allowing you to rotate IP addresses. This way, you can avoid bans on your IP.
- Respect Rate Limits: Ensuring you don’t overwhelm the server by exceeding its request limits will also keep you from being banned.
- Use Headless Browsers: Headless browsers allow you to interact with the target website using a browser; therefore, they mimic user behavior, reducing the chances of a website banning you.
- Use Headers: Headers inform the target website of the request’s origin. Websites may block certain origins, for example, from a scraper. Tweaking these headers will allow you to bypass these measures.
- Handle CAPTCHAs: Sometimes, websites may use challenges called CAPTCHAs to detect and block bots; you need to handle these CAPTCHAs separately.
Data Storage and Management
Data storage is crucial in web scraping. Poor data storage and management techniques may make your web scraping efforts futile. It has several aspects:
- First, you need to choose the appropriate data storage techniques, such as data warehousing, cloud storage, data lakes, etc.
- Next, you must ensure that you follow best practices after storing the data. These include data normalization, data indexing, etc.
- Finally, you should also monitor the performance of your data storage so that you can perform preventive maintenance.
Large Scale Web Scraping
After becoming comfortable with the web scraping process, you can start learning about large-scale web scraping. Large scale requires you to consider several things:
- Hardware: Large-scale web scraping requires advanced infrastructure that can handle a large number of requests and headless browsers.
- Parallel Processing: Huge processing capacity may require you to distribute the workload on multiple machines using frameworks like Apache Hadoop.
- Optimizing: Code must be carefully optimized for scraping on a large scale; large-scale web scraping is more susceptible to performance issues.
Learn to Scrape Ethically
Learning web scraping should not conclude with the techniques. You should know how to web scrape with Python ethically.
- Respect rate-limits: Websites have limits on the number of requests an IP address can make in a particular time. You can respect these limits by slowing down the web scraping process.
- Follow the Robot.txt: Websites specify the pages that bots can access; it is ethical to respect these.
- Scrape What You Need: Only scrape the data you require, thereby reducing unnecessary load to the website.
- Never Scrape Protected Data: Only scraping public data is legal. It is illegal to scrape data behind a paywall or a login screen.
Why Learn Web Scraping? Consider a Web Scraping Service
Learning web scraping in Python is an invaluable skill, but it requires immense time and effort to learn and practice the concepts.
If you need data quickly, consider a web scraping service like ScrapeHero.
ScrapeHero is a web scraping service capable of building enterprise-grade web scrapers and crawlers. We will take care of any website, whether static or dynamic or using strict anti-scraping measures. You can just focus on using data.
FAQs
The time it takes to learn web scraping varies. Expert programmers may start seriously in days, while beginners may take longer.
Common challenges include handling dynamic content generated by JavaScript, overcoming anti-scraping measures, and managing large volumes of data. With experience and the right tools, these challenges can be mitigated.
Before starting to learn web scraping, you must know how to code. Learn Python if you don’t know any programming language because it has an active web scraping community.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data


