

Most organizations don’t catch inaccurate data until the damage is done—a mispriced product erodes margin, a flawed supply forecast disrupts operations, or a strategic report leads to a costly misstep. Bad data doesn’t announce itself. It hides within dashboards and exports, only revealing itself through lost revenue or credibility.
The ability to fix inaccurate web data early is what separates resilient operations from those constantly battling data quality issues and solutions.
Fixing it is not about “cleaning up a spreadsheet.” It’s about diagnosing the source of the failure, fixing your data collection process, and implementing safeguards to prevent recurrence. In this article, you’ll learn why web data becomes inaccurate, how to diagnose the root causes inside your current pipeline, and what you can do to stop these failures before they impact your business.

Common Causes of Inaccurate Web Data
- Silent Failures from Site Changes and Anti-Bot Systems
- Dynamic and JavaScript-Rendered Content
- Formatting and Localization Differences
1. Silent Failures from Site Changes and Anti-Bot Systems
The most common causes of inaccurate data don’t cause loud crashes. Instead, they trigger silent failures:
Unnoticed Site Updates: A website changes its layout, causing your selectors to target empty elements. Your script runs, but captures nothing or the wrong information.
Hidden Anti-Bot Blocking: Defenses like IP rate-limiting or fingerprinting don’t always return an error page. They often serve partial, old, or alternative content that looks valid but is unusable.
In both cases, the pipeline appears healthy, while your data integrity is compromised.
Selector: A piece of code (like CSS or XPath) that “selects” a specific element on a webpage (e.g., a price, a title). When the website’s code changes, the selector breaks.
HTML Fingerprinting: A monitoring technique that creates a unique “fingerprint” of a webpage’s structure. Any change to this structure triggers an alert, signaling a potential breakage in scraping.
2. Dynamic and JavaScript-Rendered Content
Many websites load key fields through JavaScript or separate API calls. Basic scrapers that fetch static HTML never see this content. That’s why pricing, inventory, or customer reviews often go missing. They appear in the browser, but not in the collected dataset.
3. Formatting and Localization Differences
Different websites format data differently:
- Currencies may use commas or decimals.
- Dates may be in dd/mm or mm/dd format.
- Product names may vary by market or language.
If this data is not normalized after extraction, it can lead to mismatches or incorrect values in your systems and reports.

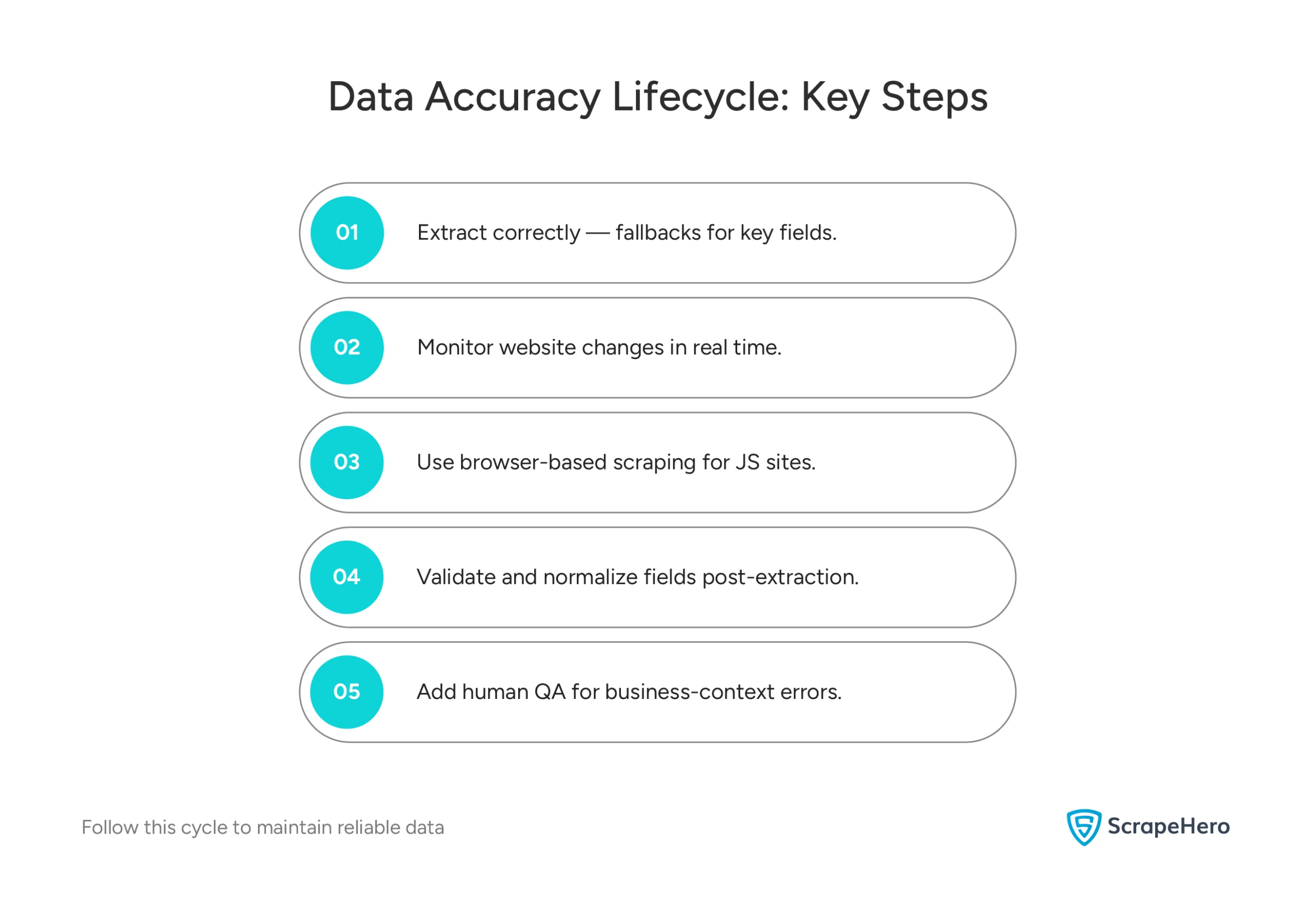
How to Fix Inaccurate Web Data in Your Data Collection System
Now that you understand the root causes, let’s look at how to fix inaccurate web data systematically.
- Strengthen Your Scraper Logic
- Add Monitoring and Alerts
- Use Browser-Based Scraping for Dynamic Content
- Validate After Extraction
1. Strengthen Your Scraper Logic
Start by improving how your scraper identifies and extracts fields. Use multiple fallback selectors for critical elements such as price, rating, and availability. Add simple checks that flag empty or null fields so the issue is caught before it flows into your BI tools.
2. Add Monitoring and Alerts
Do not wait for stakeholders to notice missing data. Instead, set up monitoring that detects structural changes on target websites. HTML fingerprinting or schema watching can alert you when a field disappears, shifts position, or stops rendering. This prevents silent failures and helps you fix data inaccuracies before they affect your analysis.
3. Use Browser-Based Scraping for Dynamic Content
If you are scraping a modern JavaScript-heavy site, static HTML fetchers are not enough. Switch to a headless browser or automated browser-based framework that loads the page exactly as a user would. This ensures you capture absolute values instead of empty placeholders.
4. Validate After Extraction
Data accuracy does not end at collection. Run post-processing checks to detect duplicates, missing fields, and abnormal values. Standardize date, price, and currency formats before storing the data inside your system. When validation happens early, it prevents bad data from corrupting your business decisions and analytics.
By combining stronger extraction logic with real-time monitoring and validation, you create a pipeline that not only collects data but also verifies it. This keeps errors contained and ensures that what reaches your analysts is trustworthy.
When Your In-House Scraping Setup Stops Scaling
An in-house scraping infrastructure often struggles as you scale. As you expand the number of target sites, the initial causes of data inaccuracy, like layout changes and blocking, evolve into more systemic problems. The effort shifts from simple maintenance to managing an operational burden that directly compromises data integrity, creating new and complex avenues for errors to enter your systems.
- Constant Fixes After Website Changes
- Delayed Access to Reliable Data
- High Engineering Maintenance Overhead
- Lack of Normalization Across Inputs
Constant Fixes After Website Changes
If your team is stuck in a cycle of reactive fixes for broken scrapers, you’re maintaining a liability rather than building an asset. This also slows data delivery because engineering time is diverted from improvements to reactive patching.
Delayed Access to Reliable Data
When fixes stack up and validation is manual, data reaches your team late. That delay means your pricing comparisons, assortment checks, or competitor tracking are based on outdated insight. For most enterprise use cases, delayed data is nearly as damaging as inaccurate data.
Example – Real-World Consequence of Inaccurate Data: An e-commerce company using inaccurate competitor pricing data consistently undercut its own prices by 5%, leading to a significant erosion of profit margins on best-selling products before the error was caught.
High Engineering Maintenance Overhead
The more sites you scrape, the more time you spend just keeping your data flow running reliably. Proxy rotation, session management, fingerprint spoofing, and retry handling start to pile up. This creates technical debt that drains engineering capacity and devalues in-house scraping infrastructure over time.
The Hidden Costs of ‘In-House Web Scraping’: Forrester Research found that, on average, data teams waste nearly 70% of their effort cleaning and validating unreliable data, leaving less than 30% for the analysis that drives decisions.
Lack of Normalization Across Inputs
Collecting raw data is one task. Making it consistent is another. When websites format information differently, analysts spend more time cleaning the dataset than using it. Without built-in normalization, the output cannot be trusted at scale. The inability to fix data inaccuracy during the collection phase forces teams into endless cleanup cycles.
When these symptoms appear together, the problem is no longer technical; it is structural. Your current pipeline can collect data, but it cannot guarantee sustained accuracy or delivery speed. This is the point where teams begin looking beyond DIY tools and internal scraping systems and consider managed scraping services built for scale and reliability.
How Managed Web Scraping Services Ensure Data Accuracy

Managed web scraping services maintain accuracy by handling the parts of data extraction that internal teams typically struggle to support at scale: constant monitoring, anti-bot defense, dynamic rendering, and normalization. The advantage is not just convenience. It is long-term reliability. When web data becomes a core business input, accuracy depends on infrastructure and operational depth that most in-house teams are not built to maintain.
- Continuous Monitoring Before Things Break
- Scalable Anti-Bot Protection
- Reliable Extraction for JS-Heavy Websites
- Clean, Ready-to-Use Output Instead of Raw Data
- Human QA Where Automation Fails
Continuous Monitoring Before Things Break
In internal setups, accuracy problems often go unnoticed until someone acts on the wrong information. Managed services prevent this by running round-the-clock monitoring on site structure, selectors, and field-level behavior.
Instead of reacting after failures occur, managed scraping reduces risk by detecting and correcting issues before they impact your business. This is the difference between patching scrapers and running a production-grade data pipeline.
Scalable Anti-Bot Protection
Anti-bot systems are a major source of hidden data loss for any scraping operation. However, most DIY and in-house setups lack detection mechanisms to detect when they are partially blocked. This leads to incomplete records that appear correct on the surface, corrupting your dataset without warning.
Managed providers invest in proxy networks, fingerprint simulation, and CAPTCHA resolution at scale, which is costly and complex for a single company to build on its own. Outsourcing removes the burden of countering anti-scraping defenses and ensures continuity even as protection systems evolve.
Tidbit: Building a reliable, scalable proxy rotation system to avoid IP blocks isn’t a one-time task. It requires continuous management.
Reliable Extraction for JS-Heavy Websites
Modern websites hide critical information behind scripts, lazy loaders, or interactive elements. DIY tools miss it because they do not fully render the page. Managed solutions use browser automation and network-level rendering to capture what users actually see. This approach is expensive to replicate internally and requires ongoing optimization to keep pace with new rendering techniques and site frameworks.
Clean, Ready-to-Use Output Instead of Raw Data
Most internal scrapers stop at “extraction,” leaving your team to clean and standardize the data later. In contrast, managed services deliver normalized, validated, and structured output, which eliminates a large portion of post-processing overhead. The result is not more raw data, but usable data. This matters when accuracy is directly tied to downstream business logic, such as pricing, inventory planning, or competitor benchmarking.
Human QA Where Automation Fails
High-value data needs a human layer to catch business-context errors that automation cannot identify. Managed pipelines include human review as a standard safeguard against low accuracy. Re-creating this inside an engineering team is rare because it demands additional staffing and workflow overhead. Outsourcing gives you this accuracy layer without having to hire or manage it yourself.
This is why companies move from DIY, in-house scraping to managed solutions when scraping becomes mission-critical. It lowers internal effort, reduces operational risk, and ensures accuracy stays intact as the web evolves.
Final Thoughts
Why Accurate Web Data Matters for Your Business
When inaccurate web data feeds business systems, the consequences are strategic, not technical. Flawed data directly undermines core operations:
Poor Commercial Decisions: Incorrect data leads to misguided pricing, eroding margins, and failed strategic investments based on a distorted view of the market.
Operational Disruption: Inaccurate data corrupts forecasting and planning, leading to operational inefficiencies.
Erosion of Trust & Speed: The ultimate cost is crippled decision-making. When data cannot be trusted, teams waste time validating information rather than acting, resulting in costly delays and missed opportunities.
For any data-driven enterprise, the goal must be data that is correct upon collection. Relying on data that is “fixed later” means your business is constantly making decisions with outdated, incomplete, or incorrect information, often discovering the errors only after a costly mistake.
Where Managed Services Improve Outcomes
Shift from reactive maintenance to proactive monitoring: Managed services detect and fix issues before they corrupt your data, preventing silent failures.
Turn technical challenges into reliable infrastructure: Complex problems like anti-bot systems and JavaScript rendering are handled automatically, ensuring consistent data flow.
Reclaim engineering resources: Your team gets reliable, ready-to-use data without spending time on maintenance, allowing them to focus on core business objectives.
What ScrapeHero Adds
If your internal scraping systems are struggling to maintain accuracy or keep up with maintenance, it is likely time to move to a managed approach. ScrapeHero’s web scraping service handles the monitoring, scaling, anti-bot defense, and validation for you, so your team gets production-ready data without the overhead of maintaining scrapers.
When you need to fix inaccurate web data at scale, ScrapeHero delivers the reliability your business demands.
Talk to our experts to see how an accuracy-first managed solution can help you replace internal complexity with dependable, enterprise-grade data delivery.
FAQs
Address inaccurate data at the source by strengthening extraction logic, using browser-based scraping for dynamic content, and adding automated checks. Monitor for silent failures and correct issues before they reach reporting systems.
Standardize date, currency, unit, and naming conventions immediately after extraction. Implement validation rules and normalization workflows to ensure consistent data across sources and markets.
Web data becomes inaccurate due to site layout changes, anti-bot blocks, JavaScript-loaded elements that basic scrapers don’t capture, and inconsistent formatting across regions. These issues often occur silently, so pipelines must detect and flag them.
Use automated validation, fallback selectors, and normalization scripts to detect and fix errors early. For high-value use cases, add human review to catch context-specific mistakes that automation misses.



