

Every major business decision comes down to timing. The impact of data latency on business operations becomes evident when your teams react to market changes hours—or even minutes—late, leaving them a step behind.
This gap between what’s happening and what you’re seeing is data latency, and it quietly drains revenue and slows decisions across the enterprise.
Data Latency Data latency refers to the delay between when data is generated and when it becomes available for use. In most organizations, this delay ranges from a few minutes to several hours, depending on how their pipelines are built.
So, how do you close this gap?
This article breaks down the actual cost of slow data, explains why common internal scraping workflows consistently fall behind, and shows how a specialized outsourcing strategy can solve the latency problem for good.

The Growing Business Impact of Data Latency
Data delays create real financial and operational problems. When your teams use outdated information, the impact spreads across revenue, efficiency, and decision-making.
Here are a few examples of this:
- Revenue Loss
- The Cost of Stale Leads
- Missed Opportunities in Sentiment Analysis
- More Real World Impacts
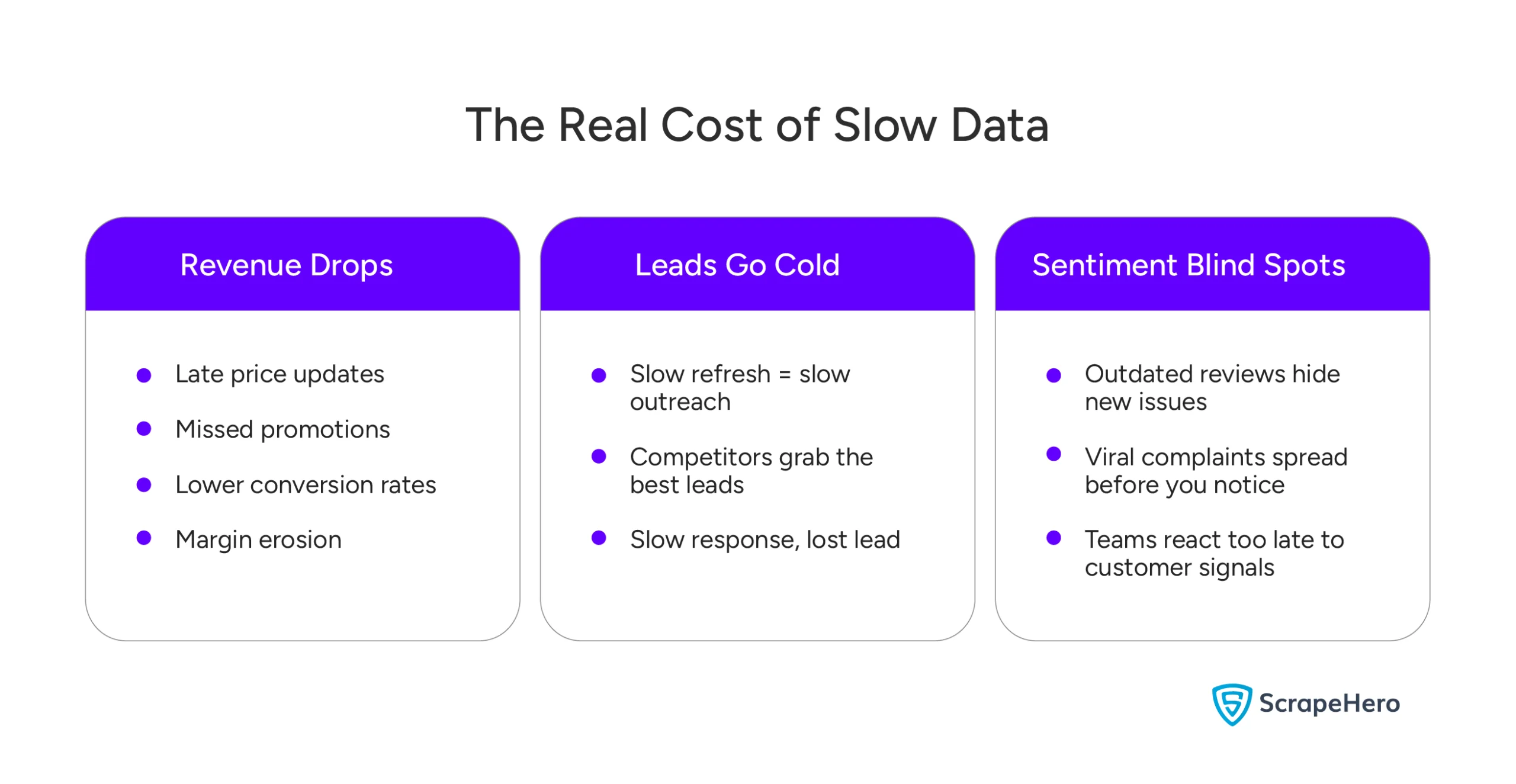
1. Revenue Loss
In E-commerce, delayed price changes reduce conversion rates. When competitors change prices or launch promotions, reacting late results in lost sales and excessive discounting. Even short delays in fast-moving categories can change the outcome of a whole sales cycle.
2. The Cost of Stale Leads
In lead generation, slow data doesn’t just mean you’re inefficient—it means you’re irrelevant. You are constantly reacting to a reality that has already changed, wasting money and effort while your competitors capture the best opportunities.
Did You Know? Industry research shows that contacting a lead within 5 minutes increases qualification rates by up to 21 times. Slow data often pushes this window far beyond the point of recovery.
3. Missed Opportunities in Sentiment Analysis
Analyzing customer sentiment with slow data forces you to react to yesterday’s crisis while missing today’s emerging issues. This delay wastes marketing resources on outdated complaints and prevents teams from capitalizing on real-time opportunities.
4. More Real World Impacts
Further, financial analysts miss high-speed trading windows that close in minutes. And for travel platforms, whose rankings live or die by millisecond price accuracy, latency delivers outdated results, eroding customer trust and the competitive edge.
Slow data’s cost is cumulative and cross-functional. What begins as a minor delay in one team’s report becomes a critical blind spot for another. As a result, the impact of data latency on business extends beyond individual departments, affecting the organization’s ability to compete effectively in fast-moving markets.
The Data Latency Problem: What the Research Shows
Multiple studies confirm that data latency is a direct barrier to growth. Companies need to capitalize on immediate opportunities, but their data infrastructure creates bottlenecks that prevent them from doing so.
1. Slow Data is a Competitive Disadvantage
More than 58% of companies use inaccurate data to make big decisions. When leadership teams lack current information, they delay actions that affect pricing, promotions, and market positioning.
2. Slow Data Blocks AI Use
85% of companies report that inaccurate data is one of the main reasons they don’t use AI effectively across the business. Models trained on old or incomplete information deliver weak results. This forces teams to distrust the outputs and slow down use.
3. Slow Data Fuels Financial Loss
Every year, poor data quality costs organizations an average of $12.9 million. A significant driver of this cost is data latency, which systematically erodes the value of information before it can even be used.
Most organizations believe they are “data-driven.” Yet their systems rely on manual checks, weak scripts, or batch processes that update only once or twice a day. This gap between what they want and what they have is what creates the data latency problem.
How In-House Scraping Inevitably Leads to Data Delays
Many companies start by building their own internal systems to collect web data. These solutions are often practical and cost-effective in the short term. However, as the business grows and the need for real-time, reliable information becomes critical, these systems struggle to scale and maintain consistency.
The challenge isn’t a failure of effort, but a natural limitation of infrastructure that wasn’t designed for enterprise-grade speed and reliability.
- Weak Scripts and Frequent Breakages
- The Maintenance Burden
- Manual Pipelines That Are Not Automated
- Compliance and Legal Risks
- Inability to Handle Large-Scale Needs
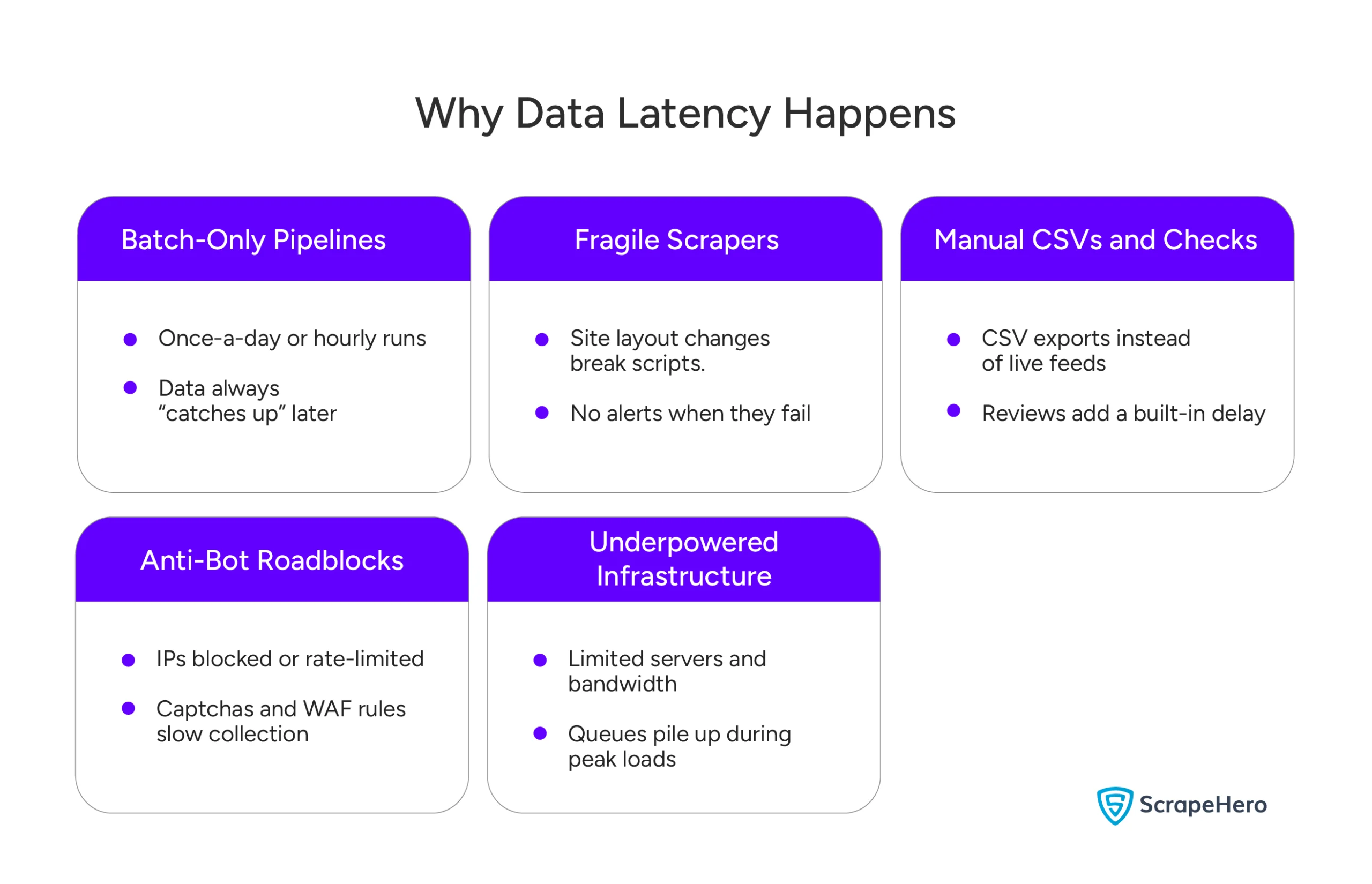
1. Weak Scripts and Frequent Breakages
Websites change layouts, load patterns, and anti-bot rules without notice. As a result, internal scripts often fail without warning. This leads to hours or days of missing data. Teams discover the problem only when a dashboard looks “off.” They don’t find out when the break happens.
2. The Maintenance Burden
Maintaining in-house web scraping systems consumes 40–60% of your engineers’ time, as they constantly work to fix breaks and ensure data consistency. They update selectors or respond to anti-bot blocks. This work adds no value. It takes talent away from the core product or analytics work.
3. Manual Pipelines That Are Not Automated
Many teams still rely on CSV downloads, scheduled runs, or manual checks to validate data quality. These steps introduce a delay by design. They make it impossible to deliver reliable hourly or real-time feeds.
4. Compliance and Legal Risks
In-house scraping systems often operate without essential compliance safeguards. This neglect of proper data governance and legal protocols directly exposes the business to significant regulatory penalties and legal challenges.
5. Inability to Handle Large-Scale Needs
Collecting data at scale from hundreds or even thousands of sources quickly overwhelms internal systems, leading to a direct decline in performance, growing queues, and increased delay.
These issues compound, creating a fundamental gap between the data speed the business requires and what the internal team can reliably deliver. The impact of data latency on business becomes most apparent here, where technical limitations directly translate into missed opportunities and competitive disadvantage.
How Outsourcing Removes the Data Latency Problem
Most companies don’t realize how much delay comes from the limits of their own systems. Outsourcing web data collection removes these limits. The whole pipeline is built and managed by specialists. This includes collection, processing, delivery, and compliance.
1. Always-On, Strong Systems
A managed service uses dedicated crawlers, rotating proxy networks, and other enterprise-grade systems designed for uninterrupted data flow.
2. Automated, Real-Time Data Pipelines
Professional scraping services deliver a continuous stream of real-time data, eliminating reliance on batch runs or manual checks. This live feed flows directly into your existing systems, such as data warehouses, BI tools, APIs, and CRMs. As a result, your teams can work with live data rather than yesterday’s outdated snapshot.
3. Compliance First Design
A managed service operates under a compliance-first design, embedding legal-safe workflows and data regulatory compliance directly into its architecture. This proactive approach systematically eliminates the risk of compliance violations and regulatory penalties.
By outsourcing, you eliminate this legal exposure and gain a partner that assumes the responsibility for compliant data collection, allowing you to scale with confidence.
Real-Time Data: The Key to Staying Competitive
When your teams work with data that updates constantly, every function across the business becomes faster and more accurate. Real-time data analytics doesn’t just improve decisions—it changes the pace at which your entire organization operates. Understanding the importance of real-time data in business has become critical for maintaining a competitive advantage.
- Dynamic Pricing and Revenue Optimization
- Gain Immediate Competitive Intelligence
- Better Customer Experience Insights
- Better AI and Prediction Models
1. Dynamic Pricing and Revenue Optimization
With fresh market signals, your pricing engines adjust right away to competitor movements, demand spikes, or stock changes. This leads to stronger margins and higher conversion rates. This is most important in categories where price changes influence buying decisions within hours.
2. Gain Immediate Competitive Intelligence
Real-time tracking lets you see changes in pricing, product selection, inventory, and promotions as they happen. You can respond before competitors gain an advantage. This improves both market share and promotion efficiency.
3. Better Customer Experience Insights
Fresh reviews and real-time customer feedback provide a live pulse on shifting sentiment. This allows teams to spot early warnings, address issues before they escalate, and capitalize on opportunities faster than ever.
Tidbit: A study found that 83% of consumers expect brands to respond to product issues immediately—something impossible with slow data pipelines.
4. Better AI and Prediction Models
AI systems depend on clean, current data to perform effectively. When trained on real-time inputs, they experience less model drift, achieve greater forecast accuracy, and ultimately operate at their full potential. This creates a compounding competitive advantage.
Organizations can further strengthen these outcomes through AI data mapping, which helps connect and organize information from multiple sources.

Implementing effective ways to reduce latency in data analytics starts with choosing the right web scraping partner.
How ScrapeHero Gets Rid of the Data Latency Problem
Companies struggling with slow data don’t have a quick-fix problem. They have a system problem. This is where ScrapeHero’s web scraping service provides the solution, replacing fragile, in-house setups with a managed, real-time data pipeline built for scale.
- Live, Real-Time Data Delivery
- Automated Pipelines With Less Maintenance
- Custom APIs That Fit Your Existing Systems
- Business-Grade SLAs and Compliance Safeguards
- Predictable Costs
1. Live, Real-Time Data Delivery
ScrapeHero delivers a reliable, constantly-updating stream of critical business data from any online source, freeing you from the technical burden of data collection.
2. Automated Pipelines With Less Maintenance
ScrapeHero manages the entire data pipeline through a seamless blend of automation and human oversight. This end-to-end management handles extraction, validation, transformation, and delivery, guaranteeing data quality without the burden falling on your team.
3. Custom APIs That Fit Your Existing Systems
Seamlessly integrate web data directly into your workflow with ScrapeHero’s Web Scraping API. It powers your applications with real-time data instantly, ensuring your tools and dashboards are always fueled by the latest market intelligence.
4. Business-Grade SLAs and Compliance Safeguards
ScrapeHero provides guaranteed uptime, accuracy promises, legal-safe workflows, and proper SLAs. Your teams get consistency and accountability that internal scraping efforts rarely match.
5. Predictable Costs
Maintaining your own scraping system requires significant engineering effort and ongoing maintenance. ScrapeHero replaces that uncertainty with predictable, transparent pricing.
By outsourcing to Scrapehero, you eliminate data latency. Your data is up to date, compliant, and reliable.
Final Thoughts
Businesses often assume they’re seeing the market as it is, but they’re actually reacting to outdated snapshots that no longer reflect current customer behavior or competitor actions. Companies that move faster don’t have better instincts—they operate on fresher data.
However, internal scraping systems rarely deliver true real-time visibility. So, if your goal is live, reliable data, outsourcing is the most effective way to keep pace with the market you’re trying to lead.
Ready to eliminate slow data and the impact of data latency on your business? Contact ScrapeHero to turn the web into your always-on competitive advantage.
FAQs
Data latency is the delay between when data is created and when you can actually access it. In web scraping, it’s the delay between when something changes on a website and when your scraper captures that change and delivers it to you. Lower latency means fresher, more reliable data.
High latency means you’re reacting to old information. This can lead to missed price changes, outdated inventory insights, or wrong decisions in fast-moving markets. The longer the delay, the bigger the risk.
Your latency is acceptable only if the data arrives in time to influence your decisions. If price updates, availability shifts, or competitor moves reach you too late to act on, your latency is too high.
Yes, it’s possible to get real-time or near–real-time web data, but it depends on how your scraping pipeline is designed. With high-frequency crawlers, event-based triggers, and the proper infrastructure, you can capture updates almost the moment they appear on a site. The key is to match the data refresh speed to the speed at which you need to act.



