

This article is for you if you are a curious beginner or an enterprise data team that wants a clear view of where web scraping is heading this year.
The web scraping industry in 2025 has evolved—and it’s changing faster than ever.
Technologies are getting smarter, laws are tightening, and tools are becoming more user-friendly.
Businesses depend more than ever on online data for real-time insights and automation.
So whether you’re building smarter scrapers or choosing the right tools, you can’t afford to miss these five trends:
Trend 1: AI-Powered Scraping
Trend 2: Ethical and Legal Scraping
Trend 3: No-Code/Low-Code Tools for Web Scraping
Trend 4: Real-Time Data Demand
Trend 5: Multimedia Data Extraction
Trend 1: AI-Powered Scraping
AI-driven scrapers come to the limelight when traditional scrapers often fail when a site’s DOM (Document Object Model) changes.
AI scrapers can detect layout shifts, adjust extraction logic automatically, and even predict when changes are likely to happen.
1. Adaptive Scrapers with Machine Learning
These AI-driven scrapers use machine learning for parsing page structures without relying on hardcoded tags or XPaths with two key techniques:
-
Visual Learning
With visual learning, the scraper can identify key sections on a webpage, such as titles, prices, and reviews, based on their layout and visual structure.
Here, the scraper does not rely on specific HTML code. It adapts to changes in page design, making it more robust and responsive to dynamic content changes.
For instance, the scraper can still accurately extract the data by recognizing the layout’s consistency, even if a website updates the CSS or changes HTML tags for product information.
Here’s a simplified code example using visual learning for page layout recognition:
import cv2
import numpy as np
# Load an image of a product page for analysis
image = cv2.imread('product_page.png')
# Apply image recognition techniques to detect areas that typically contain product titles, prices, and reviews
# This is a simplified example, actual implementations would use deep learning models
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
edges = cv2.Canny(gray, 100, 200)
# Example function to detect title region
def detect_title_area(image):
# Logic to detect title region using contours and layout-based recognition
return image[100:150, 100:300] # Example coordinates, would vary based on image analysis
title_area = detect_title_area(image)
cv2.imshow("Title Area", title_area)
cv2.waitKey(0)
cv2.destroyAllWindows()
-
Natural Language Processing (NLP)
NLP allows scrapers to label elements in the Document Object Model (DOM) by their semantic meaning.
So rather than relying solely on the HTML tag names like <h1>, <p>, or <div> the NLP can better identify and extract the correct data understanding the content’s context.
For instance, NLP models can analyze the text’s meaning to identify which section is most likely to be the product description, even if the class name or tag changes.
Here’s a simple example using NLP with Python’s spaCy library to identify product descriptions in a text:
- HTML Content (Input to NLP):
<h1>Product Title: SuperWidget 3000</h1>
<p>Description: The SuperWidget 3000 is the most powerful widget on the market...</p>
<span>Price: $99.99</span>- Python Code:
import spacy
from bs4 import BeautifulSoup
# Load the spaCy NLP model
nlp = spacy.load("en_core_web_sm")
# HTML content extracted from a page
html_content = """
<h1>Product Title: SuperWidget 3000</h1>
<p>Description: The SuperWidget 3000 is the most powerful widget on the market...</p>
<span>Price: $99.99</span>
"""
# Parse the HTML to extract text
soup = BeautifulSoup(html_content, "html.parser")
text_content = soup.get_text(separator="\n")
# Apply NLP to the extracted text
doc = nlp(text_content)
# Find the sentence containing the product description
description = None
for sent in doc.sents:
if "Description" in sent.text:
description = sent.text.strip()
print("Extracted Description:", description)
- Output:
Extracted Description: Description: The SuperWidget 3000 is the most powerful widget on the market.
2. Predictive Data Collection
Beyond adapting to structure, AI scrapers are also predictive. Instead of passively reading data, AI models learn patterns over time.
Models can perform temporal learning, which allows scrapers to recognize, for instance, that product updates on retail sites often spike between 6 and 9 p.m. on Fridays.
They can also detect trigger events, like monitoring major product reviews as a signal that price changes are about to occur.
Here’s how to train a random forest classifier to predict the likelihood of a price update based on historical data, including day, hour, and review count.
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestClassifier
# Sample historical update data
data = pd.DataFrame({
'day': ['Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Sun'],
'hour': [10, 14, 13, 15, 18, 11, 9],
'review_count': [5, 8, 12, 6, 30, 3, 2],
'price_updated': [0, 0, 1, 0, 1, 0, 0]
})
# Encode categorical
data['day_num'] = data['day'].astype('category').cat.codes
# Train a simple model
X = data[['day_num', 'hour', 'review_count']]
y = data['price_updated']
model = RandomForestClassifier().fit(X, y)
# Predict update likelihood
test = pd.DataFrame({'day_num': [4], 'hour': [18], 'review_count': [25]})
print("Update Likelihood:", model.predict_proba(test)[0][1])
The shift to AI web scraping offers significant benefits, especially for businesses. Accuracy improves on dynamic websites, while maintenance costs decrease due to self-healing systems.
Brands can also monitor product pricing and stock and review data twice as fast.
Trend 2: Ethical and Legal Scraping
Web scraping without compliance often leads to lawsuits, platform bans, or heavy fines. So, it is essential to navigate the complexities of data privacy laws to avoid costly mistakes, especially with the tightening of global regulations.
Ethical Scraping Rules
To avoid IP bans and hefty fines, it is essential to follow some ethical web scraping practices.
-
Scrape Public, Non-PII Data Only
Make sure that you extract public, non-personally identifiable information (non-PII). You can extract data like product listings, pricing, and public reviews, which are openly accessible on websites.
However, you should avoid scraping login-gated data, user profiles, or any information that could involve personal identifiers such as names and email addresses, as it can lead to legal complications.
-
Respect Website Permissions
Always check the site’s robots.txt file and Terms of Service and try to understand the rules and guidelines set by the website owner.
The robots.txt file clearly mentions which parts of the website can be extracted and which cannot.
Disregarding a website’s terms can result in IP bans or legal action from the site owner, even if you scrape publicly available data.
-
Throttle, Delay, and Rotate
Do not hammer servers. Also, use timed delays between your requests to avoid overwhelming the website.
You must also rotate user-agents and headers ethically to mimic real user behavior and introduce random intervals to lighten the server load.
Keep in mind that if you don’t manage your request patterns properly, there’s a higher risk that your IP will get blocked or flagged for malicious activity.
Trend 3: No-Code/Low-Code Tools for Web Scraping
You don’t need to write Python to collect web data. No-code/low-code scraping tools enable you to break technical barriers and extract the data you need without engineering support.
You can run these no-code scrapers without writing a line of code. These platforms offer:
-
Point-and-click interfaces
Point-and-click interfaces allow the users to choose the data they require from a website through a visual interface.
The tool then automatically generates the necessary scraping logic in the background, enabling non-technical users to gather data quickly and efficiently.
For example, when the user clicks on product titles on a webpage, the system generates the extraction rules, and the user can collect all product data without any technical input.
-
Pre-built templates
Many no-code scrapers offer ready-to-use templates specifically designed for use cases such as tracking product data, monitoring competitor prices, or gathering real estate listings.
These templates provide a predefined structure that can be applied directly to the task at hand, simplifying the whole process.
You can also adjust these templates for specific fields without requiring users to start from scratch, which ultimately saves time and reduces complexity.
For example, suppose you are using a pre-built template for price monitoring. It automatically targets product prices, descriptions, and ratings on e-commerce websites, helping you track pricing trends with minimal configuration.
-
Visual workflows
Drag-and-drop workflows allow the users to easily build and manage scraping tasks without needing to write complex code.
Such workflows simplify tasks like setting conditions, handling pagination, and managing logins.
You can even design your scraping task with ease by dragging and dropping components without any coding knowledge.
This way, even non-technical users can navigate complex scraping tasks without having to manually edit the underlying logic.
Here is an example code for visual workflow that illustrates the concept of managing pagination and login handling:
import requests
from bs4 import BeautifulSoup
# Define start URL
URL = "https://example.com/products"
# Headers to mimic a real browser request
HEADERS = {
"User-Agent": "Mozilla/5.0 (compatible; MyBot/1.0)"
}
def get_data(url):
# Send GET request to fetch the page content
response = requests.get(url, headers=HEADERS)
soup = BeautifulSoup(response.text, 'html.parser')
# Extract relevant data
product_titles = soup.select('.product-title')
prices = soup.select('.product-price')
# Print extracted data
for title, price in zip(product_titles, prices):
print(f"Title: {title.text.strip()}, Price: {price.text.strip()}")
# Handling pagination (if available)
next_page = soup.select_one('.next-page')
if next_page:
next_url = next_page['href']
get_data(next_url) # Recursively scrape the next page
# Start scraping
get_data(URL)
ScrapeHero Cloud: No-code Scrapers and Real-Time APIs
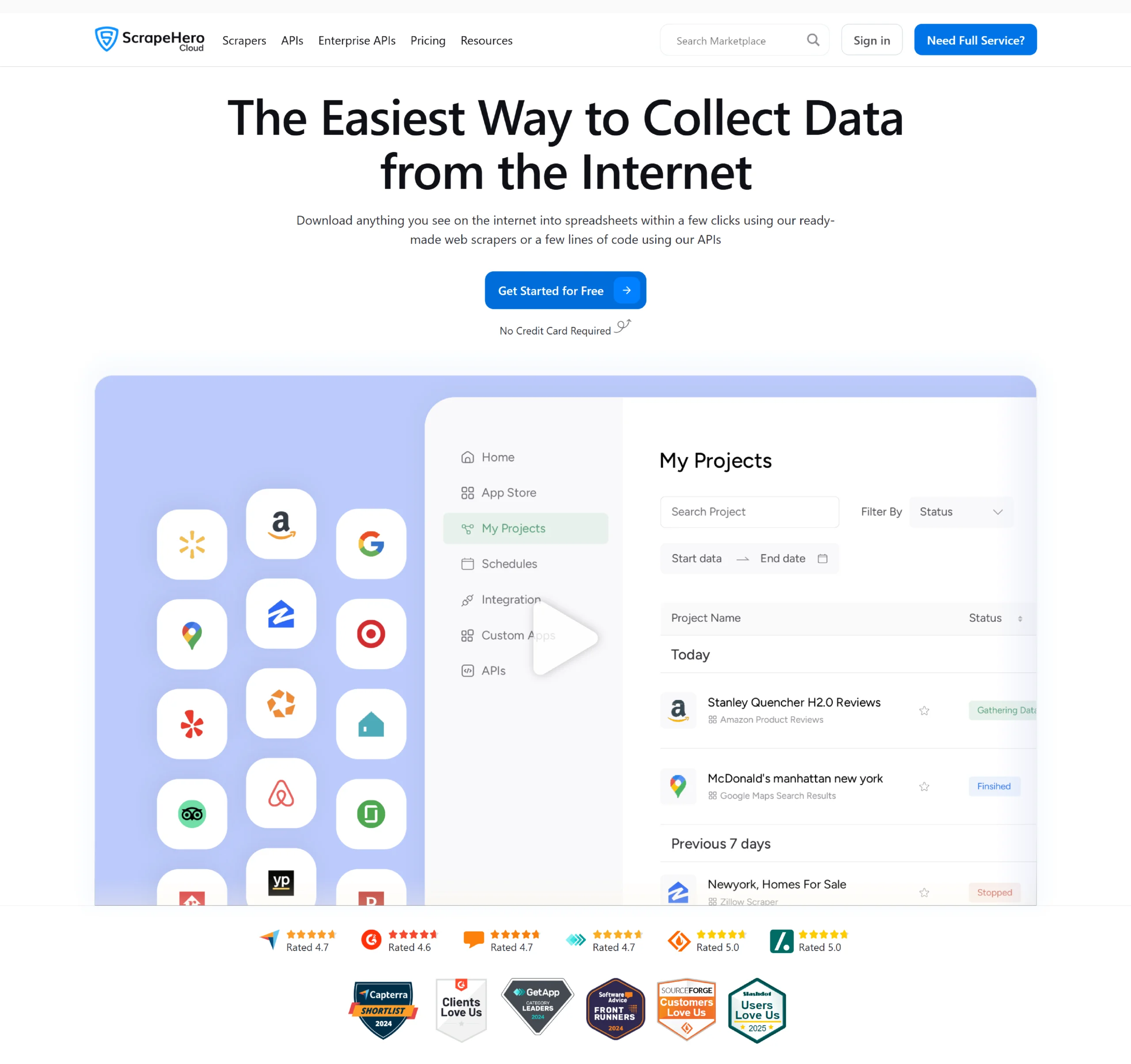
ScrapeHero offers an easy-to-use, no-code solution for web scraping: ScrapeHero Cloud. Our pre-built scrapers and real-time APIs allow you to extract and integrate data into your system quickly.
Key Features of ScrapeHero Scrapers
- Extract over 25 data points from web pages, including product details, reviews, and more.
- Scrape an unlimited number of products without requiring maintenance, with automatic handling of website structure changes and blocking.
- Schedule scrapers to run hourly, daily, or weekly for continuous data collection.
- Periodically deliver scraped data to Dropbox for easy storage and access.
- Affordable solution with a free trial available.
- Accessible for various use cases, providing a simple way to collect data efficiently.

Key Features of ScrapeHero Scraping APIs
-
Extract product details like descriptions, variants, names, types, and 20+ data points in real-time.
-
Structured JSON output for easy integration into applications and systems.
-
Legally compliant, adhering to website policies to avoid potential issues.
-
Real-time data on best-selling products, including rankings, pricing, and reviews.
-
Scalable infrastructure to handle high-volume demands efficiently.
-
Uses residential proxies to bypass CAPTCHAs and IP bans, ensuring smooth data extraction.
With the Ultra plan, you can get up to 4,000 credits per dollar, which allows 300 API calls per minute and 10 concurrent API calls. For more details, refer to our pricing plans.
Trend 4: Real-Time Data Demand
Industries such as finance, e-commerce, and media rely on real-time insights to stay competitive.
So, in order to meet the demand for up-to-the-minute data, scraping pipelines must support dynamic rendering, low-latency delivery, and scalable refreshes.
Key Tips for Scaling Real-Time Scraping
-
Headless browsers + async I/O
If you combine headless browsers like Puppeteer or Playwright with asynchronous I/O, you can reduce latency and increase throughput.
Such headless browsers will allow faster rendering of dynamic content without a UI. Asynchronous I/O enables multiple requests to be processed simultaneously, improving efficiency.
The combination of both can ensure real-time data scraping and handling of a high volume of requests with minimal delay.
In Python, you can use Playwright with asyncio for headless browser scraping to reduce latency and increase throughput.
import asyncio
from playwright.async_api import async_playwright
async def scrape_data():
async with async_playwright() as p:
browser = await p.chromium.launch(headless=True)
page = await browser.new_page()
await page.goto('https://example.com/products')
# Extract product data
product_data = await page.evaluate('''() => {
let products = [];
document.querySelectorAll('.product').forEach(product => {
products.push({
title: product.querySelector('.title').textContent,
price: product.querySelector('.price').textContent
});
});
return products;
}''')
# Print scraped data
print(product_data)
await browser.close()
# Run the scraper asynchronously
asyncio.run(scrape_data())
-
Queue systems
Queue systems such as Redis and RabbitMQ are crucial for managing and distributing tasks in real time.
These systems not only efficiently queue scraping jobs but also ensure that they are processed without overloading servers.
Queue systems ensure that data is collected and processed without bottlenecks by distributing tasks across multiple workers during high-traffic periods.
Here’s how you can use Redis to queue tasks for real-time data scraping.
import redis
import requests
from bs4 import BeautifulSoup
# Connect to Redis
r = redis.Redis(host='localhost', port=6379, db=0)
# Push URLs to the Redis queue
r.lpush('scrape_queue', 'https://example.com/product1')
r.lpush('scrape_queue', 'https://example.com/product2')
# Worker function to process URLs from the queue
def process_queue():
while True:
url = r.brpop('scrape_queue')[1].decode('utf-8')
scrape_data(url)
def scrape_data(url):
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
title = soup.find('h1').text
print(f"Scraped data: {title}")
# Start the worker to process the queue
process_queue()
-
Caching + diff checks
You can avoid redundant parsing of content that hasn’t changed if you implement caching and differential checks.
Also, if the duplicate content is requested again, you can quickly access it if your caching temporarily stores previously scraped data.
Diff checks compare new data with existing data and determine if there have been any changes.
It reduces the need for unnecessary re-scraping and improves efficiency by focusing only on updated content.
Use hashing to detect content changes and avoid redundant parsing of unchanged content. This helps identify whether the page content has changed before scraping again.
import hashlib
import requests
from bs4 import BeautifulSoup
# Function to hash page content
def hash_page(url):
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
page_content = soup.get_text()
return hashlib.sha256(page_content.encode()).hexdigest()
# Store previous hash (could be stored in a file or database)
previous_hash = None
# Check for changes on the page
def check_for_changes(url):
global previous_hash
current_hash = hash_page(url)
if current_hash != previous_hash:
print(f"Content has changed at {url}")
previous_hash = current_hash
else:
print(f"No changes at {url}")
check_for_changes('https://example.com/product1')
-
Triggering systems
When data changes, trigger systems such as webhooks, cron jobs, or file watchers to initiate scraping updates automatically.
Webhooks can notify your system when specific events occur, cron jobs can schedule regular updates, and file watchers can detect when a file or content has been updated.
Such systems maintain a continuous flow of real-time data and ensure that scraping processes are triggered promptly whenever new data is available.
Here’s how you can create a Python scraper and schedule scraping to run at regular intervals using cron jobs.
1. Python Script (scrape.py)
import requests
from bs4 import BeautifulSoup
def scrape_data():
url = "https://example.com/products"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
data = soup.find_all('div', class_='product')
for item in data:
print(item.text)
if __name__ == "__main__":
scrape_data()
2. Scheduling with Cron
To schedule this script to run every 5 minutes and ensure real-time data collection, you can add the following line to your cron jobs:
*/5 * * * * /usr/bin/python3 /path/to/scrape.py
Trend 5: Multimedia Data Extraction
In 2025, web scraping will not be limited to extracting text and prices. Scraping product images, demo videos, and alt text has also become important, especially in retail and e-commerce.
Brand monitoring now involves detecting logos in images across review sites and social platforms and influencer marketing tracks embedded in YouTube and Instagram videos for product mentions.
This shift towards rich media scraping reflects a broader trend of integrating visual and audio data into digital strategies.
Image Scraping with Python
Here’s a basic image scraper using requests and shutil, fully compliant with public content scraping:
import requests
import shutil
def download_image(image_url, filename):
r = requests.get(image_url, stream=True)
if r.status_code == 200:
with open(filename, 'wb') as f:
shutil.copyfileobj(r.raw, f)
print(f"Saved: {filename}")
else:
print("Failed to download:", image_url)
# Example usage
download_image("https://example.com/image.jpg", "product_image.jpg")
Why ScrapeHero Web Scraping Service?
In a year when websites are more dynamic and anti-bot measures more advanced, smart crawlers that can reduce manual maintenance and improve data quality over time are needed.
An enterprise-grade web scraping service like ScrapeHero can make data extraction more resilient.
As a reliable data-scraping partner, we can always offer you a customized plan that fits your requirements perfectly.
Frequently Asked Questions
The top 5 shaping the web scraping industry in 2025 are AI scrapers, legal compliance, no-code tools, real-time data, and multimedia scraping.
Web scraping using AI can reduce downtime by adapting to site changes and predicting when data updates.
As new technologies related to web scraping emerge, the laws will get tighter, and scrapers will need to comply with global data rules to avoid fines.
For faster, more reliable scraping, Playwright will be dominating. Low-code SaaS platforms also make automation accessible to all. Also, AI-driven selectors boost efficiency, and dynamic JavaScript scrapers will tackle evolving websites.
Rely on smart scheduling, distributed crawling, API integration, and serverless pipelines like AWS Lambda for large-scale data extraction.


