

Walmart.com is a dynamic website. When you search for a product on Walmart.com, it executes JavaScript to show the search results.
However, the data is already inside a script tag of the page as a JSON string. The JavaScript merely displays the data at appropriate places.
Therefore, there are two methods you can use for web scraping Walmart.
The first method uses Selenium to visit Walmart.com, execute JavaScript, and extract data. The second method uses Python requests for web scraping and extracts the JSON data inside the script tag.
This article uses the second method, using Python requests to scrape Walmart product results from the script tag.
Environment
The code in this tutorial uses four packages:
- Python requests to manage HTTP requests
- BeautifulSoup to parse and extract the response
- The json module to write the extracted data to a JSON file
- The re module to use regular expressions
You need to install Python requests and BeautifulSoup because they are external Python libraries. The Python package manager pip can install both.
pip install requests bs4The modules json and re are part of the Python standard library.
Data Scraped From Walmart
The tutorial for web scraping Walmart scrapes four data points of each product:
- Name
- Price
- Rating
- URL
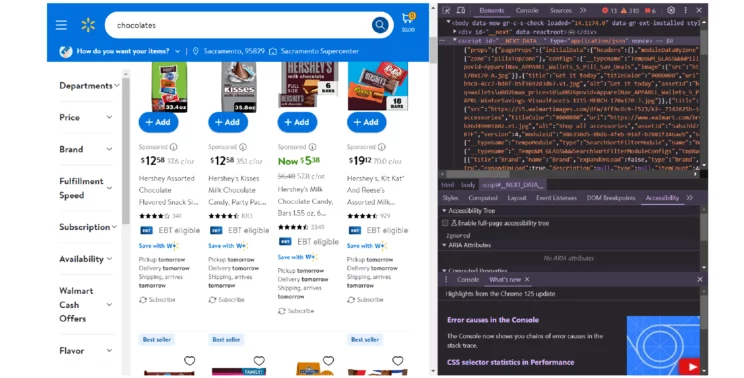
These data points will be inside a JSON string in a script tag with the id “__NEXT_DATA__.”
Web Scraping Walmart with Python: The Code

First, import Python requests, BeautifulSoup, and json.
- Python for handling HTTP requests
- BeauitulSoup for parsing
- The json module handles writing to a JSON file.
import requests
from bs4 import BeautifulSoup
import jsonIt is better to make the script functional for all search queries. Therefore, the code asks the user to enter the search term using the input function.
search_term = input("What do you want buy on Walmart?")Use the search term to build the URL.
You can get the URL template by visiting walmart.com and searching for a product. The address bar of the search results page will give you the required URL structure.
You can then replace the search term with the above variable.
url = f"https://www.walmart.com/search?q={search_term}"Walmart does not support web scraping; therefore, headers are necessary when sending requests that pose as a browser request.
headers = {'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,'
'*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'accept-language': 'en-GB;q=0.9,en-US;q=0.8,en;q=0.7',
'dpr': '1',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'none',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'}Use the get method of requests to make a GET request to the URL with headers as an argument.
You can then parse the response text using BeautifulSoup.
response = requests.get(url,headers=headers)
soup = BeautifulSoup(response.text)As mentioned above, the product details will be inside the JSON string in a script tag with the id “__NEXT_DATA__.” Find this script tag and extract its text using BeautifulSoup.
nextData = soup.find("script",{"id":"__NEXT_DATA__"}).textLoad the JSON string using json.loads(), creating a JSON object.
jsonData = json.loads(nextData)This JSON object will contain all the required product details; however, you need to analyze the JSON object manually to determine how to extract them.
There are two methods for that:
- You can use the autocomplete functionality of a code editor and an IPython notebook.
- Type square brackets with quotes inside next to the Javascript object. The editor will make suggestions.
- Use them individually to find the correct key
- Save the entire JSON string in a file, search for the product details, and figure out the keys.
Here, the product details of all the products are inside the key “items.”
products = jsonData["props"]["pageProps"]["initialData"]["searchResult"]["itemStacks"][0]["items"]You can now loop through each product and extract details. In each loop,
- Use an if condition to verify if the product is in stock.
- Extract name, ratings, URL, and price
- Store the extracted details in an array defined outside the loop.
for product in products:
try:
if product["availabilityStatusV2"]["value"] == 'IN_STOCK':
name = product["name"]
url = "https://walmart.com"+product["canonicalUrl"]
ratings = product["rating"]
price = product["price"]
walmartProducts.append(
{
"name":name,
"price":price,
"url":url,
"ratings":ratings
}
)
except:
continueNote:
- Use a try-except block to avoid errors when entries do not have some keys.
- Add the base URL to the canonical URL to make the URL absolute
Finally, save the array to a JSON file.
with open("walmartProducts.json","w",encoding="UTF-8") as jsonFile:
json.dump(walmartProducts,jsonFile,ensure_ascii=False,indent=4)Code Limitations
This code for Walmart web scraping does not go into each product page. You need to do that to get more information, including reviews and descriptions.
Moreover, Walmart can change the JSON structure anytime, making your code invalid. You then need to figure out the keys of the new JSON structure and update the code.
Walmart Scraper: An Alternative
You can avoid coding with our free ScrapeHero Walmart Scraper. This no-code web scraper from ScrapeHero Cloud can extract all product details with only a few clicks.
- Go to ScrapeHero Cloud
- Create an account
- Add the Walmart Scraper
- Enter the input
- Click gather data
Features of ScrapeHero Walmart Scraper
- Use multiple input types
- Search URL
- Keyword
- SKU
- GTIN/UPC
- ISBN
- Schedule the scraper to run in fixed intervals
- Deliver it to your cloud storage
- Get the data as either Excel or JSON
- Use rest API to control the scraper programmatically
Want to scrape data from a single product? Check out this tutorial on How to Scrape Walmart Product Data.
Wrapping Up
You can scrape Walmart products from its search results page using Python requests and BeautifulSoup. However, the code does not extract details from the product pages.
You need to alter the code for that. The code will also require changes when Walmart changes the JSON structure. Moreover, you also need to update the code such that it can handle anti-scraping measures on big projects.
If you want to avoid all this coding or scrape at a large scale, try ScrapeHero Services.
ScrapeHero is an enterprise-grade web scraping service; we can build high-quality web scrapes according to your specifications. Our services range from large-scale web scraping and crawling to monitoring and custom RPA services.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data



