

The difference between web scraping and APIs comes down to where you’re pulling data from — scraping targets web pages directly; APIs use structured endpoints exposed by the server.
Each has trade-offs around data availability, cost, speed, and control over your pipeline. Knowing which to use can save you significant engineering time and cost.
What is Web Scraping?
Web scraping refers to gathering data from public web pages using a computer program. It is similar to copying the contents of web pages and pasting them into a document. However, web scraping automates this entire process at scale.
Here’s a typical code to scrape a website:
import requests
from lxml import html
import json
response = requests.get(''https://sitetoscrape.com")
parser = html.fromstring(response.text)
data_point_A = parser.xpath("//div[@id='a']/text()")
data_point_B = parser.xpath("//div[@id='b']/text()")
data = {
'A' = data_point_A,
'B' = data_point_B
}
with open('scraped.json','w') as f:
json.dump(data,f,indent=4)This code gets the data points from div elements using their IDs. The location of the data points can change depending on the data point and the website.
For instance, if the data point you need is inside a span element with the ID “name,” the XPath becomes “//span[@id=’name’]/text()”.
What are APIs?
APIs, or application programming interfaces, allow you to communicate with a server using a computer program.
Servers must expose their endpoints for APIs to function. An endpoint is the location (usually a URL) of a specific task that the API can perform. Exposing an endpoint means allowing others to interact with it.
During the interaction, you can send information, retrieve data, or manage resources, depending on the API’s purpose.
Here’s the code you would use if the site mentioned in the previous section had an API.
import requests
import json
response = requests.get(
"https://api.sitetoscrape.com/v1/data",
headers={"Authorization": "Bearer YOUR_API_KEY"}
)
response.raise_for_status()
result = response.json()
data = {
"A": result["a"],
"B": result["b"]
}
with open("api_data.json", "w") as f:
json.dump(data, f, indent=4)APIs return structured JSON objects — no parsing required. In this code, you access data points directly by key, but real responses are rarely flat. Your actual fields will likely be nested several levels deep, so expect paths like result[“data”][“attributes”][“a”] instead of a simple result[“a”].
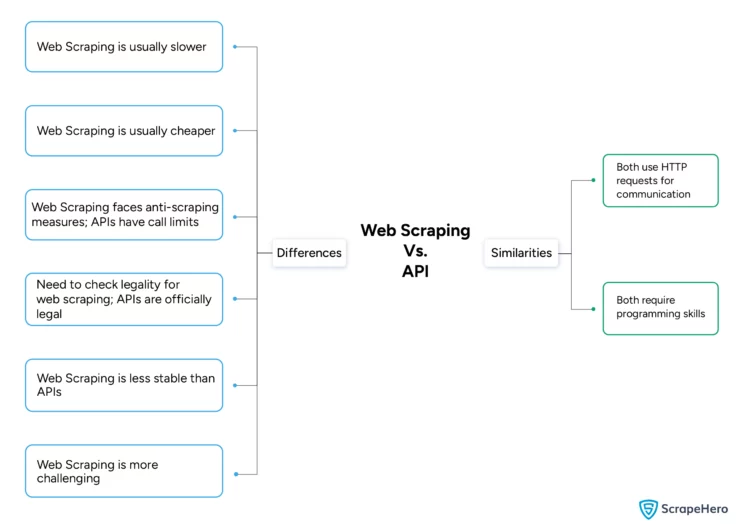
Differences Between Web Scraping and APIs
When comparing API vs scraping data, the differences span six dimensions:
- Speed
- Cost
- Restrictions
- Legality
- Stability
- Difficulty
1. Speed
The primary difference between web scraping and API is that web scraping is slower than APIs, as you only extract information from public-facing web pages, while an API lets you connect directly to the server.
Moreover, web scraping may require you to render JavaScript before getting a valid response, reducing the speed. Even after getting a response with the HTML content you need, you must parse it, further slowing down the pipeline.
APIs directly return information based on your request. The payload of the request specifies exactly what data you need, with no intermediate parsing step.
2. Cost
One of the main benefits of web scraping over public API is that it is usually cheaper for high-volume data collection. You can typically scrape data from any website with only computational power and an internet connection. However, sometimes you may need to use proxies to bypass anti-scraping measures, which can be expensive.
While many APIs are free to start, most use tiered pricing where the cost depends on your usage; typically, every HTTP request you send counts as one API call toward your limit.
3. Restrictions
Servers can restrict web scraping through anti-scraping measures, including blocking specific requests. In rare situations, the server may block your IP address entirely. However, these anti-scraping measures can often be bypassed.
Servers restrict APIs by limiting the number of API calls. Private APIs usually have usage tiers: the more expensive the tier, the more API calls you can make per day or month.
4. Legality
Web scraping may be illegal if you are not careful about the data you are scraping. Web scraping public data is generally considered legal, but scraping private data behind a login or paywall is not.
APIs are official access mechanisms sanctioned by the platform. You don’t need to worry about legality as long as you don’t try to bypass their stated restrictions or Terms of Service.
5. Stability
Web scraping is less stable than using APIs, as you don’t know when the website’s structure will change. You need to update your code whenever that happens. Servers can also increase anti-scraping measures at any time, requiring you to figure out new bypass techniques.
With APIs, websites inform you well in advance before implementing changes. They also temporarily allow access to older API versions even after deploying new ones. This gives you time to make adjustments to your integration code.
6. Difficulty
Web scraping is more challenging than using an API to retrieve data. An API integration program is largely the same across providers—you only swap out access tokens and endpoints. Documentation describes exactly how each API works.
In contrast, web scraping logic depends entirely on a website’s unique structure, requiring you to reverse-engineer the layout for each target. You may also need to handle anti-scraping measures such as custom headers and proxy rotation.
Web Scraping Vs. API: Similarities
- Both web scraping and APIs can use HTTP requests to retrieve data.
- Both require programming skills to implement effectively.
What’s Changed in 2026
TLS Fingerprinting Has Raised the Bar for Scrapers
Over the past year, one of the most significant shifts in the web scraping landscape has been the widespread adoption of TLS fingerprinting as an anti-bot layer. Websites now inspect the TLS handshake itself (JA3/JA4 signatures) to detect non-browser clients. This means that standard requests-based scrapers are now blocked outright on many major e-commerce and news platforms without any visible error. You simply receive a 403 or an empty response.
Tools like curl_cffi (which impersonates Chrome’s TLS stack) have become near-essential for scraping in 2026.
AI-Assisted Scraper Maintenance
Another notable development: teams are now using LLMs as co-pilots for scraper maintenance. When a website’s HTML structure changes and an XPath selector breaks, feeding the new HTML into a model like Claude or GPT-4o to regenerate a working selector cuts debugging time from hours to minutes. This hybrid approach is quickly becoming standard in production workflows.
APIs Are Getting Tighter, Not Looser
On the API side, platforms like Reddit, X (formerly Twitter), and LinkedIn have substantially restricted or monetized their previously open API tiers throughout 2024–2025. What was once freely accessible via API is now either paywalled at high cost or entirely unavailable, pushing many legitimate data use cases back toward scraping as the only viable option.
This makes the “API vs. scraping” decision less of a technical one and more of a data access strategy decision in 2026.
Best of Both Worlds: What are ‘Web Scraping APIs’?
Web scraping APIs are APIs built on top of a scraper. You make a standard API call and receive structured scraped data in return — combining the clean interface of an API with the reach of web scraping.
ScrapeHero offers both custom-built web scraping APIs tailored to your requirements and ready-made APIs on ScrapeHero Cloud for specific use cases — such as real-time product data from Walmart, on demand.
Why would a company choose scraping over an API in 2026?
You can gather data using both web scraping and APIs, but the better method depends on the situation. Web scraping works for virtually any public website, while APIs only apply to platforms that expose endpoints.
However, web scraping is more challenging than using APIs. You must reverse-engineer the extraction logic for each site, stay ahead of anti-scraping technologies like TLS fingerprinting, and maintain your scrapers as sites change. As of 2026, many platforms have also restricted or monetized their APIs, pushing data teams back toward scraping for broad, cross-site data collection.
If you want the benefits of both approaches, web scraping APIs offer the cleanest path forward. Try ScrapeHero’s web scraping service if you want to avoid coding entirely. ScrapeHero is a full-service web scraping service provider capable of building enterprise-grade scrapers customized to your exact requirements.
FAQ
Yes, many production data pipelines combine both. For example, you might use an official API to retrieve structured product metadata and supplement it with web scraping to capture data the API doesn’t expose, such as user reviews or dynamic pricing. Hybrid approaches are common in enterprise data workflows.
REST, SOAP, GraphQL, and RPC:
1. REST is by far the most common for web data—it uses standard HTTP methods and returns JSON.
2. SOAP is older and XML-based, still common in enterprise systems.
3. GraphQL lets clients request exactly the fields they need.
4. RPC (including gRPC) calls functions on a remote server directly, common in internal microservices.
No—AI depends on data, and scraping is one of the primary ways to get it. What’s changing is that AI is being layered on top of scraping to parse unstructured content, handle dynamic pages, and adapt to site structure changes. If anything, AI makes scraping more capable, not redundant.
Not in the traditional sense. ChatGPT can browse the web via its built-in tool, but that’s controlled retrieval—not scraping. It can’t systematically extract large datasets, bypass access controls, or output structured bulk data. What it can do is write scraping code for you to run yourself.


