

Regex allows you to fish strings with specific patterns. So, in theory, you can perform web scraping using regex. However, using regex is more error-prone. Hence, dedicated parsing libraries, like BeautifulSoup, are more preferred.
But there is no harm in learning data extraction using regex; doing so can solidify your knowledge of both regex and web scraping.
Ready to see it in action? This article shows you how to use regex for web scraping without using any parser.
How regex Works
Before using regex for web scraping, let’s be clear on the fundamentals.
Regex or regular expressions work by searching for a pattern in a string. For example, suppose you want to find emails from a string. Then, the pattern of the string could be
\S+@\S+.\S+

Here,
- \S is a non-whitespace character
- + tells that the previous character should repeat one or more times
- @ matches the character itself
- \. matches the period. The period is a special character, requiring a backslash to escape it.
In short, the above pattern searches for a string. The string has a non-white characters before and after the character ‘@’. Following them, the string also has a period and another set of non-whitespace characters.
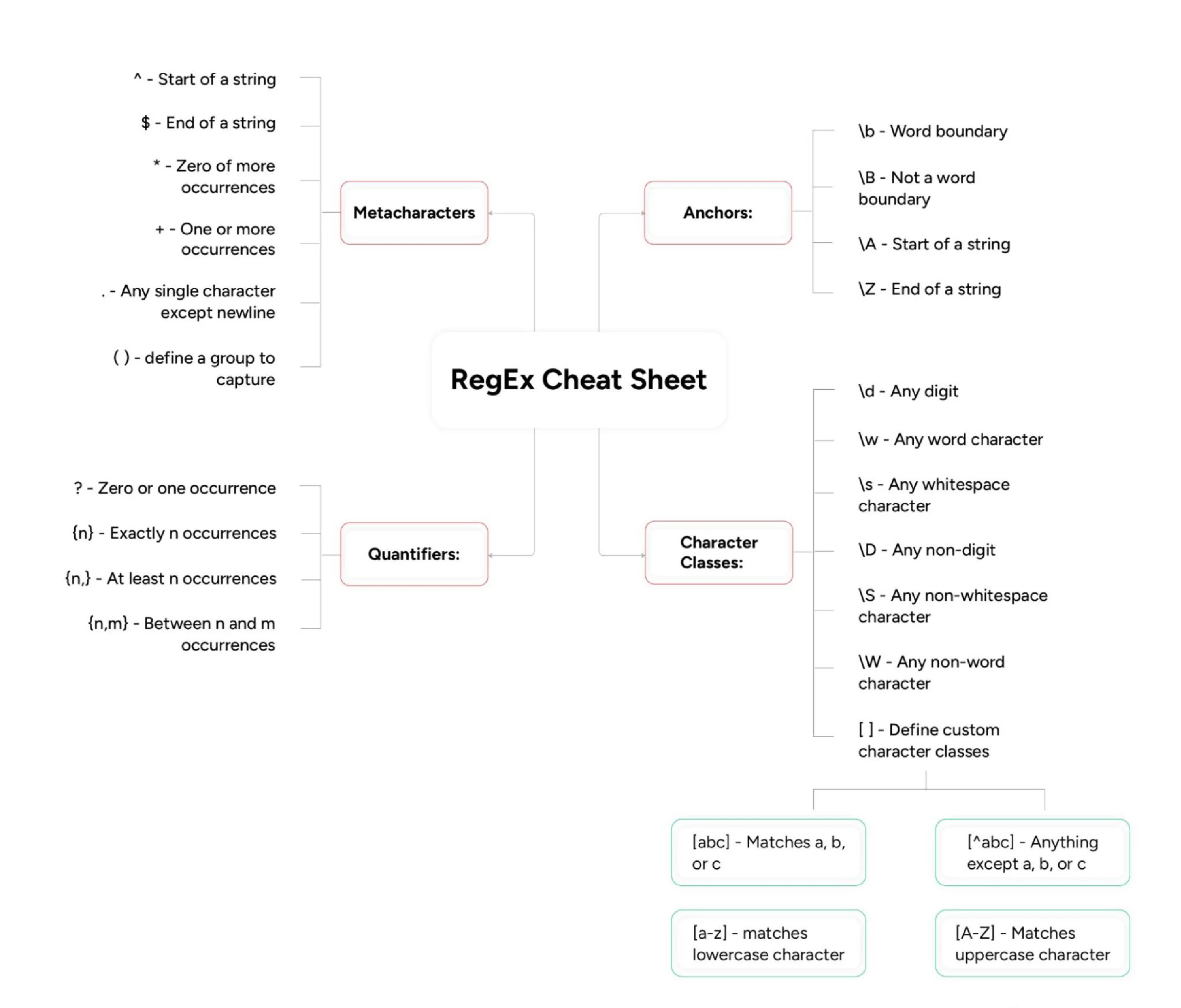
Here is a regex cheat sheet you can use while using regex for web scraping.
Data Scraped Using Regex
The tutorial shows web scraping using regular expressions with Python. The Python code uses regex to scrape eBay product data. It scrapes three product data from its search results page:
- Name
- Price
- URL
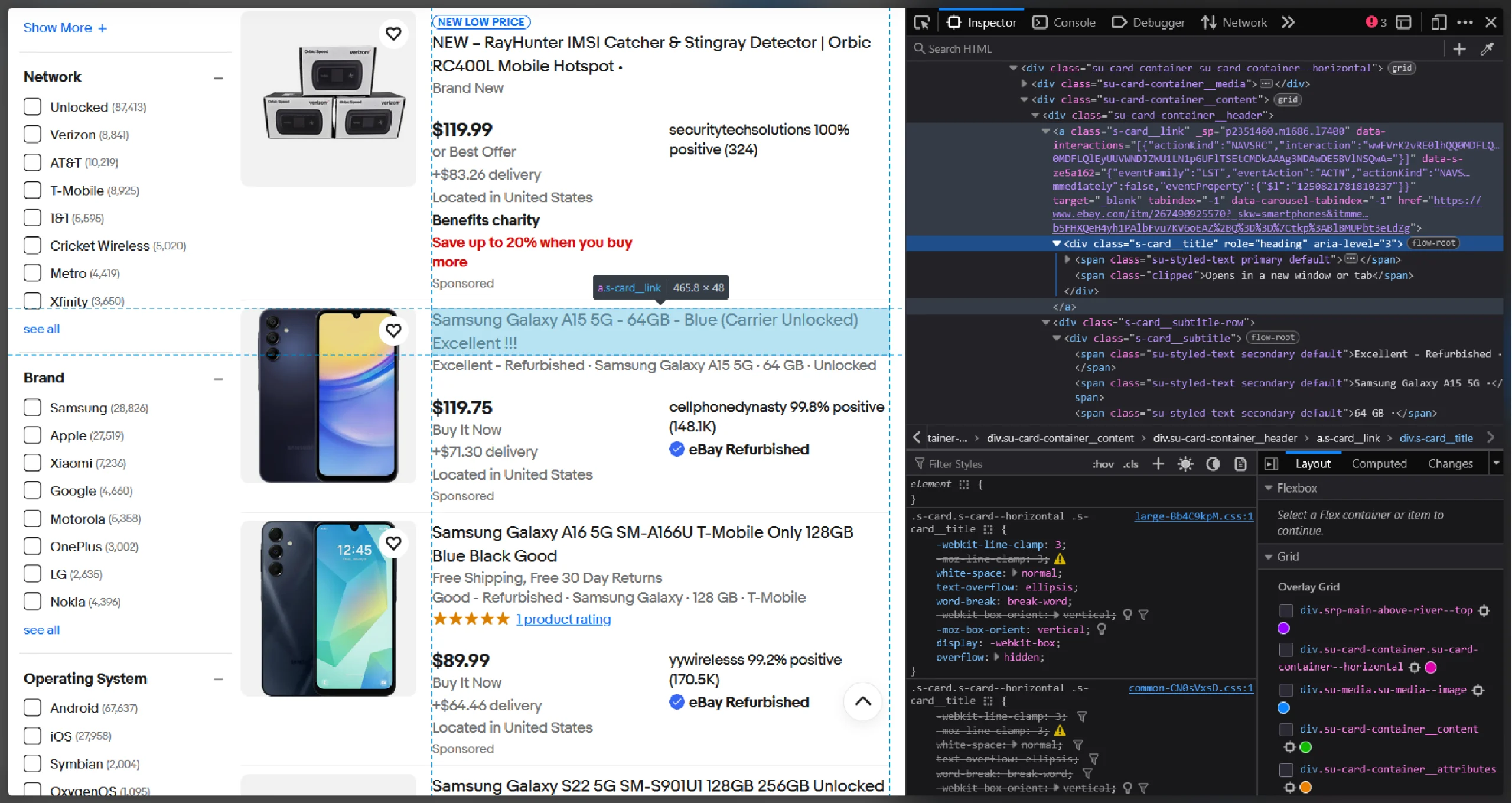
Use the browser’s inspect tool to find the HTML source code of these data points. Right-click on a data point and click ‘Inspect.’
Web Scraping Using Regex: The Environment
The code in this tutorial uses three Python packages:
- The re module: This module enables you to use regex
- The json module: This module allows you to write the extracted data to a JSON file
- Selenium: This library allows you to control a browser and interact with dynamic websites.
The re and json modules come with the Python standard library. So you don’t need to install them.
However, you need to install Selenium. You can do it using pip.
pip install selenium
Web Scraping Using Regex: The Code
Here’s the complete code if you want it right away.
import requests
from selenium import webdriver
url = "https://www.ebay.com/sch/i.html?_nkw=smartphones&_sacat=0&_from=R40&_trksid=p2510209.m570.l1313"
response = requests.get(url)
with webdriver.Chrome() as browser:
browser.get(url)
html_source = browser.page_source
products = re.findall(r'<li>.+?class="s-card.+?price.+?</li>',html_source)
nameAndUrl = []
for product in products:
name = re.findall(r'<div.+?role="heading".+?span.+?>(.+?)<',product)[0]
price = re.findall(r'<span.+?s-card__price.+?>(.+?)<',product)[0]
url = re.findall(r'<a class="s-card__link.+?href="(.+?)"',product)[0]
nameAndUrl.append(
{
"Name": name,
"Price": price,
"URL": url
}
) if 'Shop on eBay' not in name and '<' not in name else None
re.findall(r'<a class="s-card__link.+?href="(.+?)"',products[10])[0]
with open("regEx.json","w",encoding="utf-8") as f:
json.dump(nameAndUrl,f,indent=4,ensure_ascii=False)
The script starts by importing the packages mentioned above.
import re
import json
from selenium import webdriver
Next, launch the selenium browser and get the page source:
- webdriver.Chrome() launches the browser
- .get(url) navigates to eBay’s search results page
- .page_source gets the HTML source code
with webdriver.Chrome() as browser:
browser.get(url)
html_source = browser.page_sourceThe next step is to extract the list elements holding the product listings. From these li elements, you can then extract the name, URL, and price. The findall() method of the re-module can help you find the div element.
The findall() method takes two arguments, a pattern, and a string. It checks for the pattern in the string and returns the matched values. Here, the pattern matches a string that
- Starts with ‘<li’
- Contains ‘class=”s-card’ and ‘price’
- Ends with ‘</li>’
products = re.findall(r'<li.+?class="s-card.+?price.+?</li>',html_source)
The extracted div elements will be within a list; you can iterate through the list and extract the required data points. Each data point needs a different data point.
Extracting Name
The name will be inside a span tag that is inside a div element with the role “heading”
<div role="heading" aria-level="3" class="s-card__title">
<span class="su-styled-text primary default">
BLU C5L MAX (Unlocked) Black 16GB 2GB RAM 5.7" Quad-Core C0175WWBLA Android
</span>
<span class="clipped">Opens in a new window or tab</span>
</div>
Therefore, the regex pattern to extract the name should
- Start with ‘<div’
- Contain ‘role=”heading”’ and ‘span’
name_pattern = r'<div.+?role="heading".+?span.+?>(.+?)<'
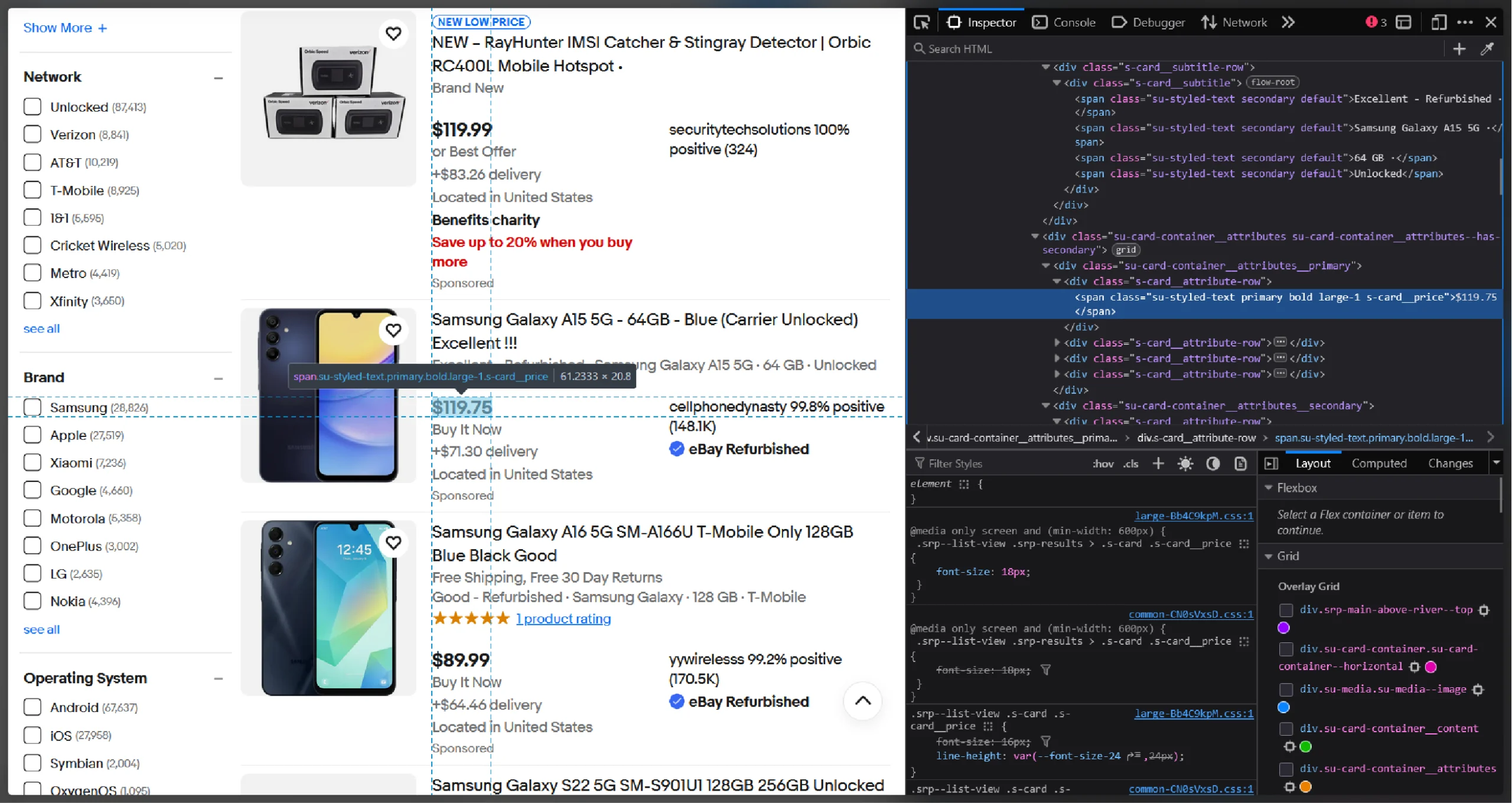
Extracting Price
The price will be inside a span element with the class ‘s-card__price’
<span class="su-styled-text primary bold large-1 s-card__price">$560.00</span>Therefore, the regex pattern to extract the name should
- Start with ‘<span’
- Contain ‘s-card__price’
price_pattern = r'<span.+?s-card__price.+?>(.+?)<'
Extracting URL
The URL will be inside an anchor tag’s href attribute:
<a class="s-card__link" _sp="p2351460.m1686.l7400"
data-interactions="[{"actionKind":"NAVSRC","interaction":"wwFVrK2vRE0lhQQ0MDFLQktYM0RLMlg3SFhaMlFYR0NUN0ZOSFQ0MDFLQktYM0RHS01IR1ZXTjI5M1ROREVaRkoAAAg3NDAwDE5BVlNSQwA="}]"
data-s-qcq0696="{"eventFamily":"LST","eventAction":"ACTN","actionKind":"NAVSRC","actionKinds":["NAVSRC"],"operationId":"2351460","flushImmediately":false,"eventProperty":{"$l":"1141073777882371"}}"
target="_blank" tabindex="-1" data-carousel-tabindex="-1"
href="https://www.ebay.com/itm/257113610638?_skw=smartphones&itmmeta=01KBKX3DGKMHGVWN293TNDEZFJ&hash=item3bdd2a598e:g:hy4AAeSwHVxozMyh&itmprp=enc%3AAQAKAAAA4FkggFvd1GGDu0w3yXCmi1eQHzeFmhQWHTjtpi%2FOyEAorO5EIvXz2Av98qnfODpBU8pu%2BUGYRvGKMwliDTiI%2F96Q9LDImM1a9Zh9QW3EJSlambrIQBxkSxg63JHNgtuhOFBUMgabR8QAjfBayEcbSons5izUbC5HGfSUQ396xduLk7bWs7ujNtoknMHolNV%2F7sEaI5vTfLcXU1d2%2BnN%2F%2BctjDm8ldViaf49wWGA7o17ALMd58AWUvtz%2Bkel4LrQr09LeFsRwgGQISOi4GVPyGTKnfP5Kvg3ESMwcLK6KOaet%7Ctkp%3ABFBMztiN_dxm">
<div role="heading" aria-level="3" class="s-card__title"><span class="su-styled-text primary default">TESLA XPLORER
9
</span>
<span class="clipped">Opens in a new window or tab</span>
</div>
</a>
Therefore, the regex pattern to extract the name should
- Start with ‘<a class=”s-card__link
- Contain href
Note: The above patterns are specific to the eBay search results page. Analyze the HTML source code to determine the appropriate regex patterns in each project.
You can use the above pattern to extract data from each div element. Iterate through the extracted div elements, and in each iteration
1. Extract name, price, and URL
name = re.findall(r'<div.+?role="heading".+?span.+?>(.+?)<',product)[0]
price = re.findall(r'<span.+?s-card__price.+?>(.+?)<',product)[0]
url = re.findall(r'<a class="s-card__link.+?href="(.+?)"',product)[0]
2. Store them in a dict and append it to an array. Here, the patterns also match strings that are not required. So use a conditional statement while appending; specifically, it should not append the values if the name contains ‘Shop on eBay’ or the character ‘<’
nameAndUrl.append(
{
"Name":name,
"Price":price,
"URL":url
}
) if name !='Shop on eBay'and '<' not in name else None
Finally, you can save the array as a JSON file using the JSON module. To do so, use json.dump().
with open("regEx.json","w",encoding="utf-8") as f:
json.dump(nameAndUrl,f,indent=4,ensure_ascii=False)
Don’t want to use regex? Read this article on Selenium web scraping that extracts data from dynamic websites.
Code Limitations
The code shown in this tutorial is only efficient if the code is well-structured. For complex, highly nested HTML source code, web scraping using regex can become slow.
Moreover, a slight change in the HTML can break the code. For example, a change in spacing or the order of attributes may render the code unusable even if the attributes and the tag names of the data points remain unchanged.
The code does not bypass anti-scraping measures. Hence, it is not appropriate for large-scale web scraping, as the massive number of requests make your scraper more susceptible to these measures.
Why Code Yourself? Use ScrapeHero’s Web Scraping Service
The code can scrape three data points from an eBay search results page, showing web scraping with regex in Python.
However, maintaining a regex code can be challenging as slight changes can break it. Moreover, trying to scrape additional data points requires complex regexes that can slow down the process.
Therefore, it is better to use a professional web scraping service, like ScrapeHero, for large-scale projects where scalability is important.
ScrapeHero’s web scraping service can build enterprise-grade web scrapers and crawlers according to your specifications. Contact ScrapeHero! You can then focus on using the data to derive insights rather than focussing on gathering the data.
FAQs
Regex is a pattern-matching language for identifying text sequences. While flexible, it’s fragile—HTML changes break patterns easily. Use it only for simple, consistent formats. For most web scraping, HTML parsers (BeautifulSoup) are more reliable since they understand document structure rather than fragile text patterns.
Regex is rarely the better choice. Prefer XPath and CSS selectors for selecting elements—they handle HTML structure changes gracefully. Only use regex for extracting specific formats within already-selected content (emails, phone numbers). Regex breaks when HTML layouts change; selectors adapt more easily.
Essential patterns include:
1. \d+ for numbers
2. \w+ for words
3. [a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.\w{2,} for emails
4. https?://[^\s]+ for URLs
5. \d{1,2}/\d{1,2}/\d{4} for dates


