
Building a framework to scrape websites requires significant time and effort. However, it provides valuable insights into various web scraping frameworks.
While customizing existing frameworks for web scraping is more efficient, the point mentioned above highlights the benefits of learning how to construct a framework.
This article shows how to create a basic Python web scraping framework.
Purpose of a Framework
Before starting with the example, let’s discuss the purpose of a web scraping framework.
A web scraping framework allows you to avoid writing boilerplate code yourself and give your web scraping projects a structure.
A boilerplate code is one that is necessary for scraping any website, but is similar in all scraping projects. For example, sending HTTP requests, saving files, etc.
By separating this boilerplate code into individual scripts, you can use them in all your projects without having to rewrite them each time.
Advantages of eliminating boilerplate code and implementing structured coding:
- Faster coding: You need to write less code, which increases the speed of completing a project.
- Less error-prone: Less code to write means less information to handle in each project, reducing the errors.
- More efficient debugging: Finding the bugs is easier when your project is well-structured.
- Easier to scale: Adding functionalities in a structured project with minimum boilerplate code is easier.
Steps to Build a Web Scraping Framework
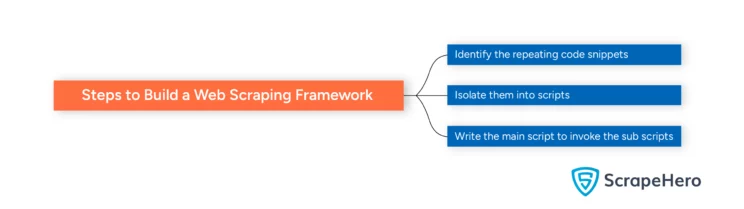
Here are the basic steps to build a web scraping framework:
- Determine the repeating code
- Isolate the code into separate scripts
- Integrate everything into a single script
Determining the Repeating Code
The repeating code can perform any function. A few examples are:
- Getting the HTML source code
- Saving the extracted data
- Handling anti-scraping measures
Isolating the Code
Before isolating the code, you must also consider the variations. For example, there are two methods of getting source code from a website:
- Sending HTTP requests directly from the script
- Using an automated browser to visit the target website and fetch the source code
The framework must allow you to select which method you want to use.
Integrating the Scripts
After isolating the code, you must write a script that integrates everything. Consider these points while integrating:
- The order of execution of the isolated code snippets
- Making changes to the snippets when the user includes a new spider
Python Web Scraping Framework: An Example
The code in this web scraping framework tutorial builds a structured directory with the name of your project. It will consist of four folders:
- grabber: This folder will contain a script that will send HTTP requests with Python requests or use Selenium to get the source code of the target website.
- spiders: The scripts with the core logic of your web scraping project will be inside this folder. They specify how you extract data from the HTML source code.
- saver: This folder will contain the script to call all the spiders and save the extracted data to a JSON file
- scrapings: This folder will contain a single JSON file containing all the extracted data.
Here is the directory structure:
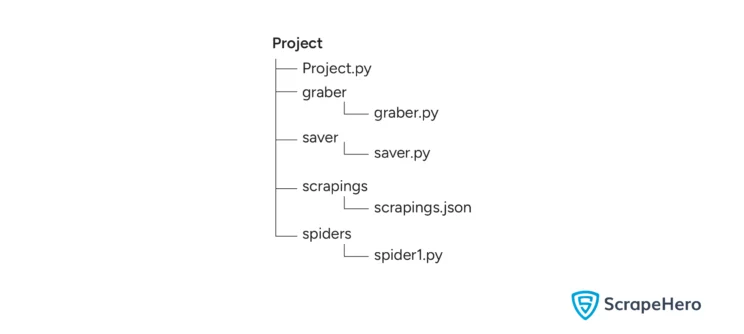
The “scrapings” and “spiders” folders will be empty.
The spider1.py is created when you run the script to create a spider, and scrapings.json is created when the scraping is successful.
The environment
To run the framework script, you don’t need to install anything. The script only uses two modules:
- Argparse
- os
The argparse module allows you to specify the project name as an argument during script execution.
The os module enables you to interact with the operating system. Here, you use it to create folders.
To start scraping, you must install the following packages:
- Python requests: for managing HTTP requests
- Selenium: for automating web browsers
- Beautiful Soup: for parsing HTML source code
You can install them with pip.
pip install requests selenium bs4Python Web Scraping Framework: The Code
As the framework script writes certain boilerplate code; you must include the code in the main script as strings. That is, the code to get HTML code using either Python requests or Selenium will be inside the main script as a string.
When you run the main script, it will create folders and necessary files with the boilerplate code inside it.
Start the main strict with two import statements.
import os
import argparseCreate a function buildAProject() that accepts the name of the project.
Inside it, define three variables:
- folders
- grabberContent
- mainContent
The folders variable
The variable “folders” contains the names of all the folders you need to create.
folders = [
f"{name}/grabber",
f"{name}/spiders",
f"{name}/saver",
f"{name}/scrapings"
]
The grabberContent variable
The variable “grabberContent” holds the code for grabber.py
- The code imports Selenium WebDriver and Python requests
- It accepts a URL and the website type
- If the website type is static, it uses requests to get content. Otherwise, it uses Selenium to get the HTML content.
- In both cases, it returns the HTML code.
grabberContent = f"""
import requests
from selenium import webdriver
def grab(url,type):
headers = {{
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,"
"*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"accept-language": "en-GB;q=0.9,en-US;q=0.8,en;q=0.7",
"dpr": "1",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "none",
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36",
}}
# checking if the website type is static
if type.lower()=="static":
response = requests.get(url,headers=headers)
return response.text
# checking if the website type is dynamic
if type.lower()=="dynamic":
options = webdriver.ChromeOptions()
options.add_argument("--headless")
chrome = webdriver.Chrome(options=options)
chrome.get(url)
return chrome.page_source"""
The mainContent variable
The variable “mainContent” holds the code for the main script, project.py. It is more complicated than the above variable, so let’s approach it in steps.
The code in this variable imports the saver.py (for scraping), json, argparse, and os.
mainContent = f"""
from saver import saver
import json, argparse, osIt has two functions:
- start()
- lay()
The start() function calls unleash() from the saver.py to start scraping. Then, it gets the extracted data and saves it into a JSON file.
def start():
saver.unleash()
data = saver.parsed
with open("scrapings/scrapings.json","w",encoding="utf-8") as scrapeFile:
json.dump(data,scrapeFile,indent=4,ensure_ascii=False)
The lay() function creates spider scripts in the “spiders” folder with the necessary code and updates saver.py.
You need to update the saver.py every time you create a new spider for your project so that saver.py calls all the created spiders.
Each spider
- Uses grabber.py to get the HTML content
- Parses and extracts the required data
- Returns the parsed data
def lay(spiderName,spiderType,spiderUrl):
spiderContent = f\"\"\"
# write your spider's script
from grabber import grabber
def {{spiderName}}():
content = grabber.grab("{{spiderUrl}}","{{spiderType}}")
parsed = []
# add logic to parse your website's HTML code in the variable content
# add the scraped data in the prased as key-value pairs
return parsed
if __name__ == "__main__":
{{spiderName}}()
\"\"\"
with open(f'spiders/{{spiderName}}.py',"a") as spiderFile:
spiderFile.write(spiderContent)
Next, the mainContent() variable will specify how saver.py will be updated.
Whenever a new spider is created, it adds a code snippet to
- Import the spider
- Call that spider and get the extracted data
- Update a dict with the data
# the code for importing the created spider
saverImports = f\"\"\"from spiders import {{spiderName}}\"\"\"
# the code for calling the created spider and updating the dict
saverCalls = f\"\"\"{{spiderName}}Data = {{spiderName}}.{{spiderName}}()
parsed["{{spiderName}}"]={{spiderName}}Data\"\"\"
# reading saver.py
with open("saver/saver.py") as saverFile:
content = saverFile.read()
# Updating the content with the code declared above
content = "\\n".join(content.split("\\n")[2:-2])
content = f\"\"\"parsed = {{{{}}}}\\n
{{saverImports}}
def unleash():
{{content}}
{{saverCalls}}
if __name__==\"__main__\":
unleash()\"\"\" if len(os.listdir("spiders")) == 0 else f\"\"\"parsed ={{{{}}}}\n
{{saverImports}}
{{content}}
{{saverCalls}}
if __name__==\"__main__\":
unleash()\"\"\"
# saving the saver file
with open("saver/saver.py","w") as saverFile:
saverFile.write(content)
Finally, the mainContent() variable contains the code to accept the user’s argument specifying whether to start scraping or create a new spider.
def main():
parser = argparse.ArgumentParser(description="Create a spider")
parser.add_argument('-function',type=str,required=True,help='what do you want to do')
args = parser.parse_args()
if args.function == "lay":
spider = input("Enter the spider name")
sType = input("Dynamic or Static")
url = input("Enter the URL")
lay(spider,sType,url)
elif args.function == "start":
start()
if __name__ == "__main__":
main()
"""You have now declared three strings containing boilerplate code. Now, write the strings to the appropriate files.
Iterate through each item in the folder variable and write the variables declared above as a Python file in the appropriate folders.
- mainContent in the project.py in the main directory of your project.
- grabberContent in the the folder grabber in a file grabber.py
#iterating though the folders variable
for folder in folders:
#making saver folder and writing saver.py
if folder == f"{name}/saver":
os.makedirs(folder,exist_ok=True)
initialFile = os.path.join(folder,f"{folder.split('/')[1]}.py")
with open(initialFile,"w") as f:
f.write(f"# {folder} script")
#making grabber folder and writing grabberContent to grabber.py
elif folder==f"{name}/grabber":
os.makedirs(folder,exist_ok=True)
grabberFile = os.path.join(folder,f"{folder.split('/')[1]}.py")
with open(grabberFile,"w") as f:
f.write(grabberContent)
#making other the folders spiders and scrapings
else:
os.makedirs(folder,exist_ok=True)
#writing mainContent to the main script
main_file = os.path.join(name,f"{name}.py")
with open(main_file,'w') as f:
f.write(mainContent)Finally, write the code to accept arguments from the user specifying the project’s name.
def main():
parser = argparse.ArgumentParser(description="Create a project structure for web scraping.")
parser.add_argument('-project', type=str, required=False, help='The name of the project')
args = parser.parse_args()
buildAProject(args.project)
if __name__ == "__main__":
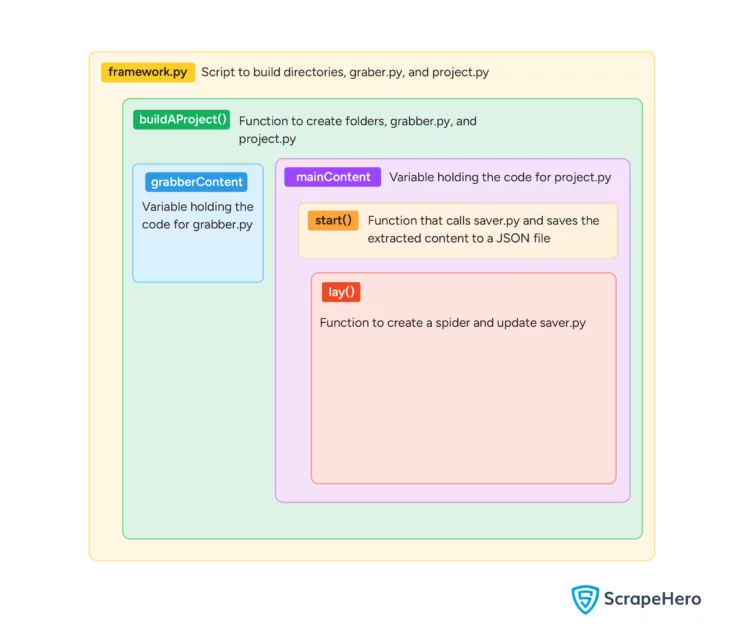
main()Here is a diagram showing the structure of the code.
And here is the complete code
# importing necessary modules
import os
import argparse
# defining the function to build directories and create files
def buildAProject(name):
folders = [
f"{name}/grabber",
f"{name}/spiders",
f"{name}/saver",
f"{name}/scrapings"
]
# code for the grabber.py
grabberContent = f"""# {folder} script
import requests
from selenium import webdriver
def grab(url,type):
headers = {{
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,"
"*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"accept-language": "en-GB;q=0.9,en-US;q=0.8,en;q=0.7",
"dpr": "1",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "none",
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36",
}}
if type.lower()=="static":
response = requests.get(url,headers=headers)
return response.text
if type.lower()=="dynamic":
options = webdriver.ChromeOptions()
options.add_argument("--headless")
chrome = webdriver.Chrome(options=options)
chrome.get(url)
return chrome.page_source"""
# code for the main script
mainContent = f"""
# {name} main script
from saver import saver
import json, argparse, os
# function to start scraping
def start():
saver.unleash()
data = saver.parsed
with open("scrapings/scrapings.json","w",encoding="utf-8") as scrapeFile:
json.dump(data,scrapeFile,indent=4,ensure_ascii=False)
# function to create a spider
def lay(spiderName,spiderType,spiderUrl):
spiderContent = f\"\"\"
# write your spider's script
from grabber import grabber
def {{spiderName}}():
content = grabber.grab("{{spiderUrl}}","{{spiderType}}")
parsed = []
# add logic to parse your website's HTML code in the variable content
# add the scraped data in the prased as key-value pairs
return parsed
if __name__ == "__main__":
{{spiderName}}()
\"\"\"
# updating saver.py
saverImports = f\"\"\"from spiders import {{spiderName}}\"\"\"
saverCalls = f\"\"\"{{spiderName}}Data = {{spiderName}}.{{spiderName}}()
parsed["{{spiderName}}"]={{spiderName}}Data\"\"\"
with open("saver/saver.py") as saverFile:
content = saverFile.read()
content = "\\n".join(content.split("\\n")[2:-2])
content = f\"\"\"parsed = {{{{}}}}\\n
{{saverImports}}
def unleash():
{{content}}
{{saverCalls}}
if __name__==\"__main__\":
unleash()\"\"\" if len(os.listdir("spiders")) == 0 else f\"\"\"parsed ={{{{}}}}\n
{{saverImports}}
{{content}}
{{saverCalls}}
if __name__==\"__main__\":
unleash()\"\"\"
with open("saver/saver.py","w") as saverFile:
saverFile.write(content)
with open(f'spiders/{{spiderName}}.py',"a") as spiderFile:
spiderFile.write(spiderContent)
def main():
parser = argparse.ArgumentParser(description="Create a spider")
parser.add_argument('-function',type=str,required=True,help='what do you want to do')
args = parser.parse_args()
if args.function == "lay":
spider = input("Enter the spider name")
sType = input("Dynamic or Static")
url = input("Enter the URL")
lay(spider,sType,url)
elif args.function == "start":
start()
if __name__ == "__main__":
main()
"""
# creating folders and files
for folder in folders:
if folder == f"{name}/saver":
os.makedirs(folder,exist_ok=True)
initialFile = os.path.join(folder,f"{folder.split('/')[1]}.py")
with open(initialFile,"w") as f:
f.write(f"# {folder} script")
elif folder==f"{name}/grabber":
os.makedirs(folder,exist_ok=True)
grabberFile = os.path.join(folder,f"{folder.split('/')[1]}.py")
with open(grabberFile,"w") as f:
f.write(grabberContent)
else:
os.makedirs(folder,exist_ok=True)
main_file = os.path.join(name,f"{name}.py")
with open(main_file,'w') as f:
f.write(mainContent)
def main():
parser = argparse.ArgumentParser(description="Create a project structure for web scraping.")
parser.add_argument('-project', type=str, required=False, help='The name of the project')
args = parser.parse_args()
buildAProject(args.project)
if __name__ == "__main__":
main()
Using the Script
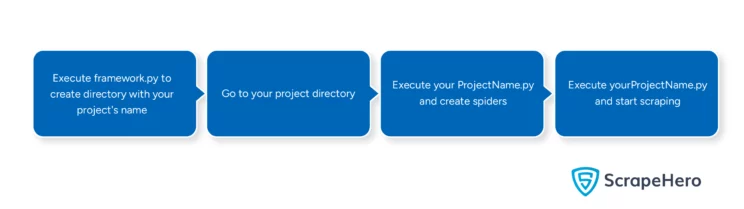
To use the script,
- Save the script as framework.py
- Run framework.py while in the same directory as the script
python framework.py -project yourProjectName - Go to your project directory
cd yourProjectName - Create a spider using this code and then enter the spider details
- Name
- Static or Dynamic
- URL
python yourProjectName.py -function lay - Update yourSpiderName.py
- Start scraping
python yourProjectName.py -function start
Limitations of the Framework
The code only scratches the surface of what a web scraping framework could be.
- The code does not bypass anti-scraping measures, like proxies or user agent rotation, to scrape without getting blocked.
- It is not scalable because you can’t create multiple spiders quickly.
- There are no options for concurrency or parallelism while web scraping.
- The code does not allow you to control the web scraping speed globally. You have to do that individually for each spider.
Wrapping Up
You can definitely build a Python web scraping framework, but it requires immense planning and a lot of coding. The efficient method would be to build on an existing Python framework for web scraping.
However, if you are only concerned with data, why waste your valuable time in coding? Contact ScrapeHero now.
ScrapeHero is a full-service web scraping service provider. We can build enterprise-grade web scrapers customized to your specifications. ScrapeHero services also include product and brand monitoring and custom robotic process automation.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data



