

This article explains Redfin data scraping methods. This process effectively exports Redfin data to Excel or other formats for easier access and use.
There are three methods to scrape Redfin data:
- Redfin data scraping with coding:Building a web scraper in Python or JavaScript
- Redfin data scraping without coding:Using the ScrapeHero Cloud’s Redfin Scraper, a no-code scraping tool
ScrapeHero Cloud offers you ready-made web crawlers and real-time APIs, which are the easiest way to extract data from websites and download it into spreadsheets with a few clicks.

Build a Redfin Data Scraper in Python/JavaScript
In this section, we will guide you on how to scrape Redfin using either Python or JavaScript. We will utilize the browser automation framework called Playwright to emulate browser behavior in our code.
One of the key advantages of this approach is its ability to bypass common blocks often put in place to prevent scraping. However, familiarity with the Playwright API is necessary to use it effectively.
Here are the steps to scrape Redfin data using Playwright:
Step 1: Choose either Python or JavaScript as your programming language.
Step 2: Install Playwright for your preferred language:
Python
pip install playwright
# to download the necessary browsers
playwright installJavaScript
npm install playwright@latest
Step 3: Write your code to emulate browser behavior and extract the desired data from Redfin using the Playwright API. You can use the code provided below:
Python
import asyncio
import json
from playwright.async_api import async_playwright
location = "Washington, DC"
max_pagination = 2
async def extract_data(page, selector) -> list:
"""
Parsing details from the listing page
Args:
page: webpage of the browser
selector: selector for the div containing property details
Returns:
list: details of homes for sale
"""
# Initializing selectors and xpaths
next_page_selector = "[data-rf-test-id='react-data-paginate-next']"
price_selector = "[class='homecardV2Price']"
specification_selector = "[class='HomeStatsV2 font-size-small ']"
address_selector = "[class='homeAddressV2']"
# List to save the details of properties
homes_for_sale = []
# Paginating through each page
for _ in range(max_pagination):
# Waiting for the page to finish loading
await page.wait_for_load_state("load")
# Extracting the elements
all_visible_elements = page.locator(selector)
all_visible_elements_count = await all_visible_elements.count()
for index in range(all_visible_elements_count):
# Hovering the element to load the price
inner_element = all_visible_elements.nth(index=index)
await inner_element.hover()
inner_element = all_visible_elements.nth(index=index)
# Extracting necessary data
price = await inner_element.locator(price_selector).inner_text() if await inner_element.locator(price_selector).count() else None
specifications = await inner_element.locator(specification_selector).inner_text() if await inner_element.locator(specification_selector).count() else None
address = await inner_element.locator(address_selector).inner_text() if await inner_element.locator(address_selector).count() else None
# Removing extra spaces and unicode characters
price = clean_data(price)
specifications = clean_data(specifications)
address = clean_data(address)
data_to_save = {
"price": price,
"specifications": specifications,
"address": address,
}
homes_for_sale.append(data_to_save)
next_page = page.locator(next_page_selector)
await next_page.hover()
if not await next_page.count():
break
# Clicking the next page button
await next_page.click()
save_data(homes_for_sale, "Data.json")
async def run(playwright) -> None:
# Initializing the browser and creating a new page.
browser = await playwright.firefox.launch(headless=False)
context = await browser.new_context()
page = await context.new_page()
await page.set_viewport_size({"width": 1920, "height": 1080})
page.set_default_timeout(120000)
# Navigating to the homepage
await page.goto("https://www.Redfin.com/", wait_until="domcontentloaded")
await page.wait_for_load_state("load")
await page.wait_for_load_state(timeout=60000)
# Initializing the xpath and selector
xpath_search_box = "[placeholder='City, Address, School, Agent, ZIP']"
listing_div_selector = "[class='bottomV2 ']"
# Clicking the input field to enter the location and navigating to the listing page
await page.locator(xpath_search_box).click()
await page.locator(xpath_search_box).fill(location)
await page.locator(xpath_search_box).press("Enter")
# Waiting until the list of properties is loaded
await page.wait_for_selector(listing_div_selector)
await extract_data(page, listing_div_selector)
await context.close()
await browser.close()
def clean_data(data: str) -> str:
"""
Cleaning data by removing extra white spaces and Unicode characters
Args:
data (str): data to be cleaned
Returns:
str: cleaned string
"""
if not data:
return ""
cleaned_data = " ".join(data.split()).strip()
cleaned_data = cleaned_data.encode("ascii", "ignore").decode("ascii")
return cleaned_data
def save_data(product_page_data: list, filename: str):
"""Converting a list of dictionaries to JSON format
Args:
product_page_data (list): details of each product
filename (str): name of the JSON file
"""
with open(filename, "w") as outfile:
json.dump(product_page_data, outfile, indent=4)
async def main() -> None:
async with async_playwright() as playwright:
await run(playwright)
if __name__ == "__main__":
asyncio.run(main())
JavaScript
const { chromium, firefox } = require('playwright');
const fs = require('fs');
const location = "Washington,DC";
const maxPagination = 2;
/**
* Save data as list of dictionaries
as json file
* @param {object} data
*/
function saveData(data) {
let dataStr = JSON.stringify(data, null, 2)
fs.writeFile("DataJS.json", dataStr, 'utf8', function (err) {
if (err) {
console.log("An error occurred while writing JSON Object to File.");
return console.log(err);
}
console.log("JSON file has been saved.");
});
}
function cleanData(data) {
if (!data) {
return;
}
// removing extra spaces and unicode characters
let cleanedData = data.split(/\s+/).join(" ").trim();
cleanedData = cleanedData.replace(/[^\x00-\x7F]/g, "");
return cleanedData;
}
/**
* The data extraction function used to extract
necessary data from the element.
* @param {HtmlElement} innerElement
* @returns
*/
async function extractData(innerElement) {
async function extractData(data) {
let count = await data.count();
if (count) {
return await data.innerText()
}
return null
};
// initializing xpath and selectors
priceSelector = "[class='homecardV2Price']"
specificationSelector = "[class='HomeStatsV2 font-size-small ']"
addressSelector = "[class='homeAddressV2']"
// Extracting necessary data
let price = innerElement.locator(priceSelector);
price = await extractData(price);
let specifications = innerElement.locator(specificationSelector);
specifications = await extractData(specifications);
let address = innerElement.locator(addressSelector);
address = await extractData(address)
// cleaning data
price = cleanData(price)
specifications = cleanData(specifications)
address = cleanData(address)
extractedData = {
"price": price,
"specifications":specifications,
'address': address
}
console.log(extractData)
return extractedData
}
/**
* The main function initiates a browser object and handles the navigation.
*/
async function run() {
// initializing browser and creating new page
const browser = await chromium.launch({ headless: false});
const context = await browser.newContext();
const page = await context.newPage();
// initializing xpaths and selectors
const xpathSearchBox = "[placeholder='City, Address, School, Agent, ZIP']";
const listingDivSelector = "[class='bottomV2 ']";
const xpathNextPage = "[data-rf-test-id='react-data-paginate-next']";
// Navigating to the home page
await page.goto('https://www.Redfin.com/', {
waitUntil: 'domcontentloaded',
timeout: 60000,
});
// Clicking the input field to enter the location
await page.waitForSelector(xpathSearchBox, { timeout: 60000 });
await page.click(xpathSearchBox);
await page.fill(xpathSearchBox, location);
await page.keyboard.press('Enter');
// Wait until the list of properties is loaded
await page.waitForSelector(listingDivSelector);
// to store the extracted data
let data = [];
// navigating through pagination
for (let pageNum = 0; pageNum < maxPagination; pageNum++) {
await page.waitForLoadState("load", { timeout: 120000 });
await page.waitForTimeout(10);
let allVisibleElements = page.locator(listingDivSelector);
allVisibleElementsCount = await allVisibleElements.count()
// going through each listing element
for (let index = 0; index < allVisibleElementsCount; index++) {
await page.waitForTimeout(2000);
await page.waitForLoadState("load");
let innerElement = await allVisibleElements.nth(index);
await innerElement.hover();
innerElement = await allVisibleElements.nth(index);
let dataToSave = await extractData(innerElement);
data.push(dataToSave);
};
//to load next page
let nextPage = page.locator(xpathNextPage);
await nextPage.hover();
if (await nextPage.count()) {
await nextPage.click();
}
else { break };
};
saveData(data);
await context.close();
await browser.close();
};
run();This code shows how to scrape Redfin using the Playwright library in Python and JavaScript.
The corresponding scripts have two main functions, namely:
- run function: This function takes a Playwright instance as an input and performs the scraping process. The function launches a Chromium browser instance, navigates to Redfin, fills in a search query, clicks the search button, and waits for the results to be displayed on the page.
The data_to_save function is then called to extract the listing details and store the data in a data.json file. - data_to_save function: This function takes a Playwright page object as input and returns a list of dictionaries containing listing details. The details include each listing’s price, specifications and address.
Finally, the main function uses the async_playwright context manager to execute the run function. A JSON file containing the listings of the Redfin script you just executed would be created.
Step 4: Run your code and collect the scraped data from Redfin.
Using No-Code Redfin Scraper by ScrapeHero Cloud
The Redfin Scraper by ScrapeHero Cloud is a convenient method for scraping real estate data, and it provides an easy, no-code method for extracting housing data.
This makes it accessible to users with limited technical skills, as you can scrape data from Redfin without code.
This section will guide you through the steps to set up and use the Redfin scraper.
1. Sign up or log in to your ScrapeHero Cloud account.
2. Go to the Redfin Scraper by ScrapeHero Cloud.
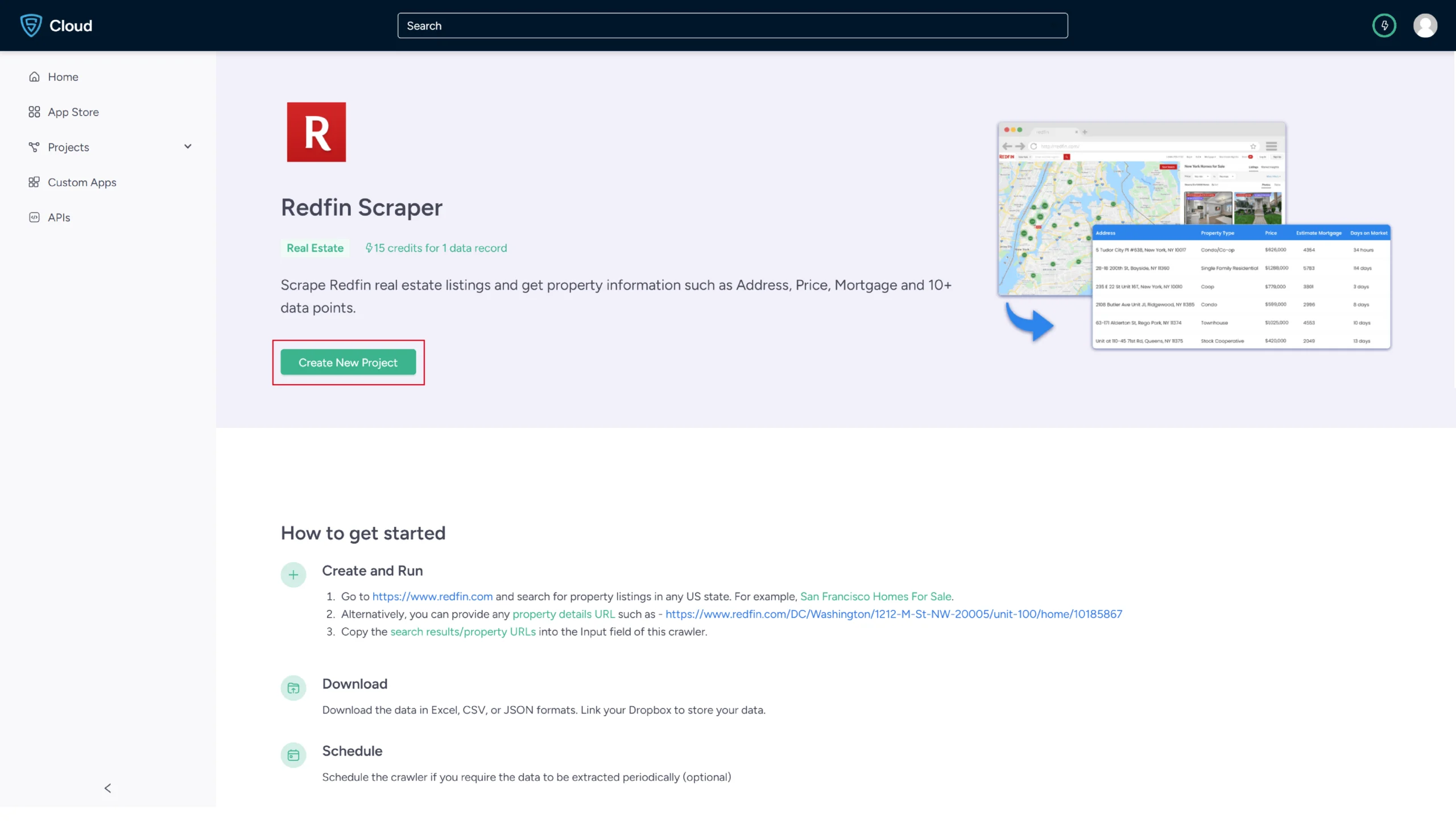
3. Click the Create New Project button.
4. You need to add the search results URL for a particular location to start the scraper.
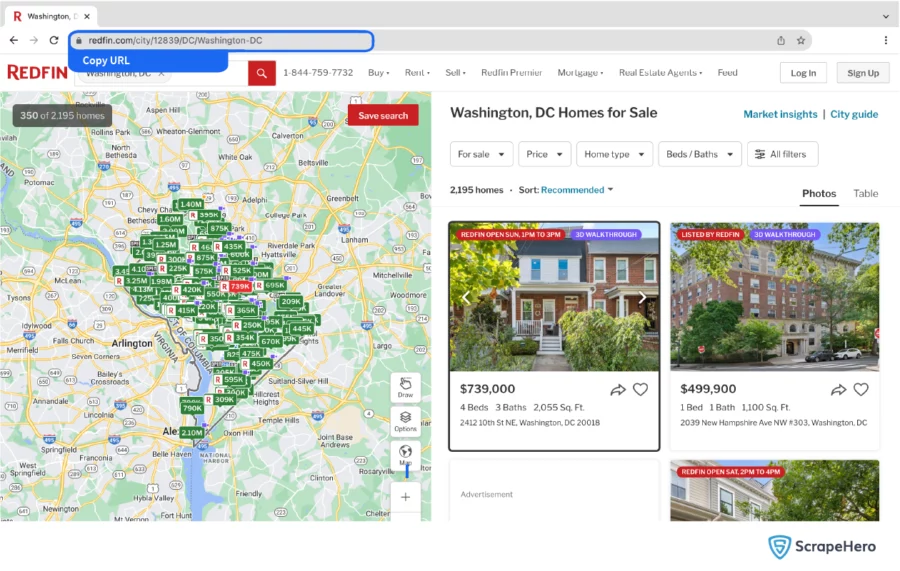
For instance, if you have to scrape all the listings from Washington, DC copy the URL:
5. In the field provided, enter a project name, the search result URL, and the maximum number of records you want to gather. Then click Gather Data.
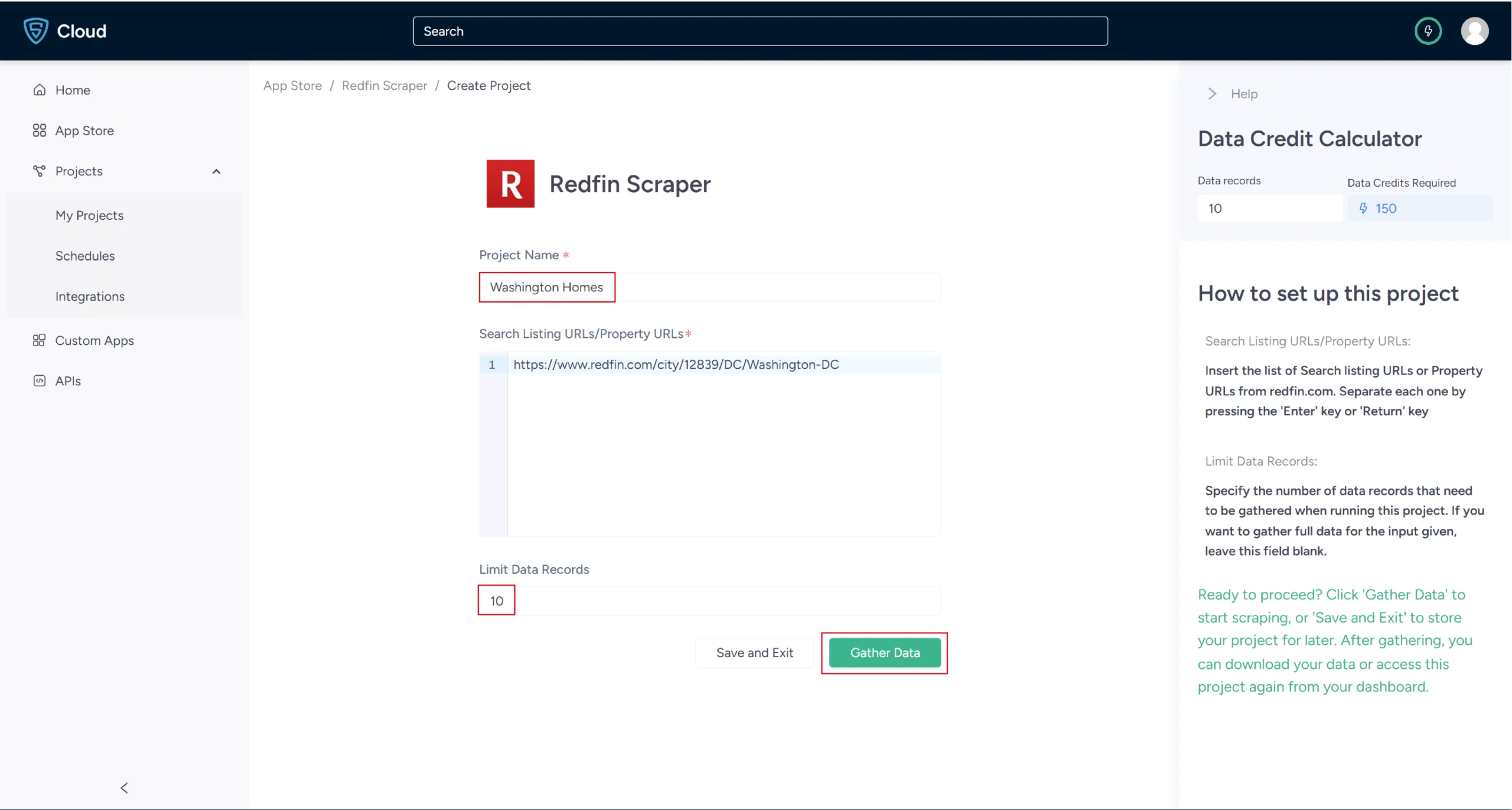
6. The scraper will start fetching data for your queries, and you can track its progress under the Projects tab.
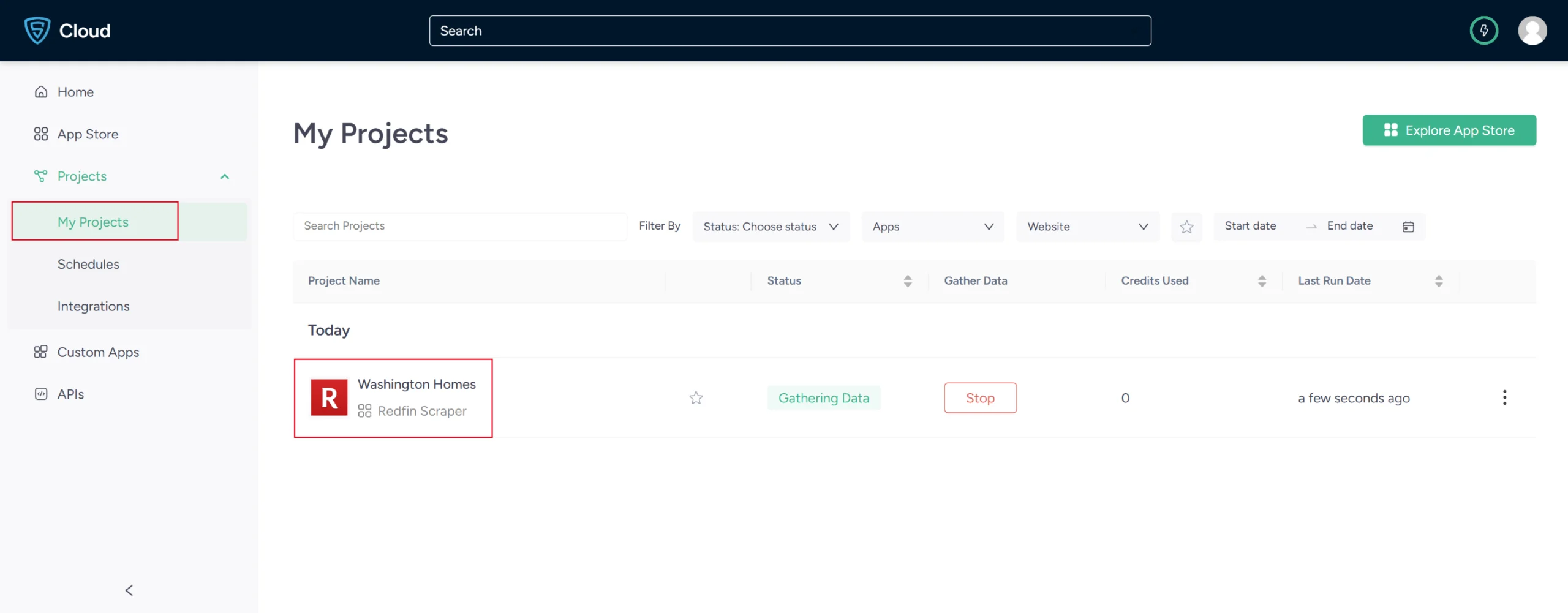
7. Once it is finished, you can view the data by clicking on the project name. A new page will appear, and under the Overview tab, you can see and download the data.
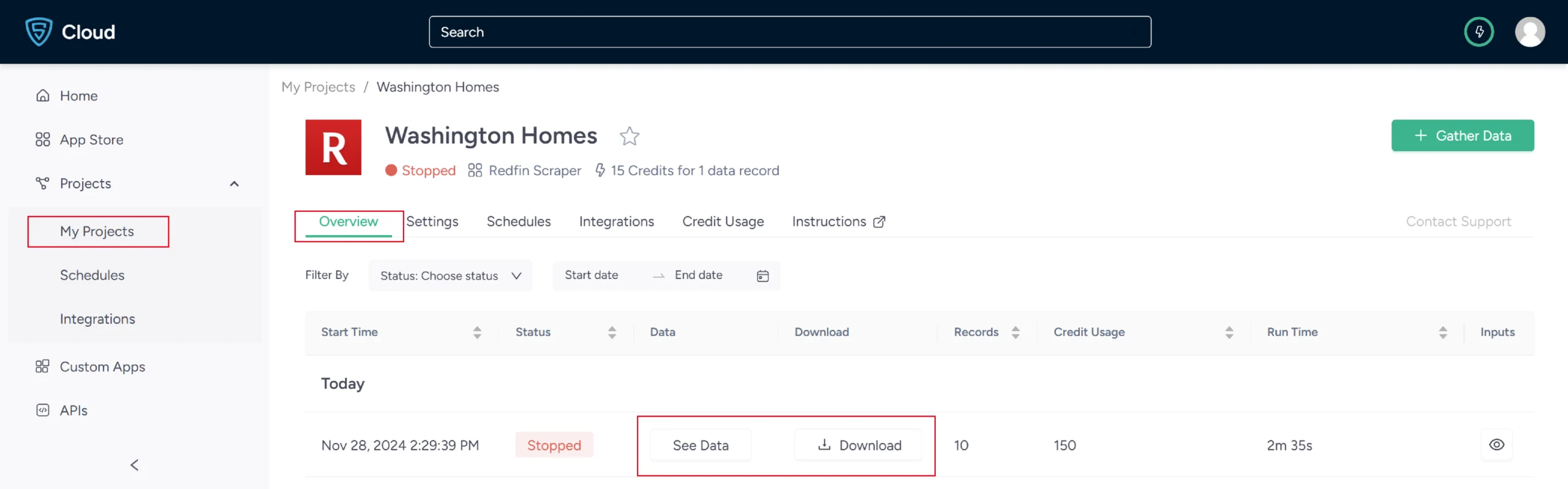
8. You can also pull Redfin data into a spreadsheet from here. Just click on Download Data, select Excel, and open the downloaded file using Microsoft Excel.
Scraping data from Redfin without code provides a simple way to access the information you need without any technical complexity.
Uses Cases of Redfin Data
If you’re unsure as to why you should scrape Redfin, here are a few use cases where this data would be helpful:
-
Real-Time Price Assessment
Redfin data enables the collection of historical factors such as the age, condition, and location of properties.
This supports price monitoring by helping both buyers and sellers access dynamic pricing models, making their decisions more accurate and timely.
-
Efficient Buyer-Seller Pairing
Utilize Redfin’s database to align buyers with properties that match their criteria, like budget and desired location. This targeted approach conserves time and resources for real estate professionals.
-
Pulse on Market Trends
Redfin data, when combined with location intelligence reports, can reveal emerging popular neighborhoods, essential amenities, and the impact of demographics on property values. Businesses can adapt more rapidly to market changes by staying informed.
-
Predictive Investment and Development
Scraping Redfin helps identify patterns influenced by factors like local policies and economic conditions. This predictive analysis enables investors and developers to focus on areas with growth potential.
-
Cost-Effective Construction
Data from Redfin allows real estate companies to manage land acquisition and construction expenses smartly. Insight into property and material costs leads to better financial decisions in development projects.
Frequently Asked Questions
Redfin scraping means real estate data scraping or data extracting from Redfin.com, including property details, to support real estate analysis and decision-making.
The legality of web scraping depends on the legal jurisdiction, i.e., laws specific to the country and the locality. Gathering or scraping publicly available information is not illegal.
Please refer to our Legal Information page to learn more about the legality of web scraping.
ScrapeHero provides a comprehensive pricing plan for both Scrapers and APIs. To know more about the pricing, visit our pricing page.
To avoid getting blocked during web scraping Redfin, it is better to use rotating proxies, randomize request intervals, and implement CAPTCHAs-solving methods.
You can use tools like BeautifulSoup and Selenium to scrape Redfin, combined with rotating proxies for anonymity. A better way is to use ScrapeHero Redfin Scraper.
While scraping Redfin, use delay tactics (e.g., sleep between requests), rotate IP addresses, and monitor for rate-limiting headers to avoid getting blocked.
To extract property details from Redfin, you should target specific HTML elements like property-listing for prices, addresses, and amenities; use XPath or CSS selectors.
Before analyzing, clean the data with Python libraries (Pandas, NumPy), and visualize it with tools such as Tableau to gain deeper insights.



