

You must’ve noticed a profile section on the right when you search for a company name on Google. It is the knowledge panel; this section contains information about the company, such as website, CEO, stock price, etc. These details come from the Google Knowledge Graph.
Here, you will explore how to scrape the details from these profiles with Python. You will use external Python libraries for web scraping.
The Google Knowledge Panel vs. Google Business Profile
To clarify, this tutorial discusses company information from knowledge panels and not Google Business Profiles (formerly Google My Business). They are slightly different:
- Google automatically generates the company information in the knowledge panels; however, companies must manually create their Google Business Profiles.
- Google Business Profiles must have an exact location on Google Maps, but the Google knowledge panel may not have an exact location.
- The Google knowledge panels may contain any information depending on the search; Google Business Profiles only contain business information.
Why Scrape company profiles from the Google Knowledge Panels?
Scraping company information from knowledge panels lets you quickly gather information on several companies, which will help you:
- Understand partnership opportunities to grow your business
- Make informed decisions to keep up with your competitors
- Evaluate the company’s online presence to develop content marketing strategies
Set Up the Web Scraping Environment
In this tutorial, we’ll use Python and two third-party modules for web scraping:
- Requests: This Python module has functions for you to make requests to the Google server and accept the response. The request will include the search URL and the company name, and the response will include the company details.
- Lxml: This module understands XML/HTML code; hence, you can use it to extract the required information. You can use the path-like XPath syntax to specify the element’s location.

Install Third-Party Packages
You must have the pip package installed on your system; it enables you to install the modules mentioned above.
After that, execute the codes below to install the package:
pip install lxml
pip install requests
The Web Scraping Code
The first step is to import the modules by writing the import statements below.
import csv
import requests
from lxml import HTMLThe CSV module is a built-in library; you can use this module to handle CSV files. We will use this module to write the scraped company details into a CSV file.
For every name in the company list, the code performs two tasks:
- Send a request to the search engine with a search term and retrieve the HTML response containing the company details.
- Extract data from the response and save it as an object in an array.
There are two separate functions to do the above tasks: get_response() and extract_data(). You can read about them in the next section.
Finally, the function scrape_data() will save the array into a CSV file after the code goes through all the names in the list.
Refer to the flowchart below to get the idea.
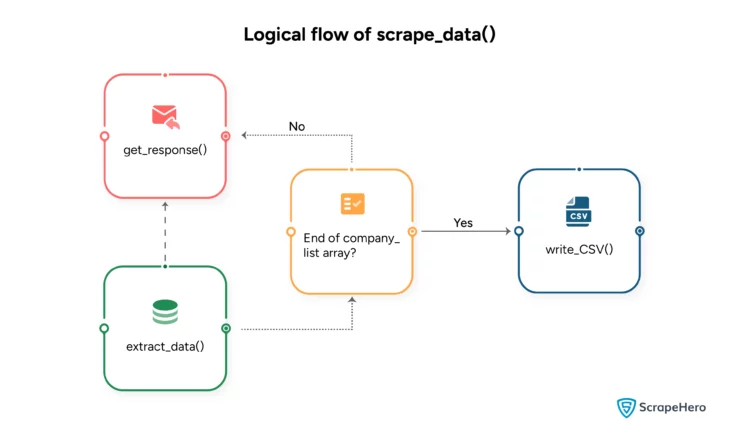
Core Steps in Scraping Company Details from Google Knowledge Panel
- Retrieve HTML Response: get_response()
In this step, you set up the headers, send a request, and verify whether it was successful.
You can read the process below:- Define the headers: These headers tell the server the request is from a web browser. They also specify additional details, including the language and the type of the response.
- Define the search URL: The URL tells the request module where to send the request. It also includes the company name.
- Send the request: Use the Python requests module to send the HTTP request.
- Verify the response: Check the status code. If it is 200, the request was successful. Otherwise, retry it. However, It’s better to have a retry limit so the program does not run indefinitely. This code has a limit of three retries; then, it jumps to the next company name.
def get_response(company_name: str) -> requests.Response: headers = { "accept": "text/html,application/xhtml+xml," "application/xml;q=0.9,image/webp,image/apng," "*/*;q=0.8,application/signed-exchange;v=b3;q=0.9", "accept-language": "en-GB;q=0.9,en-US;q=0.8,en;q=0.7", "dpr": "1", "sec-fetch-dest": "document", "sec-fetch-mode": "navigate", "sec-fetch-site": "none", "sec-fetch-user": "?1", "upgrade-insecure-requests": "1",3 "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) " "AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36", } search_url = ( f"https://www.google.com/search?q={company_name}&sourceid=chrome&ie=UTF-8" ) # Retrying 3 times if status code is not 200 for retry in range(3): response = requests.get(search_url, headers=headers) if response.status_code == 200: return response
- Extract data from HTML response: extract_data()
This function will extract the data from the response. The image below illustrates the extracted data points. They are:- Company Name
- Company Type
- Website
- Description
- CEO
- Stock Price
- Founded (year and place)
- Headquarters
- Number of employ

parser = lxml.html.fromstring(response.text)
company_name_raw = parser.xpath('//div[contains(@class, "kp-wholepage")]//*[@data-attrid="title"]//text()')
company_name = company_name_raw[0] if company_name_raw else NoneWe use the ‘lxml’ library to create an HTML parser and extract the company name with a suitable XPath expression.
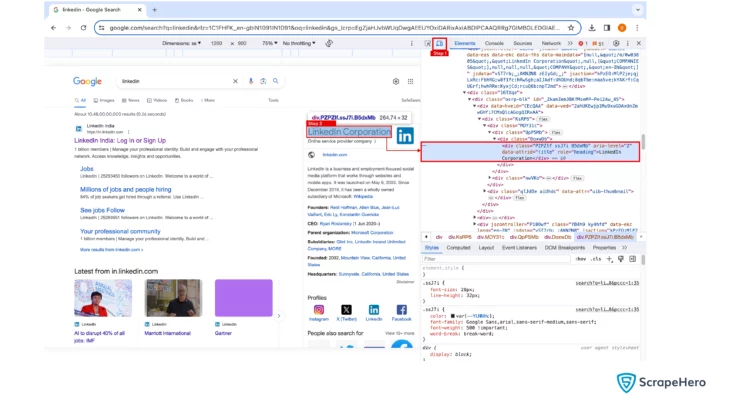
These XPath expressions require attributes to pinpoint the data. To get these attributes:
- Right-click on the web page and choose the inspect option to open developer options.
- Click on the diagonal arrow icon on the top left corner of the developer option pane.
- Click on the element whose attribute you need.
Refer to the image below:
The values in the response may be in a different format. Moreover, the companies may have only some of the information. Therefore, you may have to perform additional operations to extract the required data. That is why the code first stores data in the company_name_raw variable. Only after some operations it stores the result in the company_name variable.
This operation is different for each detail; you must analyze the response to figure it out. In this situation, the response gives an array. The value in its first index is the company name.
You can extract the rest of the company details with the code below.
def extract_company_details(response: requests.Response) -> dict:
parser = html.fromstring(response.text)
company_name_raw = parser.xpath(
'//div[contains(@class, "kp-wholepage")]//*[@data-attrid="title"]//text()'
)
company_name = company_name_raw[0] if company_name_raw else None
company_type_raw = parser.xpath(
'//div[contains(@class, "kp-wholepage")]//div[@data-attrid="subtitle"]//text()'
)
company_type = company_type_raw[0] if company_type_raw else None
website_raw = parser.xpath(
'//div[contains(@class, "kp-wholepage")]//a[@data-attrid="visit_official_site"]//@href'
)
website = website_raw[0] if website_raw else None
description_raw = parser.xpath('//div[@class="kno-rdesc"]//span/text()')
description = description_raw[0] if description_raw else None
stock_price_raw = parser.xpath(
'//div[@data-attrid="kc:/business/issuer:stock quote"]//text()'
)
stock_price = (
"".join(stock_price_raw)
.replace("Stock price:", "")
.replace("\u202f", "")
.strip()
if stock_price_raw
else None
)
ceo_raw = parser.xpath(
'//div[@data-attrid="kc:/organization/organization:ceo"]//a[@class="fl"]//text()'
)
ceo = "".join(ceo_raw).replace("CEO", "").strip() if ceo_raw else None
founder_raw = parser.xpath(
'//div[@data-attrid="kc:/business/business_operation:founder"]//text()'
)
founder = (
"".join(founder_raw).replace("Founders:", "").replace("Founder:", "").strip()
if founder_raw
else None
)
founded_raw = parser.xpath(
'//div[@data-attrid="kc:/organization/organization:founded"]//text()'
)
founded = (
"".join(founded_raw).replace("Founded:", "").strip() if founded_raw else None
)
headquarters_raw = parser.xpath(
'//div[@data-attrid="kc:/organization/organization:headquarters"]//text()'
)
headquarters = (
"".join(headquarters_raw).replace("Headquarters:", "").strip()
if headquarters_raw
else None
)
employees_raw = parser.xpath(
'//div[@data-attrid="ss:/webfacts:number_of_employe"]//text()'
)
num_of_employees = (
"".join(employees_raw).replace("Number of employees:", "").strip()
if employees_raw
else None
)
company_details = {
"company_name": company_name,
"company_type": company_type,
"website": website,
"description": description,
"stock_price": stock_price,
"ceo": ceo,
"founder": founder,
"founded": founded,
"headquarters": headquarters,
"number_of_employees": num_of_employees,
}
return company_detailsAfter the extraction, the code stores the details as an object company_details.
Integrate the functions
The function scrape_data() combines the previous two functions and the function write_csv().
scrape_data() has three tasks:
- Get response: For each company name, call get_response()
- Extract Data: call extract_data() to retrieve data and then save the data to an array.
- Write to CSV: call write_csv() to write extracted data to a CSV file.
def write_csv(file_name: str, company_details_list: list):
# Writing scraped data to CSV file
with open(file_name, 'w') as fp:
fieldnames = company_details_list[0].keys()
writer = csv.DictWriter(fp, fieldnames=fieldnames)
writer.writeheader()
for data in company_details_list:
writer.writerow(data)
def scrape_data(input_company_names: list, output_file: str):
company_details_list = []
for company in input_company_names:
response = get_response(company)
if not response:
print(f'Invalid response for company name {company}')
continue
company_details = extract_company_details(response)
company_details['input_company_name'] = company
company_details_list.append(company_details)
write_csv(output_file, company_details_list)
Combining Everything
You only have to call the scrape_data() function to start the program. This function takes two arguments,
- company_names: an array with the list of companies you want to scrape
- output_file_name: a string
if __name__ == "__main__":
company_names = ['Amazon', 'Kroger', 'Walgreens', 'Rockstar', 'Ebay']
output_file_name = 'company_details.csv'
scrape_data(company_names, output_file_name)Read the complete code: https://github.com/scrapehero-code/google-company-search/blob/main/scraper.py
Conclusion
This process converts unstructured web content into useful information. The scraped data can help you analyze markets, research competitors, and make data-driven decisions.
Want a no-code solution? Try the hassle-free ScrapeHero Google Search Scraper to extract data from the Google knowledge panel. This ScrapeHero web scraper can get company details from the knowledge panel and the search results for free. Or, If you want to get details of local businesses, try Google Maps Scraper.
Moreover, the tutorial’s code is unsuitable for bigger tasks. If you want a large-scale solution, try ScrapeHero services. ScrapeHero is a full-service web scraping solutions provider. We can create enterprise-grade scrapers to meet your specific needs.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data



