

Struggling to efficiently gather product data from major retailers like BestBuy? Keep reading. This article shows two methods to scrape BestBuy data: a no-code method and a code-based method.
The no-code method uses ScrapeHero Cloud and the code-based method uses Python Playwright.
Let’s start.

Using the No-Code BestBuy Scraper from ScrapeHero Cloud
For a maintenance-free solution to extract data from BestBuy, ScrapeHero Cloud offers a no-code platform. This platform allows you to extract data from BestBuy without any programming knowledge, infrastructure setup, or ongoing maintenance.
Follow these steps to get started with ScrapeHero Cloud for free:
1. Log in to your ScrapeHero Cloud account

2. Navigate to the BestBuy Scraper in the Scrapehero App store
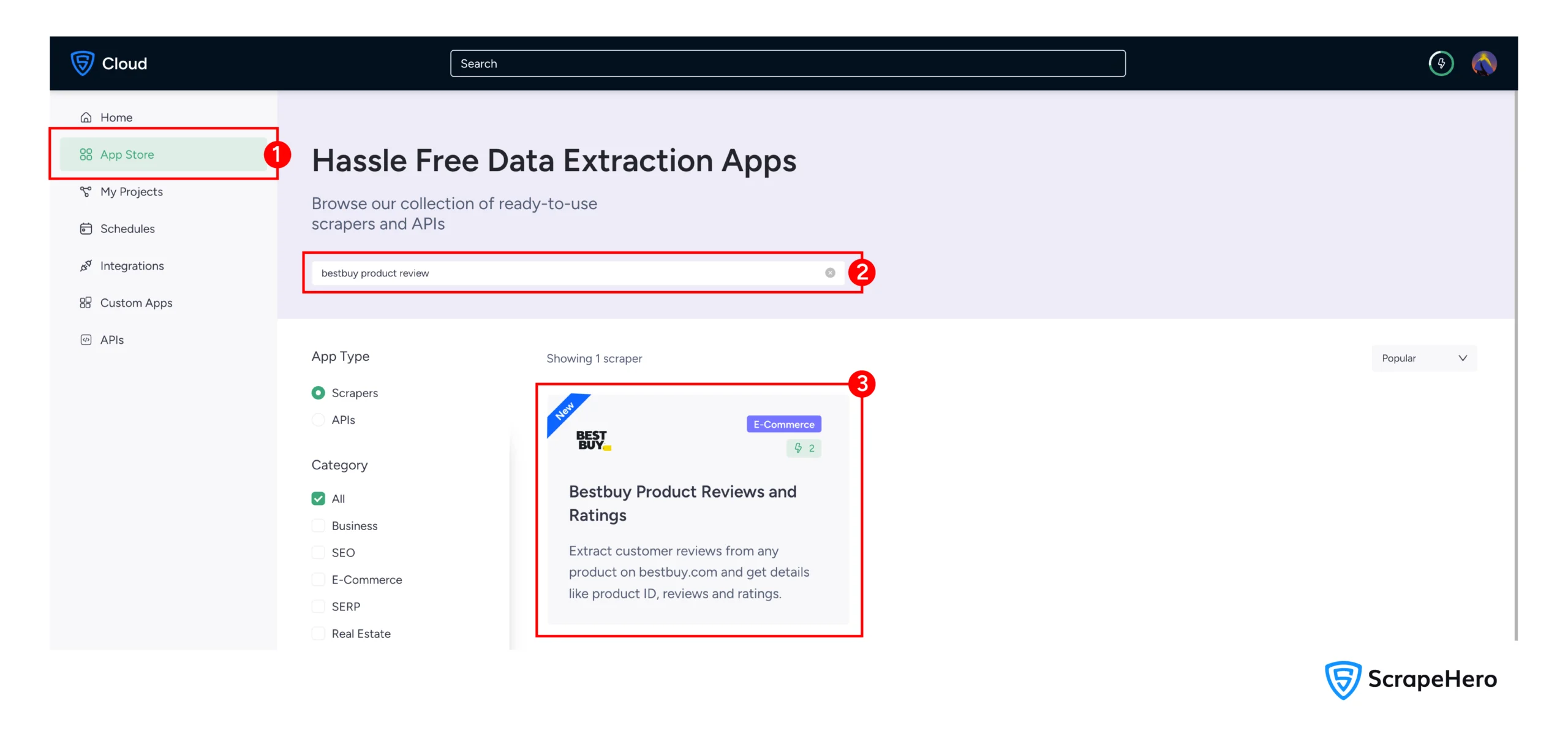
3. Click on “Create New Project”
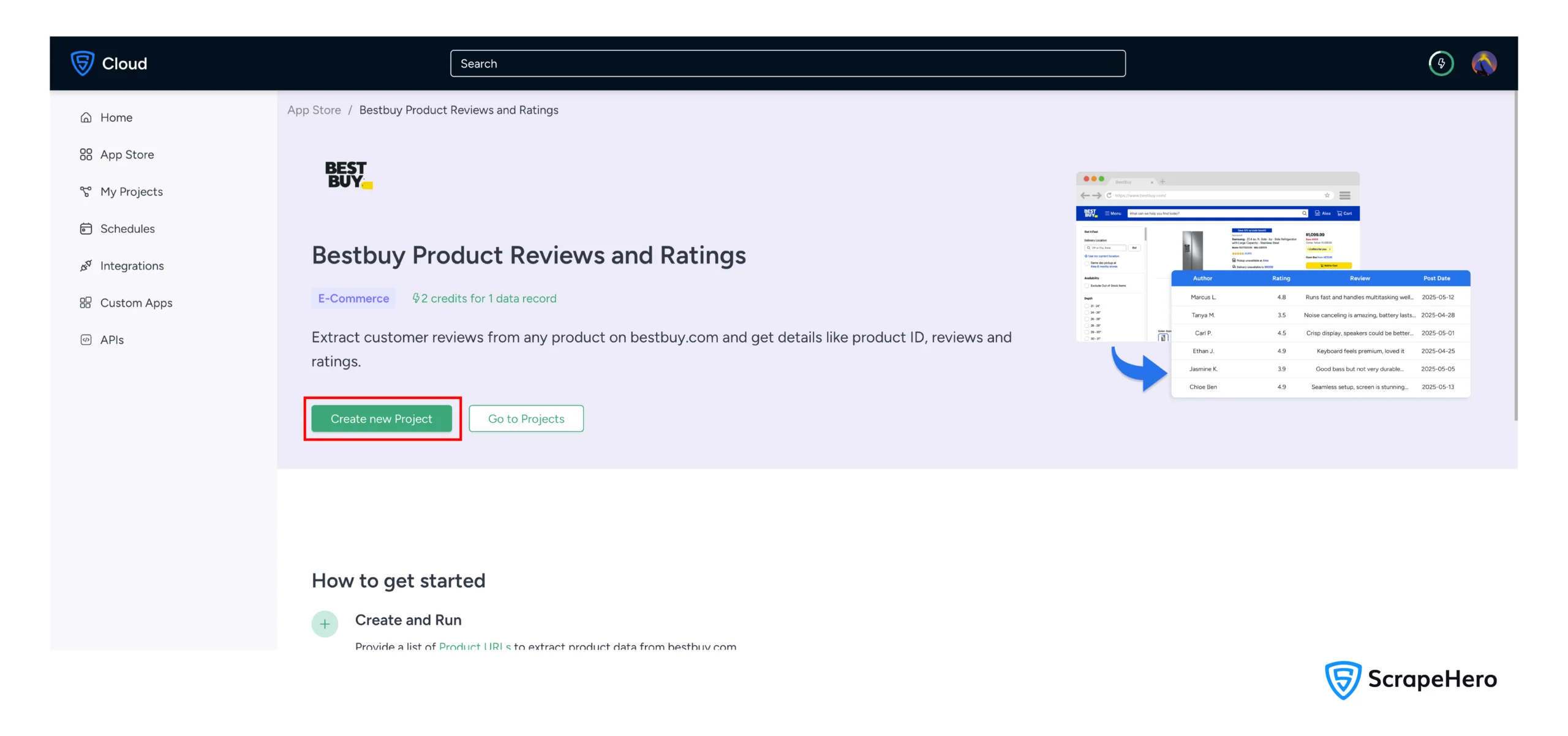
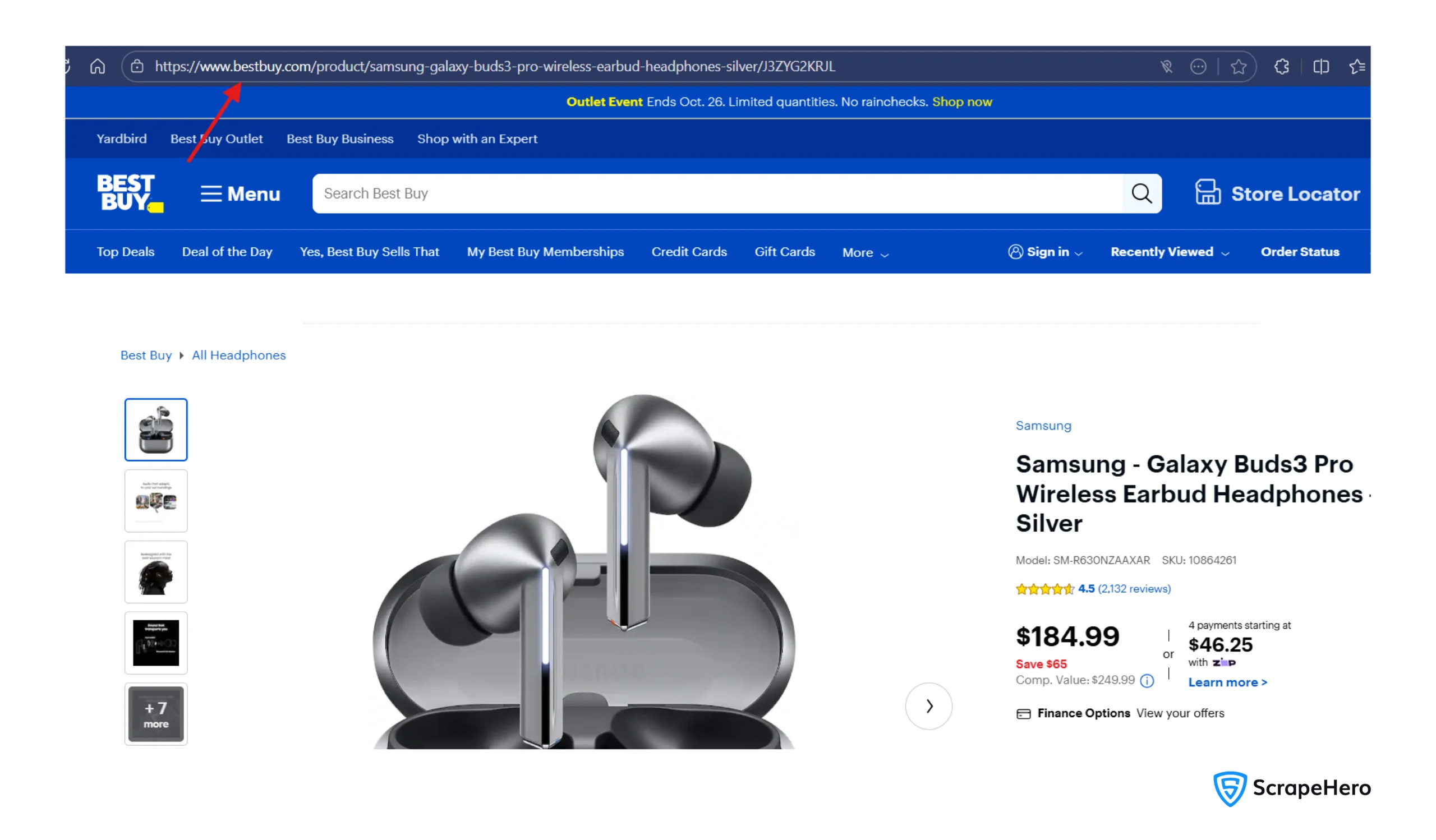
4. Enter the product URL, which you can get from the product page.
5. Name your project descriptively, such as “BestBuy Product Monitoring”.
6. Click “Gather Data” to begin the data extraction process
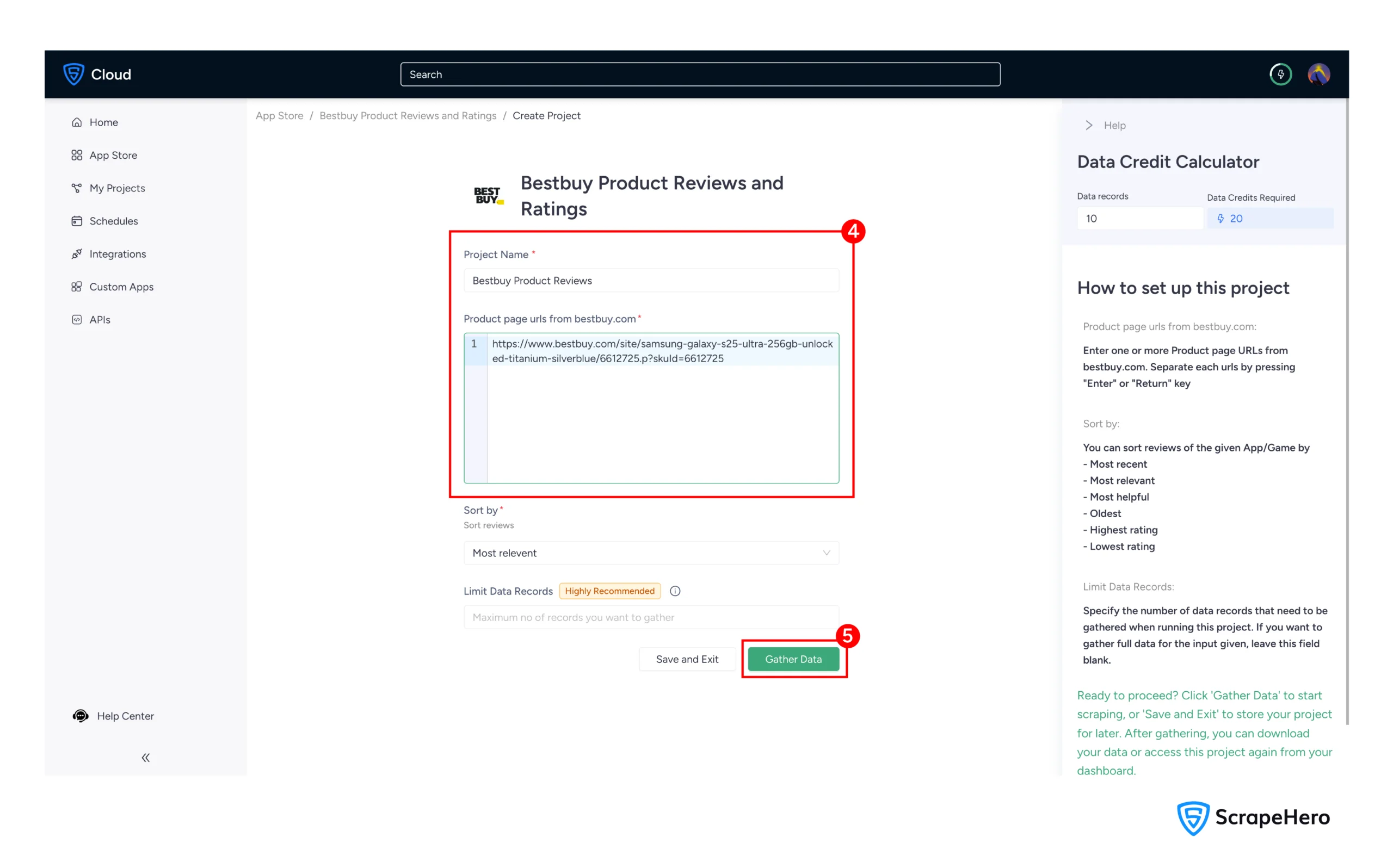
You can download the data in your preferred format (CSV, JSON, or Excel) once the scraper finishes.
Additionally, the no-code BestBuy scraper platform includes several enterprise-grade features with ScrapeHero’s paid plans:
- Cloud storage integration: Automatically sync extracted data to Google Drive, Dropbox, or Amazon S3 for seamless data pipeline integration.
- Scheduling: Configure recurring scraping sessions that runs automatically
- API Integration: Access your BestBuy data programmatically through RESTful APIs
Scrape BestBuy Data Using a Code-Based Method
Now, if you want to code yourself, read on. The following method describes how to build a BestBuy scraper using Python. Although this approach requires technical expertise, it offers complete control over the scraping logic and error handling.
Setting Up the Environment
Start by setting up the environment for the scraper to run, which means installing the right packages. The scraper shown in this tutorial only needs one external library: Playwright. Install it using PIP.
pip install playwright
You also need to install the Playwright browser separately.
playwright install
Instead of performing BestBuy web scraping using BeautifulSoup, using Playwright allows you to extract JavaScript-rendered content that traditional HTTP requests cannot process.
Data Scraped from BestBuy
The scraper targets data points using specific CSS selectors, test IDs, and DOM traversal methods. The script specifically captures:
- Product titles extracted from heading elements within anchor tags
- Current pricing information from price-block elements
- Customer ratings and review counts from rating components
- Product URLs for direct access to product pages
- Availability status through implicit indicators
To determine the selectors, inspect the data points using your browsers inspect feature:
- Right click on a data point
- Click ‘Inspect’
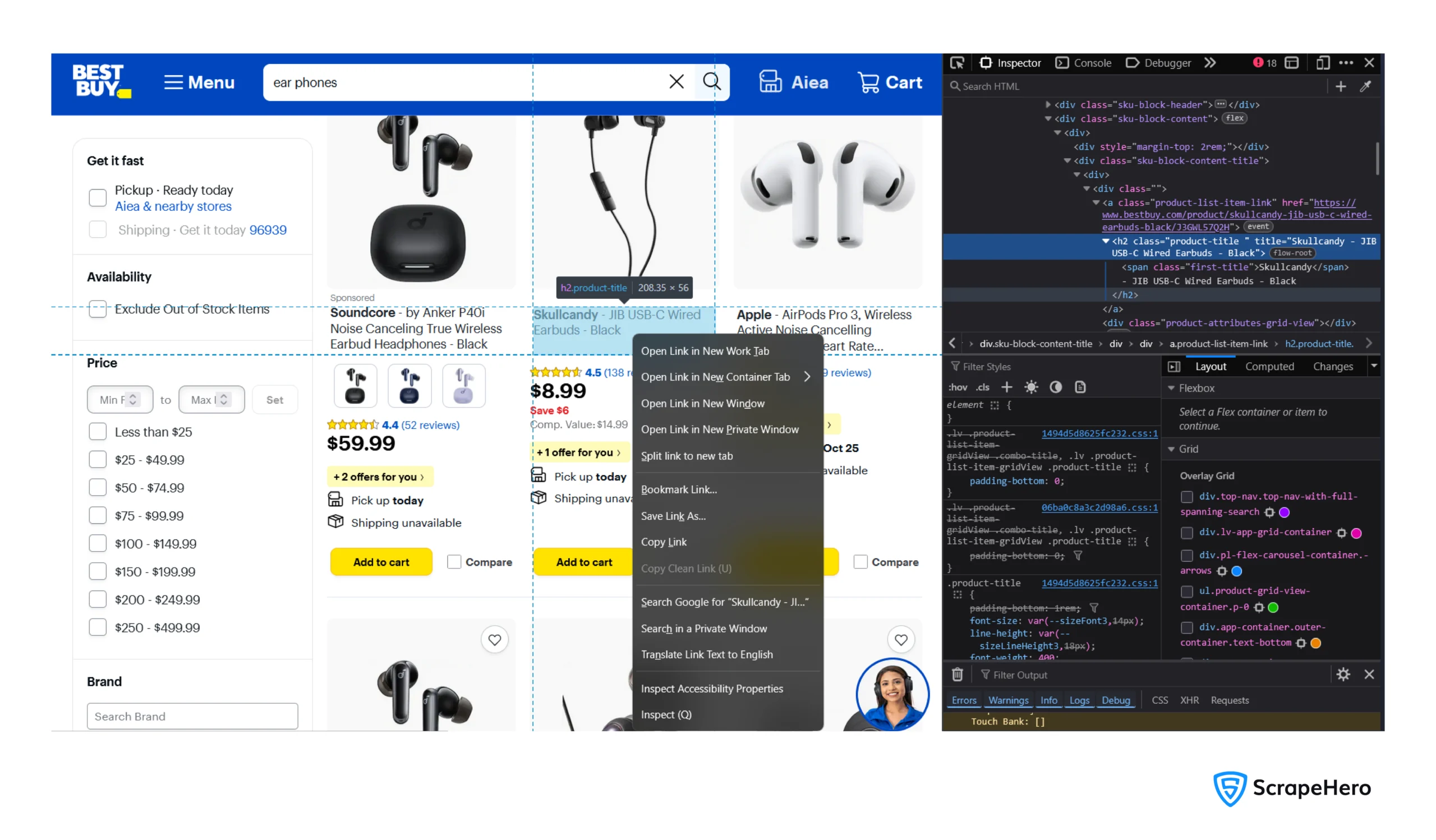
The Code to Scrape BestBuy Data
Here’s the complete code to scrape BestBuy data if you want to get started right away.
import json
from playwright.sync_api import sync_playwright
import os
def scrape_bestbuy_products():
# Create user data directory for persistent browser context
user_data_dir = os.path.join(os.getcwd(), "user_data")
if not os.path.exists(user_data_dir):
os.makedirs(user_data_dir)
url = "https://www.bestbuy.com/"
with sync_playwright() as p:
user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
# Launch persistent context with anti-detection settings
context = p.chromium.launch_persistent_context(
headless=False,
user_agent=user_agent,
user_data_dir=user_data_dir,
viewport={'width': 1920, 'height': 1080},
java_script_enabled=True,
locale='en-US',
timezone_id='America/New_York',
permissions=['geolocation'],
# Mask automation
bypass_csp=True,
ignore_https_errors=True,
channel="msedge",
args=[
'--disable-blink-features=AutomationControlled',
'--disable-dev-shm-usage',
'--no-sandbox',
'--disable-gpu',
'--disable-setuid-sandbox'
]
)
page = context.new_page()
# Set extra HTTP headers
page.set_extra_http_headers({
'Accept-Language': 'en-US,en;q=0.9',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Connection': 'keep-alive'
})
try:
# Navigate to BestBuy
print("Navigating to BestBuy...")
page.goto(url, timeout=60000)
page.wait_for_timeout(5000)
print("Page loaded successfully!")
# Take screenshot and save HTML BEFORE attempting to find search box
page.screenshot(path="bestbuy_before_search.png")
with open("bestbuy_page_source.html", "w", encoding="utf-8") as f:
f.write(page.content())
print("Screenshot and page source saved!")
# Search for product
product = "soaps"
print(f"Searching for: {product}")
# Try to find search input - this is where it might fail
search_input = page.get_by_placeholder('Search BestBuy')
search_input.fill(product)
page.wait_for_timeout(1000)
search_input.press('Enter')
# Wait for results to load
page.wait_for_selector('li.product-list-item', timeout=30000)
# drag mouse to one of the list item
first_item = page.locator('li.product-list-item').first
box = first_item.bounding_box()
if box:
page.mouse.move(box['x'] + box['width'] / 2, box['y'] + box['height'] / 2)
page.mouse.down()
page.mouse.up()
page.wait_for_timeout(500)
# Scroll to load more products
for _ in range(3):
page.mouse.wheel(0, 1000)
page.wait_for_timeout(1000)
product_cards = page.locator('li.product-list-item').all()
product_details = []
for card in product_cards[:10]:
try:
price = card.get_by_test_id('price-block-customer-price').text_content()
anchor_tag = card.locator('a.product-list-item-link')
product_url = anchor_tag.get_attribute('href').split('?')[0]
title = anchor_tag.get_by_role('heading').text_content()
rating_element = card.get_by_test_id('rnr-stats-link').get_by_role('paragraph')
rating_text = rating_element.text_content().split() if rating_element else None
rating = None
rating_count = None
if rating_text:
rating = rating_text[1]
rating_count = rating_text[-2]
product_details.append({
'title': title,
'price': price,
'rating': rating if 'yet' not in rating else None,
'rating_count': rating_count if 'yet' not in rating else None,
'url': product_url,
})
print("Extracted",title)
except Exception as e:
print(f"Error extracting product: {e}")
continue
except Exception as e:
# If any error occurs, take screenshot at the error point
print(f"Error occurred: {e}")
page.screenshot(path="bestbuy_error.png")
with open("bestbuy_error_source.html", "w", encoding="utf-8") as f:
f.write(page.content())
print("Error screenshot and source saved!")
context.close()
raise
context.close()
return product_details
if __name__ == "__main__":
try:
products = scrape_bestbuy_products()
with open("bestbuy_products.json", "w", encoding="utf-8") as f:
json.dump(products, f, indent=4, ensure_ascii=False)
print(f"Successfully saved {len(products)} products to bestbuy_products.json")
except Exception as e:
print(f"Script failed: {e}")
Want to understand the code deeply? Keep reading. First, the code starts by importing the necessary packages.
import json
from playwright.sync_api import sync_playwright
import os
This code imports three critical libraries:
- json for data serialization
- playwright for browser automation
- os for file system operations
The function scrape_bestbuy_products() handles everything related to scraping, including initializing a persistent browser context to reduce the likelihood of triggering anti-bot detection systems.
First, It creates a directory to store user data.
def scrape_bestbuy_products():
# Create user data directory for persistent browser context
user_data_dir = os.path.join(os.getcwd(), "user_data")
if not os.path.exists(user_data_dir):
os.makedirs(user_data_dir)
url = "https://www.bestbuy.com/"Creating a persistent user data directory allows the browser to maintain cookies, cache, and session information between runs, making the scraper appear more like a legitimate user revisiting the site. This reduces the chances of being blocked compared to fresh browser sessions each time.
Next, it launches the Playwright browser using the launch_persistent_context() method with required parameters.
with sync_playwright() as p:
user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
# Launch persistent context with anti-detection settings
context = p.chromium.launch_persistent_context(
headless=False,
user_agent=user_agent,
user_data_dir=user_data_dir,
viewport={'width': 1920, 'height': 1080},
java_script_enabled=True,
locale='en-US',
timezone_id='America/New_York',
permissions=['geolocation'],
# Mask automation
bypass_csp=True,
ignore_https_errors=True,
channel="msedge",
args=[
'--disable-blink-features=AutomationControlled',
'--disable-dev-shm-usage',
'--no-sandbox',
'--disable-gpu',
'--disable-setuid-sandbox'
]
)
The configuration includes:
- A realistic user agent string
- Proper viewport dimensions
- Locale settings
- Critical Chrome flags that disable automation indicators.
- The –disable-blink-features=AutomationControlled parameter removes the “navigator.webdriver” property that websites commonly check for bot detection.
The code also adds additional HTTP headers. These headers mimic those sent by standard browsers and help the scraper avoid basic fingerprinting techniques used by anti-bot systems.
page = context.new_page()
# Set extra HTTP headers
page.set_extra_http_headers({
'Accept-Language': 'en-US,en;q=0.9',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Connection': 'keep-alive'
})
Once the browser launches, you can navigate to BestBuy.com using the goto() method.
try:
# Navigate to BestBuy
print("Navigating to BestBuy...")
page.goto(url, timeout=60000)
page.wait_for_timeout(5000)
print("Page loaded successfully!")
The 60-second timeout accounts for slow loading times, while the 5-second wait allows all page elements to render before interaction.
Next, the code locates the search input field using its placeholder text, entering the search term, and executing the search with proper delays between actions.
# Search for product
product = "soaps"
print(f"Searching for: {product}")
# Try to find search input - this is where it might fail
search_input = page.get_by_placeholder('Search BestBuy')
search_input.fill(product)
page.wait_for_timeout(1000)
search_input.press('Enter')
Using the placeholder text ‘Search BestBuy’ to locate the search input makes the code more resilient to minor DOM changes than relying on CSS selectors or XPaths that might change more frequently. The one-second delay between filling the search term and pressing Enter simulates human typing speed.
BestBuy uses lazy-loading that only loads elements when you scroll. However, the mouse pointer needs to be on a scrollable area. Therefore, the code moves the cursor to one of the results (which are inside a scrollable area) and scrolls three times using the mouse wheel.
# Wait for results to load
page.wait_for_selector('li.product-list-item', timeout=30000)
# drag mouse to one of the list item
first_item = page.locator('li.product-list-item').first
box = first_item.bounding_box()
if box:
page.mouse.move(box['x'] + box['width'] / 2, box['y'] + box['height'] / 2)
page.mouse.down()
page.mouse.up()
page.wait_for_timeout(500)
# Scroll to load more products
for _ in range(3):
page.mouse.wheel(0, 1000)
page.wait_for_timeout(1000)
The code uses test IDs where available, which tend to be more stable than CSS classes, and includes fallback mechanisms for missing data.
product_cards = page.locator('li.product-list-item').all()
product_details = []
for card in product_cards[:10]:
try:
price = card.get_by_test_id('price-block-customer-price').text_content()
anchor_tag = card.locator('a.product-list-item-link')
product_url = anchor_tag.get_attribute('href').split('?')[0]
title = anchor_tag.get_by_role('heading').text_content()
rating_element = card.get_by_test_id('rnr-stats-link').get_by_role('paragraph')
rating_text = rating_element.text_content().split() if rating_element else None
rating = None
rating_count = None
if rating_text:
rating = rating_text[1]
rating_count = rating_text[-2]
product_details.append({
'title': title,
'price': price,
'rating': rating if 'yet' not in rating else None,
'rating_count': rating_count if 'yet' not in rating else None,
'url': product_url,
})
print("Extracted",title)
except Exception as e:
print(f"Error extracting product: {e}")
continue
Note: The code checks for the “yet” keyword in the rating, which will be present if the product is not yet rated.
The above data extraction runs in a try block, and the except block takes a screenshot and saves the HTML source whenever the try-block raises an error.
except Exception as e:
# If any error occurs, take screenshot at the error point
print(f"Error occurred: {e}")
page.screenshot(path="bestbuy_error.png")
with open("bestbuy_error_source.html", "w", encoding="utf-8") as f:
f.write(page.content())
print("Error screenshot and source saved!")
context.close()
raise
context.close()
Finally, the script saves the extracted data to a JSON file.
if __name__ == "__main__":
try:
products = scrape_bestbuy_products()
with open("bestbuy_products.json", "w", encoding="utf-8") as f:
json.dump(products, f, indent=4, ensure_ascii=False)
print(f"Successfully saved {len(products)} products to bestbuy_products.json")
except Exception as e:
print(f"Script failed: {e}")
Scrape BestBuy Data: Code Limitations
While this BestBuy web scraping solution provides a foundation, it has several limitations:
- The script may break when BestBuy updates its website structure, requiring ongoing maintenance to update selectors and interaction logic.
- It lacks distributed scraping capabilities, making large-scale data extraction slow and potentially detectable.
- There’s no built-in CAPTCHA solving mechanism, which could halt execution if BestBuy implements additional bot protection.
- The solution doesn’t handle geographic restrictions or regional content variations that might affect product availability and pricing.
Why Use a Web Scraping Service
For small-scale, occasional data extraction needs, the custom Python script lets you scrape BestBuy data for free. But this means you need to have technical expertise and infrastructure.
Therefore, if you just need reliable, scalable BestBuy data extraction, a web scraping service like ScrapeHero is a better choice.
ScrapeHero is among the top fully-managed web scraping service providers. We can handle website changes automatically, manage IP rotation and CAPTCHA solving, provide structured data outputs, and ensure consistent data quality. You just need to focus on using this data.
Connect with ScrapeHero to start getting hassle-free data.
FAQs
This often stems from site changes or loading delays—check the saved bestbuy_page_source.html for the current placeholder, then update get_by_placeholder(‘Search BestBuy’) accordingly. Add longer waits if JavaScript renders slowly.
Simply edit the product = “soaps” line to your keyword, like product = “laptops”. Rerun the script; it dynamically fills and submits the query, adapting the BestBuy data scraper seamlessly
The script lacks proxy support, so integrate rotating proxies via Playwright’s context args or switch to a service like ScrapeHero for built-in evasion, preventing disruptions while you extract data.



