

This article outlines a few methods to scrape Realtor.com. This could effectively export real estate data from Realtor.com to Excel or other formats for easier access and use.
There are two methods to scrape Realtor.com:
- Scraping Realtor.com in Python or JavaScript
- Using the ScrapeHero Cloud, Realtor Scraper, a no-code tool
Building a Realtor.com Scraper in Python/JavaScript
In this section, we will guide you on how to scrape Realtor.com using either Python or JavaScript. We will utilize the browser automation framework called Playwright to emulate browser behavior in our code.
One of the key advantages of this approach is its ability to bypass common blocks often put in place to prevent scraping. However, familiarity with the Playwright API is necessary to use it effectively.
You could also use Python Requests, LXML, or Beautiful Soup to build a Realtor.com scraper without using a browser or a browser automation library. However, bypassing the anti-scraping mechanisms put in place can be challenging and is beyond the scope of this article.
Here are the steps to scrape real estate data from Realtor using Playwright:
Step 1: Choose either Python or JavaScript as your programming language.
Step 2: Install Playwright for your preferred language:
Python
JavaScript
Python
pip install playwright
# to download the necessary browsers
playwright installJavaScript
npm install playwright@latest
Step 3: Write your code to emulate browser behavior and extract the desired data from Realtor.com using the Playwright API. You can use the code provided below:
Python
JavaScript
Python
import asyncio
import json
import logging
from playwright.async_api import async_playwright
LOCATION = "Texas City,TX"
MAX_PAGINATION = 2
async def extract_text(innerElement, selector):
locator = innerElement.locator(selector)
return await locator.inner_text() if await locator.count() else None
def clean_data(data: str) -> str:
if not data:
return ""
cleanedData = " ".join(data.split()).strip()
return cleanedData.encode("ascii", "ignore").decode("ascii")
async def extract_home_data(page, selector):
homes = []
for _ in selectors:
text = await extract_text(page, selector)
homes.append(clean_data(text))
return homes
async def extract_data(page, selector, location, max_pagination) -> list:
homes_for_sale = []
for pageNumber in range(max_pagination):
await page.wait_for_load_state("load")
all_visible_elements = page.locator(selector)
all_visible_elements_count = await all_visible_elements.count()
for index in range(all_visible_elements_count):
inner_element = all_visible_elements.nth(index=index)
await inner_element.hover()
selectors = [
"[data-testid='card-price']",
"[data-testid='property-meta-beds']",
"[data-testid='property-meta-baths']",
"[data-testid='property-meta-sqft']",
"[data-testid='property-meta-lot-size']",
"[data-testid='card-address']"
]
price, beds, baths, sqft, lot_size, address = await extract_home_data(inner_element, selectors)
homes_for_sale.append({
"price": price,
"no of Beds": beds,
"no of Baths": baths,
"Sqft": sqft,
"Acre Lot": lot_size,
"address": address
})
nextPage = page.locator("[aria-label='Go to next page']")
if not await nextPage.count():
break
await nextPage.click()
save_data(homes_for_sale, "HomesData.json")
async def run(playwright, location):
browser = await playwright.firefox.launch(headless=False)
context = await browser.new_context()
page = await context.new_page()
await page.set_viewport_size({"width": 1920, "height": 1080})
page.set_default_timeout(120000)
await page.goto("https://www.realtor.com/", wait_until="domcontentloaded")
await page.wait_for_load_state("load")
search_box = "[id='search-bar']"
await page.locator(search_box).click()
await page.locator(search_box).fill(location)
await page.locator(search_box).press("Enter")
listing_div_selector = "[data-testid='card-content']"
await page.wait_for_selector(listing_div_selector)
await extract_data(page, listing_div_selector, location, MAX_PAGINATION)
await context.close()
await browser.close()
def save_data(product_page_data: list, filename: str):
with open(filename, "w") as outfile:
json.dump(product_page_data, outfile, indent=4)
async def main(location):
async with async_playwright() as playwright:
await run(playwright, location)
if __name__ == "__main__":
asyncio.run(main(LOCATION))`JavaScript
const { chromium, firefox } = require('playwright');
const fs = require('fs');
const location = "Texas City,TX";
const maxPagination = 2;
/**
* Save data as list of dictionaries
as json file
* @param {object} data
*/
function saveData(data) {
let dataStr = JSON.stringify(data, null, 2)
fs.writeFile("DataJS.json", dataStr, 'utf8', function (err) {
if (err) {
console.log("An error occurred while writing JSON Object to File.");
return console.log(err);
}
console.log("JSON file has been saved.");
});
}
function cleanData(data) {
if (!data) {
return;
}
// removing extra spaces and unicode characters
let cleanedData = data.split(/s+/).join(" ").trim();
cleanedData = cleanedData.replace(/[^x00-x7F]/g, "");
return cleanedData;
}
/**
* The data extraction function used to extract
necessary data from the element.
* @param {HtmlElement} innerElement
* @returns
*/
async function extractData(innerElement) {
async function extractData(data) {
let count = await data.count();
if (count) {
return await data.innerText()
}
return null
};
// intializing xpath and selectors
const priceSelector = "[data-testid='card-price']"
const bedSelector = "[data-testid='property-meta-beds']"
const bathSelector = "[data-testid='property-meta-baths']"
const sqftSelector = "[data-testid='property-meta-sqft']"
const acreSelector = "[data-testid='property-meta-lot-size']"
const addressSelector = "[data-testid='card-address']"
// Extracting necessary data
let price = innerElement.locator(priceSelector);
price = await extractData(price);
let noOfBeds = innerElement.locator(bedSelector);
noOfBeds = await extractData(noOfBeds);
let noOfBaths = innerElement.locator(bathSelector);
noOfBaths = await extractData(noOfBaths);
let areaInSqft = innerElement.locator(sqftSelector);
areaInSqft = await extractData(areaInSqft);
if (areaInSqft) {
areaInSqft = areaInSqft.split('n')[0];
} else {
areaInSqft = null;
}
let areaInAcreLot = innerElement.locator(acreSelector);
areaInAcreLot = await extractData(areaInAcreLot);
if (areaInAcreLot) {
areaInAcreLot = areaInAcreLot.split('n')[0];
} else {
areaInAcreLot = null;
}
let address = innerElement.locator(addressSelector);
address = await extractData(address)
// cleaning data
price = cleanData(price)
noOfBeds = cleanData(noOfBeds)
noOfBaths = cleanData(noOfBaths)
areaInAcreLot = cleanData(areaInAcreLot)
areaInSqft = cleanData(areaInSqft)
address = cleanData(address)
extractedData = {
"price": price,
"no of Beds": noOfBeds,
"no of Baths": noOfBaths,
"Sqft": areaInSqft,
'Acre Lot': areaInAcreLot,
'address': address
}
console.log(extractData)
return extractedData
}
/**
* The main function initiate a browser object and handle the navigation.
*/
async function run() {
// intializing browser and creating new page
const browser = await chromium.launch({ headless: false});
const context = await browser.newContext();
const page = await context.newPage();
// initializing xpaths and selectors
const xpathSearchBox = "[id = 'search-bar']";
const listingDivSelector = "[data-testid='card-content']";
const totalResultsSelector = "[data-testid='total-results']";
const xpathNextPage = "[aria-label='Go to next page']";
// Navigating to the home page
await page.goto('https://www.realtor.com/', {
waitUntil: 'domcontentloaded',
timeout: 60000,
});
// Clicking the input field to enter the location
await page.waitForSelector(xpathSearchBox, { timeout: 60000 });
await page.click(xpathSearchBox);
await page.fill(xpathSearchBox, location);
await page.keyboard.press('Enter');
// Wait until the list of properties is loaded
await page.waitForSelector(listingDivSelector);
const totalResultCount = await page.locator(totalResultsSelector).innerText();
console.log(`Total results found - ${totalResultCount} for location - ${location}`);
// to store the extracted data
let data = [];
// navigating through pagination
for (let pageNum = 0; pageNum < maxPagination; pageNum++) {
await page.waitForLoadState("load", { timeout: 120000 });
await page.waitForTimeout(10);
let allVisibleElements = page.locator(listingDivSelector);
allVisibleElementsCount = await allVisibleElements.count()
// going through each listing element
for (let index = 0; index < allVisibleElementsCount; index++) {
await page.waitForTimeout(2000);
await page.waitForLoadState("load");
let innerElement = await allVisibleElements.nth(index);
await innerElement.hover();
innerElement = await allVisibleElements.nth(index);
let dataToSave = await extractData(innerElement);
data.push(dataToSave);
};
//to load next page
let nextPage = page.locator(xpathNextPage);
await nextPage.hover();
if (await nextPage.count()) {
await nextPage.click();
}
else { break };
};
saveData(data);
await context.close();
await browser.close();
};
run();This code shows how to scrape Realtor.com using the Playwright library in Python and JavaScript.
The corresponding scripts have two main functions, namely:
- run function: This function takes a Playwright instance as an input and performs the scraping process. The function launches a Chromium browser instance, navigates to Realtor.com, fills in a search query, clicks the search button, and waits for the results to be displayed on the page.
The extract_data function is then called to extract the listings details and store the data in a HomesData.json file. - extract_data function: This function takes a Playwright page object as input and returns a list of dictionaries containing the listing details. The details include each listing’s price, number of beds and baths, square footage, lot size, and address.
Finally, the main function uses the async_playwright context manager to execute the run function. A JSON file containing the listings of the Realtor.com script you just executed will be created.
Step 4: Run your code and collect the scraped data from Realtor.com.

Using No-Code Realtor Scraper by ScrapeHero Cloud
The Realtor Scraper by ScrapeHero Cloud is a convenient method for scraping real estate data from Realtor.com. It provides an easy, no-code method for scraping data, making it accessible for individuals with limited technical skills.
This section will guide you through setting up and using the Realtor scraper.
- Sign up or log in to your ScrapeHero Cloud account.
- Go to the Realtor scraper by ScrapeHero Cloud in the marketplace.
Note: The ScrapeHero Cloud’s Realtor Scraper falls under the premium scrapers category that does not include a free tier. To access this scraper, the user should be subscribed to a paid plan. - Add the scraper to your account. (Don’t forget to verify your email if you haven’t already.)
- You need to add the search results URL of a certain place to start the scraper. If it’s just a single query, enter it in the field provided and choose the number of pages to scrape.
For instance, if you have to scrape all the listings from Texas City, copy the URL: https://www.realtor.com/realestateandhomes-search/Texas-City_TX
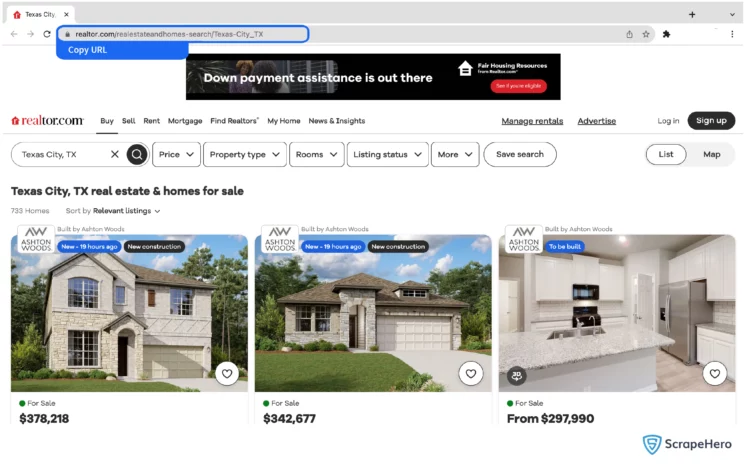
- To scrape results for multiple queries, switch to Advance Mode, and in the Input tab, add the Search results URL to the SearchQuery field and save the settings.
- To start the scraper, click on the Gather Data button.
- The scraper will start fetching data for your queries, and you can track its progress under the Jobs tab.
- Once finished, you can view or download the data from the same.
- You can also export the real estate data from Realtor.com into an Excel spreadsheet from here. Click on the Download Data, select “Excel,” and open the downloaded file using Microsoft Excel.
Uses cases of Real Estate Data from Realtor.com
If you’re unsure as to why you should scrape Realtor.com, here are a few use cases where this data would be helpful:
Real-Time Property Valuation
By scraping Realtor.com, you can gather historical data like property age, location, and condition. This helps create precise pricing models that respond in real time, aiding buyers and sellers in making informed decisions.
Buyer-Seller Matching
With the right data, realtors can match buyers with properties that meet their needs—like budget, location, and preferences. Realtor.com data can help real-estate companies target their efforts towards buyers genuinely interested in their offer, thus saving time and resources.
Market Trend Analysis
The data can show which neighborhoods are becoming popular, what amenities are essential, and how human mobility and demographics affect property values. With data scraped from Realtor.com, businesses can keep a finger on the market’s pulse, adapting quicker to shifts and changes.
Future Growth Prediction
The real estate market patterns are based on various factors such as economic conditions, local policies, and interest rates. You can pick up on these patterns by scraping and analyzing data from platforms like Realtor.com. This helps forecast which areas are likely to grow, allowing investors and developers to make proactive choices.
Cost Efficiency in Development
With the right data, real estate companies can optimize land acquisition costs and minimize waste during construction. Data from Realtor.com can provide valuable insights into property and material costs, ensuring that developers make smart spending choices.
Frequently Asked Questions
Realtor.com scraping refers to extracting real estate data from the real estate listings available on Realtor.com. This process allows for systematically collecting housing data displayed on this prominent online platform.
To scrape Realtor.com, you can either build a scraper using Python or JavaScript or if you don’t want to code, you can use the Realtor Scraper from ScrapeHero Cloud.
What is the subscription fee for the Realtor Scraper by ScrapeHero?
To know more about the pricing, visit the pricing page.
Is it legal to scrape Realtor.com?
Legality depends on the legal jurisdiction, i.e., laws specific to the country and the locality. Gathering or scraping publicly available information is not illegal.
Generally, Web scraping is legal if you are scraping publicly available data.
Please refer to our Legal Page to learn more about the legality of web scraping.
Legal information
How can I scrape housing and apartment data?
To scrape housing and apartment data, use pre-built scrapers such as the Zillow Scraper, Realtor Scraper, Trulia Scraper, etc., from ScrapeHero Cloud, or you can scrape listings manually from real estate platforms using Python or JavaScript.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data



