
Cars.com hosts details of used and new cars, including specifications and prices. You can specify the make, model, and other information to get a list of cars. Web scraping cars.com allows you to save and analyze this data.
This tutorial shows you how to scrape cars.com using Python and BeautifulSoup.
Environment for Web Scraping Cars.com
This code for automobile data scraping uses Python requests and BeautifulSoup. The requests library handles HTTP requests, and BeautifulSoup helps you parse and extract data.
Install BeautifulSoup and Python requests using pip.
pip install BeautifulSoup requestsYou may also need to install lxml, as the code uses BeautifulSoup with lxml to parse and extract data.
pip install lxmlData Scraped from Cars.com
This tutorial scrapes data from both the search results pages and the information page of each car.
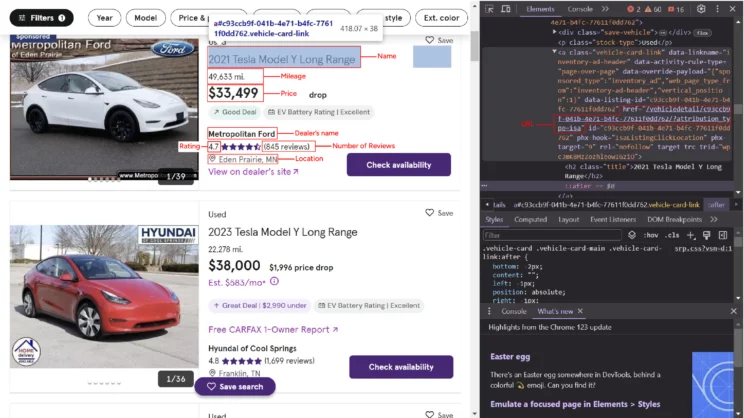
- Name
- Price
- URL
- Dealer Details
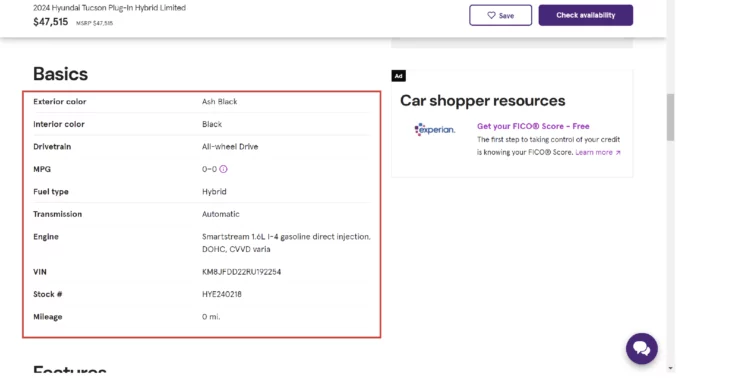
- Car Specification
The search results page only displays the name, price, URL, and dealer details.
However, to get the car specifications, you have to go to the car’s information page.
How to Scrape Cars.com: The code
Begin by writing the import statements. In addition to requests and BeautifulSoup, you need the json and argparse modules.
import requests
import argparse
import json
from bs4 import BeautifulSoupThe json module enables you to write scraped data to a JSON file. And argparse allows you to pass arguments to the script from the command line.
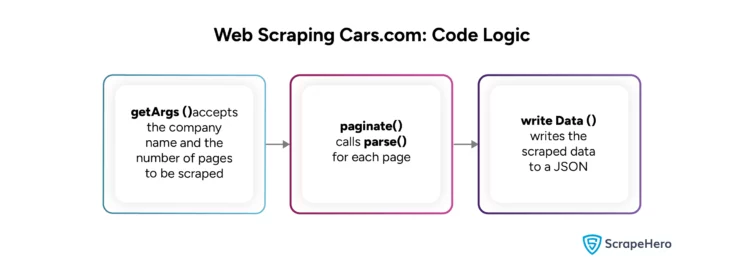
Here, the code uses four functions:
- parse() parses the required data.
- paginate() accepts the company name and the number of pages to extract. It uses these values to build URLs for each page and calls parse() in a loop.
- getArgs() parses the company’s name and the number of pages supplied during runtime.
- writeData() writes the data to a JSON file.
parse()
The function accepts a URL and sends an HTTP request to it.
def parse(url):
response = requests.get(url)You don’t need to use headers to scrape cars.com, as the website does not block the default headers of Python requests.
The next step is to parse the response.
soup = BeautifulSoup(response.text,'lxml')Here, the code uses BeautifulSoup to parse the response from cars.com.
Analyzing the code shows that the details of each car on the search results page will be inside a div element. The class to look for is ‘vehicle-details.’
Use the find_all() method to locate all the elements with that class.
cars = soup.find_all('div',{'class':'vehicle-details'})Next, iterate through all the div elements and locate the required data points.
for car in cars:BeautifulSoup’s find method can identify any single element. Moreover, it can accept attributes as search parameters.
The URL of the car’s information page will be inside the href attribute of the anchor tag. However, the URL is relative; make it absolute by prepending it with “https://cars.com.”
rawHref = car.find('a')['href']
href = rawHref if 'https' in rawHref else 'https://cars.com'+rawHrefSimilarly, you can find other data points on the website using the attributes and the tag name. For example, the car’s name includes an H2 tag with the class ‘title.’
name = car.find('h2',{'class':'title'}).textPrice is inside a span element with the class ‘primary-price.’
price = car.find('span',{'class':'primary-price'}).textMileage is the only element with class mileage, so you can skip mentioning the tag.
mileage = car.find(attrs={'class':'mileage'}).text if car.find(attrs={'class':'mileage'}) else NoneYou won’t find mileage information for some cars, that is why the above code uses a conditional statement.
Some extracted values may have unnecessary characters; use replace() to remove them.
dealer = car.find(attrs={'class':'dealer-name'}).text.replace('\n','') if car.find(attrs={'class':'dealer-name'}) else NoneThe car’s technical specifications will be on its information page. To access them, make an HTTP request using the extracted URL and parse the response.
newResponse = requests.get(href)
newSoup = BeautifulSoup(newResponse.text,'lxml')The car specification will be inside a dl element with the class ‘fancy-description-list.’
description = newSoup.find('dl',{'class':'fancy-description-list'})Find the element using the find() method, and use find_all() to find all the dt and dd elements and make a dict from them.
rawBasicKeys = description.find_all('dt')
basicKeys = [key.text.replace('\n',' ') for key in rawBasicKeys]
rawBasicValues = description.find_all('dd')
basicValues = [value.text.replace('\n',' ') for value in rawBasicValues]
basics = dict(zip(basicKeys,basicValues))Finally, store all the extracted data in another dict and return it.
data.append({
"Name":name,
"Price":price,
"URL":href,
"Mileage":mileage,
"Stock-Type":stock_type,
"Dealer Details":{"Name":dealer,
"Rating":rating,
"Review Count":reviews,
"Location":location
},
"Specifications":basics
}
)
return datapaginate()
paginate() accepts two arguments: search_term, stock_type, and max_pages.
- The search_term is the car company.
- The max_pages is the number of pages you want to scrape.
- The stock_type is whether the car is new or used.
The stock_type makes this code suitable for new and used car data extraction. To scrape used car data, you only need to provide ‘used’ as an argument when running the script. Similarly, use the ‘new’ argument to extract new cars.
The function runs a loop where max_pages determines the maximum number of iterations. In each iteration, the loop
- Builds the URL of each search results page
url = "https://www.cars.com/shopping/results/?makes[]="+search_term+"&maximum_distance=all&models[]=&Page="+str(i)+"&stock_type="+stock_type+"&zip=&models%5B%5D=&maximum_distance=all&zip=" - Calls parse() with this URL as the argument
scraped_data = parse(url)
For example, if max_pages is 5, the loop executes five times. It calls parse() and stores the data returned by parse() in an array each time.
Finally, paginate() returns the parsed data.
getArgs()
getArgs() gets the arguments mentioned above and returns them. The argparse module allows you to do that.
def getArgs():
argparser = argparse.ArgumentParser()
argparser.add_argument('search',help = 'Write name of the company')
argparser.add_argument('max_pages',help="Maximum number of pages you want to scrape")
argparser.add_argument('stock_type',help="Do you want 'used' or 'new'")
args = argparser.parse_args()
search_term = args.search
max_pages = args.max_pages
stock_type = args.stock_type
return [search_term,max_pages,stock_type]writeData()
writeData() uses the JSON module to write the extracted data into a JSON file. In addition to the extracted data, the function accepts the company name and includes it in the JSON file name.
def writeData(carData,search_term):
if carData:
print(len(carData))
with open('%s_cars.json'%(search_term),'w',encoding='utf-8') as jsonfile:
json.dump(carData,jsonfile,indent=4,ensure_ascii=False)
else:
print("No data scraped")Now that you have defined all the functions required to scrape cars.com, it is time to integrate them.
First, call the argparse function and get the company name and the number of pages to extract; the function returns these values.
search_term,max_pages,stock_type=getArgs()Next, call paginate() with these values as arguments, which gives the extracted data.
carData=paginate(max_pages,search_term,stock_type)Finally, call the writeData() function with the extracted data and the company name as arguments.
writeData(carData,search_term)The results of this automobile website scraping will look something like this.
{
"Name": "2020 Tesla Model 3 Performance",
"Price": "$31,268",
"URL": "https://cars.com/vehicledetail/afd877ad-d066-45d9-a794-ab9662265732/?attribution_type=isa",
"Mileage": "52,358 mi.",
"Stock-Type": "Used",
"Dealer Details": {
"Name": "Toyota of Cedar Park",
"Rating": "4.8",
"Review Count": "3,195 reviews",
"Location": " Cedar Park, TX"
},
"Specifications": {
"Exterior color": " Red Multi ",
"Interior color": "Black ",
"Drivetrain": "All-wheel Drive ",
"Transmission": "1-Speed Automatic",
"Engine": "Electric",
"VIN": " 5YJ3E1EC1LF586771 ",
"Stock #": " LF586771 ",
"Mileage": " 52,358 mi. "
}
},
{
"Name": "2021 Tesla Model Y Long Range",
"Price": "$33,500",
"URL": "https://cars.com/vehicledetail/3b0722f5-b82e-4c55-8a7d-e8bd5cacd715/",
"Mileage": "27,109 mi.",
"Stock-Type": "Used",
"Dealer Details": {
"Name": "SVG Motors Beavercreek",
"Rating": null,
"Review Count": "2 reviews",
"Location": " Beavercreek, OH"
},
"Specifications": {
"Exterior color": " Black ",
"Interior color": "White / Black ",
"Drivetrain": "All-wheel Drive ",
"Transmission": "1-Speed Automatic",
"Engine": "Electric",
"VIN": " 5YJYGDEE8MF120310 ",
"Stock #": " B4845 ",
"Mileage": " 27,109 mi. "
}
And here is the complete code.
import requests
import argparse
import json
from bs4 import BeautifulSoup
def parse(url):
response = requests.get(url)
soup = BeautifulSoup(response.text,'lxml')
cars = soup.find_all('div',{'class':'vehicle-details'})
data = []
for car in cars:
rawHref = car.find('a')['href']
href = rawHref if 'https' in rawHref else 'https://cars.com'+rawHref
name = car.find('h2',{'class':'title'}).text
price = car.find('span',{'class':'primary-price'}).text
mileage = car.find(attrs={'class':'mileage'}).text if car.find(attrs={'class':'mileage'}) else None
dealer = car.find(attrs={'class':'dealer-name'}).text.replace('\n','') if car.find(attrs={'class':'dealer-name'}) else None
reviews = car.find('span',{'class':'test1 sds-rating__link sds-button-link'}).text.replace('(','').replace(')'
,'') if car.find('span',{'class':'test1 sds-rating__link sds-button-link'}) else None
location = car.find(attrs={'class':'miles-from'}).text.replace('\n','')
rating = car.find('span',{'class':'sds-rating__count'}).text if car.find('span',{'class':'sds-rating__count'}) else None
stock_type = car.find('p',{'class':'stock-type'}).text
newResponse = requests.get(href)
newSoup = BeautifulSoup(newResponse.text,'lxml')
print('getting details of'+name)
description = newSoup.find('dl',{'class':'fancy-description-list'})
rawBasicKeys = description.find_all('dt')
basicKeys = [key.text.replace('\n',' ') for key in rawBasicKeys]
rawBasicValues = description.find_all('dd')
basicValues = [value.text.replace('\n',' ') for value in rawBasicValues]
basics = dict(zip(basicKeys,basicValues))
data.append({
"Name":name,
"Price":price,
"URL":href,
"Mileage":mileage,
"Stock-Type":stock_type,
"Dealer Details":{"Name":dealer,
"Rating":rating,
"Review Count":reviews,
"Location":location
},
"Specifications":basics
}
)
return data
def getArgs():
argparser = argparse.ArgumentParser()
argparser.add_argument('search',help = 'Write name of the company')
argparser.add_argument('max_pages',help="Maximum number of pages you want to scrape")
argparser.add_argument('stock_type',help="Do you want 'used' or 'new'")
args = argparser.parse_args()
search_term = args.search
max_pages = args.max_pages
stock_type = args.stock_type
return [search_term,max_pages,stock_type]
def paginate(max_pages,search_term,stock_type):
carData = []
for i in range(int(max_pages)):
url = "https://www.cars.com/shopping/results/?makes[]="+search_term+"&maximum_distance=all&models[]=&Page="+str(i)+"&stock_type="+stock_type+"&zip=&models%5B%5D=&maximum_distance=all&zip="
scraped_data = parse(url)
print(url)
for data in scraped_data:
carData.append(data)
return carData
def writeData(carData,search_term):
if carData:
print(len(carData))
with open('%s_cars.json'%(search_term),'w',encoding='utf-8') as jsonfile:
json.dump(carData,jsonfile,indent=4,ensure_ascii=False)
else:
print("No data scraped")
if __name__=="__main__":
# get arguments from the command line
search_term,max_pages,stock_type=getArgs()
# extract data
carData=paginate(max_pages,search_term,stock_type)
# write data
writeData(carData,search_term)Code Limitations
The code will work fine if cars.com does not block Python request headers. Otherwise, update the code to use headers that fake user agents when making HTTP requests to cars.com.
In addition, the HTML code can also change, requiring you to update the code for web scraping cars.com. For example, cars.com may change the tag enclosing the name of the car from H2 to H3. You then want to make this change in the code.
name = car.find('h3',{'class':'title'}).textWrapping Up
Python requests and BeautifulSoup are excellent for web scraping cars.com. Moreover, as cars.com does not block the default headers of the HTTP requests, you don’t need to fake user agents.
However, the specific attributes and HTML tags enclosing the required data may change. You then need to update the code with the new ones. And cars.com may use anti-scraping measures when you try large-scale automotive data scraping.
Therefore, it is better to use professional services, like ScrapeHero, for large-scale automobile web scraping. You can also avoid writing the code to scrape cars.com.
ScrapeHero is a full-service web scraping service provider. We can build enterprise-grade web scrapers according to your specifications. Let us know your data requirements, and we will handle the rest.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data



