

You might think web scraping is only for tech giants, legally risky, or too complex to manage. These are common myths that prevent companies from leveraging one of the most powerful tools in modern business.
In reality, professional web scraping is a lawful, structured, and accessible way to transform the chaotic internet into actionable data. It’s a practical superpower for everything from pricing intelligence to market research, and it’s within your reach.
This article separates the myths about web scraping from the reality, showing you how to harness web data confidently while staying compliant.

So let’s cut through the noise. Here are 9 web scraping myths you need to stop believing today so that you can approach it with clarity and confidence.
- Is Web Scraping Hard?
- Is Web Scraping Illegal?
- Is Web Scraping and Web Crawling the Same?
- Is Public Information Free to Use?
- Do I Need to Be a Coding Expert to Scrape?
- Do I Need Permission to Use Data I Scraped?
- Will Scrapers Work Flawlessly for a Long Time?
- Is the Data Free Since It’s Just Collected From the Web?
- Is Scraping Only Practical for Big Companies?

1. Is Web Scraping Hard?
Myth 1: “Web Scraping is Just Too Hard”
The Reality: Web scraping isn’t hard anymore. Thanks to modern no-code tools and managed services, it’s accessible to anyone, regardless of programming skills.
Think of web scraping like building a website today. You can code from scratch, use tools like Wix, or outsource it. Similarly, solutions exist for web scraping at every skill level.
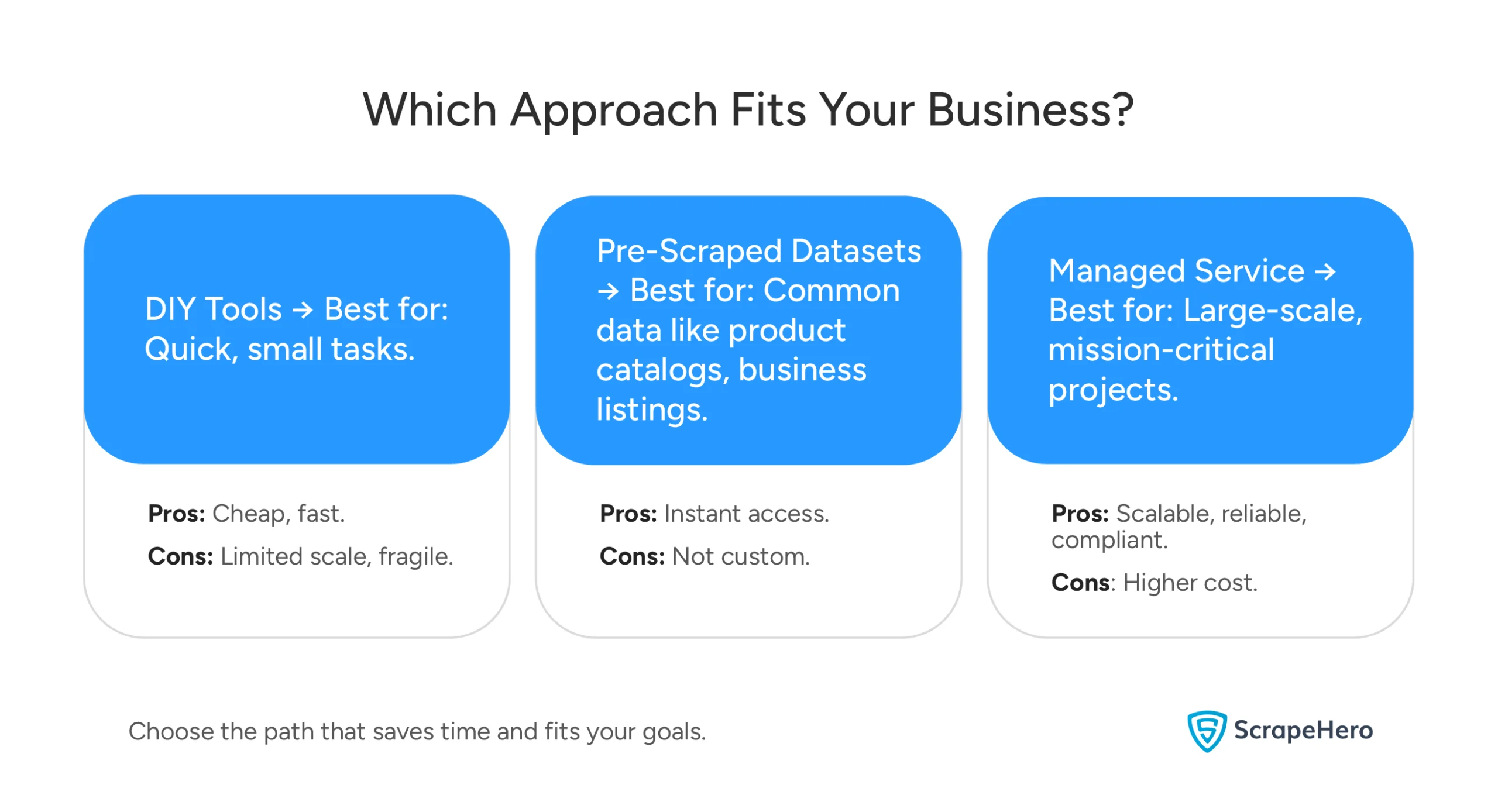
The Fast-Track Solution: Why build what already exists? For example, many providers offer ready-to-use datasets. It includes vast databases of product info, business listings, and more. As a result, you get instant data without any technical work.
The DIY Approach: For quick tasks, you can use no-code platforms like ScrapeHero Cloud. This way, you can extract data in a few simple steps. No programming needed.
The Outsource Method: For big projects, fully managed services handle everything. A partner like ScrapeHero manages the entire pipeline while handling anti-bot systems. Ultimately, they deliver clean, analysis-ready data, so your team can focus on insights rather than infrastructure.
The bottom line? The barrier is gone. The real question isn’t if you can scrape, it’s which method works best for your goals.
2. Is Web Scraping Illegal?
Myth 2: “It’s Always Illegal and Will Get Me Sued”
The Reality: Web scraping isn’t always illegal. In reality, you can legally scrape publicly available data as long as you respect the website’s terms of service and relevant privacy laws.
The fear of legal compliance paralyzes more people than any other myth, primarily because high-profile lawsuits fuel this anxiety. However, the legal landscape is nuanced, not a blanket prohibition.
When examining web scraping legality myths, it’s essential to understand that the hiQ Labs v. LinkedIn case established a crucial precedent by affirming that the legal scraping of publicly available data is permissible.
Compliant scraping rests on four pillars:
Public vs. Private data: Scraping data anyone can see is different from hacking password-protected areas.
Respecting Privacy: Ethical scrapers strictly follow GDPR and CCPA regulations. Typically, they avoid collecting personally identifiable information unless necessary. And when they do collect it, they handle it carefully.
Terms of Service Awareness: This gets complex. But reputable providers operate cautiously. They respect robots.txt files and avoid disrupting website operations.
Intent Matters: Using data for internal market research differs vastly from republishing copyrighted content.
The key takeaway? Web scraping is a legitimate business practice when conducted responsibly and ethically. Therefore, partnering with an expert is the safest path to compliance.
3. Is Web Scraping and Web Crawling the Same?
Myth 3: “Web Scraping and Crawling Are the Same Thing”
The Reality: Web scraping and crawling are different processes. Specifically, crawling discovers and indexes web pages, while scraping extracts specific data from those pages.
Using these terms interchangeably is like confusing a librarian with a researcher. Both handle books. However, their objectives differ drastically.
Web Crawling is about discovery. A crawler, such as Googlebot, systematically explores the web to map what exists. In essence, it casts a wide, shallow net to build an index.
Web Scraping is about extraction. A scraper targets specific data points, such as prices, contact details, and article text, from chosen sources. By contrast, it takes a deep, focused dive for specific intelligence.
Understanding this distinction helps you communicate your needs effectively, whether you’re building a sitemap or tracking competitor inventory.
4. Is Public Information Free to Use?
Myth 4: “If I Can Technically Scrape It, I Have the Right To”
The Reality: Technical ability doesn’t grant legal or ethical rights. On the contrary, legal restrictions on private data, copyright, and terms of service still apply, regardless of your coding skills.
This “wild west” mindset gives scraping a bad name. Just because you can engineer a script to bypass defenses doesn’t mean you should. In fact, this approach creates risk.
You need judgment to govern technical prowess. Specifically, respect these boundaries:
Private Data: Don’t access confidential user information or financial records.
Copyright Law: Don’t republish copyrighted text or images without permission.
Terms of Service: Knowingly violating a site’s ToS can lead to legal action and permanent bans.
Professional scraping isn’t about breaking down doors. Instead, it’s about knowing which doors to open and how to do it respectfully.
5. Do I Need to Be a Coding Expert to Scrape?
Myth 5: “I Need to Be a Coding Expert”
The Reality: You don’t need extensive programming knowledge. Fortunately, no-code and low-code solutions make web scraping accessible to business analysts, marketers, and researchers.
Demand for accessible data sparked a revolution in business-user tools. When examining web scraping facts vs myths, it’s clear that technical barriers have disappeared for most use cases.
For example, ScrapeHero offers purpose-built scrapers for high-value targets, such as Google Maps business listings or Zillow real estate data. Consequently, these tools work for marketers, analysts, and researchers.
They deliver data directly to spreadsheets or APIs. This empowerment accelerates your time-to-insight, allowing you to bypass IT bottlenecks entirely.
6. Do I Need Permission to Use Data I Scraped?
Myth 6: “I Can Use Scraped Data However I Want”
The Reality: You can’t use scraped data for any purpose. Instead, usage is limited by copyright law, terms of service, and regulations governing fair use and data privacy.
Getting the data is step one. However, using it properly is more important.
Generally Acceptable Uses:
Competitive Intelligence: Monitor rival pricing and product assortments
Market Research: Analyze customer sentiment and industry trends
Lead Generation: Source public business contact information
High-Risk, Potentially Illegal Uses:
Content Duplication: Using scraped articles or descriptions on your site
Data Resale: Packaging and selling scraped datasets as products
Creating a Clone: Using data to replicate a competitor’s service directly
Always define your data purpose first. That’s why a credible provider helps you navigate these boundaries safely.
7. Will Scrapers Work Flawlessly for a Long Time?
Myth 7: “Scrapers Work Flawlessly, Forever”
The Reality: Web scrapers aren’t always reliable. In fact, they need constant maintenance to combat website layout changes, anti-bot measures, and dynamic content loading.
Websites are living entities. They update layouts, change code, and deploy stronger anti-bot measures. As a result, a scraper that works today could break tomorrow from a simple button redesign. By exploring these web scraping myths debunked, businesses can set more realistic expectations about the maintenance required.
Scrapers constantly battle:
Layout Changes: Minor HTML tweaks can shatter scraper logic.
Anti-Bot Defenses: CAPTCHAs, IP blocking, and behavioral analysis stop automation.
JavaScript Rendering: Modern sites load content dynamically, meaning simple scrapers can’t see it.
This makes the strongest case against fragile in-house scripts. Conversely, a managed service’s real value lies in continuous monitoring and maintenance. Therefore, your data flow never dries up.

8. Is the Data Free Since It’s Just Collected From the Web?
Myth 8: “It’s Inherently Cheap Because the Data is Public”
The Reality: Web scraping isn’t always cheap. The true costs include infrastructure, anti-bot measures, maintenance, and the significant business risk of using inaccurate or unreliable data.
Although free scripts may look appealing, the real expense isn’t the tool, it’s the Total Cost of Ownership. This includes hidden costs, such as maintenance and data cleaning. Additionally, there is a significant business risk of inaccurate data.
A cheap solution often results in:
Inaccurate Insights: Base your pricing strategy on flawed data, and you may face substantial financial losses.
Hidden Infrastructure: Proxies, servers, and developer hours add up quickly.
Compliance Risks: Unintentional violations lead to legal consequences.
Lack of Expert Support: When your scraper breaks, generic help desks often cannot resolve the issue.
On the other hand, professional vendors provide value by mitigating these risks, not adding gimmicks.
For instance, ScrapeHero uses no-gimmick pricing and provides direct access to the experts who build and manage our scraping systems. Instead of inflating costs with impressive-sounding features, we focus on what delivers results: reliable, documented communication with the very engineers who solve complex data extraction challenges daily.
Further, we built our client experience around streamlined support channels, including a dedicated ticket system and direct email. Moreover, for technical issues that require precision, written channels ensure that every detail is tracked and addressed efficiently.
This isn’t an add-on. Instead, it’s essential for precise and responsive communication, as well as project success.

9. Is Scraping Only Practical for Big Companies?
Myth 9: “It’s Only for E-Commerce Giants”
The Reality: Web scraping isn’t only for large businesses or a specific industry. On the contrary, academics, journalists, individuals, and companies across all industries use it for market research, trend analysis, and personal projects.
Web scraping is not limited to specific businesses. In truth, anyone who makes decisions based on public information can benefit.
Academia & Journalism: Researchers can analyze social trends. Meanwhile, journalists can track news sources.
Individuals: Job seekers can monitor job listings. Similarly, travelers can find deal alerts.
Various Industries:
- E-commerce – Price tracking, catalog monitoring.
- Real Estate – Listings, rental trends.
- Finance – Market sentiment, filings, stock news.
- Healthcare – Drug prices, outbreak monitoring.
- Law Firms – Case law research, regulatory updates, compliance monitoring
- Non-Profit Organizations – Grant opportunities, policy changes, advocacy trend tracking.
If there’s public web data relevant to your field, scraping can help you harness it.
See How It Works in the Real World
At ScrapeHero, we’ve partnered with organizations you might not expect to use automated data collection, helping them turn public web data into mission-critical insights.
These stories show that, no matter your industry, reliable data is your most powerful asset.

Stop Letting Myths Dictate Your Strategy
Web scraping is a powerful, accessible, and legitimate tool when approached with the right expertise and knowledge. The myths about web scraping we’ve debunked often stem from experiences with fragile, amateur attempts. In contrast, the professional world of data acquisition builds on reliability, compliance, and strategic value.
Now you’re not asking whether you should use web data. Instead, you’re asking how to do it most effectively.
If you’re ready to cut through the uncertainty, ScrapeHero helps you turn data into decisions. We provide a managed web scraping service that ensures compliance, scalability, and data you can actually use.
From ready-to-download datasets to fully custom pipelines, we help businesses and researchers avoid scraping risks while getting the insights they need.
Contact ScrapeHero today to discuss your specific data needs. Let’s turn public data into your private advantage.
FAQs
Web scraping is a controversial practice because it often involves extracting data from websites without explicit permission. This raises concerns over intellectual property rights, server strain, and legal compliance.
The main dangers include legal risks, potential IP bans, inaccurate or outdated data, and ethical concerns if sensitive or private information is scraped. Poorly designed scrapers can also overload websites, causing performance issues.
Yes, web scraping is still highly relevant in 2025. As more industries move online, valuable information like prices, product catalogs, financial data, and market trends is constantly changing. Businesses rely on scraping to capture these real-time shifts at scale, something manual research or static reports can’t deliver.
Ethical concerns focus on respecting user privacy, avoiding data misuse, and responsibly scraping only publicly available content. Transparency and compliance with data protection laws are key to ethical scraping practices.



