

Big data refers to large amounts of rapidly generating, highly unstructured data that can be highly unreliable. Its collection and analysis, though challenging, are crucial for your business to remain competitive.
This article gives an overview of web scraping big data and the methods to analyze it.
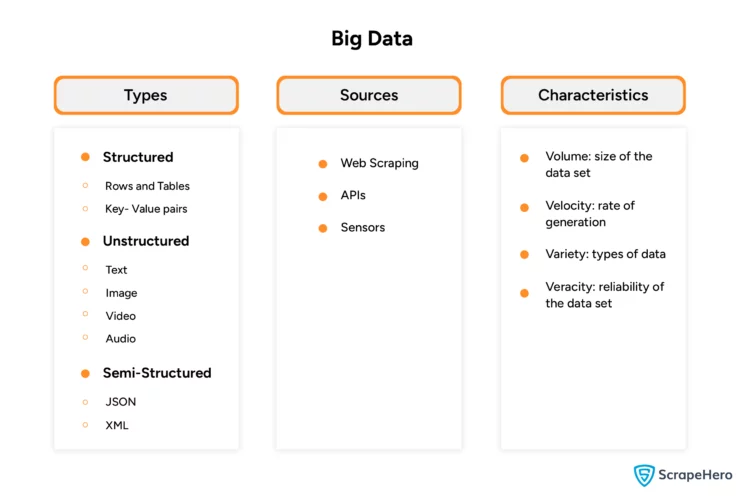
Sources of Big Data
You can perform big data extraction from various sources:
- APIs: You can get data from the APIs offered by various websites or social media. These may provide additional data or data in a more structured format.
- Sensors: IoT devices can collect data. These devices can store and transmit information regarding their usage.
- Web Scraping: You can extract vast quantities of public data online. This tutorial discusses big data web scraping using Python.
Data Types Included While Web Scraping Big Data
Data types in big data can be
- Structured
- Semi-Structured
- Unstructured
Structured data is what traditional data analysis uses. Two popular examples are
- Tables: Data organized in rows and columns, where you need two parameters to refer to a data point in tables.
- Key-value: Data organized as key-value pairs, where you can refer to a data point with one parameter, the key.
Semi-structured data has a structure that varies throughout the data set. For example
- XML/HTML: Stores data in various tags, giving it a structure. However, the tags’ names and positions are inconsistent throughout the data set.
- JSON: Stores data in key-value pairs, but the values could be arrays or another set of key-value pairs.
Unstructured data is everything else. These don’t have any structure or apparent patterns. It can include:
- Video
- Audio
- Text
Web Scraping Big Data Using Python
Big data scraping is possible with Python; it has several libraries dedicated to web scraping; for example,
- Python requests can get HTML data from websites via HTTP requests.
- BeautifulSoup can leverage HTML or XML parsers and provide intuitive methods to extract data.
- Selenium and Playwright can programmatically control a browser, making them suitable for scraping dynamic websites.
The above libraries can fetch structured, semi-structured, or unstructured data. Read on to get an overview of scraping each kind of data.
Tables
You can directly scrape tables using Pandas. The method read_html() of Pandas can extract data in tabular format from a URL; moreover, you can also use Pandas to clean the extracted data.
<pre><code> import pandas as pd # Import the pandas library for data manipulation # URL of the web page containing the table url = "http://example.com/table-data" # Use the read_html() method to scrape all tables from the URL tables = pd.read_html(url) # Assuming the table of interest is the first table (index 0) df = tables[0] # Print the first few rows of the dataframe print(df.head()) </code><pre>
HTML/XML
You can extract XML/HTML data using Python requests. The get() method of Python requests can send HTTP requests to a URL, and the resulting response will contain the HTML/XML data.
import requests
response = requests.get("https://example.com")
print(response.text)Python requests can get HTML/XML data from static websites. However, you require automated browsers like Playwright or Selenium to scrape dynamic websites.
You can visit the website using your preferred automated browser to extract the source code.
#import web driver from selenium
from selenium import webdriver
#launch the browser in a headless mode
options = webdriver.ChromeOptions()
options.add_argument("--headless=new")
browser = webdriver.Chrome(options=options)
# visit the website
browser.get("https://example.com")
# get the page source
print(browser.page_source)The above code
- Launches a Selenium browser
- Visits a website
- Gets the HTML source code
JSON
You can extract the JSON data from the XML/HTML. Usually, the script tag will have the JSON data. In that case, you can use Python requests to get the HTML data and BeautifulSoup to parse data and find the script tag.
soup = BeautifulSoup(response.text)
scripts = soup.find('script')Videos/Images
To scrape videos, you need to find the URL. You can get the URLs from the HTML/XML data fetched with Python requests or Selenium.
soup = BeautifulSoup(response.text)
video= soup.find('video')
image= soup.find(‘img’)Then, you use Python requests to fetch it; the process to get images is also similar.
videoContent= requests.get(video[‘src’])
imageContent= requests.get(image[‘src’])
with open("video","wb") as video:
video.write(videoContent.content)
with open("image","wb") as image:
image.write(imageContent.content)Text
You can parse and extract the text once you fetch the HTML/XML data. You can use BeautifulSoup for that. Find an element using the find method, and use the text attribute to extract the text.
soup = BeautifulSoup(response.text)
soup.textAnalyzing Big Data Using Python
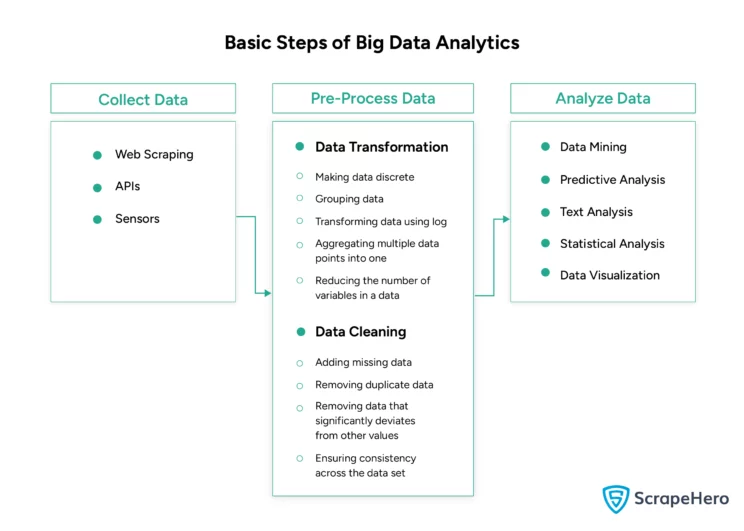
Big data analytics includes three steps:
- Collection
- Pre-Processing
- Analysis
Web scraping comes under the first step.
The second step involves preparing the data for analysis. This step is crucial, as poor pre-processing can lead to inaccurate results.
Pre-processing involves data cleaning and data transformation.
Data transformation makes the data more suitable for analysis. It involves
- Making data discrete
- Grouping data
- Transforming data using log
- Aggregating multiple data points into one
- Reducing the number of variables in a data
Data cleaning makes the data more reliable. It involves
- Adding missing data
- Removing duplicate data
- Removing data that significantly deviates from other values
- Ensuring consistency across the data set
You can use Python for pre-processing. There are libraries dedicated to handling each type of data. Examples include
- Pandas for structured data: it consists of several methods for cleaning data. For example, its dropna() method can remove rows with missing values.
import pandas as pd # Import the pandas library for data manipulation # Load the dataset into a dataframe from a CSV file df = pd.read_csv("data.csv") # Remove rows with missing values using the dropna() method df = df.dropna() # Print the first few rows of the cleaned dataframe print(df.head()) - Scikit-image for images: it has functions for image manipulation, including filtering (applying filters) and segmentation (making sections of an image).
from skimage import io, filters # Import the skimage library for image processing # Read the image from a file image = io.imread("image.jpg") # Apply the Sobel filter to detect edges in the image edges = filters.sobel(image) # Display the edges using the io module io.imshow(edges) io.show() - OpenCV for tasks requiring computer vision: It can read videos and convert them into frames; you can then process each frame.
import cv2 # Import the OpenCV library for computer vision tasks # Open the video file cap = cv2.VideoCapture("video.mp4") # Loop through the video frames while cap.isOpened(): ret, frame = cap.read() # Read a frame from the video if not ret: break # Exit the loop if no more frames # Convert the frame to grayscale gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # Display the grayscale frame cv2.imshow("frame", gray) # Break the loop if the "q" key is pressed if cv2.waitKey(1) & 0xFF == ord("q"): break # Release the video capture object and close all OpenCV windows cap.release() cv2.destroyAllWindows() - The os module for interacting with the operating system: It allows you to manage a directory, get environment variables, run programs, etc.
import os # Import the os module for interacting with the operating system # List files in a specified directory files = os.listdir("path_to_directory") # Print the list of files print(files)
After preprocessing comes the analysis, where you use various techniques to derive insights from data. A few of them are
- Data Mining: Understanding the patterns in the data sets and deriving insights.
- Predictive Analysis: Predicting future outcomes based on past data
- Deep Learning: Using neural networks to solve a problem
- Text Analysis: Deriving meaning out of large amounts of text using
- Statistical Methods: Using statistical methods to analyze data
Data Mining
The process tries to find relationships, patterns, and trends in a data set to derive meaningful conclusions. A popular data mining method is classification, where you classify data into categories.
For example, you can classify a person as someone who makes a specific purchase or someone who doesn’t based on their salary and age.
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Create a DataFrame
data_classification = {
'age': [22, 25, 47, 52, 46, 56, 55, 60, 62, 61, 30, 48, 33, 40, 28, 22, 25, 35, 29, 40],
'salary': [25000, 30000, 52000, 110000, 95000, 105000, 92000, 130000, 100000, 98000, 40000, 65000, 48000, 85000, 31000, 27000, 29000, 47000, 32000, 60000],
'purchased': [0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1] # 0 = No, 1 = Yes
}
df_classification = pd.DataFrame(data_classification)
# Prepare the features and target variable
X = df_classification[['age', 'salary']]
y = df_classification['purchased']
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
# Create and train a decision tree classifier
clf = DecisionTreeClassifier()
clf.fit(X_train, y_train)
# Make predictions on the test set
y_pred = clf.predict(X_test)
# Print the accuracy of the classifier
print(f"Accuracy: {accuracy_score(y_test, y_pred)}")
Predictive Analysis
Predictive analysis involves understanding past data to predict future results. Linear regression is one of the methods you can use to predict future outcomes; it assumes a linear relationship between a target variable and one or more features.
For example, you can assume that the experiences and salaries have a linear relationship and then use linear regression to make predictions.
import pandas as pd
from sklearn.linear_model import LinearRegression
# Create a DataFrame
data_regression = {
'years_experience': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
'salary': [45000, 50000, 60000, 65000, 70000, 75000, 80000, 85000, 90000, 95000]
}
df_regression = pd.DataFrame(data_regression)
# Prepare the features and target variable
X = df_regression[['years_experience']]
y = df_regression['salary']
# Create and train a linear regression model
reg = LinearRegression().fit(X, y)
# Make predictions on the training set
predictions = reg.predict(X)
# Print the predictions
print(predictions)Deep Learning
In deep learning, you use neural networks to find complex patterns from seemingly unstructured data. Neural networks are algorithms that operate similar to brain neurons.
Here is a code for training a model that predicts house prices from number rooms, square footage, and age of the houses.
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
import pandas as pd
# Create a DataFrame
data_deep_learning = {
'num_rooms': [3, 4, 2, 3, 4, 3, 5, 4, 2, 3],
'square_footage': [1500, 1800, 1200, 1600, 2000, 1500, 2500, 1800, 1100, 1700],
'age_of_house': [10, 15, 5, 10, 20, 10, 30, 25, 5, 12],
'price': [300000, 400000, 250000, 350000, 500000, 300000, 600000, 450000, 220000, 370000]
}
df_deep_learning = pd.DataFrame(data_deep_learning)
# Prepare the features and target variable
X = df_deep_learning[['num_rooms', 'square_footage', 'age_of_house']]
y = df_deep_learning['price']
# Define the input shape based on the features
input_shape = X.shape[1]
# Define a simple neural network model
model = Sequential([
Dense(64, activation='relu', input_shape=(input_shape,)), # Input layer
Dense(64, activation='relu'), # Hidden layer
Dense(1) # Output layer
])
# Compile the model with Adam optimizer and mean squared error loss function
model.compile(optimizer='adam', loss='mse')
# Train the model on the training data
model.fit(X, y, epochs=10, batch_size=32)
Text Analysis
Text analysis involves analyzing large amounts of text to derive meaning or information. For example,
- Sentiment Analysis: Understands the tone behind the text
from textblob import TextBlob # Import TextBlob for text processing # Sample text for sentiment analysis text = "I love programming in Python!" # Create a TextBlob object blob = TextBlob(text) # Print the sentiment of the text (polarity and subjectivity) print(blob.sentiment) - Text Extraction: Gets a particular information from the text
import re # Import the re module for regular expressions # Sample text containing a number text = "Sample text with a number 12345" # Find all sequences of digits in the text numbers = re.findall(r'\d+', text) # Print the extracted numbers print(numbers)
Statistical Methods
It uses traditional statistics on big data. Although the methods have limitations, they might prove useful in early stages of big data analytics, where you have to understand the characteristics and structure of data.
For example, central tendencies, like mean, can describe the data set.
import numpy as np # Import NumPy for numerical operations
# Sample data
data = [1, 2, 3, 4, 5, 6, 7, 8, 9]
# Calculate the mean of the data
np.mean(data)
Challenges in Big Data Analytics
Big data analytics is challenging because of its characteristics: velocity, volume, veracity, and variety.
- Velocity: rate of generation
- Volume: the size of the data set is
- Veracity: reliability of the data set
- Variety: data types in the data set
The magnitude of these is enormous.
Rapid data generation makes storing and processing more challenging. As this pace increases with the latest technology, it is essential to keep your infrastructure up-to-date.
The large volume adds further burden to your infrastructure. You must ensure adequate capacity to store big data as you need a considerable amount to derive meaningful insights.
Unreliability increases the work required for processing, making meticulous data cleaning crucial to ensure high-quality data.
Finally, the variety of data reduces the efficiency of web scraping big data as you can not have a single solution.
Wrapping Up
Big data is large, structured, or unstructured data that grows rapidly. Traditional data analysis techniques are inefficient for analyzing big data; its collection and storage are also challenging.
For both collection and analysis, you can use Python. For example, Python has libraries like Requests and BeautifulSoup for web scraping and Pandas and Scikit-learn for analysis.
However, it can be overwhelming to perform both web scraping and analysis. That is where ScrapeHero Services can help you.
We are a full-service web scraping service provider capable of building enterprise-grade scrapers and crawlers. You only have to provide the requirements, and we will deliver high-quality data that you can use to train your AI models.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data



