

As the volume of data on the web continues to grow, manual scraping becomes impractical. Web scraping tools and software can automate this process of collecting and structuring large datasets quickly and efficiently.
Whether for market research, price comparison, or lead generation, these tools can save time, improve accuracy, eliminate inefficiencies, and provide scalability to handle complex websites, all while reducing human error.
If you are looking for a cost-effective and reliable scraping tool, you can consider ScrapeHero Cloud, which clients highly recommend due to its simplicity and flexibility.

Apart from ScrapeHero Cloud, this blog will also discuss some of the best web scraping tools and software available on the market, along with their key features and pricing.
15 Best Web Scraping Software and Tools in 2025
Web scraping software and tools are crucial for anyone looking to gather data. Below is a curated list of the best web scraping tools, including free, open-source, and other options.
1. ScrapeHero Cloud
Scrapehero is an enterprise-grade web scraping service provider that offers a comprehensive set of data extraction tools as well as customized services.
ScrapeHero Cloud is an online marketplace from ScrapeHero that provides some of the best pre-built crawlers and real-time APIs for individuals with web data extraction requirements.
The platform enables anyone—whether a beginner or an expert—to collect data from popular websites, such as Amazon, Google, Walmart, and more, with just a few clicks.
Features
- ScrapeHero crawlers and APIs are designed even for users with no technical expertise, making web scraping accessible to everyone.
- You can schedule scrapers to run at specific intervals—hourly, daily, or weekly—ensuring data is always up-to-date.
- You can export data in popular formats, such as JSON, CSV, and Excel, making it easy to use the data in various applications.
- ScrapeHero offers both free and premium plans, with scalable options that cater to individuals and businesses with varying data requirements.
How to Use ScrapeHero Cloud
Let’s consider ScrapeHero Trulia Scraper. The following are the steps to set up the scraper:
1. Sign up or log in to your ScrapeHero Cloud account.
2. Go to the Trulia Scraper by ScrapeHero Cloud.
3. Click the Create New Project button.
4. To scrape the details, you need to provide the Trulia search results URL for a specific search query.
5. You can get the URL from the Trulia search results page.
In the field provided, enter a project name, Trulia URL, and the number of records you want to gather. Then, click the Gather Data button to start the scraper.
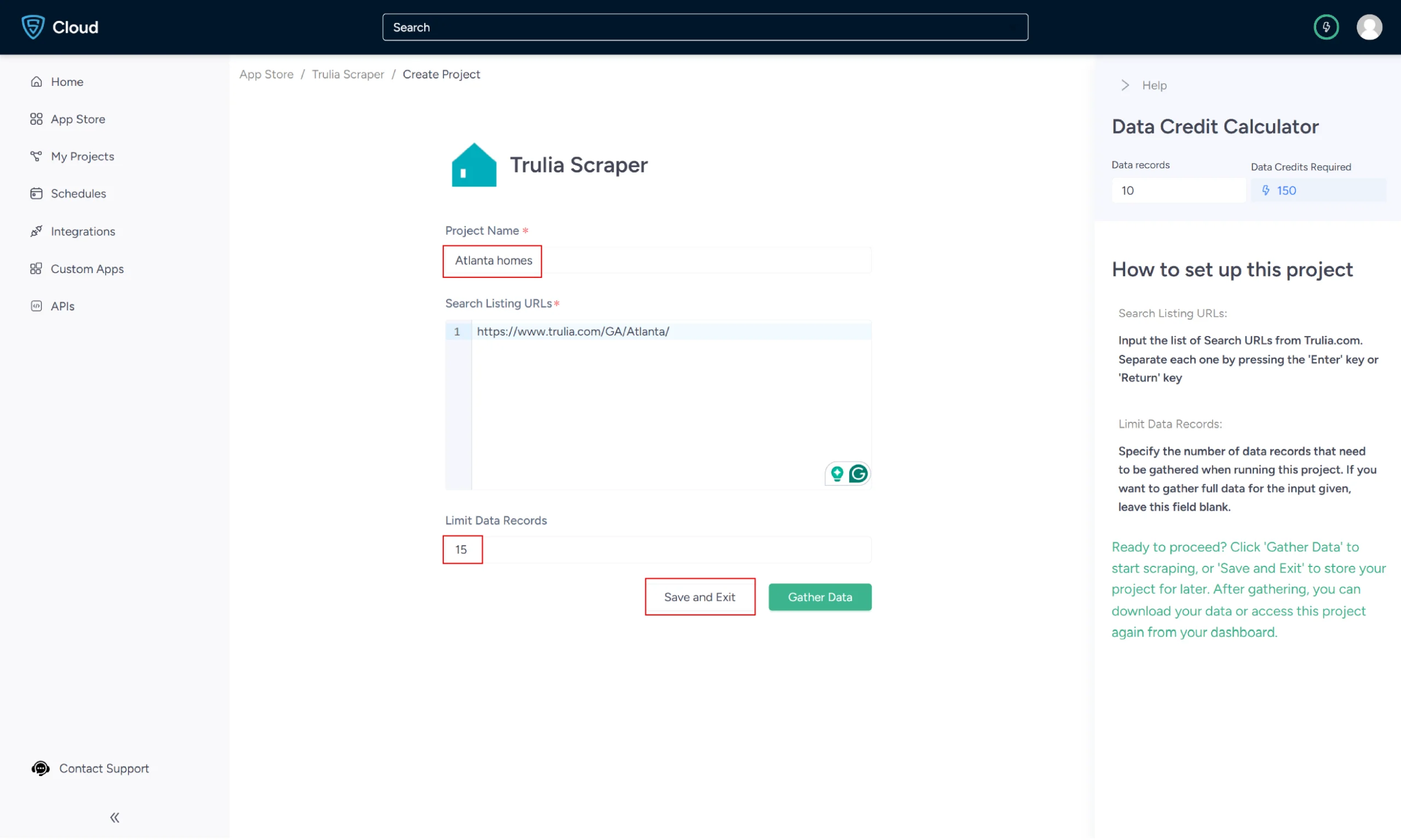
6. The scraper will start fetching data for your queries, and you can track its progress under the Projects tab.
7. Once it is finished, you can view the data by clicking on the project name. A new page will appear, and under the Overview tab, you can see and download the data.
8. You can also pull Trulia’s data into a spreadsheet from here. Click on ‘Download Data,’ select ‘Excel,’ and then open the downloaded file using Microsoft Excel.
Pricing
ScrapeHero Cloud offers flexible plans, both free and paid, for small-scale and large-scale data extraction.
You can opt for the Basic Plan, which is free and provides 400 data credits, 1 concurrent job, and 7 days of data retention, along with 10 API calls per minute and standard rotating proxies.
For more extensive scraping needs, you can choose from affordable paid plans, offering up to 4,000 credits per dollar.
Custom plans are also available for businesses with advanced requirements, offering tailored credit allocations, dedicated support, and customizable data retention periods.
To learn more about pricing, visit the ScrapeHero pricing page.
2. Web Unlocker- Bright Data
Bright Data’s Web Unlocker is a web scraping tool that enables data scraping without being blocked. The tool is designed to manage proxy and unblock infrastructure for the user.
Features
- Web Unlocker can handle site-specific browser user agents, cookies, and CAPTCHA solving.
- Web Unlocker scrapes data from websites that use automated IP address rotation.
- Web Unlocker adjusts in real-time to stay undetected by bots, which constantly develop new methods to block users.
- They also have live customer support 24/7.
Pricing
Web Unlocker follows a tiered subscription model ranging from a ‘pay as you go’ option to enterprise-level custom pricing. The price starts at $1.05 per 1,000 requests.
3. Web Unblocker- Oxylabs
Web Unblocker by Oxylabs is an AI-augmented web scraping tool. It manages the unblocking process and enables easy data extraction from websites of all complexities.
Features
- Web Unblocker offers a proxy-like integration and supports JavaScript rendering.
- This data scraping tool has a convenient dashboard to manage and track your usage statistics.
- Web Unblocker allows you to extend your sessions using the same proxy, enabling multiple requests.
Pricing
Web Unblocker offers a one-week free trial for users to test the tool. After the trial, pricing starts at $75 per month + VAT for 8 GB, billed monthly.
4. Octoparse
Octoparse is a visual web data extraction software explicitly designed for non-coders. Its point-and-click interface allows you to easily select the fields you need to scrape from a website.
Features
- Octoparse offers scheduled cloud extraction, wherein dynamic data is extracted in real-time.
- Octoparse has built-in Regex and XPath configurations to automate data cleaning.
- Octoparse provides cloud services and IP Proxy Servers to bypass reCAPTCHA and blocking.
- This web scraping tool features an advanced mode that allows for the customization of a data scraper to extract target data from complex websites.
Pricing
Octoparse offers a free version with 10 tasks per account. The standard plan, ideal for small teams, starts at $119 per month. They also provide custom enterprise plans.
5. Scrapy
Scrapy is an open-source web scraping framework in Python used to build web scrapers. It provides you with all the tools to efficiently extract data from websites, process it, and store it in your preferred structure and format.
Features
- Scrapy is built on top of a Twisted asynchronous networking framework.
- You can export data into JSON, CSV, and XML formats.
- Scrapy is popular for its ease of use, detailed documentation, and active community.
- It runs on Linux, Mac OS, and Windows systems.
Pricing
Since Scrapy is an open-source framework, it is available as a free web scraping tool.
6. Puppeteer
Puppeteer is a Node library that offers a powerful yet user-friendly API for managing Google’s headless Chrome browser. A headless browser refers to a browser that can communicate with websites but doesn’t display a graphical user interface (GUI).
The web scraping tool will operate quietly in the background, executing actions according to instructions provided by an API.
Features
- Puppeteer is an open-source data scraping tool that is useful for extracting information that relies on API data and JavaScript code.
- When you open a web browser, Puppeteer can take screenshots of web pages that are visible by default.
- Puppeteer automates form submission, UI testing, keyboard input, etc.
- This web scraping tool enables you to create an automated testing environment utilizing the latest JavaScript and browser features.
Pricing
Puppeteer is an open-source tool, and thus, it is a free web scraping tool.
7. Playwright
Playwright is a Node library developed by Microsoft, designed for automating web browsers. It allows you to write code that can initiate a web browser, employ automation scripts to visit websites, input text, click buttons, and extract data from the internet.

Features
- Playwright was developed to enhance automated UI testing by reducing unpredictability, speeding up execution, and providing in-depth insights into browser behavior.
- Playwright offers cross-browser support, enabling it to operate with Chromium, WebKit, and Firefox.
- It integrates with continuous integration platforms like Docker, Azure, CircleCI, and Jenkins.
Pricing
Like Puppeteer, Playwright is also an open-source library, making it a free web scraping tool.
8. Cheerio
Cheerio is a JavaScript library for parsing and manipulating HTML and XML documents. It’s ideal for quick web scraping as it doesn’t produce a visual rendering of the pages.
Features
- Cheerio allows the use of jQuery syntax while working with the downloaded data.
- It is a fast web scraping tool because it does not interpret the result as a web browser, produce a visual rendering, apply CSS, load external resources, or execute JavaScript.
- It is efficient in parsing large documents.
Pricing
Cheerio is a free and open-source web scraping tool.
9. Parsehub
Parsehub is an easy-to-use web scraping tool that crawls single and multiple websites. The easy-to-use, user-friendly web app can be built into the browser and comes with extensive documentation.
Features
- Parsehub is a web scraping tool that can handle websites that utilize JavaScript, AJAX, and other advanced features, such as cookies, sessions, and automatic redirections.
- Parsehub utilizes machine learning to parse the most complex websites, generating output files in JSON, CSV, Google Sheets, or via API.
- It can handle web pages with extensive content on a single page (such as infinite scrolling), pop-up windows, and menus.
- Parsehub enables you to view the collected data in Tableau, a program designed for visualizing data.
Pricing
Parsehub’s free version allows 5 public projects and 200 pages per run. The standard plan is $189 per month and offers 20 private projects with a limit of up to 10,000 pages per run.
10. Web Scraper.io
Web Scraper.io is a browser extension for Chrome and Firefox that helps you extract data from websites with multi-level navigation. It also offers cloud support for automated scraping.
Features
- The Web Scraper features a point-and-click interface that ensures easy web scraping.
- The Web Scraper provides complete JavaScript execution, waiting for Ajax requests, pagination handlers, and page scroll events.
- Web Scraper also allows you to build site maps using various types of selectors.
- You can export data in CSV, XLSX, and JSON formats or via Dropbox, Google Sheets, or Amazon S3.
Pricing
The Web Scraper Extension is a free web scraping tool and provides local support. The pricing ranges from $50 and can exceed $200 monthly for additional capabilities, including cloud and parallel tasks.
11. Apify
Apify is a cloud-based web data extraction platform that offers ready-made web scraping tools and custom scraping solutions. You can build scraping bots without coding, schedule scraping tasks, and manage scraped data using this web scraping tool.

Features
- Apify lets you create scraping bots without coding through a drag-and-drop interface.
- Apify offers a public scraper library, allowing you to access and utilize pre-built scrapers for popular websites.
- It has a versatile actor system for various web scraping and automation tasks.
- This web scraping tool can be connected with popular platforms like Zapier, Google Sheets, and Slack for streamlined workflows.
Pricing
Apify offers a free plan with limited resources. Premium plans range from a basic tier to custom enterprise solutions, with pricing varying based on resource usage.
12. Browse AI
Browse AI offers AI-powered web scraping with advanced features, including dynamic rendering, JavaScript execution, and anti-bot detection bypass. It provides both a visual scraper builder and a coding interface for experienced users.
Features
- This web scraping tool can bypass advanced bot detection countermeasures to avoid getting blocked.
- You can access Browse AI’s functionality through a robust API for seamless integration with your applications.
Pricing
Browse AI offers a free trial; paid plans start at $19 per month with varying resource allocations.
13. SerpAPI
SerpAPI focuses on search engine result page (SERP) scraping, providing access to search results from various search engines, including Google, Bing, and DuckDuckGo.
You can extract organic and paid search results, analyze SERP features, and track keyword rankings using this web data extraction tool.
Features
- SerpAPI can extract both organic and paid search results, including titles, URLs, snippets, and ad details.
- This web scraper can be used to track keyword rankings over time and across various search engines and locations, allowing for the monitoring of SEO performance.
- It lets you access real-time search results through SerpAPI’s powerful API for instant data retrieval.
Pricing
SerpAPI’s free plan has limited features; paid plans start at $75 per month for developers.
14. Clay.com
Clay.com is a visual web scraping tool that enables non-technical users to automate scraping tasks. It offers easy scheduling and data export to various formats.
Features
- Clay.com features a point-and-click functionality that allows you to extract data with just a few clicks.
- You can schedule scraping tasks to run automatically at specific intervals, ensuring you never miss valuable data updates.
- It is possible to export scraped data in various formats like CSV, JSON, and Excel.
- You can connect Clay.com with popular tools like Google Sheets and Zapier.
Pricing
Clay.com has plans that cater to a range of users, from individuals to large enterprises, with pricing reflecting the level of resources and features provided.
15. Selenium
Selenium is an open-source tool for automating web browsers, often used by experienced developers for web scraping and data extraction. It supports various programming languages, including Python, Java, and C#.

Features
- Control web browsers like Chrome, Firefox, and Edge programmatically for precise scraping tasks.
- Selenium can execute JavaScript code on scraped pages to access dynamic content and hidden data.
- With Selenium, you can run scraping tasks in the background without opening a browser window, resulting in increased efficiency.
- It provides extensive customization options and granular control over scraping behavior for advanced web data extraction needs.
Pricing
Selenium is a free web scraping tool, but it requires a good amount of coding knowledge and setup effort, as it is a sophisticated framework for browser automation.
Why ScrapeHero Web Scraping Service?
The scale and complexity of online data can be overwhelming, especially without technical expertise.
While basic web scraping tools work for smaller, straightforward tasks, they often struggle with large-scale or complex data extraction.
However, web scraping tools and software struggle to handle large-scale web scraping and complex logic, bypass CAPTCHA and do not scale well when the volume of websites is high.
ScrapeHero web scraping service is a better and more economical option in such cases. For businesses that require scalable, hassle-free web scraping, we offer a more economical and efficient solution, ensuring clean, structured data without the complexities of managing teams and tools.
Frequently Asked Questions
To automate data collection, save time, and enable businesses to gather valuable insights from websites efficiently, you need web data extraction tools in 2025.
The top web scrapers for market research in 2025 are ScrapeHero, Apify, and Bright Data. These tools help extract valuable insights from competitor websites quickly.
You can use ScrapeHero Cloud which is an easy-to-use, no-code platform for data collection and extraction. It provides ideal web scraping software for non-technical users.



