

Scraping the Google Play Store allows developers and businesses to remain competitive. And there are various ways to do so; this article shows you two methods to scrape the Google Play Store.
- A no-code solution using ScrapeHero Cloud
- A code-based solution using Python Playwright

The No-Code Solution: ScrapeHero Play Store Scraper
If you want a reliable and maintenance-free way to scrape Google Play Store, a no-code tool like ScrapeHero Cloud’s Google Play Store Reviews Scraper can be an excellent choice.
Here’s how to get started with the Google Play Store scraper for free:
1. Log in to your ScrapeHero Cloud account. You can easily do so by logging in with Google.

2. Navigate to the Google Play Store Reviews Scraper in the ScrapeHero Apps store.
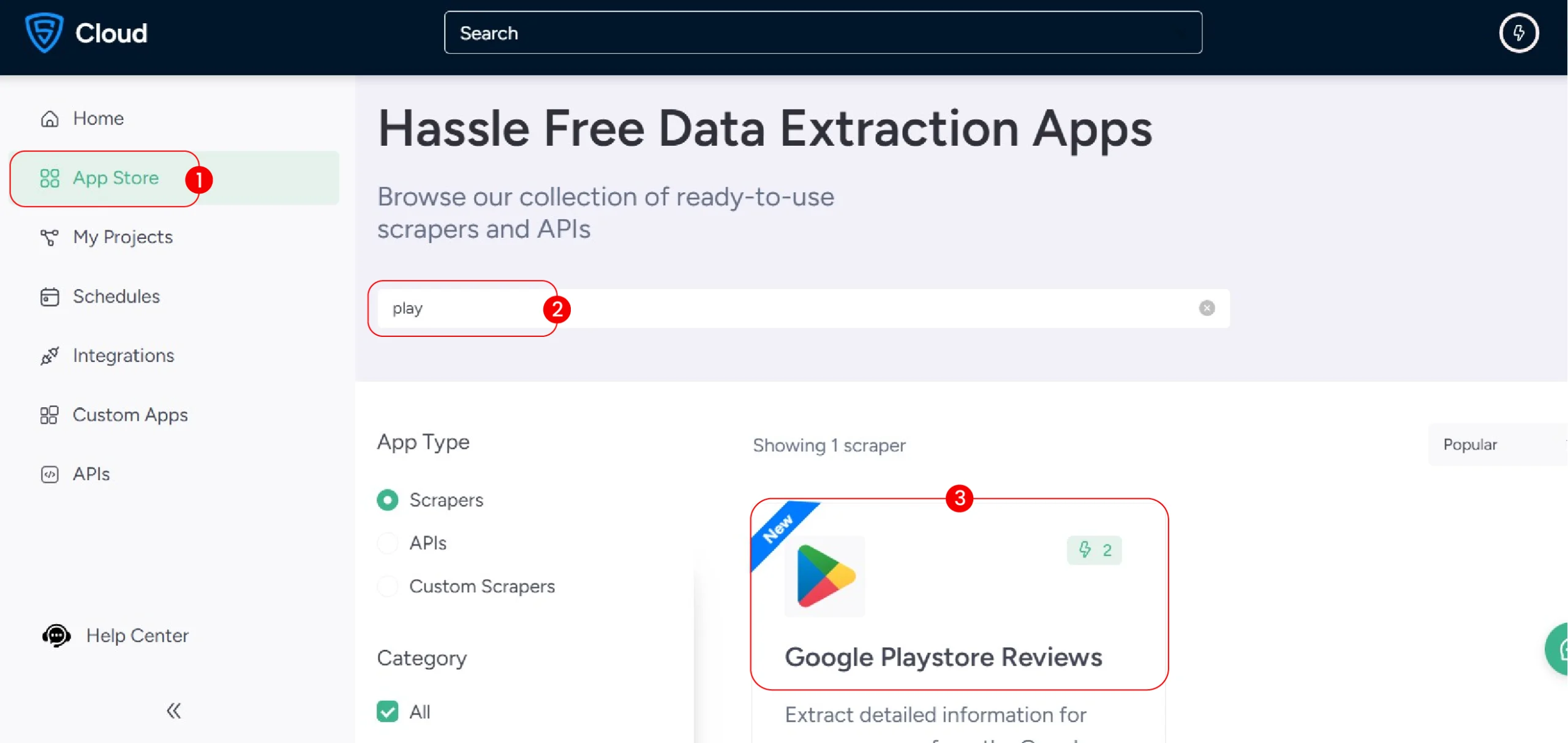
3. Click on “Create New Project”
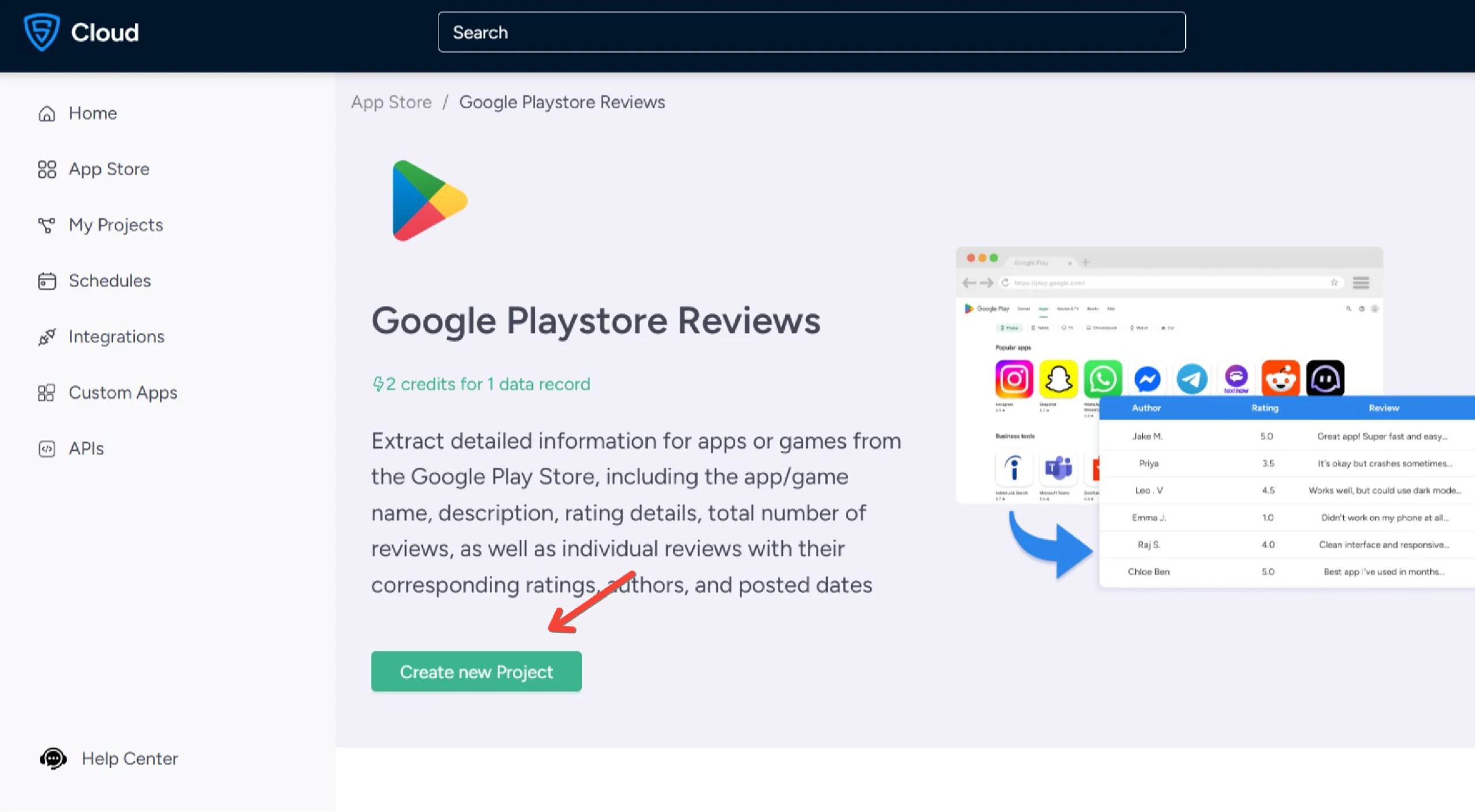
4. Go to “https://play.google.com”, search for any product, and copy the URL.
5. Name your project
6. Paste the URL into the scraper’s input.
7. Click “Gather Data” to start the scraper.
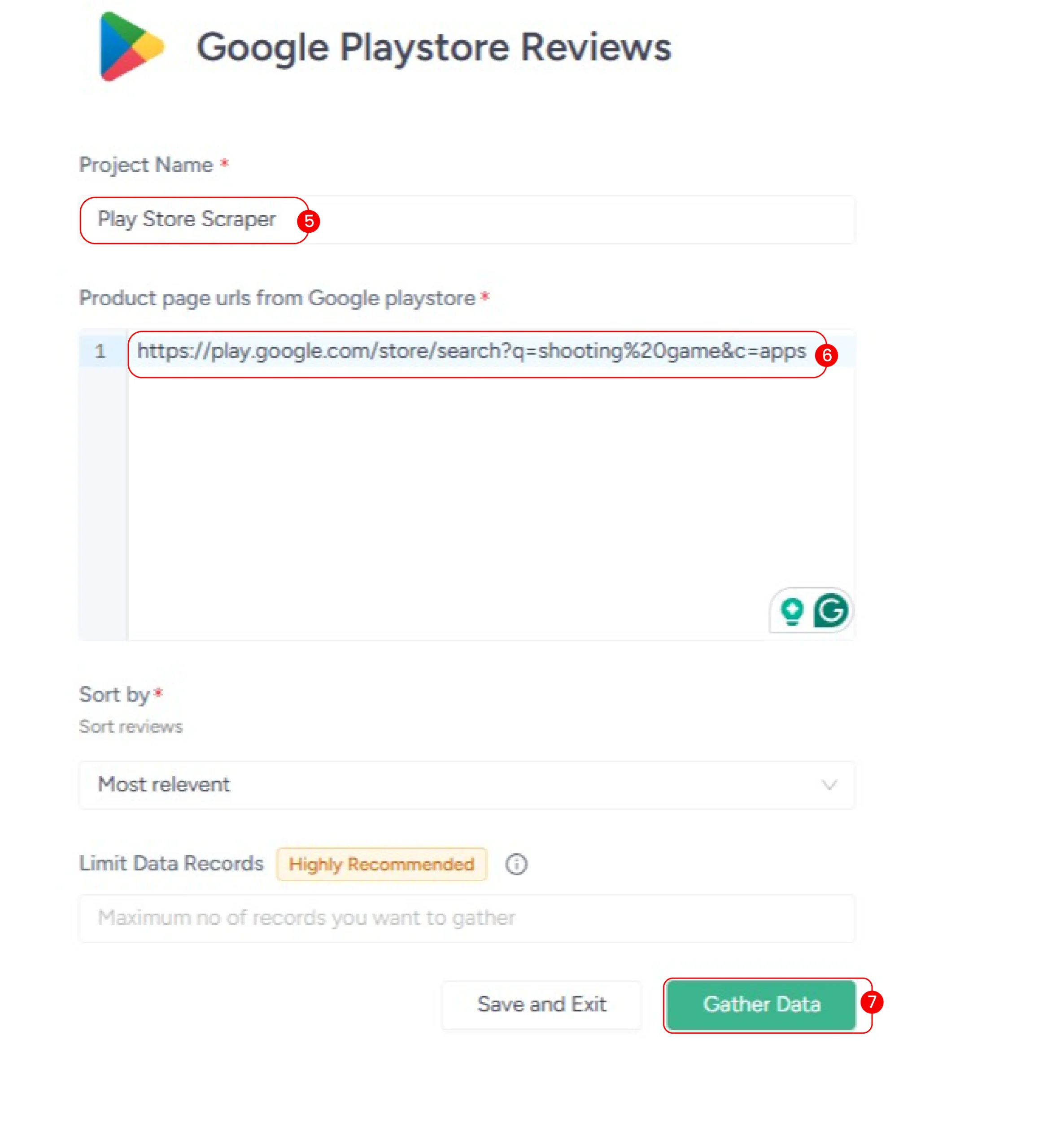
The scraper will extract the review details in a few minutes, which you can download in your preferred format (CSV, JSON, Excel)
Besides these, ScrapeHero Cloud’s premium features also include:
-
- Cloud Storage Integration: Automatically send your scraped data to services like S3, Google Cloud Storage, etc.
- Scheduling: Set up periodic scrapes to monitor changes in app rankings and reviews over time.
- API Integration: Access your structured data directly via an API to feed it to your custom dashboards automatically.
The Code-Based Method: Scrape Google Play Store Using Playwright
For developers who prefer a hands-on approach to scrape play.google.com, here’s a code-based solution that uses Playwright for web scraping.
Setting Up The Environment
To run the provided code, you need to install the necessary Python libraries. The code relies on ‘playwright,’ a modern browser automation library that can handle dynamic content rendered by JavaScript.
Install the Playwright library using PIP.
pip install playwright
You also need to install the Playwright browser separately.
playwright install
Data Scraped from the Play Store
The Python script extracts two sets of data points:
From Search Listings:
- App Name: The title of the application or the game
- Publisher: The name of the company or developer who published the app
- Rating: The average user rating out of 5
- URL: The direct link to the app’s main page on the Play Store
From Individual App Pages:
- Review Author: The name of the user who left the review
- Review Rating: The individual star rating given by the user
- Review Date: The date when the user published the review
- Review Text: The full text content of the user’s review
The provided script uses CSS selectors to locate these data points. You can figure them out by inspecting each data point using your browser’s DevTools:
- Right-click on an element
- Click Inspect
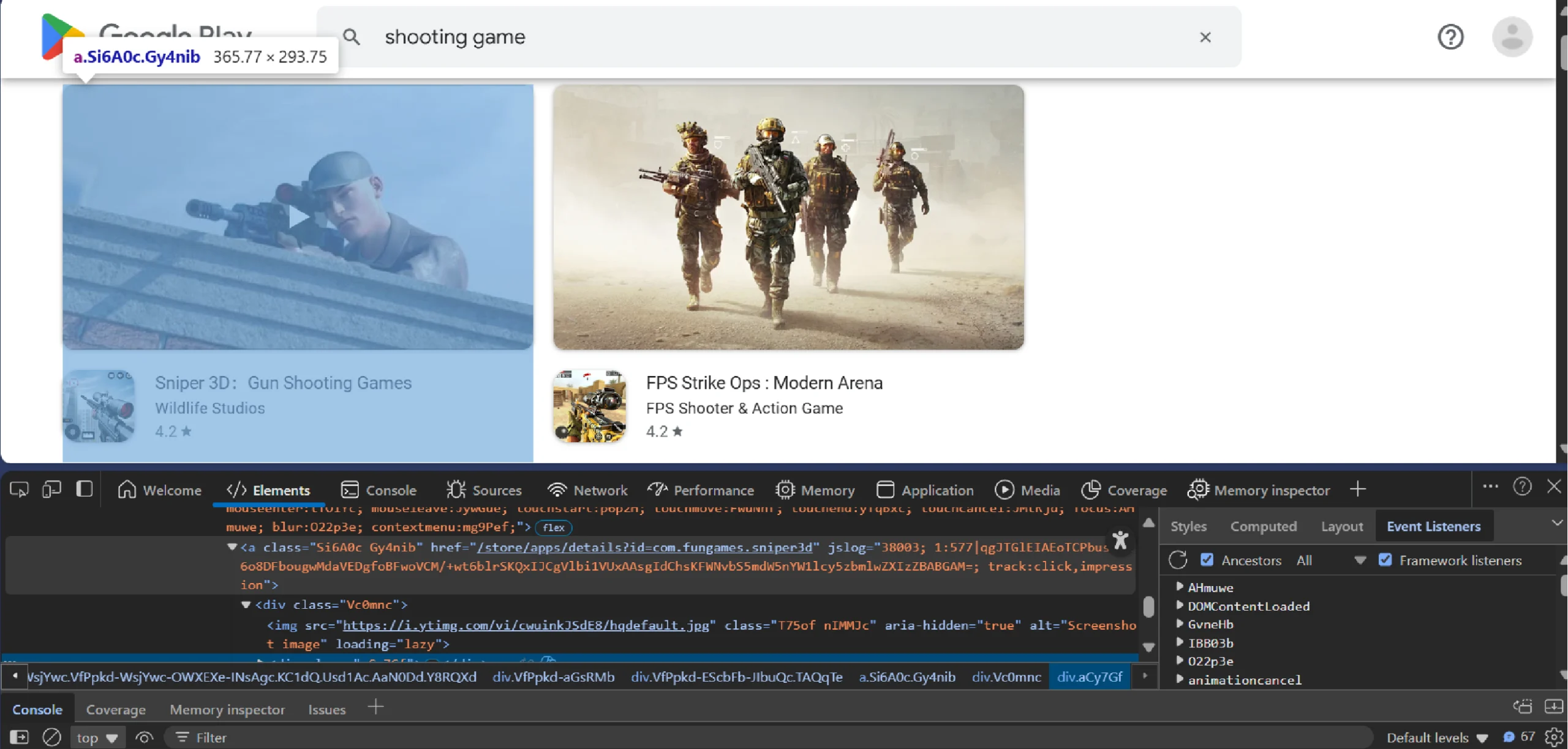
Scrape Google Play Store: The Code
Here’s the complete code for Play Store data extraction, if you would like to start using it immediately.
from playwright.sync_api import sync_playwright
import json
def scrape_listings(search_term):
with sync_playwright() as p:
# Launch browser (use headless=True for production)
browser = p.chromium.launch()
page = browser.new_page()
# Navigate to the search URL
search_url = f"https://play.google.com/store/search?q={search_term}%20games&c=apps"
page.goto(search_url)
# Extract app data using the selectors
app_elements = page.get_by_role('listitem').all()
results = []
for app in app_elements:
try:
anchor_tag = app.get_by_role('link')
url = anchor_tag.get_attribute("href")
details = app.all_inner_texts()
for detail in details:
text = detail.split("\n")
results.append(
{
"Name": text[0],
"Publisher": text[1],
"Rating": text[2],
"URL": "https://play.google.com" + url,
}
)
except Exception as e:
print(f"Error extracting app data: {e}")
continue
return results
def get_reviews(results):
with sync_playwright() as p:
# Launch browser (use headless=True for production)
browser = p.chromium.launch()
for result in results[:10]:
url = result["URL"]
page = browser.new_page()
page.goto(url)
review_button = page.get_by_role('button', name='See more information on Ratings and reviews', exact=True)
review_button.click()
reviews = page.locator('div.RHo1pe').all()
review_details = []
for review in reviews:
author = review.locator('div.X5PpBb').text_content()
rating = review.locator('div.Jx4nYe > div').get_attribute(
"aria-label"
).split()[1]
date = review.locator('span.bp9Aid').text_content()
text = review.locator('div.h3YV2d').text_content()
review_details.append({
"Author": author,
"Rating": rating,
"Date": date,
"Text": text,
})
result["Reviews"] = review_details
return results
# Run the scraper
if __name__ == "__main__":
search_term = input("What do you want to search?")
data = scrape_listings(search_term)
data_with_reviews = get_reviews(data)
with open(f'{search_term}.json','w',encoding='utf-8') as f:
json.dump(data_with_reviews,f,indent=4,ensure_ascii=False)
Let’s go through the code above and explain how it works. Start by importing the necessary libraries:
- playwright manages Google Play data extraction
- json module manages data storage
from playwright.sync_api import sync_playwright
import json
Create a function that accepts a search term and returns relevant game listings. This function serves as the scraper’s entry point.
def scrape_listings(search_term):
Start the function by launching the Playwright browser using chromium.launch() and initialize a new page using the new_page() method.
with sync_playwright() as p:
browser = p.chromium.launch()
page = browser.new_page()
Then, use goto() to navigate to the Play Store search results page.
search_url = f"https://play.google.com/store/search?q={search_term}%20games&c=apps"
page.goto(search_url)
Locate all listings using the method get_by_role(). This built-in method of Playwright is more reliable than CSS selectors.
app_elements = page.get_by_role('listitem').all()Process each listing individually, extracting both the URL and all textual content. Although most elements follow a predictable pattern, implement error handling to manage unexpected structure variations.
results = []
for app in app_elements:
try:
anchor_tag = app.get_by_role('link')
url = anchor_tag.get_attribute("href")
details = app.all_inner_texts()
Parse the extracted text by splitting on newline characters, then map the segments to specific data fields, including app and publisher names.
for detail in details:
text = detail.split("\n")
results.append(
{
"Name": text[0],
"Publisher": text[1],
"Rating": text[2],
"URL": "https://play.google.com" + url,
}
)
except Exception as e:
print(f"Error extracting app data: {e}")
continue
Finally, end the function by returning the collected results.
return results
Next, define a second function that accepts the initial results and appends them with review data.
def get_reviews(results):
This function also begins by launching a browser instance.
with sync_playwright() as p:
# Launch browser (use headless=True for production)
browser = p.chromium.launch()
Then, it iterates through a limited subset of the results list, processing only the first ten items.
for result in results[:10]:
For each listing,
- Get its URL
- Initialize a new page
- Go to the URL using goto()
- Locate a button with the aria-label “see more information on Rating and reviews” using get_by_locator()
- Click the button using click() to reveal all the reviews.
url = result["URL"]
page = browser.new_page()
page.goto(url)
review_button = page.get_by_role('button', name='See more information on Ratings and reviews', exact=True)
review_button.click()
Still inside the loop, identify all the review containers using page.locator(). These containers hold details, including the author, date, and the text of the reviews.
reviews = page.locator('div.RHo1pe').all()
From each review container, extract four key data points:
- Author name
- Rating
- Review Date
- Review Text
review_details = []
for review in reviews:
author = review.locator('div.X5PpBb').text_content()
rating = review.locator('div.Jx4nYe > div').get_attribute(
"aria-label"
).split()[1]
date = review.locator('span.bp9Aid').text_content()
text = review.locator('div.h3YV2d').text_content()
This code uses CSS selectors to locate the element holding the data point and then extracts the text content, except in the case of rating. The code gets the rating from an aria-label.
Store the extracted review data into a structured dictionary and end the loop.
review_details.append({
"Author": author,
"Rating": rating,
"Date": date,
"Text": text,
})
Now, end the earlier loop by adding this dictionary as another item in the listing dictionary with the key as “reviews”.
result["Reviews"] = review_details
Finally, end the get reviews() function by updating the results list.
return results
The main execution performs three actions:
- Prompts the user for a search term
- Uses the search term as an argument and calls scrape_listings()
- Calls get_reviews() with data returned by scrape_listings()
- Saves the extracted details to a JSON file using json.dump().
if __name__ == "__main__":
search_term = input("What do you want to search?")
data = scrape_listings(search_term)
data_with_reviews = get_reviews(data)
with open(f'{search_term}.json','w',encoding='utf-8') as f:
json.dump(data_with_reviews,f,indent=4,ensure_ascii=False)
The data extracted will look like this:
{
"Name": "Minecraft: Dream it, Build it!",
"Publisher": "Mojang",
"Rating": "4.6",
"URL": "https://play.google.com/store/apps/details?id=com.mojang.minecraftpe",
"Reviews": [
{
"Author": "Asha",
"Rating": "5",
"Date": "September 1, 2025",
"Text": "In Minecraft, the entire world is made up of blocks. You can break these blocks, collect resources, and build anything you want. From simple huts to giant castles, from farms to roller coasters — there is no limit to what you can create. The game encourages you to explore, survive, and design your own adventures. Unlike many other games, there is no fixed story. You make your own journey and decide how you want to places ✔️✔️☺️😊"
},
{
"Author": "Chitrang Koli",
"Rating": "5",
"Date": "August 30, 2025",
"Text": "Minecraft is one of the most engaging games I’ve played. Every world feels like a new challenge where you must gather resources, craft tools, and survive against mobs. Exploring caves and fighting through the night brings real excitement. Each update adds fresh challenges, keeping the game interesting. It’s unpredictable, sometimes tough, but that makes every achievement rewarding. A game that never gets boring and truly deserves 5 stars."
}
]
}
Code Limitations
This code can certainly help you get started with Google Play web scraping, but it has several limitations:
- The code depends on CSS selectors, which means UI updates may break the scraper, requiring constant maintenance.
- The script doesn’t include proxy rotation or rate limiting, making it susceptible to IP blocking.
- The script only scrapes the basic set of fields. If you need additional data, you need to update the code.
- Browser automation libraries are resource-intensive, requiring extensive infrastructure for large-scale projects.
Why Web Scraping Service Is a Better Choice
The limitations of the custom code highlight why a dedicated web scraping service is often a better choice. Maintaining code, setting up proxies, and handling anti-bot systems, etc., require considerable time and resources.
A web scraping service like ScrapeHero can handle these complexities for you.
ScrapeHero is an enterprise-grade web scraping service provider. We can provide high-quality data for your specific needs, so that you can focus on analyzing the data rather than fighting technical battles.
FAQs
The most likely cause is that the Play Store updated the HTML page, meaning the structure changed. You now need to inspect the data points again, figure out the new selectors, and update the code.
Yes, you can use other browser automation libraries, like Selenium and Puppeteer. You can also use Python requests to scrape data by extracting data from the script tags.
We used Playwright’s get_by_role() it is more resilient to UI changes. That is because it locates elements based on their ARIA roles (buttons, link, textbox), which are defined from a user’s perspective. This means slight changes in the Play Store’s HTML structure (classes, ids, etc.) is less likely to break the script as long as the roles don’t change.


