
Gathering travel data regarding flights is a mammoth task when done manually. There are hundreds of thousands of combinations of airports, routes, timings and ever changing prices. Ticket prices tend to vary daily (or even hourly), and there are a large number of flights available per day. Web Scraping is one of the solutions to keep track of this data. In this tutorial, we will scrape Expedia, a leading travel booking website to extract details on flights. Our scraper will extract the flight schedules and prices for a source and destination pair.
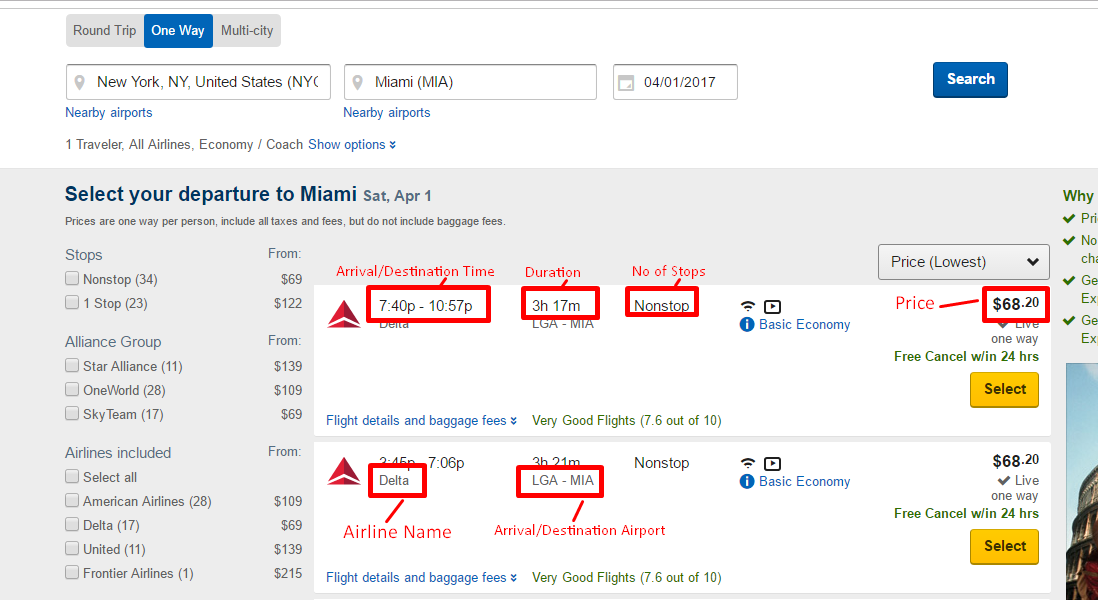
Here is a list of fields that we will be extracting:
- Arrival Airport
- Arrival Time
- Departure Airport
- Departure Time
- Plane Name
- Airline
- Flight Duration
- Plane Code
- Ticket Price
- No of Stops
Below is a screenshot of some of the data we will be extracting
Scraping Logic
- Construct the URL of the search results from Expedia- Here is one for the available flights listed from New York to Miami –https://www.expedia.com/Flights-Search?trip=oneway&leg1=from:New%20York,%20NY%20(NYC-All%20Airports),to:Miami,%20Florida,departure:04/01/2017TANYT&passengers=children:0,adults:1,seniors:0,infantinlap:Y&mode=search
- Download HTML of the search result page using Python Requests.
- Parse the page using LXML – LXML lets you navigate the HTML Tree Structure using Xpaths. We have predefined the XPaths for the details we need in the code.
- Save the data to a JSON file. You can later modify this to write to a database.
Requirements
For this web scraping tutorial using Python 3, we will need some packages for downloading and parsing the HTML. Below are the package requirements.
Install Python 3 and Pip
Here is a guide to install Python 3 in Linux – http://docs.python-guide.org/en/latest/starting/install3/linux/
Mac Users can follow this guide – http://docs.python-guide.org/en/latest/starting/install3/osx/
Windows Users go here – https://www.scrapehero.com/how-to-install-python3-in-windows-10/
Install Packages
- PIP to install the following packages in Python (https://pip.pypa.io/en/stable/installing/)
- Python Requests, to make requests and download the HTML content of the pages ( http://docs.python-requests.org/en/master/user/install/).
- Python LXML, for parsing the HTML Tree Structure using Xpaths (Learn how to install that here – http://lxml.de/installation.html)

The Code
The code is self-explanatory.
https://gist.github.com/scrapehero/bc34513e2ea72dc0890ad47fbd8a1a4f
If the embed above doesn’t work, you can download the code from the link here.
If you would like the code in Python 2, you can check out the link here.
Running The Expedia Scraper
Assume the script is named expedia.py. If you type in the script name in command prompt or terminal along with a -h
usage: expedia.py [-h] source destination date
positional arguments:
source Source airport code
destination Destination airport code
date MM/DD/YYYY
optional arguments:
-h, --help show this help message and exit
The arguments source and destination are the airport codes for the source and destination airports. The date argument should be in the format MM/DD/YYYY.
As an example, to find the flights listed from New York to Miami we would put the arguments like this:
python3 expedia.py nyc mia 04/01/2017
This will create a JSON output file called nyc-mia-flight-results.json that will be in the same folder as the script.
The output file will look similar to this:
{
"arrival": "Miami Intl., Miami",
"timings": [
{
"arrival_airport": "Miami, FL (MIA-Miami Intl.)",
"arrival_time": "12:19a",
"departure_airport": "New York, NY (LGA-LaGuardia)",
"departure_time": "9:00p"
}
],
"airline": "American Airlines",
"flight duration": "1 days 3 hours 19 minutes",
"plane code": "738",
"plane": "Boeing 737-800",
"departure": "LaGuardia, New York",
"stops": "Nonstop",
"ticket price": "1144.21"
},
{
"arrival": "Miami Intl., Miami",
"timings": [
{
"arrival_airport": "St. Louis, MO (STL-Lambert-St. Louis Intl.)",
"arrival_time": "11:15a",
"departure_airport": "New York, NY (LGA-LaGuardia)",
"departure_time": "9:11a"
},
{
"arrival_airport": "Miami, FL (MIA-Miami Intl.)",
"arrival_time": "8:44p",
"departure_airport": "St. Louis, MO (STL-Lambert-St. Louis Intl.)",
"departure_time": "4:54p"
}
],
"airline": "Republic Airlines As American Eagle",
"flight duration": "0 days 11 hours 33 minutes",
"plane code": "E75",
"plane": "Embraer 175",
"departure": "LaGuardia, New York",
"stops": "1 Stop",
"ticket price": "2028.40"
},
You can download the code at https://gist.github.com/scrapehero/bc34513e2ea72dc0890ad47fbd8a1a4f
Let us know in the comments how this scraper worked for you.
Known Limitations
This scraper should work for extracting most flight details available on Expedia unless the website structure changes drastically. If you would like to scrape the details of thousands of pages at very short intervals, this scraper is probably not going to work for you. You should read Scalable do-it-yourself scraping – How to build and run scrapers on a large scale and How to prevent getting blacklisted while scraping.
If you need professional help with scraping complex websites, contact us by filling up the form below.
Tell us about your complex web scraping projects
Turn the Internet into meaningful, structured and usable data
Disclaimer: Any code provided in our tutorials is for illustration and learning purposes only. We are not responsible for how it is used and assume no liability for any detrimental usage of the source code. The mere presence of this code on our site does not imply that we encourage scraping or scrape the websites referenced in the code and accompanying tutorial. The tutorials only help illustrate the technique of programming web scrapers for popular internet websites. We are not obligated to provide any support for the code, however, if you add your questions in the comments section, we may periodically address them.


