
Are you thinking of web scraping Alibaba? Search no more. Here is how to scrape data from Alibaba using Python.
Python has several modules for web scraping. This tutorial will show how to scrape Alibaba products using Python’s Playwright module. The module allows you to surf websites programmatically using its unique browser.
Setting up the Environment for Web Scraping Alibaba
Install Playwright and SelectorLib using the pip package manager.
pip install selectorlib playwrightThen, install the Playwright browser.
playwright installUse SelectorLib to Get CSS Elements
Here, you will use a YAML file to provide information about the elements you want to scrape. SelectorLib will help you create this YAML file. It is a convenient tool to select elements from a web page to get their CSS selectors.
You can install SelectorLib as a Chrome extension. After installation, you can find it in your browser’s developer tools.
General steps to get CSS elements using SelectorLib,
- Go to the page you want to scrape from Alibab.com and open SelectorLib in Developer Tools.
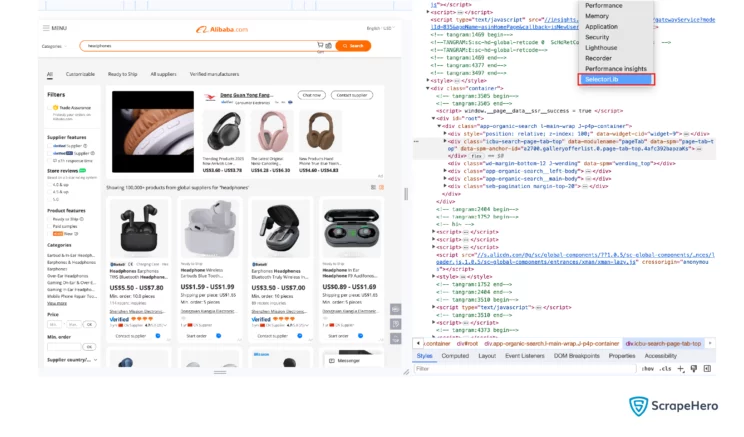
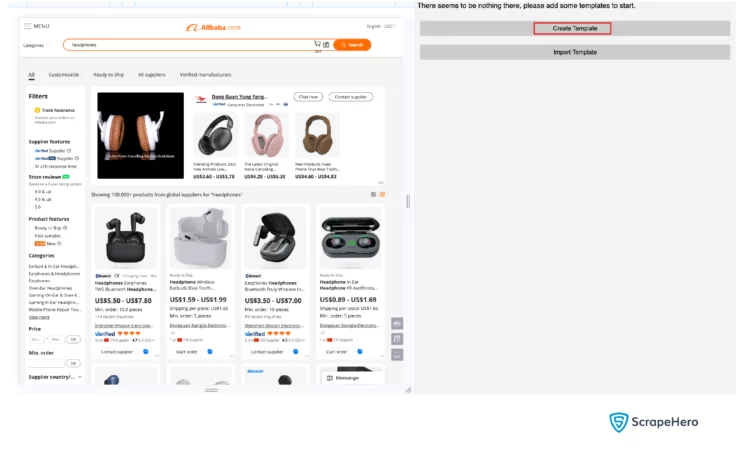
- Click on Create Template and enter the desired name.
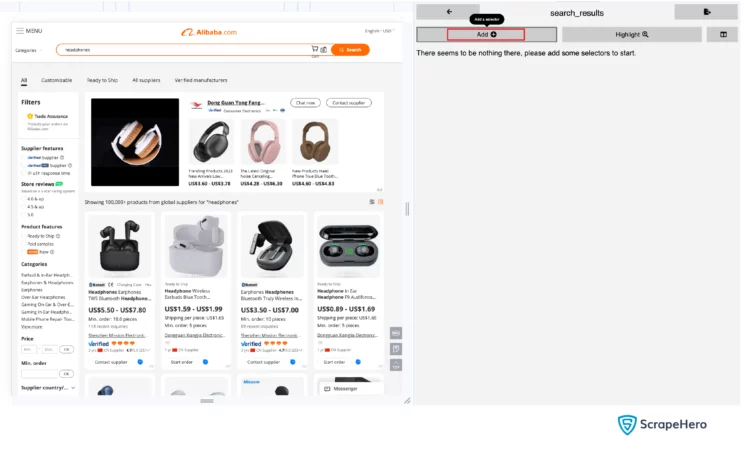
- Click Add, and select the type of the selector.
- Click Select Element and then select the HTML element on the web page. To select an HTML element, you must hover over it; this will highlight the element. Then click, and you will see the CSS selector in the corresponding text box.
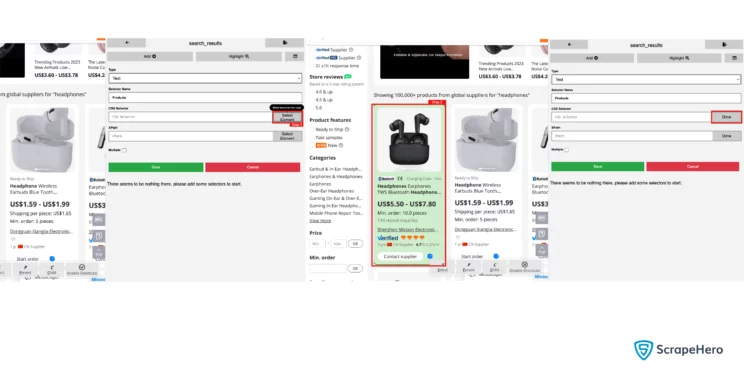
- Click save, and you will get the following screen.
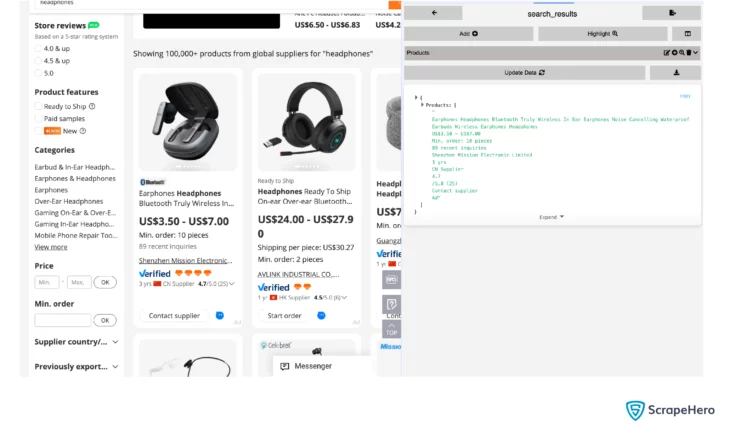
You can then create child elements by clicking on the plus sign on a parent element.
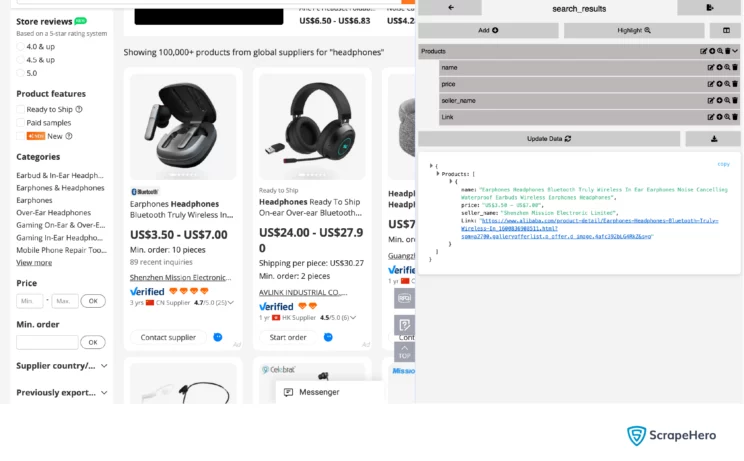
Finally, you can export the content as a YAML file.
Products:
css: 'div.fy23-search-card:nth-of-type(1)'
xpath: null
type: Text
children:
name:
css: 'h2.search-card-e-title span'
xpath: null
price:
css: div.search-card-e-price-main
xpath: null
type: Text
seller_name:
css: a.search-card-e-company
xpath: null
type: Text
Link:
css: a.search-card-e-slider__link
xpath: null
type: LinkYou can see from the YAML file that this tutorial scrapes four data points:
- Name
- Price
- Seller Name
- Link
Here, the code only scrapes data from the product search results page, which has these details. However, you can also write code to go to the product page and extract more information. Keep in mind that the code will then require more time to finish.
The code for Web Scraping Alibaba
The code has several defined functions. Here is their basic logical flow.
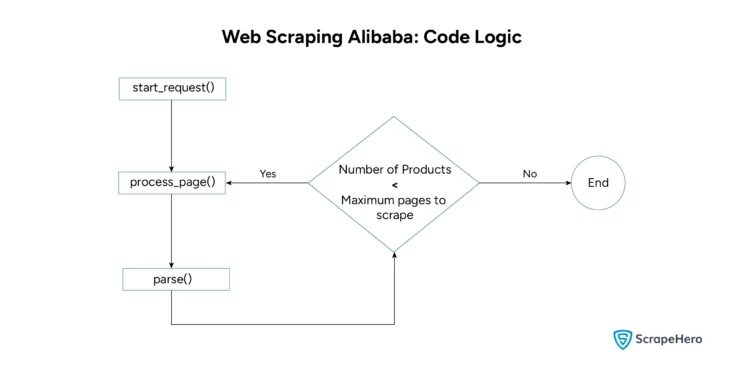
Here are the steps to write the code:
- Import the modules necessary for Alibaba web scraping:
- Asyncio: for asynchronous programming that allows the code to execute the next step while the previous step is still waiting for the results.
- Playwright: to browse the internet programmatically
- CSV: to save the result as a CSV file
- SelectorLib: to get the selectors for locating data points
- Re: for Regular Expression support
import asyncio import re from playwright.async_api import async_playwright import csv from selectorlib import Extractor
- Create a function parse() to
- Get HTML content from a web page.
- Extract the required data from the HTML content
async def parse(page, search_text, extractor): html_content = await page.content() return extractor.extract(html_content, base_url=page.url)
- Write a function process_page() to
- Use the Playwright browser to go to Alibaba’s website
- Call parse() function to get data
- Write the data into the created CSV file
- Call process_page() again if the number of products scraped is less than the allowed maximum.
async def process_page(page, url, search_text, extractor, max_pages, writer, current_page_no=1): try: await page.goto(url) data = await parse(page, search_text, extractor) product = data['Products'] # Write to CSV writer.writerow([product['name'], product['price'], product['seller_name'], product['Link']]) # Pagination logic if data['Products'] and current_page_no < max_pages: next_page_no = current_page_no + 1 next_page_url = re.sub(r'(page=\d+)|$', lambda match: f'page={next_page_no}' if match.group(1) else f'&page={next_page_no}', url) await process_page(page, next_page_url, search_text, extractor, max_pages, writer, next_page_no) except Exception as e: print(f"Error processing page: {e}")
- Define a function start_requests() to
- Extract keywords from “keywords.csv,”
- Create a CSV file to write the results
- Run the process_page() function.
async def start_requests(page, extractor, max_pages): with open("keywords.csv") as search_keywords, open("alibaba_products.csv", "w", newline="") as csvfile: writer = csv.writer(csvfile) # Write CSV header writer.writerow(["Name", "Price", "Seller Name", "Link"]) reader = csv.DictReader(search_keywords) for keyword in reader: search_text = keyword["keyword"] url = f"https://www.alibaba.com/trade/search?fsb=y&IndexArea=product_en&CatId=&SearchText={search_text}&viewtype=G&page=1" await process_page(page, url, search_text, extractor, max_pages, writer)
- Finally, the main() function integrates the functions defined above. The function
- Launches the Playwright browser
- Extracts CSS selectors from the YAML file
- Sets the maximum number of pages the code can scrape
- Calls the start_requests() function
- Limitations of the Code
async def main(): async with async_playwright() as p: browser = await p.chromium.launch() page = await browser.new_page() extractor = Extractor.from_yaml_file("search_results.yml") max_pages = 20 await start_requests(page, extractor, max_pages) await browser.close() # Run the main function await main()
Here is the scraped data
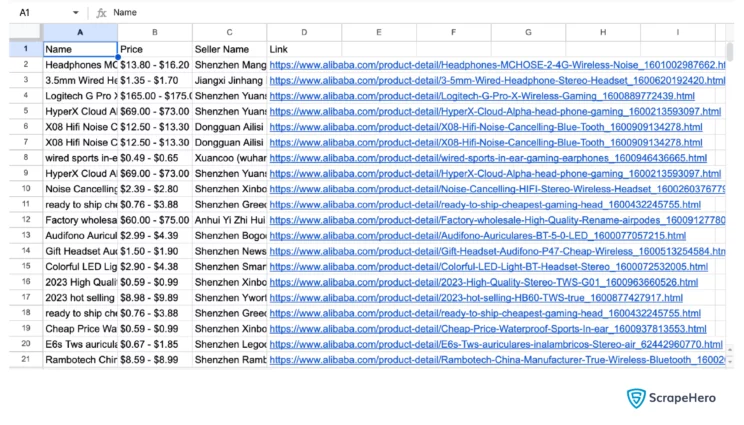
Limitations of the Code
This code uses CSS selectors to locate elements on Alibaba’s website. The selectors may change frequently. So, you must use SelectorLib again to get the new CSS selectors.
Moreover, the code might fail for large-scale scraping because it can’t bypass anti-scraping measures like rate limiting.
Concluding
You can scrape product data from a website, such as Alibaba, using Python. This tutorial showed you how to scrape Alibaba using Playwright. Further, you saw how to use SelectorLib to get the CSS selectors required to instruct Playwright on what to scrape.
However, CSS selectors can change frequently. Therefore, you must keep checking for any changes in the website structure. Or your code will fail to locate the data points.
This code can also only scrape a modest amount of data. To get thousands of product details, you need a more robust code. Try ScrapeHero Sevices; we can build enterprise-grade web scrapers for you.
ScrapeHero is a fully managed web scraping service that can scrape eCommerce websites for product and brand monitoring and more.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data



