
Price Scraping involves gathering price information of a product from an eCommerce website using web scraping. A price scraper can help you easily scrape prices from website for price monitoring purposes of your competitor and your products.
How to Scrape Prices
1. Create your own Price Monitoring Tool to Scrape Prices
There are plenty of web scraping tutorials on the internet where you can learn how to create your own price scraper to gather pricing from eCommerce websites. However, writing a new scraper for every different eCommerce site could get very expensive and tedious. Below we demonstrate some advanced techniques to build a basic web scraper that could scrape prices from any eCommerce page.
2. Web Scraping using Price Scraping Tools
Web scraping tools such as ScrapeHero Cloud can help you scrape prices without coding, downloading and learning how to use a tool. ScrapeHero Cloud has pre-built crawlers that can help you scrape popular eCommerce websites such as Amazon, Walmart, Target easily. ScrapeHero Cloud also has scraping APIs to help you scrape prices from Amazon and Walmart in real-time, web scraping APIs can help you get pricing details within seconds.
3. Custom Price Monitoring Solution
ScrapeHero Price Monitoring Solutions are cost-effective and can be built within weeks and in some cases days. Our price monitoring solution can easily be scaled to include multiple websites and/or products within a short span of time. We have considerable experience in handling all the challenges involved in price monitoring and have the sufficient know-how about the essentials of product monitoring.
Learn how to scrape prices for FREE –
How to Build a Price Scraper
In this tutorial, we will show you how to build a basic web scraper which will help you in scraping prices from eCommerce websites by taking a few common websites as an example.
Let’s start by taking a look at a few product pages, and identify certain design patterns on how product prices are displayed on the websites.
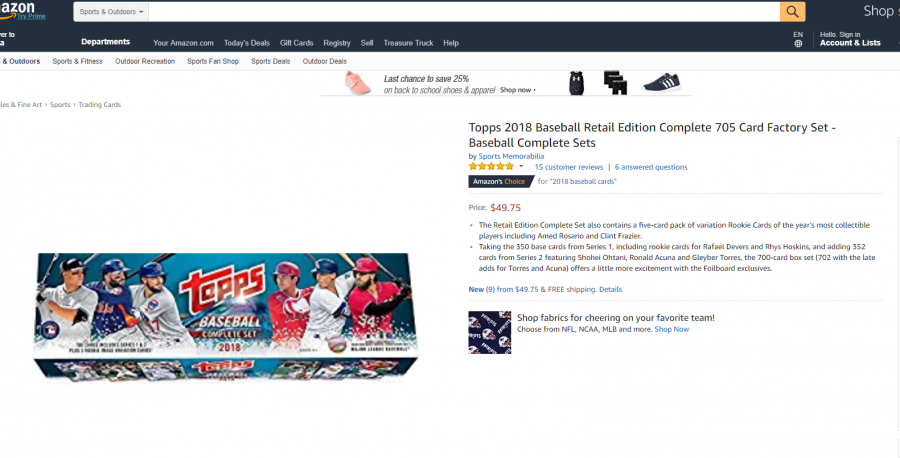
Amazon.com
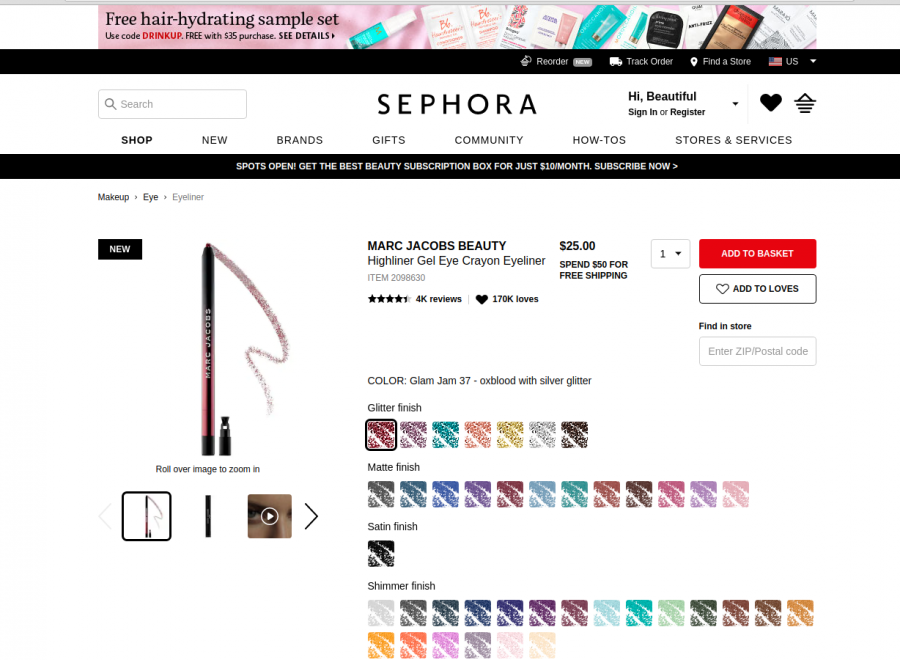
Sephora.com
Observations and Patterns
Some patterns that we identified by looking at these product pages are:
- Price appears as currency figures (never as words)
- The price is the currency figure with the largest font size
- Price comes inside first 600 pixels height
- Usually the price comes above other currency figures
Of course, there could be exceptions to these observations, we’ll discuss how to deal with exceptions later in this article. We can combine these observations to create a fairly effective and generic crawler for scraping prices from eCommerce websites.
Implementation of a generic eCommerce scraper to scrape prices
Step 1: Installation
This tutorial uses the Google Chrome web browser. If you don’t have Google Chrome installed, you can follow the installation instructions.
Instead of Google Chrome, advanced developers can use a programmable version of Google Chrome called Puppeteer. This will remove the necessity of a running GUI application to run the scraper. However, that is beyond the scope of this tutorial.
Step 2: Chrome Developer Tools
The code presented in this tutorial is designed for scraping prices as simple as possible. Therefore, it will not be capable of fetching the price from every product page out there.
For now, we’ll visit an Amazon product page or a Sephora product page in Google Chrome.
- Visit the product page in Google Chrome
- Right-click anywhere on the page and select ‘Inspect Element’ to open up Chrome DevTools
- Click on the Console tab of DevTools
Inside the Console tab, you can enter any JavaScript code. The browser will execute the code in the context of the web page that has been loaded. You can learn more about DevTools using their official documentation.
Step 3: Run the JavaScript snippet
Copy the following JavaScript snippet and paste it into the console.
let elements = [
...document.querySelectorAll(' body *')
]
function createRecordFromElement(element) {
const text = element.textContent.trim()
var record = {}
const bBox = element.getBoundingClientRect()
if(text.length <= 30 && !(bBox.x == 0 && bBox.y == 0)) {
record['fontSize'] = parseInt(getComputedStyle(element)['fontSize']) }
record['y'] = bBox.y
record['x'] = bBox.x
record['text'] = text
return record
}
let records = elements.map(createRecordFromElement)
function canBePrice(record) {
if( record['y'] > 600 ||
record['fontSize'] == undefined ||
!record['text'].match(/(^(US ){0,1}(rs\.|Rs\.|RS\.|\$|₹|INR|USD|CAD|C\$){0,1}(\s){0,1}[\d,]+(\.\d+){0,1}(\s){0,1}(AED){0,1}$)/)
)
return false
else return true
}
let possiblePriceRecords = records.filter(canBePrice)
let priceRecordsSortedByFontSize = possiblePriceRecords.sort(function(a, b) {
if (a['fontSize'] == b['fontSize']) return a['y'] > b['y']
return a['fontSize'] < b['fontSize']
})
console.log(priceRecordsSortedByFontSize[0]['text']);
Press ‘Enter’ and you should now be seeing the price of the product displayed on the console.
If you don’t, then you have probably visited a product page which is an exception to our observations. This is completely normal, we’ll discuss how we can expand our script to cover more product pages of these kinds. You could try one of the sample pages provided in step 2.
The animated GIF below shows how we get the price from Amazon.com
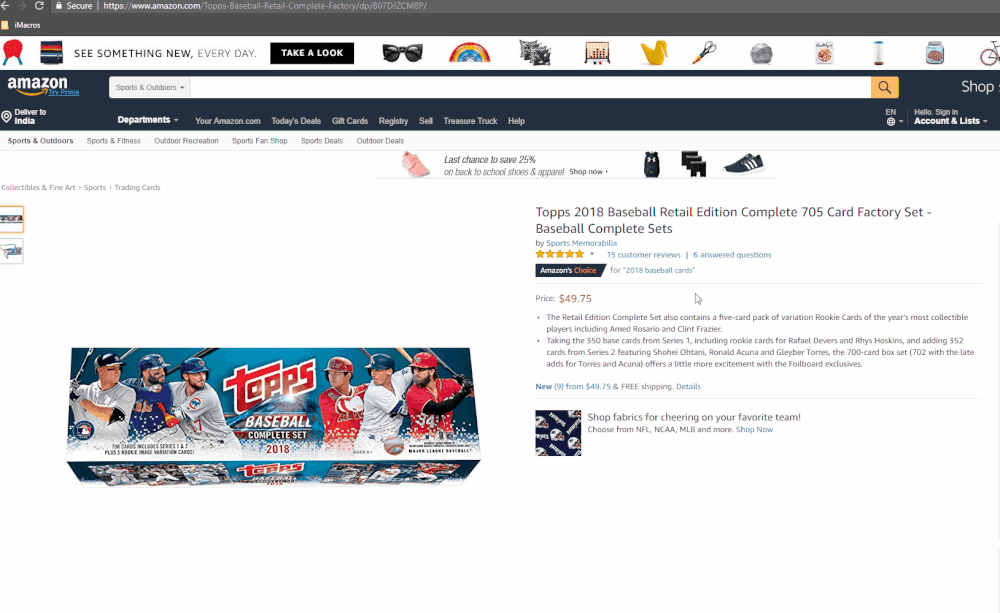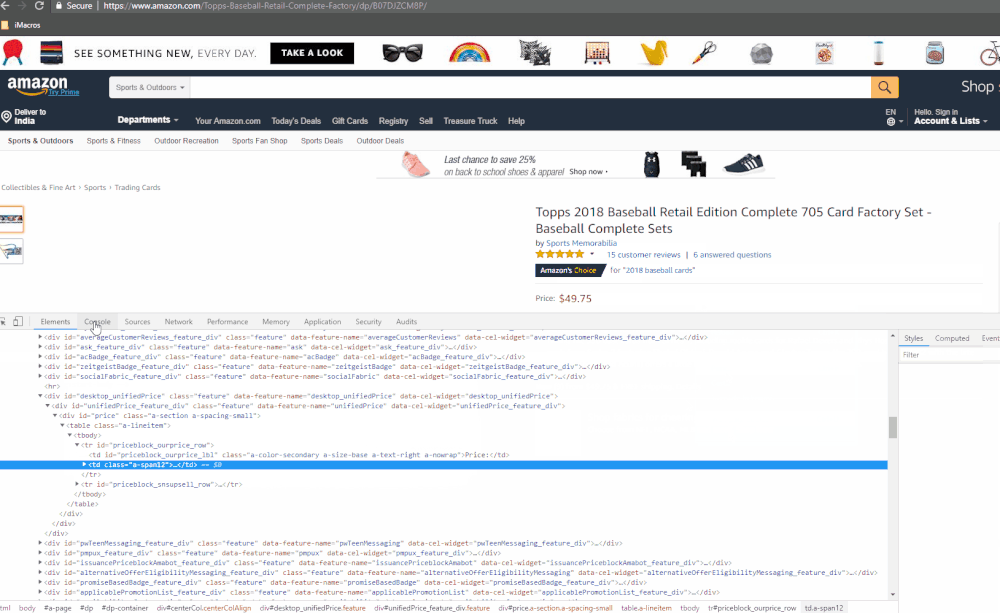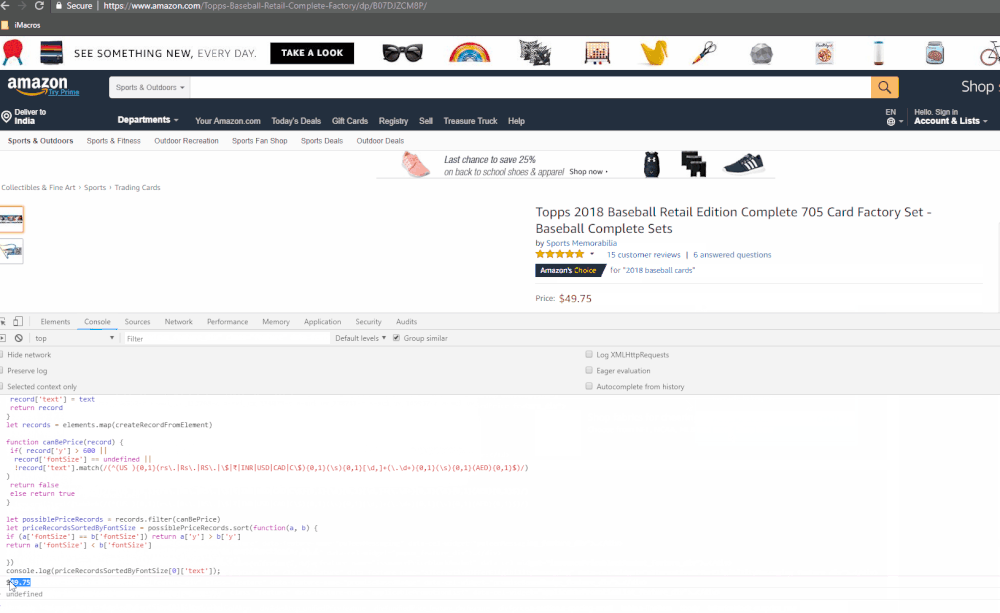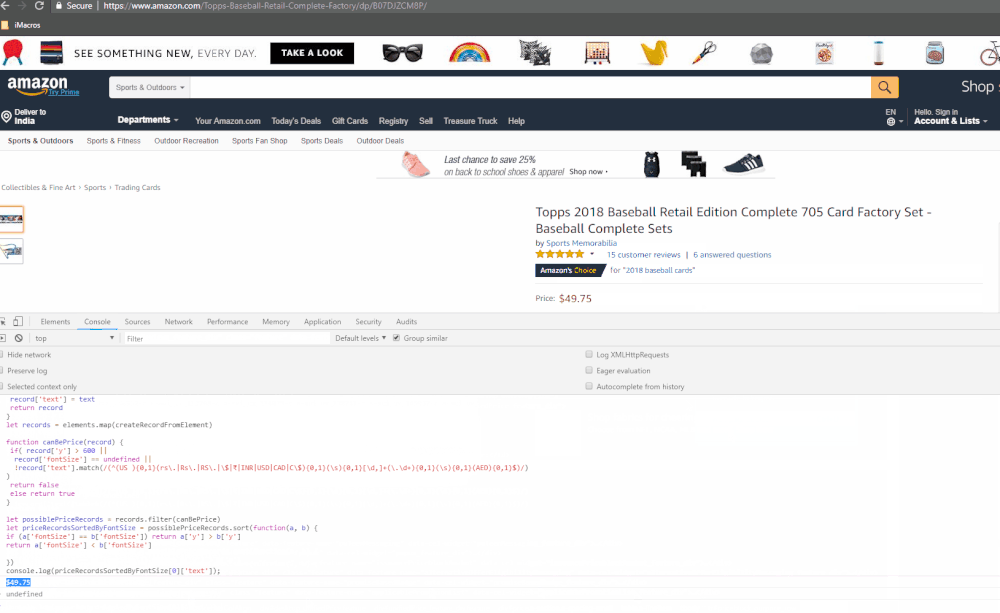
How it works
First, we have to fetch all the HTML DOM elements in the page.
let elements = [
...document.querySelectorAll(' body *')
]
We need to convert each of these elements to simple JavaScript objects which stores their XY position values, text content and font size, which looks something like {'text':'Tennis Ball', 'fontSize':'14px', 'x':100,'y':200}. So we have to write a function for that, as follows.
function createRecordFromElement(element) {
const text = element.textContent.trim() // Fetches text content of the element
var record = {} // Initiates a simple JavaScript object
const bBox = element.getBoundingClientRect()
// getBoundingClientRect is a function provided by Google Chrome, it returns
// an object which contains x,y values, height and width
if(text.length <= 30 && !(bBox.x == 0 && bBox.y == 0)) {
record['fontSize'] = parseInt(getComputedStyle(element)['fontSize'])
}
// getComputedStyle is a function provided by Google Chrome, it returns an
// object with all its style information. Since this function is relatively
// time-consuming, we are only collecting the font size of elements whose
// text content length is atmost 30 and whose x and y coordinates are not 0
record['y'] = bBox.y
record['x'] = bBox.x
record['text'] = text
return record
}
Now, convert all the elements collected to JavaScript objects by applying our function on all elements using the JavaScript map function.
let records = elements.map(createRecordFromElement)
Remember the observations we made regarding how a price is displayed. We can now filter just those records which match our design observations. So we need a function that says whether a given record matches with our design observations.
function canBePrice(record) {
if(
record['y'] > 600 ||
record['fontSize'] == undefined ||
!record['text'].match(/(^(US ){0,1}(rs\.|Rs\.|RS\.|\$|₹|INR|USD|CAD|C\$){0,1}(\s){0,1}[\d,]+(\.\d+){0,1}(\s){0,1}(AED){0,1}$)/)
)
return false
else return true
}
We have used a Regular Expression to check if a given text is a currency figure or not. You can modify this regular expression in case it doesn’t cover any web pages that you’re experimenting with.
Now we can filter just the records that are possibly price records
let possiblePriceRecords = records.filter(canBePrice)
Finally, as we’ve observed, the Price comes as the currency figure having the highest font size. If there are multiple currency figures with equally high font size, then Price probably corresponds to the one residing at a higher position. We are going to sort out our records based on these conditions, using the JavaScript sort<em><strong> function.
let priceRecordsSortedByFontSize = possiblePriceRecords.sort(function(a, b) {
if (a['fontSize'] == b['fontSize']) return a['y'] > b['y']
return a['fontSize'] < b['fontSize']
})
Now we just need to display it on the console
console.log(priceRecordsSortedByFontSize[0]['text'])
Taking it further
Moving to a GUI-less based scalable program
You can replace Google Chrome with a headless version of it called Puppeteer. Puppeteer is arguably the fastest option for headless web rendering. It works entirely based on the same ecosystem provided in Google Chrome. Once Puppeteer is set up, you can inject our script programmatically to the headless browser, and have the price returned to a function in your program. To learn more, visit our tutorial on Puppeteer.
Learn more: Web Scraping with Puppeteer and Node.Js
Improving and enhancing this script
You will quickly notice that some product pages will not work with such a script because they don’t follow the assumptions we have made about how the product price is displayed and the patterns we identified.
Unfortunately, there is no “holy grail” or a perfect solution to this problem. It is possible to generalize more web pages and identify more patterns and enhance this scraper.
A few suggestions for enhancements are:
- Figuring out more features, such as font-weight, font color, etc.
- Class names or IDs of the elements containing price would probably have the word price. You could figure out such other commonly occurring words.
- Currency figures with strike-through are probably regular prices, those could be ignored.
There could be pages that follow some of our design observations but violates some others. The snippet provided above strictly filters out elements that violate even one of the observations. In order to deal with this, you can try creating a score based system. This would award points for following certain observations and penalize for violating certain observations. Those elements scoring above a particular threshold could be considered as price.
The next significant step that you would use to handle other pages is to employ Artificial Intelligence/Machine Learning based techniques. You can identify and classify patterns and automate the process to a larger degree this way. However, this field is an evolving field of study and we at ScrapeHero are using such techniques already with varying degrees of success.
If you need help to scrape prices from Amazon.com you can check out our tutorial specifically designed for Amazon.com:
Learn More: How to Scrape Prices from Amazon using Python
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data
Disclaimer: Any code provided in our tutorials is for illustration and learning purposes only. We are not responsible for how it is used and assume no liability for any detrimental usage of the source code. The mere presence of this code on our site does not imply that we encourage scraping or scrape the websites referenced in the code and accompanying tutorial. The tutorials only help illustrate the technique of programming web scrapers for popular internet websites. We are not obligated to provide any support for the code, however, if you add your questions in the comments section, we may periodically address them.



