
In this article, we will show you how to scrape Amazon Best Seller list by category from the Amazon’s Best Seller page such as bestseller rank, product name, rating, number of reviews, price, product image, and URL from Amazon using the Amazon Best Seller Crawler on ScrapeHero Cloud.
Here are the steps to scrape Amazon Best Seller Data:
- Create a ScrapeHero Cloud account and select the Amazon Best Seller Crawler.
- Input the Amazon bestseller URLs and filters.
- Run the scraper and download the data (CSV, JSON, XML).
Web scraping allows you to monitor best selling brands and gather useful insights. ScrapeHero Cloud has pre-built scrapers which help businesses to easily gather data from e-commerce websites such as Amazon. These scrapers are pre-built and cloud-based, you need not worry about selecting the fields to be scraped nor download any software. The scraper and the data can be accessed from any browser at any time and can deliver the data directly to Dropbox.

Data Fields we will be Extracting
For this tutorial we will only extract the following fields based on a best seller URL:
- Product Rank
- Product Name
- Number of Reviews
- Price
- Product Image
- Rating
- Brand
- Seller
- Description
- Product Specifications
- Product Model
- Category
- Customer Reviews
- Sponsored Products
Step 1: Create an account
First, we will create an account in ScrapeHero Marketplace. To sign up go to the link – https://cloud.scrapehero.com/accounts/login/ and create an account with your email address.

Step 2: Input the Details for the Amazon Bestseller Crawler
To choose the best seller URL you must go to the Amazon Best Seller page and choose any category from the sidebar.
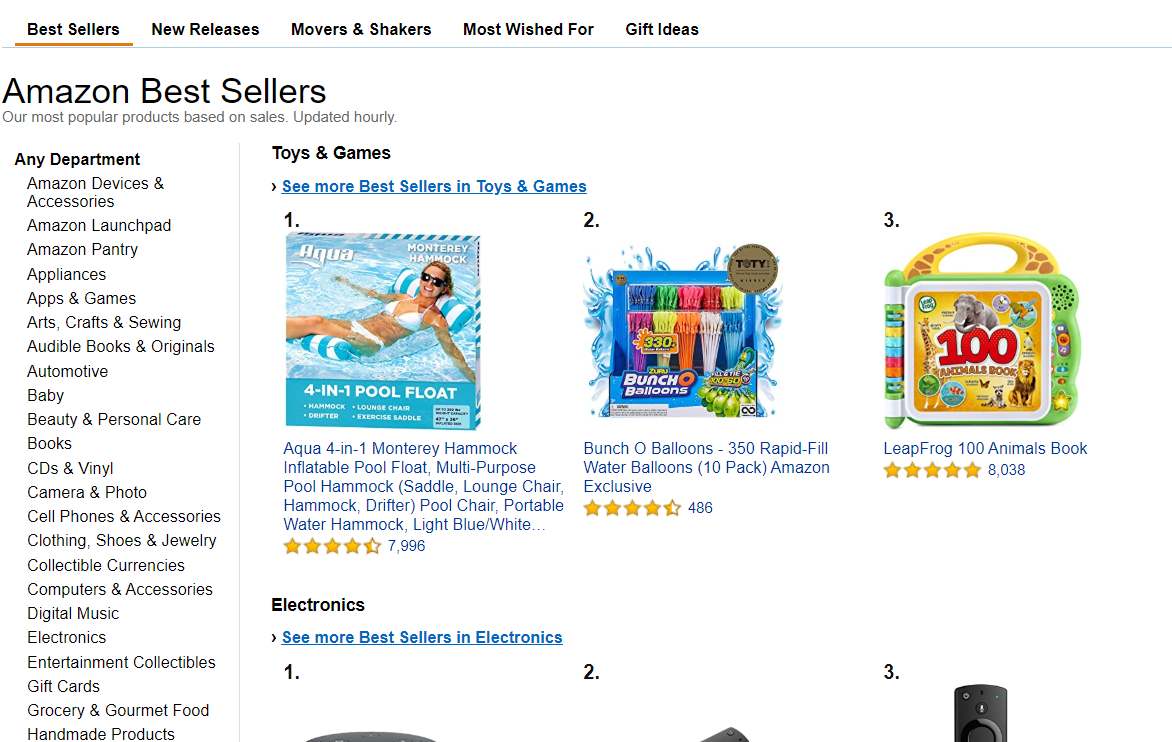
Copy the webpage URL and paste it in the BestSeller Category URLs field of this scraper. Here is an example: https://www.amazon.com/Best-Sellers-Computers-Accessories-Laptop/zgbs/pc/565108/

To get best seller data from multiple categories, go to ‘Input’ in Advanced Mode and add the URL of each best seller list as a new line to the Best Seller URLs. Then click on ‘Save Settings’.
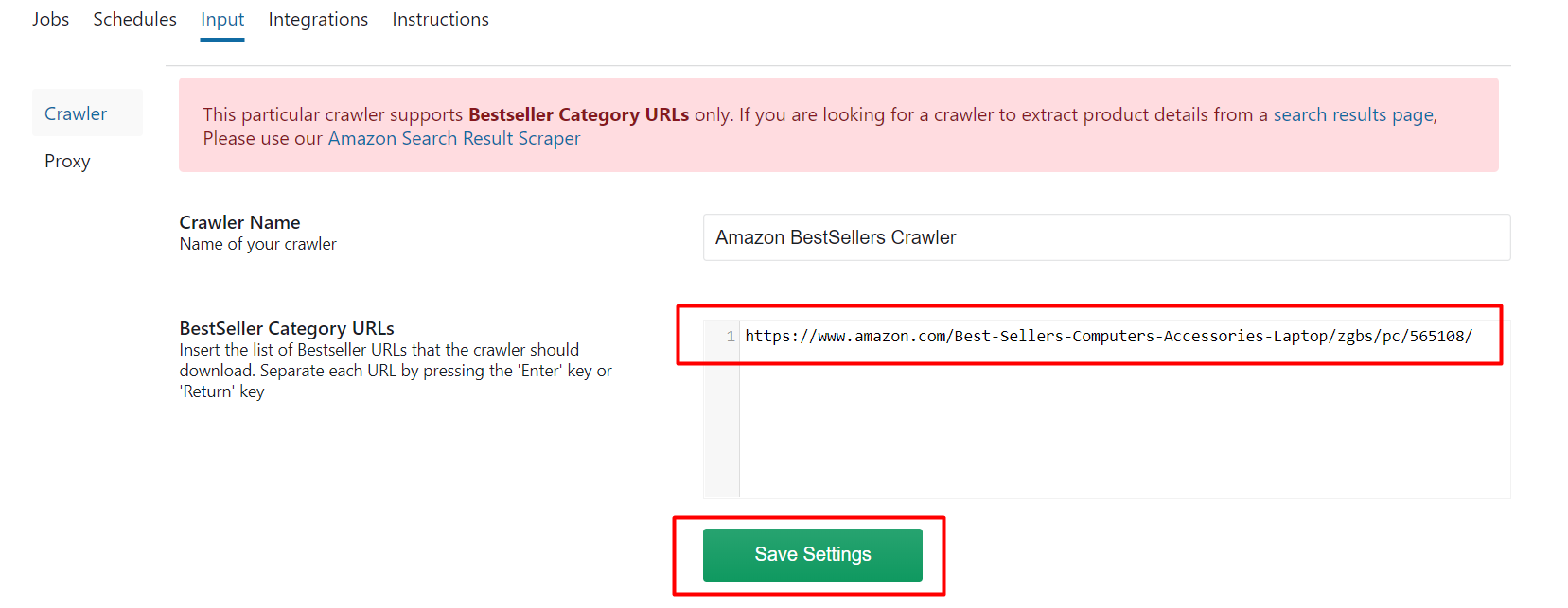
After saving the settings with your desired best seller URLs you can click on ‘Gather data’ to run the scraper.
Step 3: Run the Scraper
Once the crawler has started its run you will see a notification regarding the data collection.
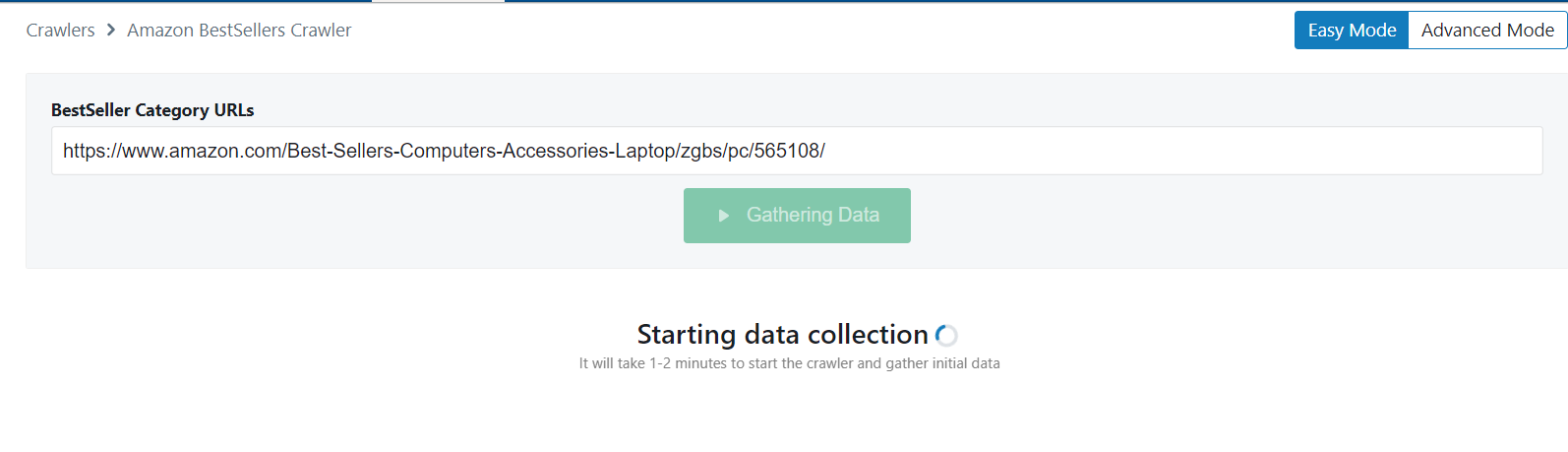
Step 4: Download the Data
After all the records have been collected, click on ‘Download Data’.
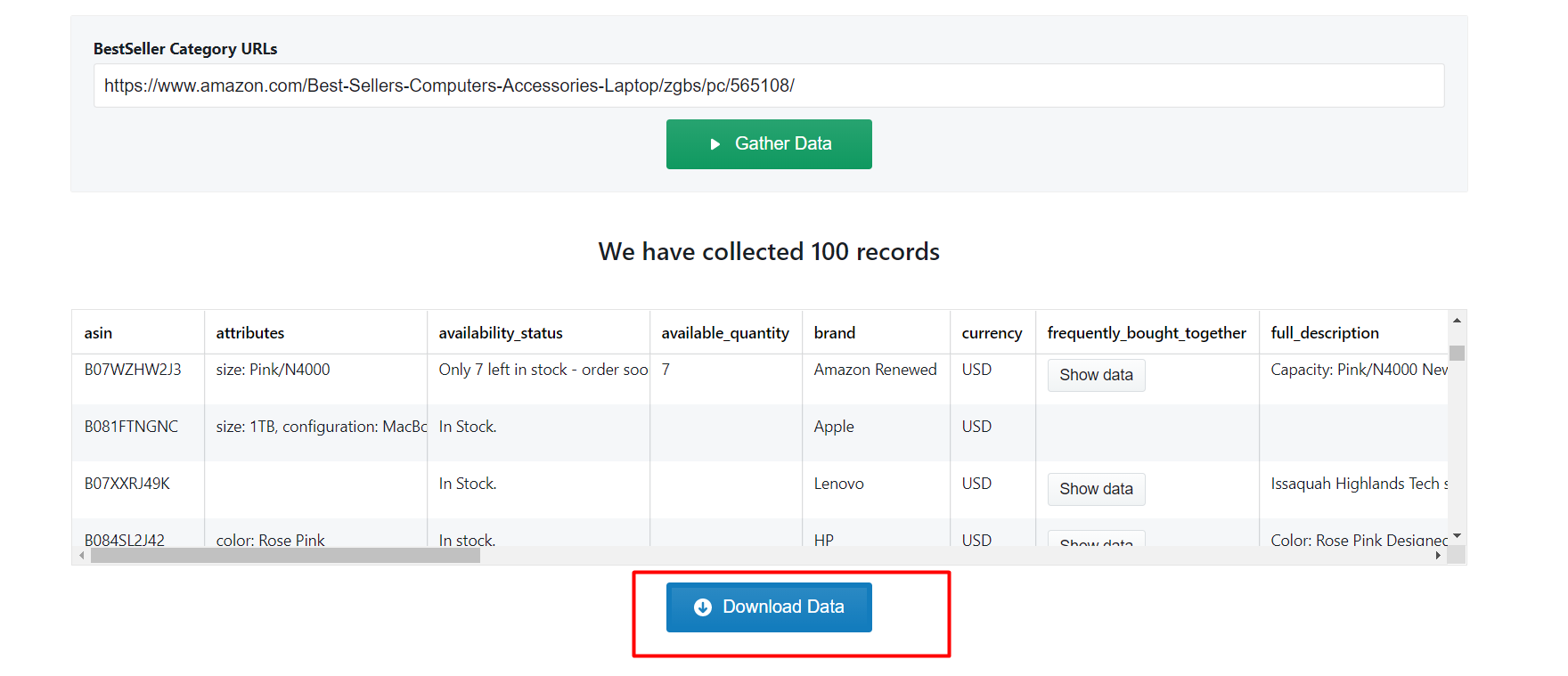
A drop down to select a data format will appear. You can choose between CSV, JSON, and XML formats. After clicking on the data format option, a file will soon be downloaded with all the scraped review data.
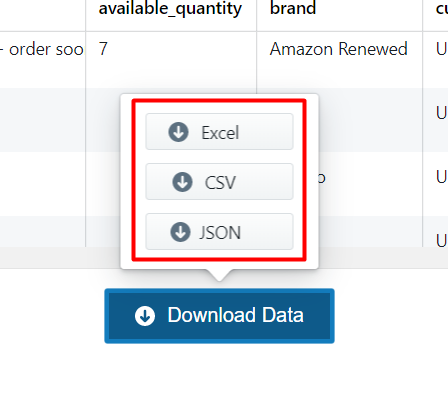
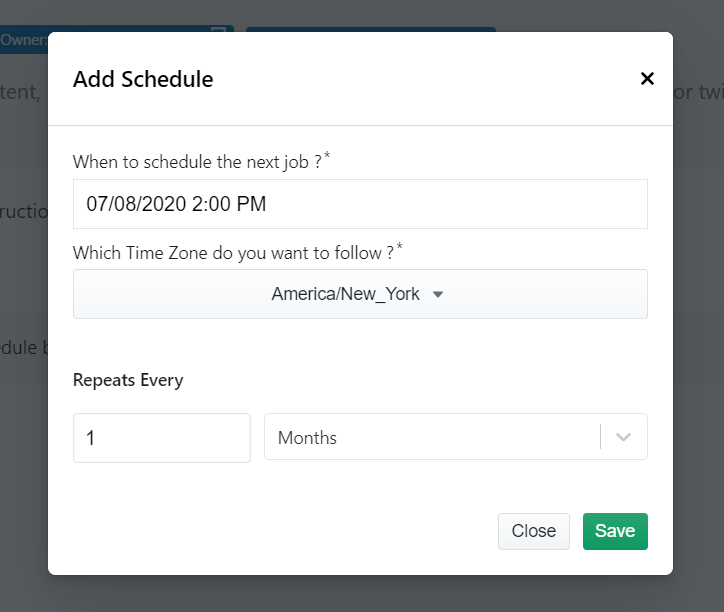
You can get data delivered to Dropbox if you integrate the crawler account to your Dropbox account. You also have the option to schedule the data if you want to extract best seller data on a timely basis.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data



