
In this 10 minute tutorial, we will show you how to build a web scraper that will get the latest delivery status and price for liquor (in this case Single Malt) from your local Total Wine and More store.
This tutorial is built for educational purposes to learn how to quickly program a web scraper. Over time, the website will change and the code will NOT work as-is by copying and pasting. The objective of this and all tutorials on this site is that you understand how the scraper is built and coded so that you can make it your own and more importantly maintain it over time as changes are made to the website.
We will be using Python 3 and some common Python libraries and an awesome and Free Web Scraper tool called Selectorlib to make things easier for us.
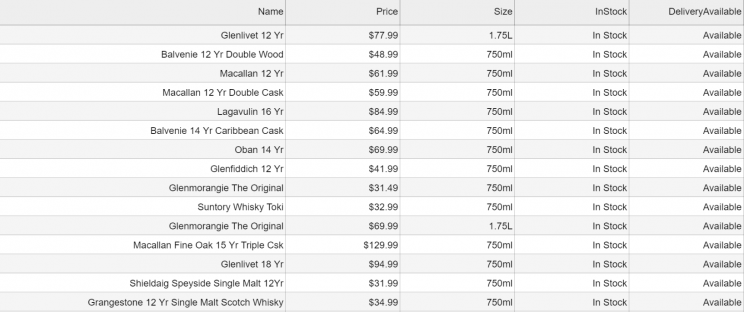
Here are some of the data fields that this scraper will help you extract into a spreadsheet:
- Name
- Price
- Size/Quantity
- InStock – whether the liquor is in stock
- DeliveryAvailable – whether the liquor can be delivered to you
- URL
We will save the data as an Excel Spreadsheet (CSV) that looks like this.
Installing the required packages for running Total Wine and More Web Scraper
For this web scraping tutorial, we will be using Python 3 and its libraries and it can be run in the Cloud or VPS or even a Raspberry Pi.
If you do not have Python 3 installed, you can follow this guide to install Python in Windows here – How To Install Python Packages.
We will use these libraries:
- Python Requests, to make requests and download the HTML content of the pages ( http://docs.python-requests.org/en/master/user/install/).
- Selectorlib, to extract data using the YAML file we created from the web pages we download
Install them using pip3
pip3 install requests selectorlib
The Python Code
All the code used in this tutorial is available for download from Github at https://github.com/scrapehero-code/totalwine-price-scraper
Let’s create a file called products.py and paste the following Python code into it.
from selectorlib import Extractor
import requests
import csv
e = Extractor.from_yaml_file('selectors.yml')
def scrape(url):
headers = {
'authority': 'www.totalwine.com',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.122 Safari/537.36',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'referer': 'https://www.totalwine.com/beer/united-states/c/001304',
'accept-language': 'en-US,en;q=0.9',
}
r = requests.get(url, headers=headers)
return e.extract(r.text, base_url=url)
with open("urls.txt",'r') as urllist, open('data.csv','w') as outfile:
writer = csv.DictWriter(outfile, fieldnames=["Name","Price","Size","InStock","DeliveryAvailable","URL"],quoting=csv.QUOTE_ALL)
writer.writeheader()
for url in urllist.read().splitlines():
data = scrape(url)
if data:
for r in data['Products']:
writer.writerow(r)
Here is what the code does:
- Reads a list of Total Wine and More URLs from a file called urls.txt (This file will contain the URLs for the TWM product pages you care about such as Beer, Wines, Scotch etc)
- Uses a selectorlib YAML file that identifies the data on an Total Wine page and is saved in a file called selectors.yml (more on how to generate this file later in this tutorial)
- Scrapes the Data
- Saves the data as CSV Spreadsheet called data.csv
Creating the YAML file – selectors.yml
You will notice that in the code above that we used a file called selectors.yml. This file is what makes the code in this tutorial so concise and easy. The magic behind creating this file is a Web Scraper tool called Selectorlib.
Selectorlib is a tool that makes selecting, marking up, and extracting data from web pages visual and easy. The Selectorlib Web Scraper Chrome Extension lets you mark data that you need to extract, and creates the CSS Selectors or XPaths needed to extract that data. Then previews how the data would look like. You can learn more about Selectorlib and how to use it here
If you just need the data we have shown above, you do not need to use Selectorlib. Since we have done that for you already and generated a simple “template” that you can just use. However, if you want to add a new field, you can use Selectorlib to add that field to the template.
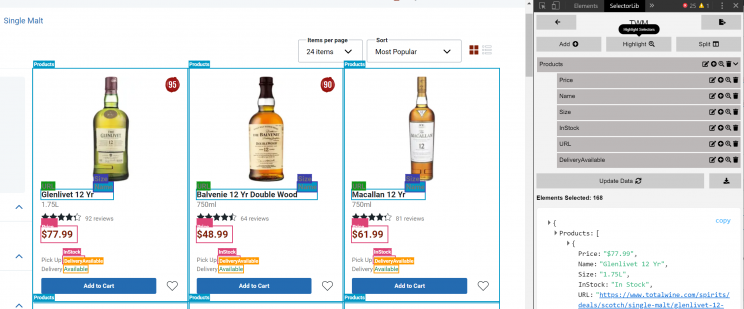
Here is how we marked up the fields for the data we need to scrape using Selectorlib Chrome Extension.
Once you have created the template, click on ‘Highlight’ to highlight and preview all of your selectors. Finally, click on ‘Export’ and download the YAML file and that file is the selectors.yml file.
Here is how our template (selectors.yml) file looks like:
Products:
css: article.productCard__2nWxIKmi
multiple: true
type: Text
children:
Price:
css: span.price__1JvDDp_x
type: Text
Name:
css: 'h2.title__2RoYeYuO a'
type: Text
Size:
css: 'h2.title__2RoYeYuO span'
type: Text
InStock:
css: 'p:nth-of-type(1) span.message__IRMIwVd1'
type: Text
URL:
css: 'h2.title__2RoYeYuO a'
type: Link
DeliveryAvailable:
css: 'p:nth-of-type(2) span.message__IRMIwVd1'
type: Text
Running the Total Wine and More Scraper
All you need to do is add the URL you need to scrape into a text file called urls.txt in the same folder.
Here is what’s in our urls.txt file
https://www.totalwine.com/spirits/scotch/single-malt/c/000887?viewall=true&pageSize=120&aty=0,0,0,0
Then run the scraper using the command:
python3 products.py
Problems you may face with this code and other self-service tools and internet copied scripts
Code degrades over time and websites change and that is the reason why just code or one time scripts break down over time.
Here are some issues you may face with this or any other code or tool that is not maintained.
- If the website changes its structure e.g. the CSS Selector we used for the Price in the selectors.yaml file called price__1JvDDp_x will most likely change over time or even every day.
- The location selection for your “local” store may be based on more variables rather than your geolocated IP address and the site may ask you to select the location. This is not handled in the simple code.
- The site may add new data points or modify the existing ones.
- The site may block the User Agent used
- The site may block the pattern of access this scripts uses
- The site may block you IP address or all IPs from your proxy provider
All these items and so many more are the reason full-service enterprise companies such as ScrapeHero work better than self service products and tools and DIY scripts. This is a lesson one learns only after going down the DIY or self-service tool route and have things break down frequently. You can go further and use this data to monitor prices and brands of your favorite wines.
If you need help with your complex scraping projects let us know and we will be glad to help.
Are your self-service tools and scripts not working? Let's talk
Turn the Internet into meaningful, structured and usable data


