

The AI Overview feature now puts summaries straight in search results. Users get answers without ever leaving Google or visiting your site. This is a problem. So you now need AI overview scraping to understand how your content appears in these summaries to stay competitive. This guide shows you how to build an AI Overview scraper that extracts text and citations across multiple queries.

AI Overview Scraping: Setting Up the Environment
Before running the scraper, install the necessary dependencies. This code relies on Playwright for webscraping, a browser automation library.
Installing Playwright is necessary as Google generates AI overviews dynamically and needs to run JavaScript; you can install it using:
pip install playwright
playwright install chromium
AI Overview Scraping: The Data Scraped
The scraper pulls two key things from the Google results page:
- The Summary Text: It extracts the full AI Overview text using the inner_text() method. This just gives you clean text with no messy HTML.
- The Sources: It finds all the hyperlinks (source citations) referenced in the overview by looking for all the anchor tags (a[href]) inside the main content.
AI Overview Scraping: The Code
Here’s the complete code scrape AI overviews.
"""
Google AI Overview Scraper using Playwright
Scrapes AI Overview sections from Google Search results
"""
from playwright.sync_api import sync_playwright
import json
import time
import os
import random
from typing import Dict, List
class GoogleAIOverviewScraper:
def __init__(self, headless: bool = False):
"""
Initialize the scraper
Args:
headless: Whether to run browser in headless mode
"""
self.headless = headless
self.playwright = None
self.browser = None
self.context = None
self.page = None
def start(self):
"""Start the browser"""
user_data_dir = os.path.join(os.getcwd(), "user_data")
if not os.path.exists(user_data_dir):
os.makedirs(user_data_dir)
user_agent='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
self.playwright = sync_playwright().start()
self.context = self.playwright.chromium.launch_persistent_context(
headless=False,
user_agent=user_agent,
user_data_dir=user_data_dir,
viewport={'width': 1920, 'height': 1080},
java_script_enabled=True,
locale='en-US',
timezone_id='America/New_York',
permissions=['geolocation'],
# Mask automation
bypass_csp=True,
ignore_https_errors=True,
channel="chromium",
args=[
'--disable-blink-features=AutomationControlled',
'--disable-dev-shm-usage',
'--no-sandbox',
'--disable-gpu',
'--disable-setuid-sandbox'
]
)
self.page = self.context.new_page()
def close(self):
"""Close the browser"""
if self.page:
self.page.close()
if self.context:
self.context.close()
if self.browser:
self.browser.close()
if self.playwright:
self.playwright.stop()
def search_and_extract_ai_overview(self, query: str) -> Dict:
"""
Search Google and extract AI Overview if present
"""
result = {
'query': query,
'ai_overview_present': False,
'ai_overview_text': None,
'ai_overview_sources': [],
'timestamp': time.strftime('%Y-%m-%d %H:%M:%S')
}
try:
# Navigate to Google
search_url = f"https://www.google.com/search?q={query.replace(' ', '+')}"
self.page.goto(search_url, wait_until='networkidle')
# Wait a bit for AI Overview to load
time.sleep(2)
# Try to find AI Overview section
# Google's AI Overview typically appears in specific containers
# Click "Show more" if it exists to expand the AI overview
try:
show_more_button = self.page.get_by_role('button',name='Show more')
if show_more_button:
self.page.wait_for_timeout(random.randrange(1000,3000))
show_more_button.click()
# Wait a moment for the content to expand
time.sleep(1)
except Exception as e:
print(f"couldn't find show more button: {e}")
# If "Show more" button is not found, just continue
pass
input()
ai_overview_selector = '.kCrYT'
try:
elements = self.page.query_selector_all(ai_overview_selector)
loop = 0
for element in elements:
if "AI Overview" in element.text_content():
ai_overview_element = elements[loop+1]
break
loop = loop + 1
except Exception as e:
print(e)
if ai_overview_element:
result['ai_overview_present'] = True
# Extract the main AI Overview text
text_content = ai_overview_element.inner_text()
result['ai_overview_text'] = text_content.strip()
# Try to extract sources/citations
source_links = ai_overview_element.query_selector_all('a[href]')
sources = []
for link in source_links:
href = link.get_attribute('href')
text = link.inner_text().strip()
if href and text:
sources.append({
'text': text,
'url': href
})
result['ai_overview_sources'] = sources
else:
print(f"No AI Overview found for query: {query}")
except Exception as e:
result['error'] = str(e)
print(f"Error scraping AI Overview: {e}")
return result
def scrape_multiple_queries(self, queries: List[str]) -> List[Dict]:
"""
Scrape AI Overviews for multiple queries
"""
results = []
for i, query in enumerate(queries):
print(f"Processing query {i+1}/{len(queries)}: {query}")
result = self.search_and_extract_ai_overview(query)
results.append(result)
# Add delay between requests to avoid rate limiting
if i < len(queries) - 1:
time.sleep(3)
return results
def main():
# Main function to demonstrate usage
queries = [
"what is powerlifting",
"how does progressive overload work",
"what is RPE in lifting",
"how to calculate one rep max",
"what is proper squat form",
"what is proper bench press form",
"what is proper deadlift form",
"what is lifting programming",
"what are compound exercises",
"what is hypertrophy training"
]
scraper = GoogleAIOverviewScraper(headless=False)
try:
# Start the browser
scraper.start()
# Scrape AI Overviews
results = scraper.scrape_multiple_queries(queries)
# Save results to JSON file
output_file = 'ai_overview_results.json'
with open(output_file, 'w', encoding='utf-8') as f:
json.dump(results, f, indent=4, ensure_ascii=False)
print(f"\nResults saved to {output_file}")
# Print summary
print("\n=== Summary ===")
for result in results:
status = "Found" if result['ai_overview_present'] else "Not Found"
print(f"Query: {result['query']}")
print(f"AI Overview: {status}")
if result['ai_overview_present']:
print(f"Text length: {len(result['ai_overview_text'])} characters")
print(f"Sources: {len(result['ai_overview_sources'])}")
print("-" * 50)
finally:
# Close the browser
scraper.close()
if __name__ == "__main__":
main()
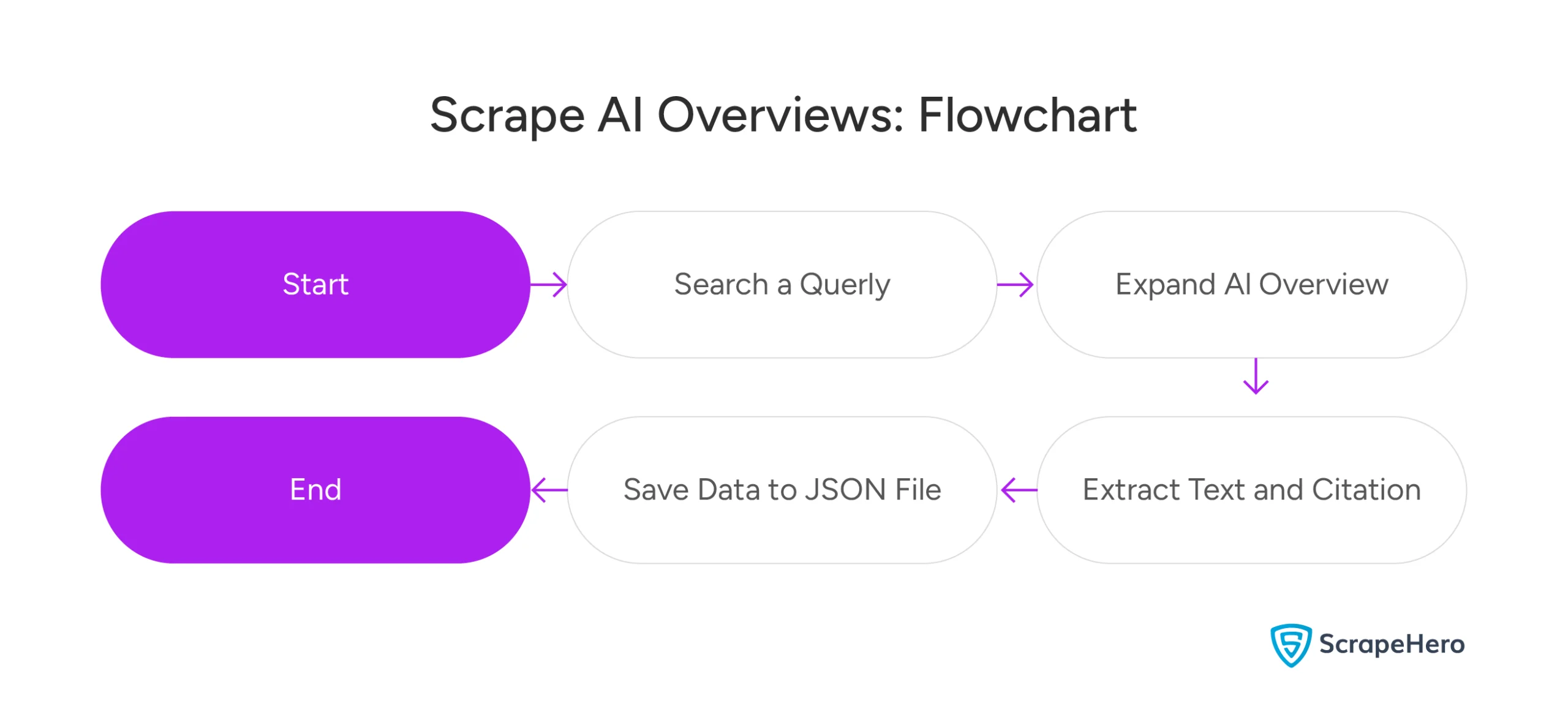
For a quick, high-level view of everything this script does, just look at this flowchart.
The script starts by importing the necessary Python libraries:
from playwright.sync_api import sync_playwright
import json
import time
import os
import random
from typing import Dict, List
- The playwright.sync_api helps with browser automation—that’s the main engine.
- The json module handles saving our scraped results.
- The time and random modules are used to create those small, unpredictable delays between actions, which helps us avoid being detected.
- The os module helps us manage files and folders
- The typing module makes the code cleaner by letting us specify the data types, like Dict (for dictionaries) and List (for lists).
Now, initialize the scraper class, which means configure the browser and define exactly how the data will be pulled from the page.
Initializing the Scraper Class
The scraper uses a class named GoogleAIOverviewScraper to keep the code neat and organized.
class GoogleAIOverviewScraper:
def __init__(self, headless: bool = False):
"""
Initialize the scraper
Args:
headless: Whether to run browser in headless mode
"""
self.headless = headless
self.playwright = None
self.context = None
self.page = None
The constructor of the class initializes five variables:
- self.headless: stores a boolean value that determines whether or not the Playwright browser starts in a headless mode.
- self.playwright: stores the Playwright instance that manages the entire browser automation framework
- self.context: stores the browser context that isolates cookies, cache, etc. for the scraping session
- self.page: stores the page object, which are individual tabs
Starting the Browser
To launch the browser, create a “persistent context.” This just means setting up several anti-detection flags and configurations that help the browser mimic a real user and avoid being flagged as automation.
def start(self):
"""Start the browser"""
user_data_dir = os.path.join(os.getcwd(), "../user_data")
if not os.path.exists(user_data_dir):
os.makedirs(user_data_dir)
user_agent='Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
self.playwright = sync_playwright().start()
self.context = self.playwright.chromium.launch_persistent_context(
headless=False,
user_agent=user_agent,
user_data_dir=user_data_dir,
viewport={'width': 1920, 'height': 1080},
java_script_enabled=True,
locale='en-US',
timezone_id='America/New_York',
permissions=['geolocation'],
# Mask automation
bypass_csp=True,
ignore_https_errors=True,
channel="msedge",
args=[
'--disable-blink-features=AutomationControlled',
'--disable-dev-shm-usage',
'--no-sandbox',
'--disable-gpu',
'--disable-setuid-sandbox'
]
)
self.page = self.context.new_page()
In this code,
- The launch_persistent_context() method saves the browser’s state (like cookies and settings) in a special folder. This means the browser remembers things between each time you run the script.
- The user agent is set to make the browser look like Chrome running on Windows. This is a very common setup, which makes it less suspicious.
- The viewport is set to 1920×1080 to mimic a standard desktop monitor.
- The bypass_csp flag temporarily disables security rules (Content Security Policy) that some websites use to specifically block automated tools.
- The disable-blink-features=AutomationControlled argument removes a hidden flag navigator.webdriver that most automation tools expose, making it much harder for websites to know they’re talking to Playwright.
Extracting the AI Overview
To extract AI overviews, the script
- Goes to Google’s search interface
- Waits for content to load
- Attempts to locate and expand the AI Overview section
It uses wait_until=’networkidle’ to ensure JavaScript has finished rendering.
def search_and_extract_ai_overview(self, query: str) -> Dict:
## Search Google and extract AI Overview if present
result = {
'query': query,
'ai_overview_present': False,
'ai_overview_text': None,
'ai_overview_sources': [],
'timestamp': time.strftime('%Y-%m-%d %H:%M:%S')
}
try:++++++++++++++++++++++++++++++++++++++++++++
# Navigate to Google
search_url = f"https://www.google.com/search?q={query.replace(' ', '+')}"
self.page.goto(search_url, wait_until='networkidle')
# Wait a bit for AI Overview to load
time.sleep(2)
Here,
- The result dictionary starts with empty values, establishing the final structure for the extracted data.
- The search URL format replaces spaces with plus signs, according to Google’s URL conventions.
- The two-second delay after navigation ensures AI Overview content has loaded before the code begins extraction.
Expanding Collapsed Overviews
Google often hides the full AI Overview behind a “Show more” button. Inspecting it shows that it is actually a div element with the role “button.”
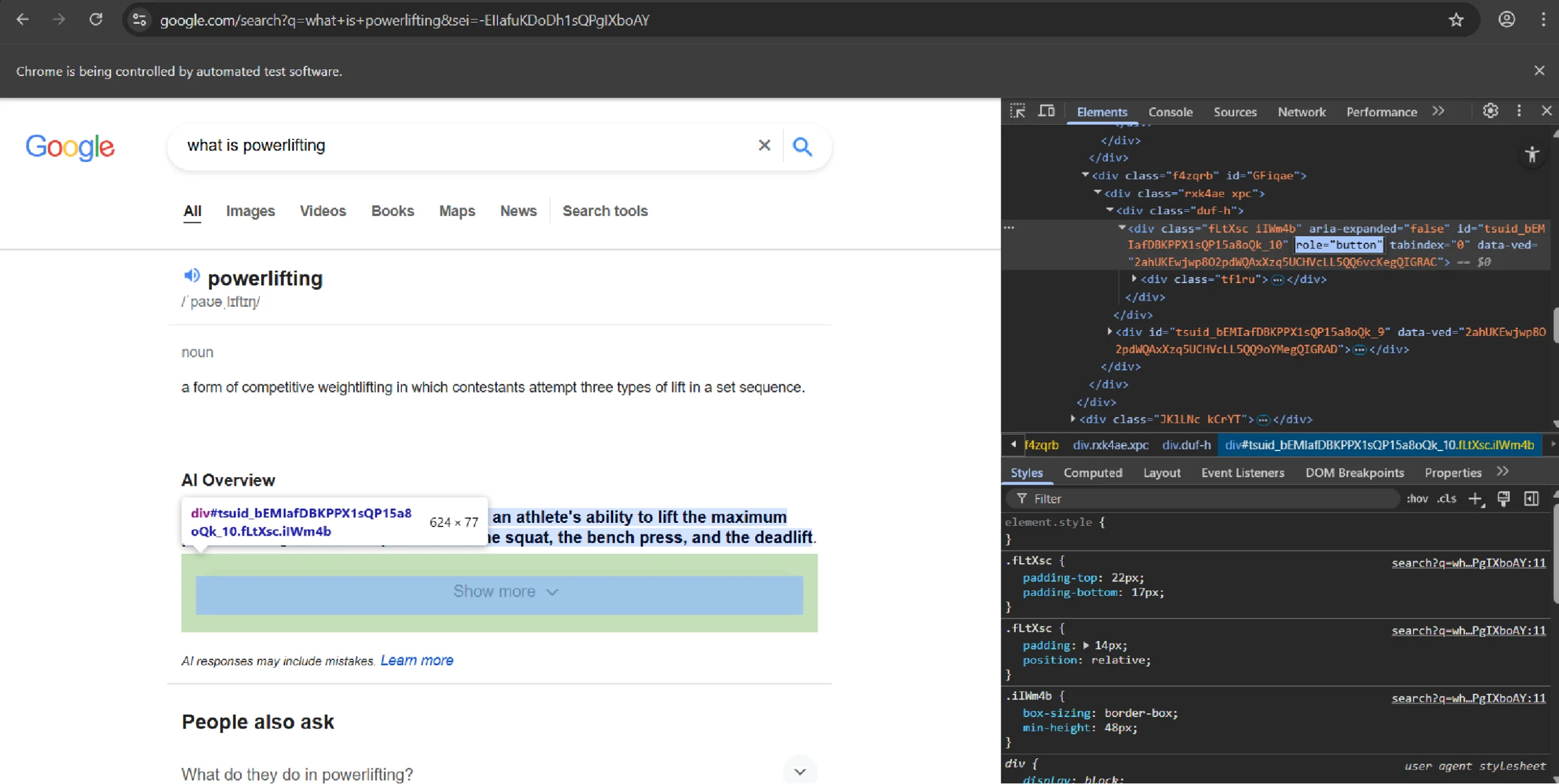
This part of the code simply tries to find and click that button to show the full text. It also includes checks (error handling) for two scenarios: if the button doesn’t exist (because the overview is already fully open) or if the button can’t be clicked.
# Click "Show more" if it exists to expand the AI overview
try:
show_more_button = self.page.get_by_role('button',name='Show more')
if show_more_button:
self.page.wait_for_timeout(random.randrange(1000,3000))
show_more_button.click()
# Wait a moment for the content to expand
time.sleep(1)
except Exception as e:
pass
This code
- Uses the get_by_role() method to find the “Show more” button. This is a much more stable way to locate it because it relies on accessibility names, which don’t change as often as complicated website code (CSS selectors).
- Adds a random delay of 1 to 3 seconds after attempting the click. This pause is crucial because it simulates the variable time a real person might take, making the automation much harder to detect.
- Continues execution if the “Show more” button isn’t found ( usually when the AI Overview is already fully expanded or simply missing.)
Locating and Extracting Text Content
After the “Show more” button is handled, the scraper looks for the AI Overview content using the .kCrYT selector. This specific code is how Google usually identifies the main container for its AI-generated content.
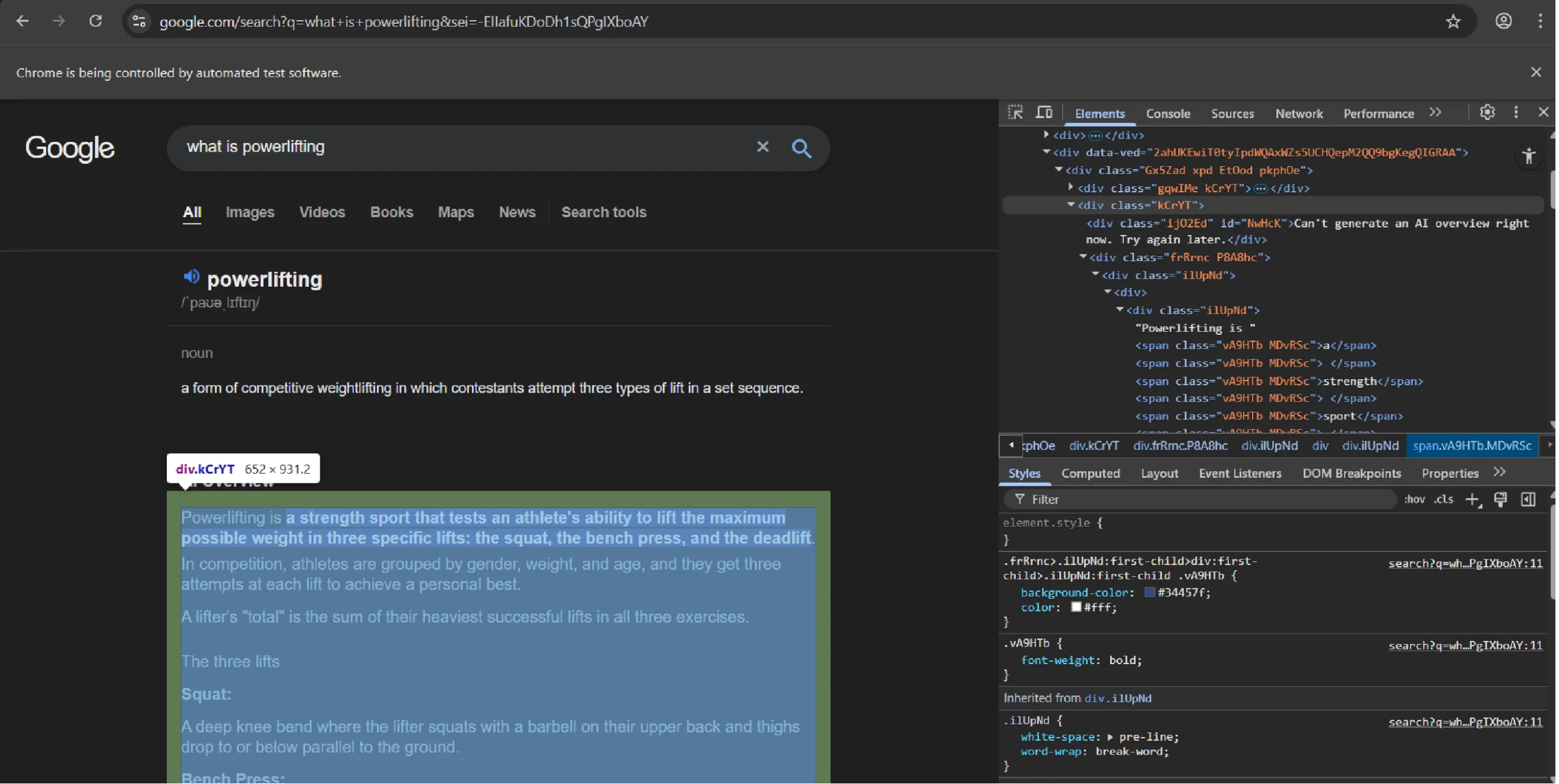
However, the page has multiple elements with the class kCrYt, including one that holds the ‘AI Overview’ heading. The code grabs all of them and picks the one right after the heading.
ai_overview_selector = '.kCrYT'
try:
elements = self.page.query_selector_all(ai_overview_selector)
loop = 0
for element in elements:
if "AI Overview" in element.text_content():
ai_overview_element = elements[loop+1]
break
loop = loop + 1
except Exception as e:
print(e)
if ai_overview_element:
result['ai_overview_present'] = True
# Extract the main AI Overview text
text_content = ai_overview_element.inner_text()
result['ai_overview_text'] = text_content.strip()
Once the code finds the correct content, the inner_text() method is used to grab all the visible text. This gives you the full summary Google generated, but without any messy HTML tags.
The .strip() method then quickly cleans things up by removing any extra spaces at the beginning or end of the text. This is necessary because web pages often include this kind of unwanted whitespace.
Capturing Source Citations
The AI Overview usually has citations that link back to its sources. The scraper grabs these by searching for all the anchor tags (the hyperlinks) inside the main overview box.
It collects two things for each source: the URL destination (the actual web address) and the display text (the title you see on the screen). This is how you get all the source documents.
# Try to extract sources/citations
source_links = ai_overview_element.query_selector_all('a[href]')
sources = []
for link in source_links:
href = link.get_attribute('href')
text = link.inner_text().strip()
if href and text:
sources.append({
'text': text,
'url': href
})
result['ai_overview_sources'] = sources
else:
print(f"No AI Overview found for query: {query}")
The code includes a check, if href and text, to make sure only valid sources are saved. This avoids storing any links that are empty or broken.
Each valid source is then saved as a small dictionary. This keeps the clickable text and the destination URL together. This format makes it easy later on to analyze where the AI Overview is getting its information or to compare the source titles to the summary text.
Performing Multiple Query Web Scraping
To run the scraper for lots of different searches, use the scrape_multiple_queries() method. This part of the code handles the whole process, making sure there’s a delay between each search.
This delay is really important because it prevents your scraper from running too fast, which helps you avoid getting rate-limited or looking too suspicious to Google.
def scrape_multiple_queries(self, queries: List[str]) -> List[Dict]:
"""
Scrape AI Overviews for multiple queries
Args:
queries: List of search queries
Returns:
List of dictionaries containing results for each query
"""
results = []
for i, query in enumerate(queries):
print(f"Processing query {i+1}/{len(queries)}: {query}")
result = self.search_and_extract_ai_overview(query)
results.append(result)
# Add delay between requests to avoid rate limiting
if i < len(queries) - 1:
time.sleep(3)
return results
There’s a three-second pause between each search query. This delay is there to mimic natural browsing behavior and significantly lowers the chance of Google slowing down (throttling) your connection.
The script also provides progress output as it runs. This is helpful for monitoring long scraping jobs, so you always know the current processing status.
Cleanup and Resource Management
Proper cleanup is important to make sure memory is released and all processes stop correctly.
The close method takes care of this by systematically shutting down all Playwright resources in the exact reverse order of how they were started. This ensures everything closes cleanly.
def close(self):
"""Close the browser"""
if self.page:
self.page.close()
if self.context:
self.context.close()
if self.playwright:
self.playwright.stop()
Main Execution and Result Export
The main function shows you exactly how to run the scraper, from starting it up to exporting the final results. This structured format gives you a repeatable template you can use for your full-scale, production scraping jobs.
def main():
"""Main function to demonstrate usage"""
# Example queries that might trigger AI Overview
queries = [
"what is artificial intelligence",
"how does machine learning work",
"what is deep learning",
"what is ChatGPT",
"what are neural networks",
"how does AI image generation work",
"what is natural language processing",
"what is computer vision",
"what is reinforcement learning",
"what are language models"
]
scraper = GoogleAIOverviewScraper(headless=False)
try:
# Start the browser
scraper.start()
# Scrape AI Overviews
results = scraper.scrape_multiple_queries(queries)
# Save results to JSON file
output_file = 'ai_overview_results.json'
with open(output_file, 'w', encoding='utf-8') as f:
json.dump(results, f, indent=4, ensure_ascii=False)
print(f"\nResults saved to {output_file}")
# Print summary
print("\n=== Summary ===")
for result in results:
status = "Found" if result['ai_overview_present'] else "Not Found"
print(f"Query: {result['query']}")
print(f"AI Overview: {status}")
if result['ai_overview_present']:
print(f"Text length: {len(result['ai_overview_text'])} characters")
print(f"Sources: {len(result['ai_overview_sources'])}")
print("-" * 50)
finally:
# Close the browser
scraper.close()
if __name__ == "__main__":
main()
The results are saved in JSON format using UTF-8 encoding. This is important because it saves all international characters correctly and makes sure the data works with all your analysis tools later.
Code Limitations
This code is a good start to scrape AI search results, but there are a few limits you need to consider:
- Maintenance Headache: Google’s layout and code is constantly changing—things like class names and features get restructured. This means your code will require ongoing maintenance and monitoring to keep it working.
- Rate Limits & Blocking: Google uses advanced bot detection and rate limiting. Even with our anti-detection steps, too many requests from one IP will often trigger CAPTCHAs or temporary blocks. This makes scraping at a large scale very difficult.
- Performance Costs: Browser automation uses a lot of your computer’s memory and CPU. Trying to run thousands of queries isn’t practical unless you use powerful distributed infrastructure and a smart queue management system.
Why Choose a Web Scraping Service
Building a custom AI Overview scraper for your enterprise is a hidden tax on engineering talent, requiring constant maintenance, debugging, and resource allocation away from innovation.
ScrapeHero, a fully managed, enterprise-grade web scraping service, eliminates this overhead entirely. Our self-healing infrastructure, massive-scale proxy network, and AI-powered quality checks turn the complex challenge of data extraction into a simple, reliable API call.
Contact ScrapeHero today to start your solution and free your engineering team from the burden of scraping infrastructure.
Frequently Asked Questions
Google sometimes hides AI Overviews when it detects automated browsers like Playwright. Anti-bot systems can still spot these frameworks even when you use anti-detection flags. To troubleshoot this, you need to manually check if the overview is appearing consistently when you browse normally. Also, check the browser console for any JavaScript errors, and make sure the .kCrYT selector your code uses is still the correct one.
You can use a few techniques to increase success rate:
1. Delay on Blocks: If blocked, pause requests and gradually increase the delay.
2. Rotate Proxies: Use multiple residential proxies to spread traffic geographically.
3. Change Identity: Randomize user agents and browser settings to evade detection.
4. Go Off-Peak: Schedule scraping during low-traffic hours when limits are softer.
5. Monitor Frequencies: Watch response patterns to find the fastest safe request speed.
Yes, you can change the target language:
1. Edit the Code: In the launch_persistent_context() method, change the locale (e.g., set locale=’fr-FR’ for French) and update the timezone_id for the right region.
2. Keep in mind: The AI Overview language always follows the language of your search query.



