

A website stores its metadata in meta tags. These tags are static, meaning you can scrape website metadata using request-based methods. Just make a request to the target website, extract all the tags named ‘meta’, and get all their attributes.
Want to learn exactly how? Read on. This article shows you how to scrape metadata using Python and JavaScript.
Scrape Website Metadata: Data Scraped from Meta Tags
The code shown in this tutorial scrapes all the meta tag attributes.
It scrapes key-value pairs of all the attributes in this code, except for these standard attributes:
- name
- property
- itemprop
- http-equiv
For these attributes, the code only scrapes the values and pairs it with the value of the corresponding content/value attributes.
Look at this standard metatag defining the viewport size.
<meta name="viewport" content="width=device-width, initial-scale=1">The scraper will extract these attributes as:
{
"viewport":"width=device-width, initial-scale=1.0",
}

Scrape Website Metadata Using Python
You need three external libraries to scrape metadata using Python:
- requests: Allows you to fetch the HTML source code of the target web page.
- BeautifulSoup: Enables you to parse and extract HTML code.
- random_header_generator: Helps you generate random HTTP headers.
Start the code with importing the necessary packages. Besides the packages mentioned above, this code also imports the json module. This module allows you to save the extracted data to a JSON file.
import json
from bs4 import BeautifulSoup
import requests
from random_header_generator import HeaderGenerator
The code can extract meta tags from multiple URLs by repeatedly calling a function, extract_meta_tags(), that:
- Accepts a URL
- Extracts metadata from the URL
- Saves the extracted data to a JSON file
extract_meta_tags() starts with setting up the headers. It creates an object of the HeaderGenerator() class, which has a call method. So call the object directly to generate a set of HTTP headers.
generator = HeaderGenerator()
headers = generator()
Next, the function makes a HTTP request to the URL.
response = requests.get(url,headers=headers)
The response will contain the HTML code; pass this code to BeautifulSoup to parse it.
soup = BeautifulSoup(response.text,'lxml')
Then, you can use the find_all() method of the BeautifulSoup to extract metadata.
meta_tags = soup.find_all('meta')
find_all() returns a list of meta tags; iterate through them and extract all the attributes.
tag_attributes = {}
for tag in meta_tags:
for attr in tag.attrs:
if attr not in ["name", "content", "itemprop", "property","value","http-equiv"]:
tag_attributes[attr] = tag.attrs[attr]
elif attr not in["content","value"]:
content = tag.get_attribute_list("content")[0]
tag_attributes[tag.attrs[attr]] = content if content else tag.get_attribute_list("value")[0]
Finally, return the extracted metadata.
return tag_attributesYou can now use the extract_meta_tags() function to pull metadata from any website.
Start by reading a list of URLs from a text file.
with open("urls.txt") as f:
urls = [site.strip() for site in f.readlines()]
After extracting the URLs, iterate through the URLs and for each URL call extract_meta_tags() with the URL as the argument.
all_site_meta_tags = {}
for url in urls:
print(f'Fetching data from {url}')
attributes = extract_meta_tags(url)
all_site_meta_tags[f'{url.split("/")[2]}'] = attributes
Finally, save the extracted data to a JSON file using json.dump().
with open('meta_tag_content.json', "w", encoding="utf-8") as f:
json.dump(all_site_meta_tags, f, ensure_ascii=False, indent=4)
Here is the complete code to scrape metadata using Python:
import json
from bs4 import BeautifulSoup
import requests
from random_header_generator import HeaderGenerator
def extract_meta_tags(url):
generator = HeaderGenerator()
headers = generator()
response = requests.get(url,headers=headers)
soup = BeautifulSoup(response.text,'lxml')
meta_tags = soup.find_all('meta')
tag_attributes = {}
for tag in meta_tags:
for attr in tag.attrs:
if attr not in ["name", "content", "itemprop", "property","value","http-equiv"]:
tag_attributes[attr] = tag.attrs[attr]
elif attr not in["content","value"]:
content = tag.get_attribute_list("content")[0]
tag_attributes[tag.attrs[attr]] = content if content else tag.get_attribute_list("value")[0]
return tag_attributes
if __name__ == "__main__":
with open("urls.txt") as f:
urls = [site.strip() for site in f.readlines()]
all_site_meta_tags = {}
for url in urls:
print(f'Fetching data from {url}')
attributes = extract_meta_tags(url)
all_site_meta_tags[f'{url.split("/")[2]}'] = attributes
with open('meta_tag_content.json', "w", encoding="utf-8") as f:
json.dump(all_site_meta_tags, f, ensure_ascii=False, indent=4)
Here’s a flowchart showing the process:
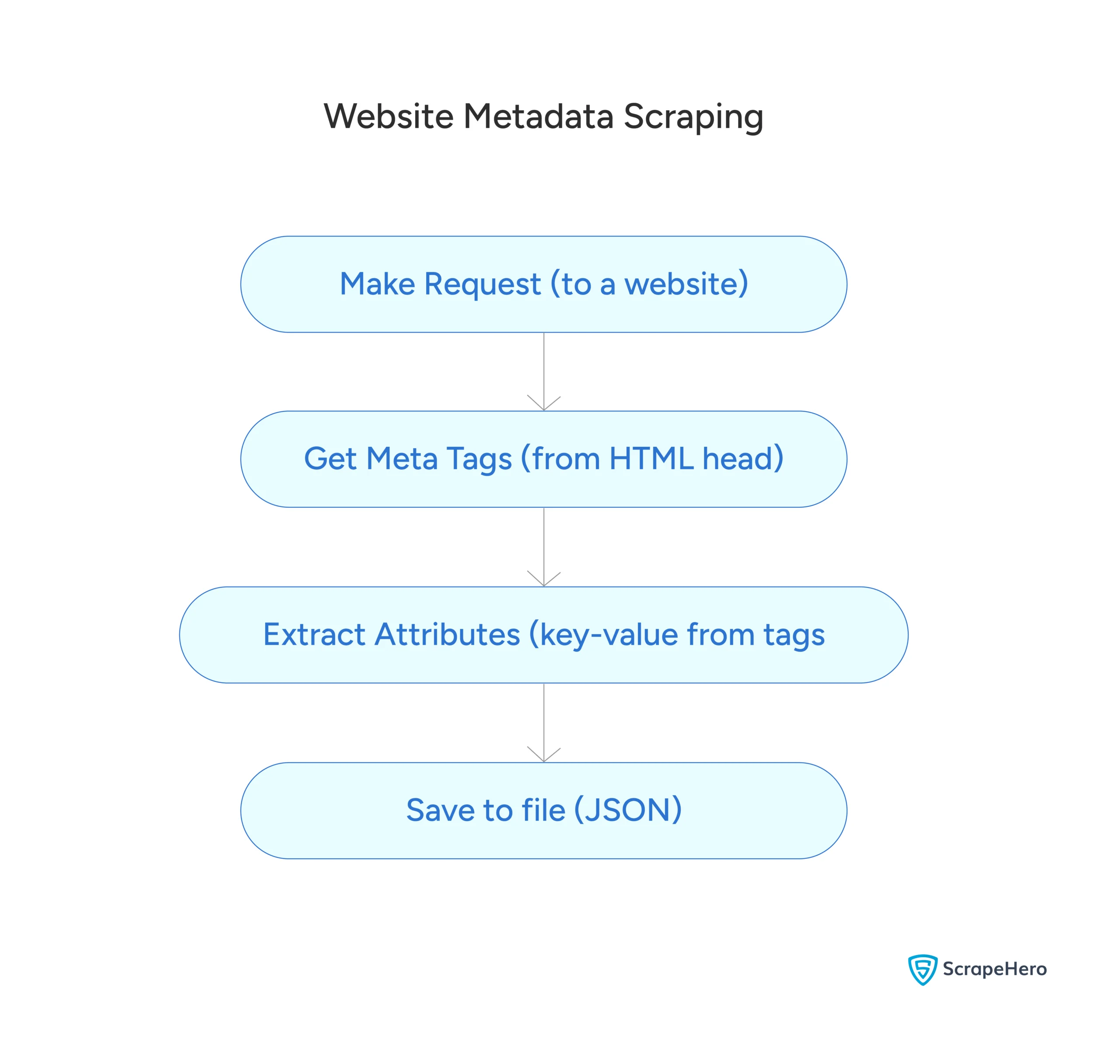
Scrape Website Metadata Using JavaScript
In JavaScript, you also need three external libraries:
- axios: Handles HTTP requests
- cheerio: Parses the HTML source code
- header-generator: Generates random HTTP headers
Import these packages to begin your JavaScript code to extract website metadata. You’ll also need to import ‘fs’ to allow your code to interact with the file system.
const fs = require('fs');
const axios = require('axios');
const cheerio = require('cheerio');
const header_generator = require('header-generator')
Next, create two asynchronous functions:
- fetchMetaTags()
- scrapeData()
fetchMetaTags
This function accepts a URL and returns a dict containing meta tag attributes.
Begin by setting up random HTTP headers using the header-generator library.
const generator = new header_generator.HeaderGenerator()
const headers = generator.getHeaders()
Next, make an HTTP request to the URL with the headers using the axios.get() method.
const response = await axios.get(url, { headers });
The response will contain the HTML code of the target webpage; parse this HTML using cheerio.load(). This will create a cheerio object. You can extract meta tags from this object; however, before that define an empty dict metaData to save all the meta tags.
const metaData = {};
Now, you can extract meta tags and iterate through them. In each iteration:
- Extract all the attributes
- Iterate through the attributes and extract the tag attributes
- Store it to metaData
$('meta').each((i, tag) => {
const attributes = $(tag).attr()
const entries = Object.entries(attributes)
entries.forEach((entry) => {
if (!['name', 'value', 'content', 'itemprop', 'property', 'http-equiv'].includes(entry[0])) {
metaData[entry[0]] = entry[1]
}
else if (!['value', 'content'].includes(entry[0])) {
const content = $(tag).attr('content')
if (content) {
metaData[entry[1]] = content
} else {
metaData[entry[1]] = $(tag).attr('value')
}
}
})
});
scrapeData
This function accepts a file path and returns a dict containing the meta tags from all the URLs.
Start by reading a text file to get a list of URLs.
const urls = fs.readFileSync(filePath, 'utf-8').split('\n').filter(Boolean);
Now, you can iterate through the list of URLs and call fetchMetaTags for each. But before that define a dict, all_tags, to store the tags from all the URLs.
const all_tags = {};
Next, iterate the URL list and in each iteration:
- Call fetchMetaTags()
- Save the dict returned to all_tags
for (const url of urls) {
console.log(`Fetching meta data for: ${url}`);
const metaData = await fetchMetaTags(url);
all_tags[url.split('/')[2].replace('\r', '')] = metaData;
}
Finally, write all_tags to a JSON file using fs.writeFileSync() method.
const outputPath = 'metat_data.json';
fs.writeFileSync(outputPath, JSON.stringify(all_tags, null, 4));
Now, you can execute the entire script by just calling scrapeData().
if (require.main === module) {
scrapeData('urls.txt');
}
Here’s the complete code for website metadata scraping using JavaScript.
const fs = require('fs');
const axios = require('axios');
const cheerio = require('cheerio');
const header_generator = require('header-generator')
// Function to fetch and parse meta tags from a URL
async function fetchMetaTags(url) {
try {
const generator = new header_generator.HeaderGenerator()
const headers = generator.getHeaders()
console.log(headers)
const response = await axios.get(url, { headers });
const $ = cheerio.load(response.data);
const metaData = {};
$('meta').each((i, tag) => {
const attributes = $(tag).attr()
const entries = Object.entries(attributes)
entries.forEach((entry) => {
if (!['name', 'value', 'content', 'itemprop', 'property', 'http-equiv'].includes(entry[0])) {
metaData[entry[0]] = entry[1]
}
else if (!['value', 'content'].includes(entry[0])) {
const content = $(tag).attr('content')
if (content) {
metaData[entry[1]] = content
} else {
metaData[entry[1]] = $(tag).attr('value')
}
}
})
});
return metaData;
} catch (error) {
console.error(`Error fetching URL ${url}:`, error.message);
return null;
}
}
// Main function to read URLs from a file and scrape meta data
async function scrapeData(filePath) {
try {
const urls = fs.readFileSync(filePath, 'utf-8').split('\n').filter(Boolean);
const all_tags = {};
for (const url of urls) {
console.log(`Fetching meta data for: ${url}`);
const metaData = await fetchMetaTags(url);
all_tags[url.split('/')[2].replace('\r', '')] = metaData;
}
const outputPath = 'metat_data.json';
fs.writeFileSync(outputPath, JSON.stringify(all_tags, null, 4));
} catch (error) {
console.error('Error reading file:', error.message);
}
}
// Replace 'urls.txt' with the path to your text file containing URLs
if (require.main === module) {
scrapeData('urls.txt');
}
Scrape Website Metadata: Code Limitations
The code can scrape attributes from any website if they don’t block your scraper. If that happens, you may need to use techniques to avoid anti-scraping measures like request throttling.
ScrapeHero Metadata Scraper: An Alternative
If you want to avoid coding, use Metadata Scraper from ScrapeHero Cloud. It’s a no-code solution where you only have to input the URLs and the scraper extracts the meta tags for you.
Here’s how you can get started for free:
- Go to the scraper’s homepage
- Click ‘Create Project’
- Give a name
- Enter URLs
- Click ‘Gather Data’
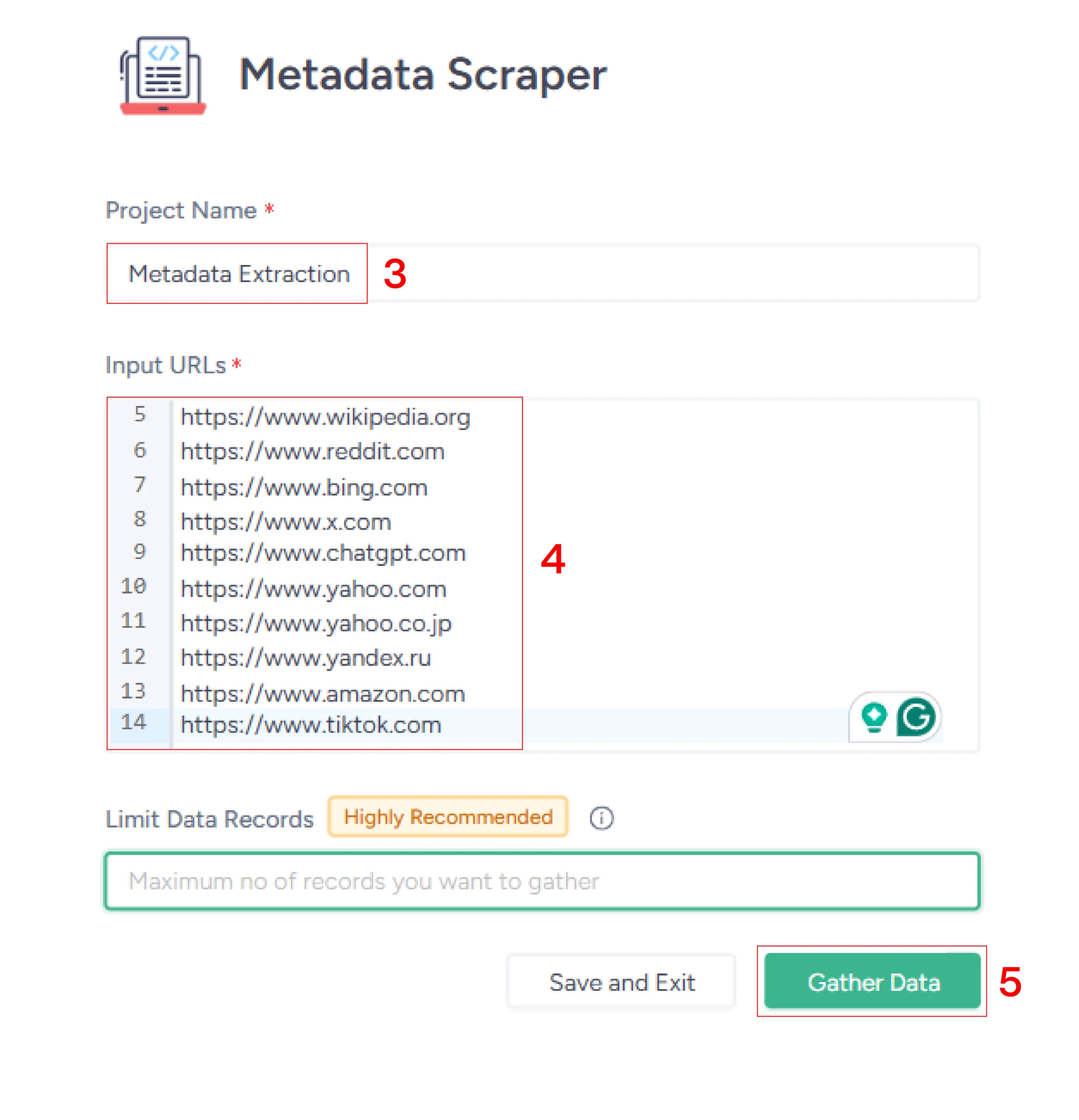
You don’t have to write the code. Use Metadata Scraper from ScrapeHero Cloud; you only need to input URLs and the scraper will do the extraction for you.
Moreover, you can enjoy additional benefits with ScrapeHero Cloud’s premium plans:
- Schedule scrapers to run at fixed intervals
- Get the data delivered directly to your cloud storages
- Integrate the scraper to your workflow using APIs
Wrapping Up
The code will allow you to scrape meta tags from many websites. However, you might get errors due to the anti-scraping measures used by some websites. To handle these challenges effectively, you’ll need to implement additional techniques.
If you don’t want to manage these complexities yourself, it’s better to use a web scraping service like ScrapeHero.
ScrapeHero is an enterprise-grade web scraping service provider. We are capable of building quality scrapers and crawlers according to your specifications. Just contact us and you can focus on using the data, not scraping it.



