

Cheerio is a popular library for Node.js web scraping. It is known for Its jQuery-based API and ability to use CSS-style syntax. Want to try it out? This article covers the basics of web scraping using Cheerio and Axios.
Setting Up Cheerio for Web Scraping
You can install Cheerio and other required libraries locally in a directory.
Here are the steps:
1. Create a directory for your Cheerio project.
2. Open the terminal inside the directory and type this command to initialize project files.
npm init3. Use these commands to install required packages locally.
npm install axios
npm install cheerio
npm install objects-to-csvThis code installs three packages:
- Axios to handle HTTP requests
- Cheerio to parse and extract data from HTML pages
- objects-to-csv to save the extracted data to a CSV file
Figuring Out CSS Selectors
This scraper shown in this tutorial extracts data from scrapeme.live’s product listing to illustrate web scraping using Cheerio and Axios.
From each product listing, the scraper extracts the product URL using CSS selectors. You can figure out the selector using your browser’s inspect tool.
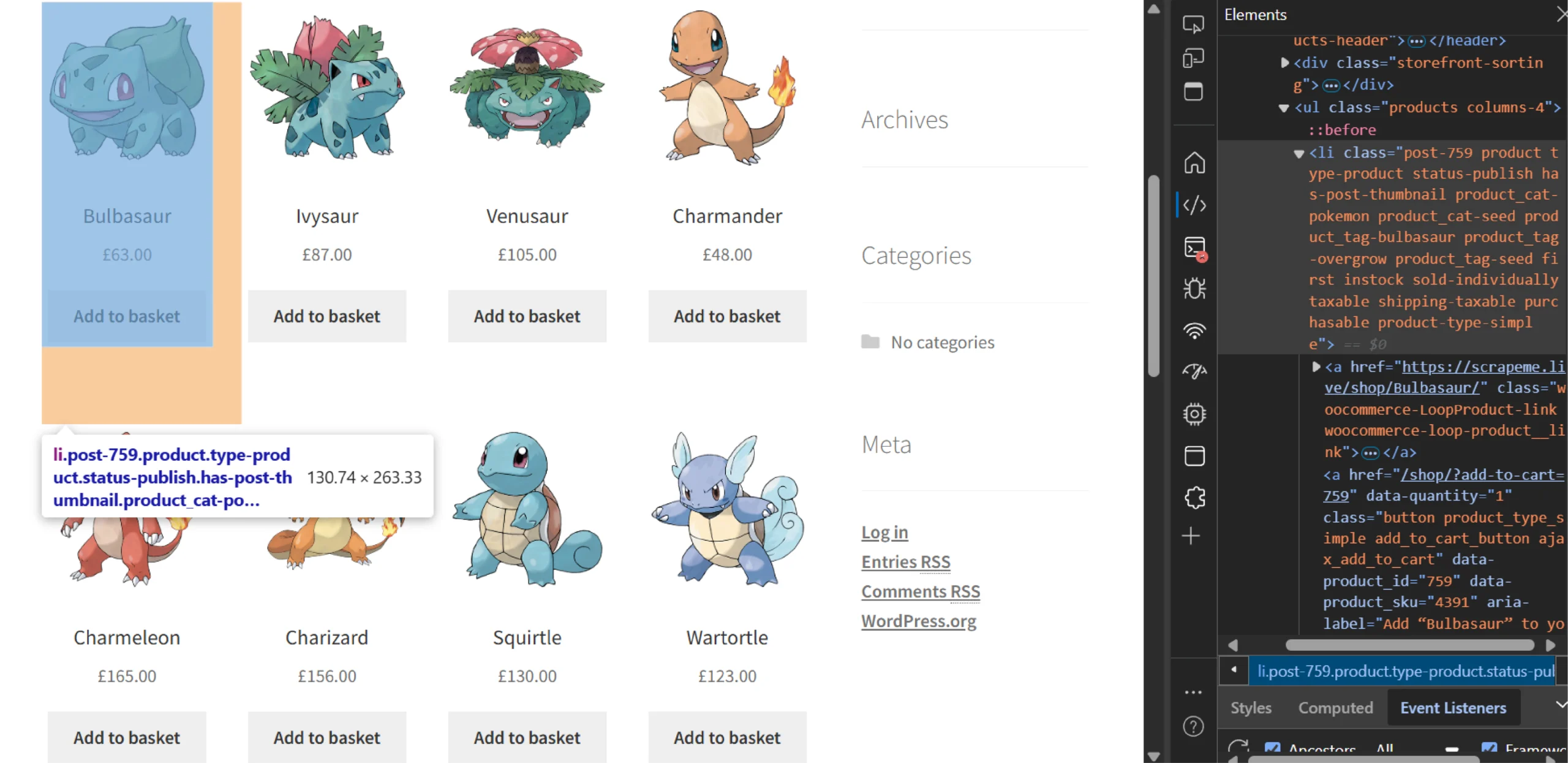
You can see that the product URL is the href attribute of the anchor tag inside a li tag. So you can first get the li tag using the CSS selector ‘li.product’
Then, you can extract the URL from the anchor tag’s href attribute using Cheerio’s methods, which you can read below.
Similarly, you can use the inspect method on the product page to determine the CSS selectors required to extract product details.
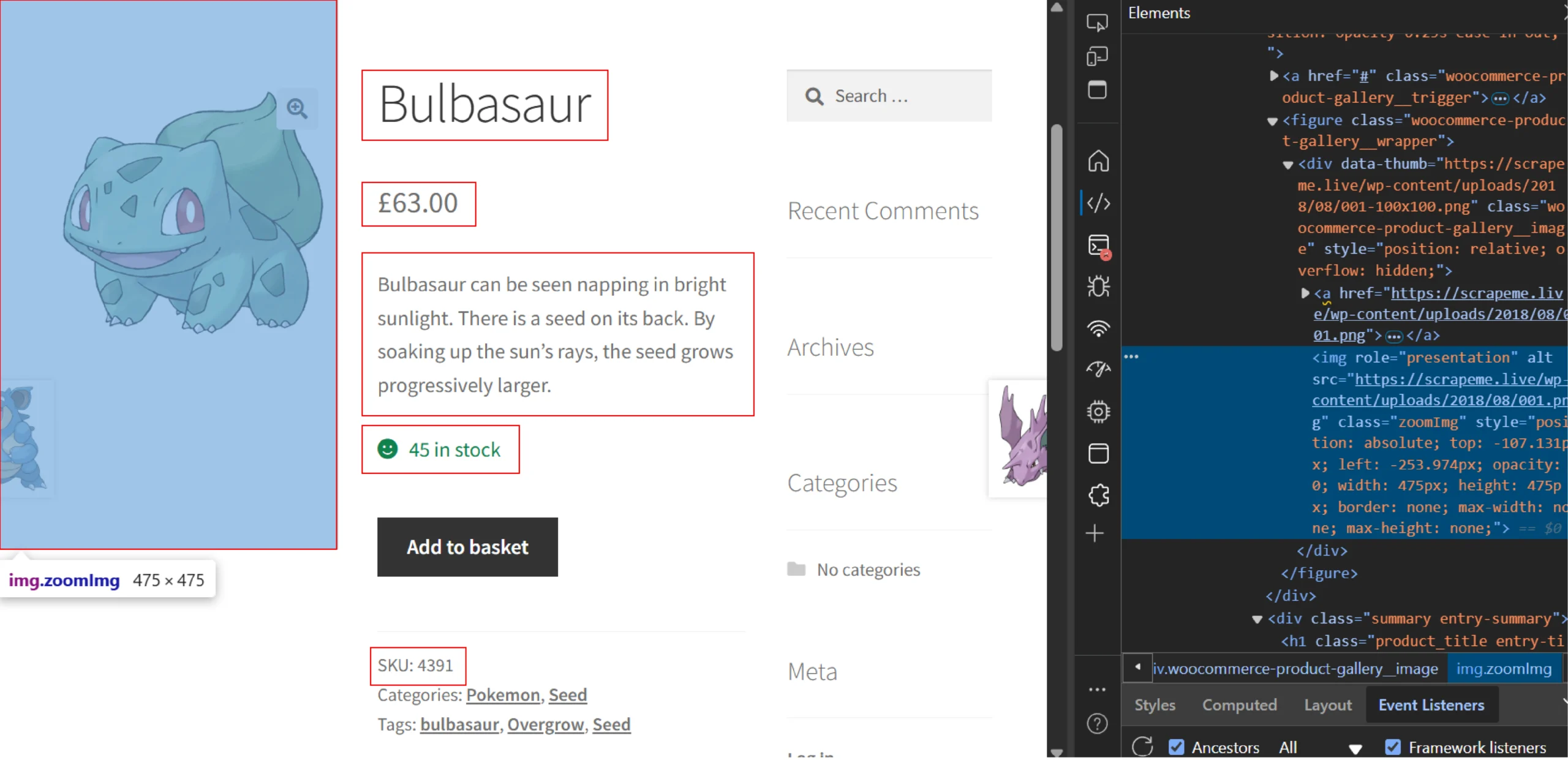
Here are the CSS selectors of the highlighted elements:
- Description: “div.woocommerce-product-details__short-description”
- Title: “h1.product_title”
- Raw Price: “p.price>span.woocommerce-Price-amount.amount”
- Stock: “p.stock.in-stock”
- SKU: “span.sku”
- Image Anchor Tag: “figure>div>a”

Code for Web Scraping Using Cheerio and Axios
The code shown in this tutorial follows these steps:
- Navigate to https://scrapeme.live/shop, and extract the product URLs.
- Go to the next page and extract the product URLs
- Repeat the process for a specific number of pages
- Loop through all the product URLs and extract the required data
- Save the data to a CSV file
To begin, import the required packages.
const axios = require('axios');
const cheerio = require('cheerio');
const ObjectsToCsv = require("objects-to-csv");Next, write a function main() that implements the workflow at a high level.
async function main() {
const urls = await get_urls("https://scrapeme.live/shop/",3)
const product_details = []
urls.forEach(async (url) => {
details = await extract_data(url, product_details)
product_details.push(details)
})
const csv = new ObjectsToCsv(product_details)
csv.toDisk('./products.csv')
}The function performs three tasks:
- Gets product URLs from the listing page using get_urls()
- Loops through the URLs and extracts data from each using extract_data()
- Saves the extracted data to a CSV file using ObjectsToCsv()
You now need to define functions that main() uses.
get_urls()
This function accepts two arguments:
- The product listing URL
- The maximum number of pages to scrape
async function get_urls(url, max_pages) {
const urls = []
for (let i = 1; i <= max_pages; i++) {
const res = await axios.get(url)
const parser = cheerio.load(res.data)
const products = parser('li.product')
products.each(function (product) {
const parsed_product = parser(products[product])
const product_url = parsed_product.find("a").attr("href");
urls.push(product_url)
})
url = parser("a.next.page-numbers").attr("href")
}
return urlsThe function uses a loop, and in each iteration:
- Makes an HTTP request to the listing URL using Axios.
- Parses the response text using Cheerio
- Extracts all the elements holding the product URLs.
- Loops through the elements, extracts the product URLs, and saves them in a list
- Replaces the listing URL with the next-page URL obtained using CSS selectors.
The loop runs as long as the loop count is not greater than the maximum number of pages you need to scrape. After the loop ends, the function returns a list of product URLs.
extract_data()
This function accepts a product URL and returns the product data as a dict object.
async function extract_data(url) {
const product_res = await axios.get(url);
const product_parser = cheerio.load(product_res.data);
const raw_description = product_parser("div.woocommerce-product-details__short-description").text();
const raw_title = product_parser("h1.product_title").text();
const raw_price = product_parser("p.price>span.woocommerce-Price-amount.amount").text();
const raw_stock = product_parser("p.stock.in-stock").text();
const raw_sku = product_parser("span.sku").text();
const raw_imageUrl = product_parser("figure>div>a").attr("href");
const description = clean_string(raw_description);
const title = clean_string(raw_title);
const price = clean_string(raw_price);
const stock = clean_stock(raw_stock);
const sku = clean_string(raw_sku);
const imageUrl = clean_string(raw_imageUrl);
const product_details = {
title,
description,
price,
stock,
sku,
imageUrl
}
return product_details
}extract_data() also uses Axios and Cheerio to fetch and parse HTML data; as before, it uses CSS selectors to locate and extract data points.
The function also modifies the extracted data points using calls either clean_string() or clean_stock():
- clean_string() removes extra spaces
- clean_stock() removes the phrase ‘in stock’
clean_string()
function clean_string(str) {
return str.replace(/[\n\t\r]/g, "").trim()
}clean_string()
function clean_stock(str) {
return str.replace(' in stock', '').trim()
}Finally, you can end the code by calling main().
if (require.main === module) {
main()
} How to Use Proxies and Headers in Axios
The code shown did not use customized HTTP headers. These headers include data necessary for
- Authorization: Provides authentication data, such as a user’s credentials or an API key, to the server.
- Protection: Establishes security measures, such as defining the origin of a request or guarding against cross-site scripting (XSS) attacks.
- Content Management: Specifies the format or encoding that the server returns.
Servers consider the header content to check whether a request is from a bot, making it crucial to use custom headers for hiding your scraper from servers.
When a server detects your scraper, it may block your IP address. That is where proxies come in. By using a proxy, you can hide your IP address; the server will only see the IP address of the proxy used.
Here’s how you can use headers and proxies while web scraping using Axios.
const axios = require('axios');
const res = await axios.get('http://httpbin.org/get?answer=42', {
proxy: {
host: '',
port:
},
Headers: {
'content-type': 'text/json'
}
});
How to Send POST Requests Using Axios
Sometimes, you need to make a POST request to scrape data from an endpoint. You can use the axios.post() method to do so; the method uses two arguments:
- Endpoint URL: The URL to which you want to make a POST request.
- Payload: An object that contains the data you want to send with the request.
You can use axios.post() to send POST requests.
const axios = require('axios');
const res = await axios.post('https://httpbin.org/post', { hello: 'world' }, {
headers: {
'content-type': 'text/json'
}
});Cheerio-Axios Web Scraping: Pros and Cons
Pros
- Familiar Syntax: Cheerio incorporates a portion of the jQuery core and eliminates any inconsistent DOM (Document Object Model) and unwanted browser elements, presenting a superior API.
- Extremely Fast: Cheerio operates on a straightforward sequential DOM, which allows for quick parsing, handling, and display.
- Highly Adaptable: Cheerio utilizes the parse5 parser and can also use htmlparser2. It can parse almost any HTML or XML document.
Cons
- No JavaScript Executions: You can only scrape static websites using this method. For dynamic sites, you need to use browser automation libraries like Puppeteer or Playwright.
- Limited CSS-Selector Support: Although you can use various CSS selectors to locate HTML elements, Cheerio doesn’t support all of them.
Why Use a Web Scraping Service
Web scraping using Cheerio and Axios can be an option for small-scale data extraction from static sites. But for large-scale web scraping or scraping dynamic sites, you need to use other libraries. You also need to take care of anti-scraping measures yourself.
If you want to avoid all this burden, use a web scraping service.
A web scraping service like ScrapeHero can take care of all the technical aspects of web scraping. You don’t have to bother about choosing libraries, dynamic websites, or even anti-scraping measures. ScrapeHero has got them covered for you.
ScrapeHero is a fully-managed web scraping service capable of building enterprise-grade scrapers and crawlers. Our services also include custom RPA and AI solutions.


