The data gathered from the internet through web scraping is usually unstructured and needs to be formatted in order to be used for analysis. This page goes into detail about a couple of common needs based on the data that we provide – “Formatting of the extracted Data in various ways” and “Loading the data into a customer’s database”. This page attempts to explain the boundaries between what we provide as part of our regular/core service and what we expect the requester of the data (you) to do or we provide as an add-on to our service on request.
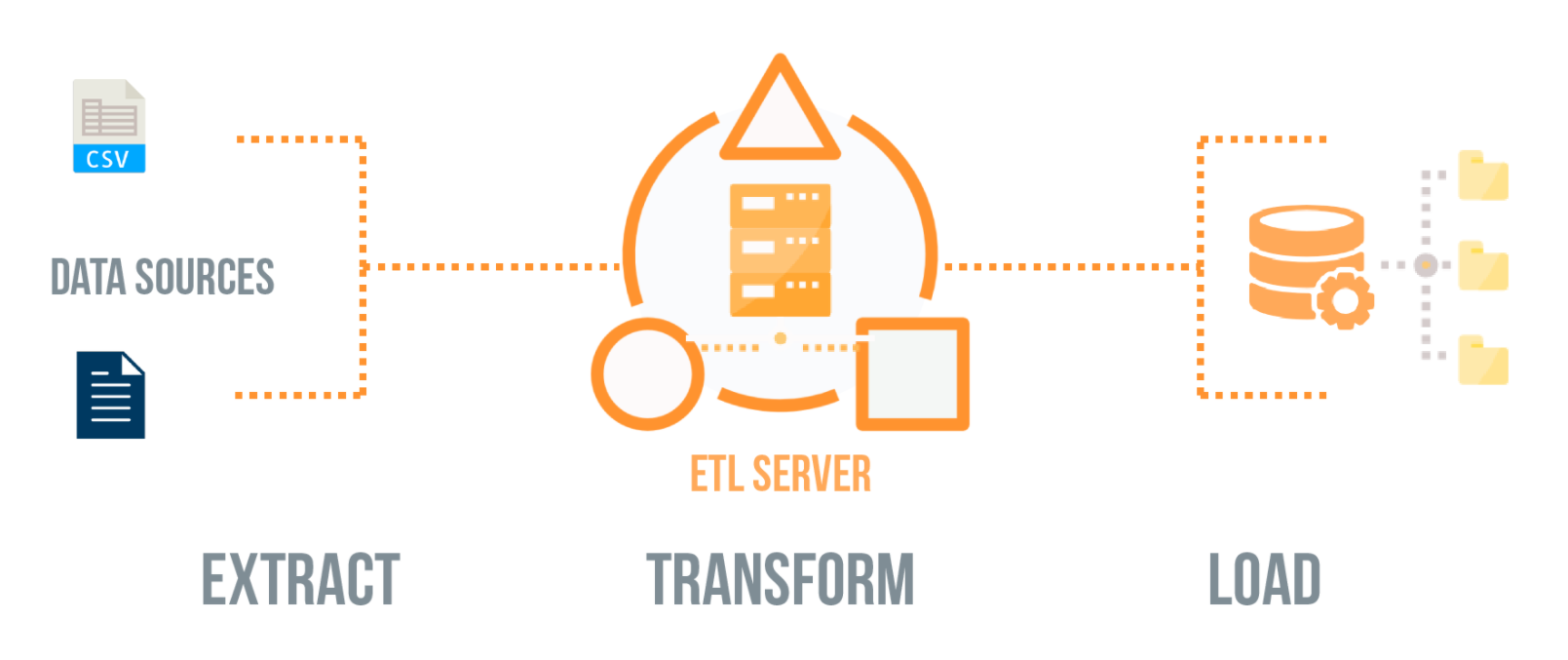
Dealing with data involves a set of operations that are commonly known as ETL Extract, Transform and Load operations.
Extract (E):
We deal with only the “E” part of it. ETL Extract means we will extract the data and give you the raw data in a structured format that matches how it comes from the source.
Transform (T) and Load (L):
ScrapeHero’s core services do not include the “T” and “L” parts of it as part of our regular and default service offering, only ETL Extract. That would fall within the realm of your application and application/database programmers or as an add-on to our service.
We provide the data from the source site broken down into some fields that lend themselves to be broken down – which may or may not match how you need it for your database. The fields that can be broken down are separated using HTML tags or CSS styles in the source itself.
That is where the “T” part comes in and you will need to transform what we provide, into the format you need and then “L” load it into your application or backend database.
Transform Example 1:
If the source site has some date data and they have it in the format April 20, 2014 at someplace and as 4/20/14 in others or in any of the other formats a date can be represented.
We will provide you the date “as is” from the site, you will need to Transform it to fit the date field in your database.
Transform Example 2:
Another example would be a field such as $35,012,25 – We get the data “as is”. Our core web scraping service does not include removing the comma nor does it include converting Dollars to Euros or British Pounds.
Transform Example 3:
Some more examples are pages that contain just text in a block which appears formatted to the eye but is just a block of text with no way to separate the text. e.g. a typical citation text
Wara, Michael W. "Permanent El Niño-Like Conditions during the Pliocene Warm Period." Science 309 (2005): 758-762.
or a typical “address block”
ABC Enterprises 123 Main St Anytown USA 10234
Such text does contain what appear to have discrete and structured “fields or data points” such as Author, Title, Date or Address, Street, Zipcode etc because the source website contains all this in one big block of text without any delimiters that can be used programmatically. Splitting (which is a form of text transformation) is not something that is part of our core web scraping offering.
Difficulty of transforming data
Transformation of data is never perfect or easy – despite our best efforts to do this as an “add on” service, the combinations of source data available on the billions of pages on the Internet is a complicated task to achieve with a high degree of accuracy.
Maintenance of such transformations
It is also very time consuming to maintain such transformations over time and websites.
Plain text typed by people can take many shapes and change with the author, eg lets take an example of a product that lists product weights and that is all in one location on the page e.g lets say the data entry person for this site starts with
7.5lb for one product and then in the next product uses this format 7 1/2 pounds then over time a new person comes in and types this in 7 and 3/4 lb. and so on ... 7 lb 3 ounces
As you can see, while this text is easily recognizable and in some case understandable by a human, trying to maintain this variation even for one site is an expensive proposition
Creating data
We also cannot create data for you (ironically contrary to popular belief).
If the data is not on the source site, we obviously cannot get it for you or “insert/add” it for you. Some of the popular requests have been around getting contact information e.g. “We really need that email address or phone number”.
If the site doesn’t have the email or phone number – we will not be able to get it for you.
Loading data into customer databases
Due to various reasons such as security, low integration costs and the need to keep our systems and our customer’s systems decoupled, our regular services do not load or import any data into our customer’s databases or applications.
We can write the data into a customer’s Amazon S3 bucket, Azure storage, FTP server, Dropbox, etc and then our customers read the data from these storage locations and after checking the quality of the data import them into their databases.
This approach keeps the security of our customer systems high and prevents any issues from our systems from impacting customer systems.
Free Tools to the Rescue
Thankfully, the field of ETL has been around as long as Data has been and there is some excellent and Open source (Free) tools that can make life a lot easier for people who are just getting into this field.
Pentaho
One of the excellent and free tools out there is Pentaho, available at community.pentaho.com – The product used for ETL is the Kettle product. It can be downloaded and can take the JSON format we provide and transform into wondrous and consistent data and load it into your database.
According to their site, “Data Integration (or Kettle) delivers powerful Extraction, Transformation, and Loading (ETL) capabilities, using a groundbreaking, metadata-driven approach.”
Talend Open Studio
Another Open source and free product in this space is Talend
According to their site “Free, open-source integration software. Talend’s open source products and open architecture create unmatched flexibility so you can solve integration challenges your way. Talend reduces the learning curve and lowers the barrier to adoption for data integration, data profiling, big data, application integration, and more.”
We hope this page clears up some mystery and draws some clear boundaries in what to expect of our core service and what would be something you would do or ask for as an add-on to our service.



