

You’ve probably heard that bypassing TLS fingerprinting is “easy” or that you can defeat the tools like JA3 with a simple library switch. The reality is messier. What actually happened is that the defensive landscape evolved—and so did the TLS fingerprint bypass techniques.
This guide breaks down the real game and what it means for your scraping strategy.
Understanding TLS Fingerprinting
TLS (Transport Layer Security) is the encryption protocol securing HTTPS connections. But before any encryption happens, your browser and server perform a “handshake”—a negotiation where they agree on encryption algorithms and key exchange methods.
This negotiation occurs in plain sight and is where fingerprinting happens.
The ClientHello: Your TLS Signature
Your browser’s first message in this handshake is called the ClientHello. It contains:
- TLS Version—Which TLS versions your browser supports (TLS 1.2, TLS 1.3, etc.)
- Cipher Suites—A list of encryption algorithm combinations your browser supports
- Extensions—Optional TLS features (Server Name Indication, ALPN protocol negotiation, Key Share, Signature Algorithms, etc.)
- Elliptic Curves—Different mathematical methods for securely exchanging encryption (x25519, secp256r1, etc.)
- Elliptic Curve Point Formats—How you encode curve data for transmission
The server reads this message (before any encryption) and immediately learns which browser—or bot—you are.
This matters because each browser is hardcoded with a specific configuration. Chrome lists cipher suites in one order, Firefox in another, Safari in yet another. A Python requests library lists them in an unnatural order that screams “automation.”
The combination (TLS version + cipher order + extension order + curves + point formats) creates a unique fingerprint.
Example:
- Chrome: TLS 1.3, 1.2 → cipher suites in order A → extensions in order B → prefers x25519
- Firefox: TLS 1.3, 1.2 → cipher suites in order C → extensions in order D → also prefers x25519
- Python requests: TLS 1.2 only → outdated cipher suites → no x25519 → obviously not a browser
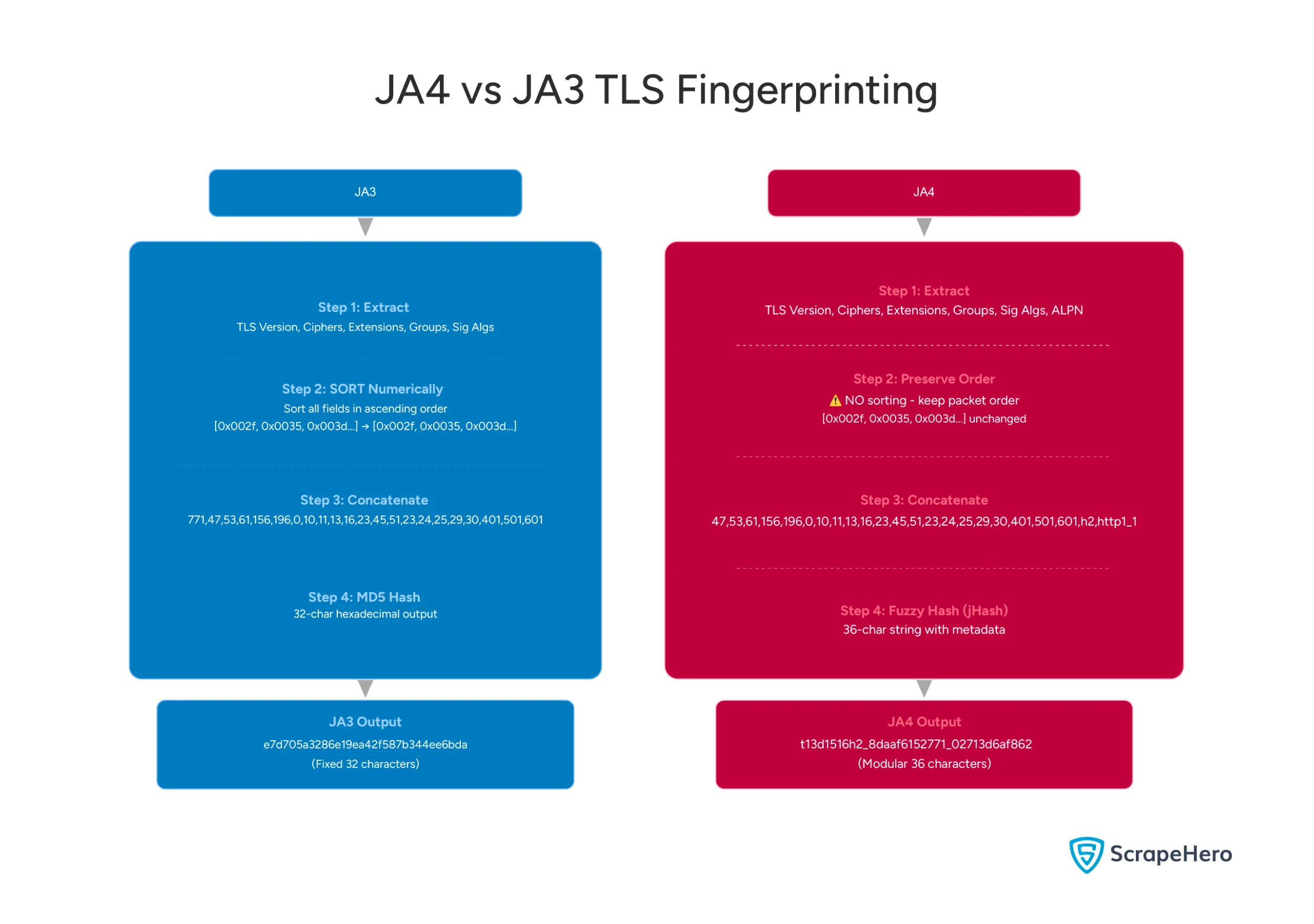
This is the entire foundation of TLS fingerprinting. JA3, JA3S, and JA4 are just different ways of hashing these fields into comparable signatures.
The landscape of TLS fingerprinting in web scraping has transformed considerably—let’s trace that evolution.
The JA3 Era (2017-2021)—”Just Randomize and Move On”
When JA3 fingerprint evasion arrived, it was genuinely revolutionary. For the first time, servers could identify you not by your IP, but by your TLS handshake signature. Every browser has a unique fingerprint based on:
- TLS version
- Cipher suite order
- Supported elliptic curves
- Elliptic Curves Point Formats
- Extension order and values
JA3 hashed these values into a clean 32-character ID, known as your TLS fingerprint.
Tidbit: The “3” in JA3 refers to the three inventors with “JA” initials—John Althouse, Jeff Atkinson, and Josh Atkins—rather than to a version number. Its successor, JA4, was released by Althouse at FoxIO to continue the naming tradition by including a fourth contributor, Joshua Alexander.
Evasion Attempt
The answer seemed simple: use libraries like uTLS (Go), curl-impersonate (Python), and browser-based solutions that had stealth plugins to randomize or spoof browser fingerprints. The logic was sound:
- Mimic Chrome’s TLS signature
- Randomize parameters between requests
- Mix in residential proxies for traffic that “looked human”
This means many sites that relied solely on JA3 detection got bypassed.
The Counter-Response
Smart defenders realized the problem: JA3 was too simple. They implemented:
- JA3S (server response fingerprinting)—servers now fingerprinted client libraries themselves by analyzing the ServerHello response
- JARM (fingerprinting server behavior)—flipped the script by fingerprinting the server’s TLS implementation to detect honeypots and proxies
- Behavioral analysis—tracking patterns beyond the handshake (request timing, header order, HTTP/2 frame sequences)
Once defenders moved beyond JA3, simple spoofing stopped working.
The JA4 Transition (2023-2025)—”Sorting as an Evasion Blocker”
The Problem JA4 Was Built to Solve
By 2023, scrapers had figured out how to systematically evade JA3 and JA3S: simply randomize your cipher suites, extensions, and elliptic curves on every request.
Since each randomization produced a different JA3 hash, you’d never get flagged as the same bot twice. Libraries like uTLS made this trivial—rotate the fingerprint every request, and you’re invisible.
Defenders recognized this problem. A sophisticated scraper could cycle through 100 different “valid” fingerprints, each matching a different real browser, making signature-based tracking useless.
The JA4 Solution: Normalization and Sorting
JA4 countered randomization by introducing normalization logic. Instead of creating a signature based on the exact order and values of cipher suites and extensions, JA4 would:
- Sort cipher suites and extensions into a canonical order, meaning randomization would not have any effect.
- Ignore GREASE values, which are fake, random, and harmless values; even if they varied, the fingerprint remained stable.
- Normalize ephemeral fields, like session keys, that change frequently
The theory was elegant: no matter how a scraper randomized its handshake, JA4 would normalize it back to a stable fingerprint. Randomization would no longer work.
And that is why defenders invested in JA4 as the “next generation” fingerprinting that made randomization obsolete
GREASE (Generating Random Extensions And Sustaining Extensibility) Middleboxes, like firewalls, often block unfamiliar data because they are tuned to old patterns. This rigidity—known as ossification—stalls internet progress, as old hardware rejects new security upgrades simply because they look different. GREASE fixes this by injecting random “junk” values into handshakes. This forces the network to handle unknown data constantly, training hardware to ignore unrecognized extensions instead of failing. This ensures future upgrades pass through seamlessly.
Counters to JA4’s Sorting Logic
The problem emerged quickly: browsers counter JA4’s sorting algorithm by introducing legitimate complexity that even a “sorting” algorithm struggles to normalize.
While JA4 tries to normalize randomization into stable patterns, browsers use the following strategies to stay ahead:
- Using Non-Ignored Extensions JA4 ignores GREASE values, but browsers can introduce other “real” extensions that affect the fingerprint.
For example, Safari uses the Pre-Shared Key (PSK) extension for resuming a session. Since this extension is only present on repeat visits (and absent on the first), the JA4 signature actually changes between the first and second request from the same browser.
This means JA4’s signature becomes unstable in real-world browsing scenarios where users naturally revisit sites.
- Entropy Injection (Beyond Sorting) While JA4 sorts extensions to defeat randomization, browsers can still change the values or parameters inside those extensions in ways that affect the fingerprint:
- Key Shares: Browsers can rotate the types of key-exchange algorithms they support or offer multiple versions, which alters the “Extension List” used in the JA4 hash.
- ALPN Shuffling: By rotating or varying the Application-Layer Protocol Negotiation (ALPN) list (e.g., swapping HTTP/2 and HTTP/3 support), scrapers change a core component of the JA4 “a” and “c” segments.
- Handshake Generalization (The “Herd” Defense) Privacy-focused browsers like Tor and Brave aim to make every user look identical, leading to a million people sharing one fingerprint, making it impossible to single anyone out.
- Anti-Fingerprinting Blocking Browsers like Firefox and Safari maintain lists of known tracking domains and block third-party requests to them. Even if a JA4 hash is stable, if the script trying to collect it is blocked, the fingerprinting fails before it begins. This approach bypasses the technical problem entirely by preventing collection at the source.
JA4’s Fundamental Limitation
JA4’s sorting approach is clever, but it has a critical flaw: it assumes randomization is the only evasion technique that matters.
By normalizing and sorting, JA4 made pure randomization useless for scrapers. But it didn’t account for legitimate browser diversity—and browsers aren’t about to standardize on a single fingerprint just to help defenders.
Defenders now have a “stable” fingerprint to work with, but that fingerprint is only stable if the browser doesn’t change its behavior in legitimate ways.
The moment browsers introduce new protocols, extensions, or certificate chains (which they constantly do), JA4 has to decide: ignore them and lose signal, or include them and accept natural fingerprint variation.
The Current State (2024-2026)—”Context Matters More Than Signatures”
Core Philosophical Shift
The detection industry has undergone a fundamental shift in philosophy over the past two years. No signature is perfect, but context always reveals intent and deception that isolated signals cannot hide.
This realization has reshaped how both attackers and defenders operate in this arms race.
How Modern Defenses Work
Layer 1: Multi-Signal Fingerprinting
Modern defenses combine multiple signals rather than relying on checking single JA3 hashes. A typical fingerprinting vector includes TLS hashes, HTTP/2 settings, certificate chains, DNS behavior patterns, velocity metrics, and geolocation consistency checks.
A single signature might match a legitimate browser, but the combination of these signals reveals the traffic’s true nature.
Layer 2: Correlation Strategy
This shift toward composite analysis forced attackers to maintain consistency across multiple independent signal channels simultaneously. A perfect TLS spoof becomes worthless if JavaScript execution patterns look wrong or if requests suddenly originate from five different locations within two minutes.
Modern WAFs correlate third-party signals, such as TLS fingerprints, with first-party signals, such as browser APIs and behavioral markers.
Layer 3: Machine Learning Detection
Machine learning has significantly accelerated detection capabilities, moving beyond rule-based systems. Cloudflare, AWS WAF, and other providers deployed ML models trained on millions of legitimate user sessions. These systems detect subtle anomalies: unusual cipher combinations, rare elliptic curves, and non-standard protocol upgrades.
Current Evasion Techniques
Technique 1: Residential Proxy + Real Browser Automation [Highest Effectiveness]
The most reliable evasion combines residential proxy infrastructure with genuine browser automation. Real browser instances, such as Chromium or Firefox, generate authentic TLS handshakes, while residential proxies route traffic through real ISP IP addresses. Stealth plugins remove automation telemetry, and behavioral randomization introduces natural human-like variance.
Why It Works:
- TLS fingerprint comes from a genuine browser
- Network behavior matches residential patterns exactly
- Interaction patterns include human-like randomness
Trade-off: Slower and substantially more expensive, but highly effective against sophisticated defenses.
Technique 2: Browser-Specific TLS Libraries [Medium Effectiveness]
Browser-specific TLS libraries, such as curl-impersonate, offer per-browser TLS configurations for Chrome, Firefox, Safari, and Edge.
Combined with header randomization, User-Agent rotation, and proper cookie handling, they create convincing signatures, but behavioral signals like request timing variance and scroll velocities can still reveal automation.
Why It Works Partially:
- TLS signature matches real browser patterns
- HTTP/2 frames are authentic and properly sequenced
- But behavioral patterns expose automation
Trade-off: Medium-cost approach that defeats signature-based systems but fails against behavioral ML anomaly detection.
Technique 3: Distributed Scraping Architecture [Moderate Effectiveness]
A third strategy distributes scraping load across multiple IP addresses and rotating browser profiles. This approach naturally varies request timing, rotates through different browser profiles, and intersperses legitimate traffic. No single fingerprint appears obviously wrong, velocity checks pass naturally, and context appears legitimate.
Why It Works:
- No single signature stands out as suspicious
- Velocity patterns resemble natural human behavior
- Distributed requests blend with legitimate traffic
Trade-off: Requires real infrastructure and investment, but resilient because it doesn’t depend on perfecting any single technique.
Velocity Checks A technique that measures the frequency, speed, and volume of incoming TLS handshake attempts from specific clients or network locations to detect bots.
The Modern Defense Stack
Level 1: Signature Detection
This layer checks for known bot fingerprints and blocks them immediately without further analysis.
- Cost: Very low
- Speed: instantaneous
- Defeated by: uTLS, curl-impersonate, or real browser automation.
Level 2: Distributed Fingerprinting
This layer combines multiple signals into composite anomaly scores and issues challenges when thresholds are exceeded.
- Cost: Medium
- Defeated by: Real browsers combined with residential proxies and behavioral consistency patterns.
Level 3: Behavioral ML Analysis
This layer builds comprehensive behavioral vectors from interaction, network, and content-access patterns.
- Cost: High, using ML models trained on millions of genuine sessions
- Defeated by: Human-like patterns, distributed requests, or sophisticated behavioral simulation.
Level 4: Sophisticated Context Analysis
This layer correlates multiple independent signals simultaneously: Chrome fingerprint, unusual APIs, perfect timing, and datacenter IP triggers.
- Cost: Very high (enterprise-only)
- Defeated by: Real users with genuine behavior or context simulation costing as much as human labor.
The Truth: What Works Against What
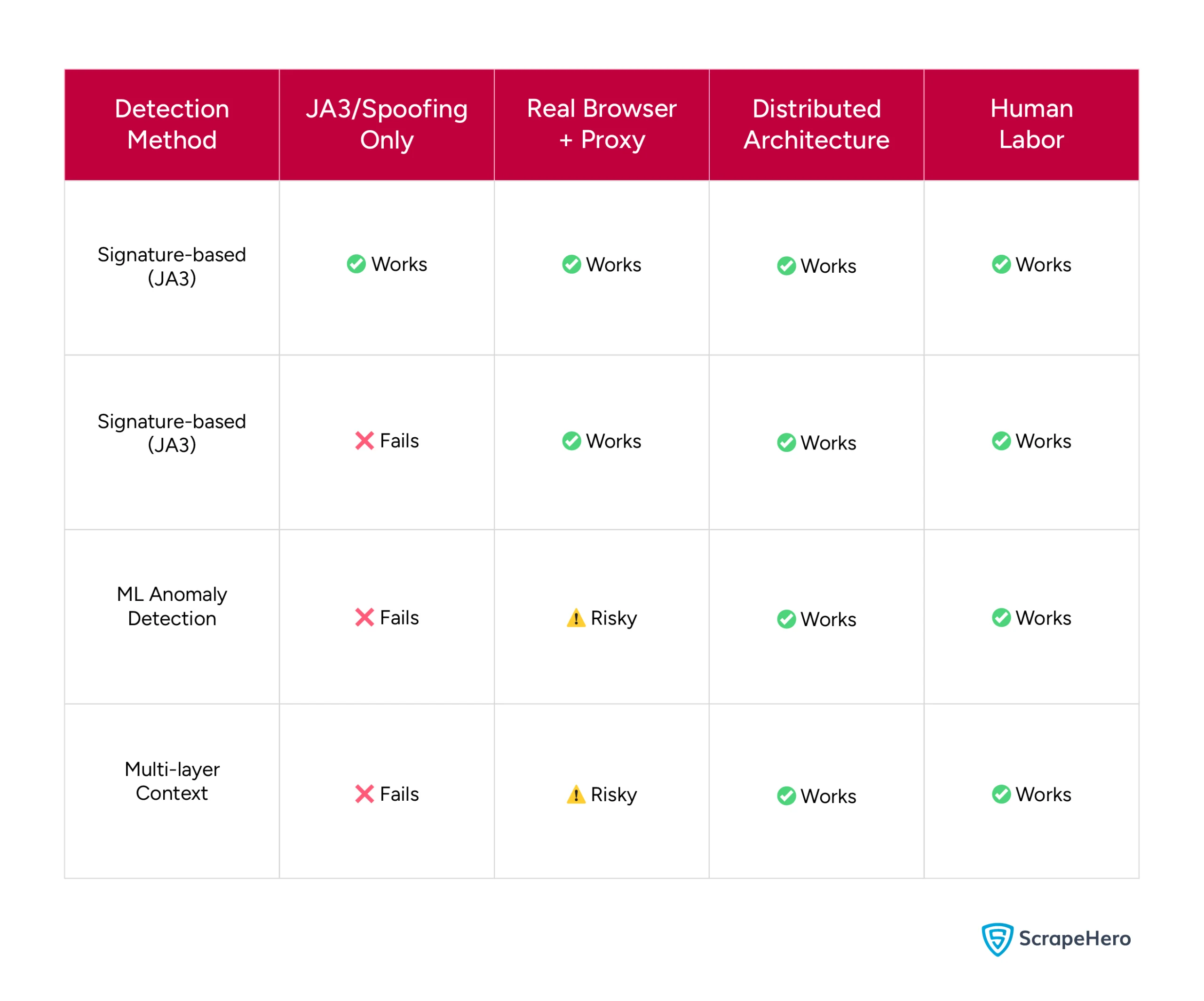
Key takeaway: Simple signature spoofing works against old defenses. Against modern defenses, you need authentic behavior, not authentic signatures.
Choosing Your Strategy
Matching Defense to Offense
The right TLS fingerprinting bypass techniques to use depend on what your target actually uses. Most sites fall into three tiers based on defense sophistication:
Basic Defenses (JA3, rate limiting):
Use uTLS or curl-impersonate with minimal infrastructure. These libraries allow you to change signatures, which defeats simple checks. This method is viable for many sites because it is low-cost.
Moderate Defenses (JA3S, behavioral checks, basic WAF):
For moderate defenses, you need real browser automation with Puppeteer or Playwright. Add residential proxy rotation and stealth plugins to defeat headless detection. This method allows you to perform behavioral randomization with realistic delays and handle moderate behavioral checks.
Enterprise Defenses (ML models, sophisticated WAFs):
Enterprises often employ robust defenses that require distributed real-browser instances across multiple residential IPs. Here, mimicking human patterns—varied clicking, scrolling, typing—becomes more critical. You may also need session management that mimics real user journeys to prevent detection.
Emerging Techniques
Emerging detection techniques include:
- WebRTC Leak Detection—checking if your real IP leaks
- Canvas Fingerprinting + TLS Correlation—combining renderer behavior with TLS signatures
- Hardware-Level Fingerprinting—analyzing TLS performance characteristics to detect emulation
- Behavioral Biometrics—ML models trained on thousands of real users to detect statistical anomalies
Emerging evasion techniques include:
- Isolated VM Execution—running browsers in isolated virtual machines that generate unique hardware fingerprints per session
- Device Farm Integration—accessing real devices through farm APIs
- Human-in-the-Loop Automation—a distributed network of human operators for high-value targets
- Adversarial TLS Fingerprinting—TLS configurations generated by machine learning that fool classifiers
How to Build Sustainable Systems
Layer Your Defenses:
Don’t rely on single evasion techniques since they all eventually fail. For instance, combine curl-impersonate for signatures, residential proxies for IP detection, and request randomization for velocity. This ensures that when one layer gets defeated, others still provide protection.
Distribute Your Requests:
Distribute your requests across IPs and browser profiles. Spreading requests across multiple IPs makes it harder to detect bots using velocity checks, and using different browser profiles prevents profile-based blocking.
Add Human Behavior:
Humans visit pages in random order, spend variable time, and sometimes revisit pages. Adding this natural variation defeats ML models trained on human behavior distributions. This isn’t random delays everywhere, but navigation patterns reflecting real browsing.
Why You Need a Web Scraping Service
Building your own scraping infrastructure means constantly chasing defenses. Every time detection evolves—and it evolves constantly—your solution breaks. You need to understand JA3, then JA3S, then behavioral ML, then context correlation.
By the time you’ve implemented one layer of evasion, defenders have already moved to the next.
A dedicated web scraping service owns this arms race instead. They monitor which defenses are being deployed and continuously update their evasion methods. When detection changes, their team adapts, and your scraper keeps working. You don’t need to become an expert in fingerprinting, behavioral analysis, or WAF evasion—you just use the service.
The sites that are trying hardest to block scrapers aren’t using JA3 anymore. They’re building ML models and correlating multiple signals. Keeping up with that evolution is a full-time job. A web scraping service, like ScrapeHero, handles it so you don’t have to.
ScrapeHero is an enterprise-grade web scraping service that handles everything for you. Connect with ScrapeHero now to free your team from the hassle of dealing with anti-scraping measures altogether.



