
Managing scraping pipelines can be challenging due to the complexities involved in data extraction, transformation, and loading. Apache Airflow provides tools to simplify the process and build scalable and reliable data pipelines. This article will guide you through creating a scraping pipeline using Airflow.
Scraping Pipeline Using Airflow: The Environment
A scraping pipeline is a data pipeline that uses web scraping during data ingestion. To build a scraping pipeline using Airflow, you need to have Python installed. That is because Apache Airflow is a Python package with workflows defined as Python scripts.
System Requirements
Apache officially supports modern Linux distributions and recent versions of macOS. If you are using Windows, you will need to install Airflow within the Windows Subsystem for Linux (WSL).
Installation
You can install Apache Airflow using a pip command.
pip install apache-airflowSince this tutorial focuses on Apache Airflow for web scraping, you also need to install additional Python libraries for data extraction and manipulation:
- BeautifulSoup: For parsing HTML data.
- Requests: For handling HTTP requests.
- Pandas: For data manipulation.
- SQLite3: For database interactions
You can install these libraries using pip:
pip install beautifulsoup4 requests pandas sqlite3Scraping Pipeline Using Airflow: Building a DAG
In Apache Workflow, workflows are defined as Directed Acyclic Graphs (DAGs). These DAGs are Python scripts stored in the dags folder of your default Airflow directory.
Overview of the Airflow Scraping Pipeline
This tutorial builds a workflow that scrapes details of research papers from arXiv.org on a specific topic. The pipeline performs the following tasks:
- Scrapes four details of each research paper: topic, authors, abstract, and PDF link
- Performs data manipulation tasks:
- Creates a data set without abstracts
- Extracts authors and creates a frequency table
- Loads the data into an SQL database
Steps to Build a DAG
1. Import Required Packages: Each DAG requires a specific set of Python libraries and modules. This tutorial uses:
- DAG: To define the properties of your DAG.
- PythonOperator: To call Python functions.
- datetime & timedelta: For date and time manipulation.
- BeautifulSoup: For parsing HTML data.
- requests: For handling HTTP requests.
- pandas: For manipulating tabular data.
- sqlite3: For database interactions.
- os: For operating system interactions.
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime, timedelta
from bs4 import BeautifulSoup
import requests, pandas, sqlite3, os2. Define Default Arguments: Specify default arguments for your DAG to handle errors and set properties like retries, start date, etc.
default_args = {
"owner":"airflow",
"depends_on_past":False,
"start_date":datetime(2024,9,19),
"email_on_failure": False,
"email_on_retry": False,
"retries":1,
"retry_delay":timedelta(minutes=5)
}3. Set Up Your DAG: Use the DAG constructor to:
- Specify the ID of your DAG.
- Pass the default arguments defined above.
- Write a description for clarity.
- Specify the schedule for your DAG.
dag = DAG(
dag_id='scraping_pipeline',
default_args=default_args,
description='Web Scraping Pipeline Using Airflow',
schedule_interval=timedelta(days=1), # operates everyday
)4. Create the Scraping Task:
- Define a function that sends an HTTP request to arXiv.org to extract details of the research papers (topic, abstract, PDF link, authors)
def scrape_data(**kwargs):
query = "internet"
response = requests.get(f"https://arxiv.org/search/?query={query}&searchtype=all&abstracts=show&order=-announced_date_first&size=50")
soup = BeautifulSoup(response.text)
articles = soup.find_all("li",attrs={"class":"arxiv-result"})
articleInfo = []
for article in articles:
rawTopic = article.find("p",attrs={"class":"title"}).text
topic = rawTopic.replace("\n","").strip()
abstract = article.find("p",attrs={"class":"abstract"})
rawFullAbstract = abstract.find("span",{"class":"abstract-full"}).text
fullAbstract = rawFullAbstract.replace("\n","").strip()
pdfURL = article.div.p.span.a['href'],
authors = article.find("p",{"class":"authors"}).text.split()[1:]
arxivArticle= {
"Topic": topic,
"Abstract": fullAbstract,
"PDF": pdfURL,
"Authors": authors
}
articleInfo.append(arxivArticle)
df = pandas.DataFrame(articleInfo)
df.to_csv('/home/madhudath/airflow/outs/articles.csv')- Set up a PythonOperator to call this function, specifying the task ID and associated DAG.
scraping_task = PythonOperator(
task_id ='scrape_data',
python_callable=scrape_data,
provide_context = True,
dag = dag
)5. Create Data Transformation Task:
- Define a function that processes the scraped data to create a dataset without abstracts and generates frequency tables for author names.
def transform_data(**kwargs):
# read the scraped data
with open('/home/madhudath/airflow/outs/articles.csv') as f:
df= pandas.read_csv(f)
newDf = pandas.DataFrame()
newDf = df[['Authors','Topic','PDF']]
newDf.to_csv("/home/madhudath/airflow/outs/withoutAbstracts.csv")
authors = df[['Authors']]
all_authors = []
for value in authors.values:
for author in eval(value[0]):
all_authors.append(author)
authorDf = pandas.DataFrame(all_authors)
authorFrequency = authorDf.value_counts().reset_index()
authorFrequency.columns = ['Value','Counts']
authorFrequency.to_csv("/home/madhudath/airflow/outs/authors.csv")- Specify another PythonOperator that calls this transformation function.
transforming_task = PythonOperator(
task_id = 'transform_data',
python_callable=transform_data,
provide_context = True,
dag = dag
)6. Create a Loading Task:
- Define a function that reads the datasets stored in an output folder and loads them into an SQLite database as tables. Use the to_sql() method of Pandas to store the data to the SQL database.
def load_data(**kwargs):
# specify the output folder
output_folder = '/home/madhudath/airflow/outs/'
#specify the sql database
connection = sqlite3.connect('/home/madhudath/airflow/airflow.db')
for file in os.listdir(output_folder):
# check if the file ends with .csv
if file.endswith(".csv"):
# if yes, append the filename to the folder path and construct the file path
file_path = os.path.join(output_folder,file)
# read the file using Pandas
df = pandas.read_csv(file_path)
#connect the file to sqlite
df.to_sql(file, connection, if_exists='replace')- Set up another PythonOperator to execute this loading function.
loading_task = PythonOperator(
task_id = 'load_to_sqlite',
python_callable=load_data,
provide_context = True,
dag = dag
)7. Specify Task Dependencies: Define the order in which tasks execute by setting dependencies between them using bitwise operators (>> or <<).
scraping_task >> transforming_task >> loading_taskScraping Pipeline Using Airflow: Running the DAG
Once you have saved the Python script in the appropriate folder you can view it in the Airflow UI. To test the code, start Apache websever and Apache scheduler.
airflow scheduler
airflow webserverNow, you can open the Airflow UI at https://localhost:8080
The homepage will show a list of DAGs imported by Airflow. On the search_bar, type and click ‘scraping_pipeline.’
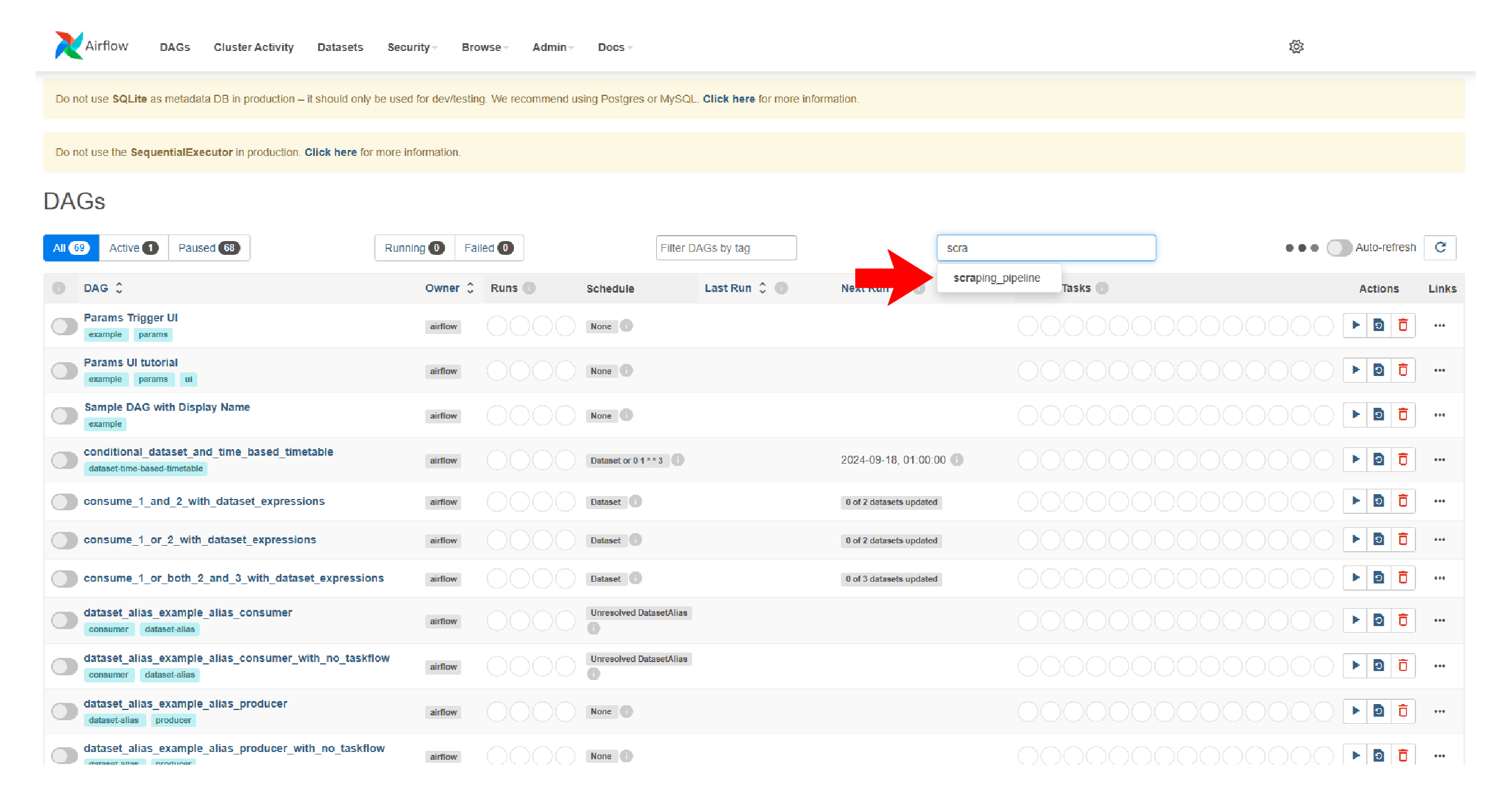
The page of your scraping pipeline will have several helpful information. You can see
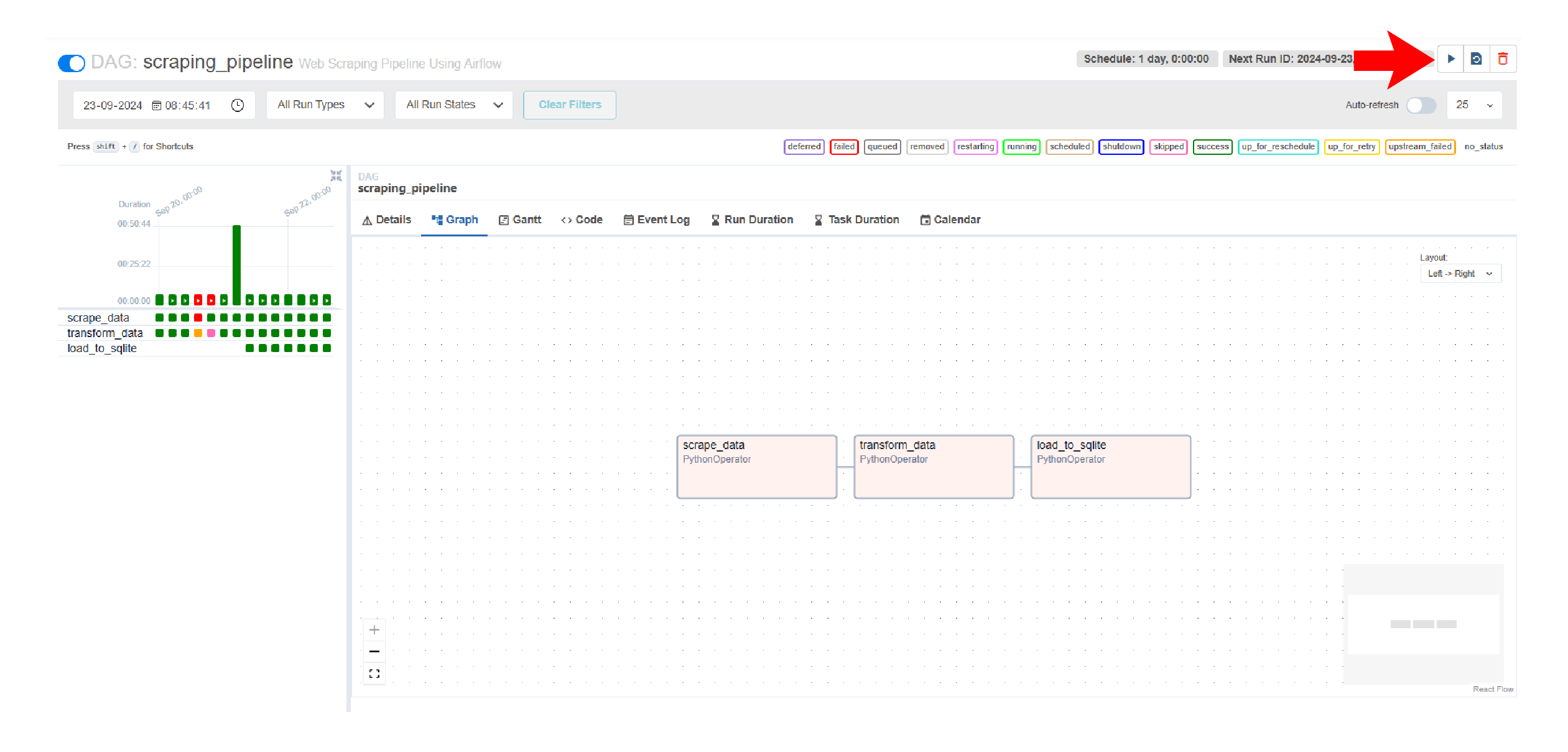
- DAG Details: This includes details of the DAG, like name and ID, and a summary of DAG runs, like total successes and failures.
- Graph: A visualization of tasks and operators of the DAG
- Gantt: A visual representation of the DAG runs
- Code: The Python code the DAG uses.
- Event Log: Logs of each event, like successes, failures, etc.
- Run Duration: Duration of each run as a bar chart
- Task Duration: Duration of each task during each run as a multi-line chart
- Calendar: A calendar that shows the days on which workflow is executed
Although the DAG is scheduled to run every day, you can run it manually. Click the play button on the top right corner.
Code Limitations
This code illustrates the basics of data scraping with Apache Airflow; however, the code is unsuitable for large-scale operations:
- The code doesn’t have error-handling or logging capabilities, making debugging difficult
- It doesn’t implement rate limits or other techniques to bypass anti-scraping measures, which increases its chances of being blocked.
- URL is hardcoded, reducing flexibility. You have to change the DAG code each time.
How Can a Web Scraping Service Help?
Airflow makes building and managing pipelines easier; anyone with Python experience can deploy scraping pipelines using Airflow. However, building pipelines will still take considerable effort and time, especially for large-scale projects.
Therefore, it is better to outsource the web scraping part of your pipeline as it is challenging in itself. You can use a web scraping service like ScrapeHero to do so.
ScrapeHero is a fully managed web scraping service provider. We can deliver high-quality data for your data pipeline, leaving you to focus on managing your Airflow pipeline.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data



