

BeautifulSoup enhances your experience while navigating a tag soup, which is a poorly structured HTML code. However, it doesn’t parse the HTML code itself.
BeautifulSoup is a Python library that uses other libraries, like lxml, to parse but offers intuitive methods to extract data. This makes BeautifulSoup web scraping extremely convenient.
This article discusses the inner workings of Python BeautifulSoup.
How BeautifulSoup Works
During BeautifulSoup web scraping, the library creates an object using the raw HTML you wish to parse. It follows specific steps to do so:
- Accepting HTML: BeautifulSoup accepts a raw HTML.
- Choosing a Parser: BeautifulSoup uses an external parser to create a parse tree.
- Creating a BeautifulSoup Object: It uses the parse tree created by the HTML parser to create a BeautifulSoup object.
However, you only need to write a single line of code to perform all the steps above.
soup = BeautifulSoup(html_code,'lxml')Role of a Parser
You need an external parser to perform basic parsing, as BeautifulSoup can’t parse. Parsing means analyzing a string of symbols to extract meaningful information. In web scraping, parsing refers to converting HTML or XML data into an easy-to-handle format.
Here are the basic steps a parser performs:
- Lexical Analysis: A parser breaks down the HTML code into small tokens to simplify analysis.
- Syntax Analysis: It analyzes each token to determine the opening and closing tags.
- Building a Basic Parse Tree: From the discovered tags, the parser creates a hierarchical structure.
Learn more about data parsing in What Is Data Parsing?
Understanding Parse Trees
A parse tree is an abstract structure that doesn’t use physical memory. The only way to understand this structure is by looking at the source code.
The structure of a parse tree represents the hierarchical organization of an HTML source code. By understanding the hierarchy, a parser can provide methods to navigate the HTML code. For instance, you can tell the parser to get the text of an h1 tag inside a div with a specific class.
You can also represent the structure of a parse tree using nodes. Each node will be an HTML tag. Moreover, the nodes are connected with child or parent nodes using branches.
To get a better idea, consider the following HTML code.
<html> <head> <title>Sample Title</title> </head> <body> <h1>Sample Heading</h1> <p>Sample Paragraph</p> </body> </html>
Its parse tree has the following structure.
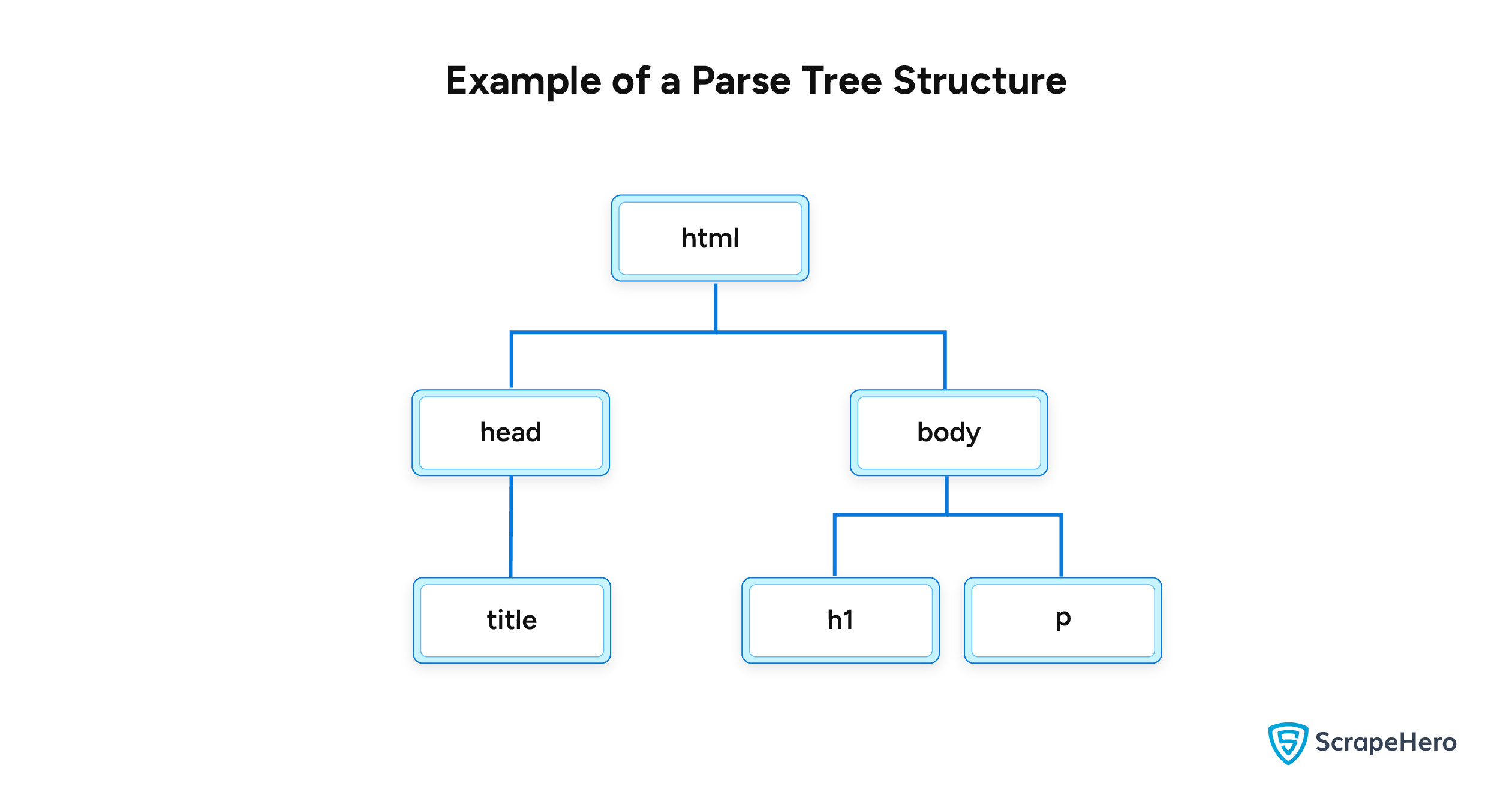
BeautifulSoup implements this parse tree using a BeautifulSoup object.
Understanding a BeautifulSoup Object
A BeautifulSoup object wraps around the parse tree supplied by the external parser. This object allows you to use Pythonic methods to navigate the parse trees. For instance, if ‘soup’ is the BeautifulSoup object, soup.h1.text is the first h1 tag.
There are three main kinds of BeautifulSoup objects:
- Tag: This object corresponds to an HTML tag. It has methods to get its various attributes, like href, id, etc.
- NavigableString: This object holds the string within an element’s opening and closing tag.
- BeautifulSoup: This object represents the entire HTML document and contains methods to extract tags and strings.
Let’s understand the objects by parsing this poorly structured HTML code.
html_doc = """<html> <head><title>BeautifulSop</title></head> <body><h1>Advantages of BeautifulSop</h1> <li>Intuitive methods for navigating HTML source code</li> <li>Can use any parser</li> </ul> </p> </body> </html> """
Now, parse this using the following code snippet.
soup = BeautifulSoup(html_doc,'lxml')The variable soup is a BeautifulSoup object. You can check its type using Python’s type method.
type(soup)
#Output: bs4.BeautifulSOupBeautifulSoup makes the code structured. You can use the prettify() method to look at this structure.
print(soup.prettify()) # Output: # # <html> # <head> # <title> # BeautifulSop # </title> # </head> # <body> # <h1> # Advantages of BeautifulSop # </h1> # <li> # Intuitive methods for navigating HTML source code # </li> # <li> # Can use any parser # </li> # </body> # </html>
You can directly get a tag by saying its name if you don’t need to specify attributes. Let’s get the title tag.
title = soup.title print(title) #Output: <title>BeautifulSop</title>
This is a Tag object.
type(title) #Output: bs4.element.Tag
Finally, let’s get the title string, which is a Navigable String.
titleString = title.string print(titleString) #Output: BeautifulSop type(titleString) #Output: bs4.element.NavigableString
Now that you know what BeautifulSoup does, learn more about scraping pages with Python in the article “Web Scraping with BeautifulSoup.”
Why Use ScrapeHero Web Scraping Service?
Understanding the inner workings of BeautifulSoup can solidify your understanding of scraping. You will be able to resolve bugs more efficiently.
However, if you want to scrape large amounts of data, you should use a web scraping service like ScrapeHero.
ScrapeHero is a fully managed web scraping service provider capable of building high-quality custom web scrapers and crawlers. Tell us your data requirements, and our experts at ScrapeHero will manage every aspect of web scraping to deliver the data you need.
FAQs about BeautifulSoup
You can install BeautifulSoup using Python’s package manager pip. Just run this command: pip install beautifulsoup4.
Yes, BeautifulSoup can handle malformed HTML. It attempts to fix common issues in the HTML code to create a navigable parse tree and provides methods to navigate the three easily.
While BeautifulSoup is excellent for smaller projects and quick data extraction tasks, consider using it in conjunction with web scraping frameworks for large-scale projects.
The primary limitation of BeautifulSoup is that it can’t work alone; BeautifulSoup needs another parser to work. This also means that BeautifulSoup web scraping is slow because it adds an extra layer after parsing.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data



