

Swiggy dish listings largely depend on location. To set the location, you need to either reverse-engineer their API or use a headless browser. This article chooses the second method to scrape Swiggy data.
However, if you don’t want to write code yourself, you can use ScrapeHero’s Q-commerce data scraping service.
Otherwise, read on.
This article explains how to scrape Swiggy data using Selenium—a headless browser.

How Do You Set Up the Environment to Scrape Swiggy?
You can set up the environment to scrape Swiggy by simply installing Selenium using PIP.
pip install selenium
Although you need the sleep and json modules, they come pre-installed with Python.
What Data Can You Scrape from Swiggy?
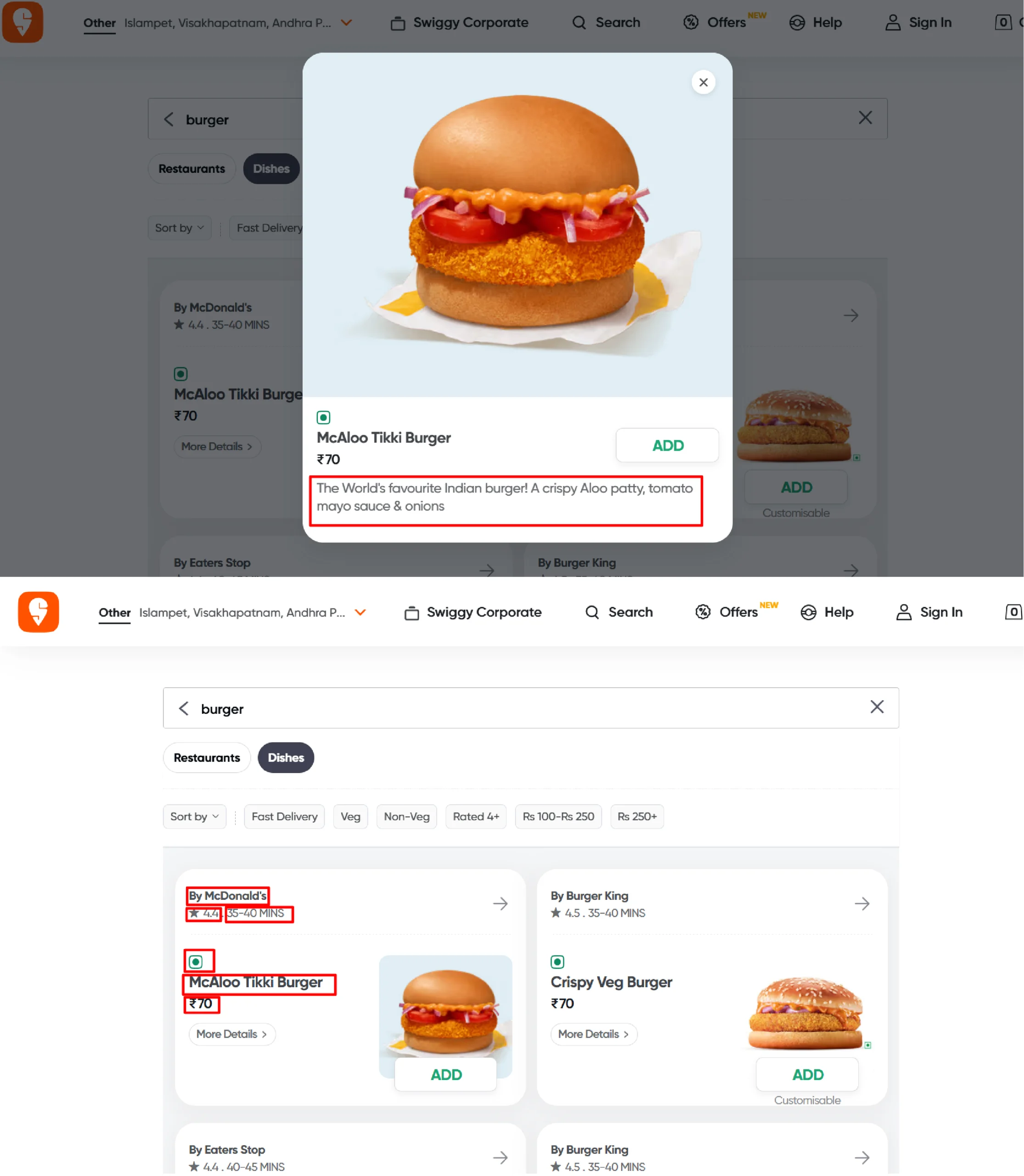
From the Swiggy search results page, you can scrape these data points:
- Dish Name
- Restaurant Name
- Restaurant Rating
- Delivery Time
- Category
- Description
- Price
How to Write the Code for a Swiggy Scraper?
You can write the code for a Swiggy scraper by following these steps:
- Import necessary modules and classes
- Navigate to Swiggy’s search results page
- Set the location
- Extract the details from the listings
- Save the details in a JSON file
Importing Modules and Classes
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from time import sleep
import json
Here,
- webdriver allows you to control the browser.
- By helps you locate HTML elements using various selectors, including CSS, XPath, and other methods.
- Keys can help you simulate a keyboard key press, such as pressing the “End” key.
- json enables you to save the scraped data in a JSON file.
- sleep allows you to add delays, giving enough time for the website to load elements.
How Do You Navigate to Swiggy’s Search Results Page?
To navigate to Swiggy’s search results page, you need to get its URL. Visit Swiggy.com and search for a dish. Then, copy the URL from the address bar.
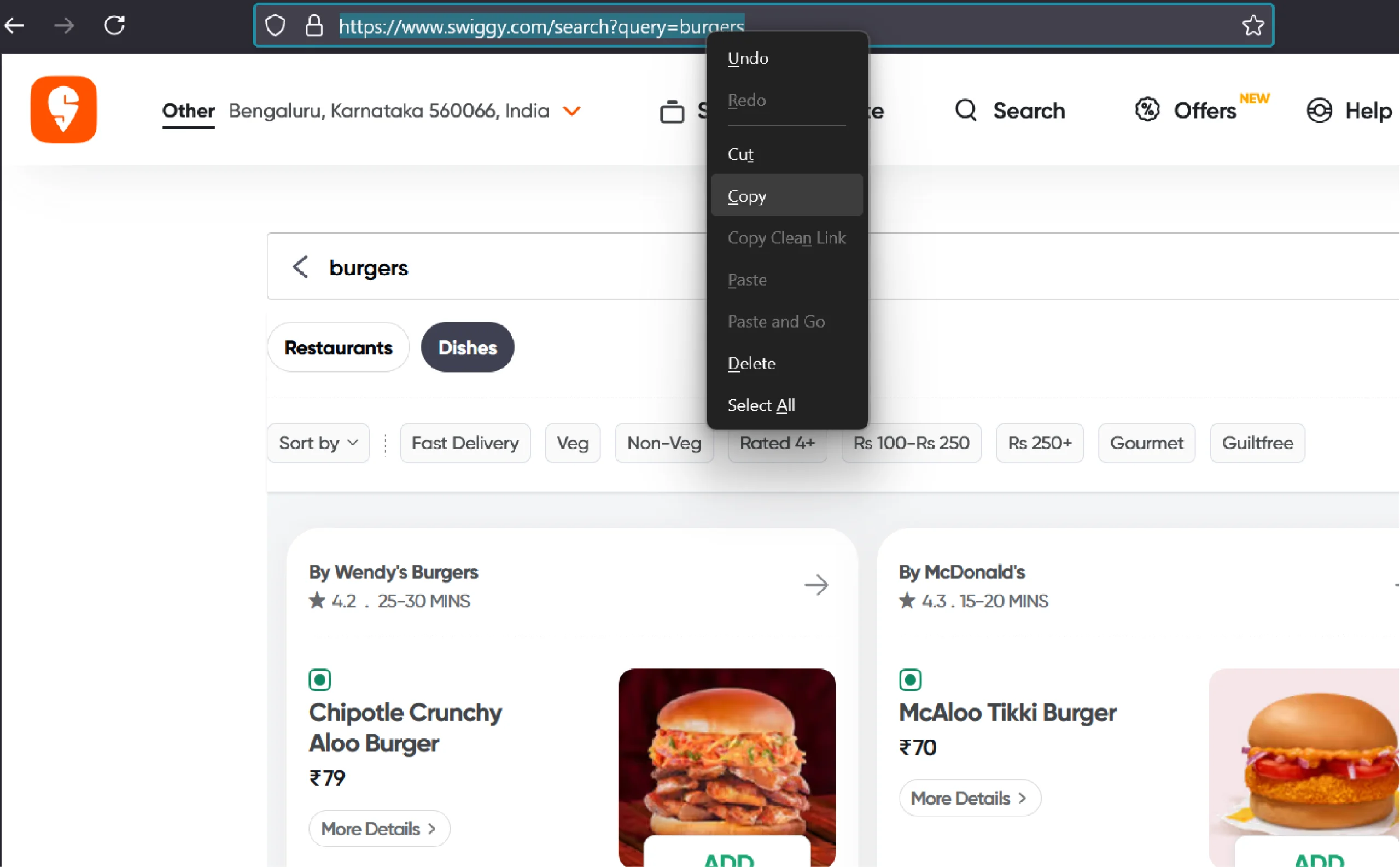
Next, launch the Selenium browser using the webdriver method.
browser = webdriver.Chrome()
Then, use get() with the search results page’s URL—with the search term of your choice—for navigation.
search_term = "burgers"
browser.get(f'https://www.swiggy.com/search?query={search_term}')
How Do You Set the Location on Swiggy.com with Selenium?
You can set the location by entering a location term or PIN in the location input. For instance, if you want to check hotels in Bangalore, you can use “560003.”
location = "560003"
First, you need to click on the location selector button. To do so, inspect the button and build its XPath.
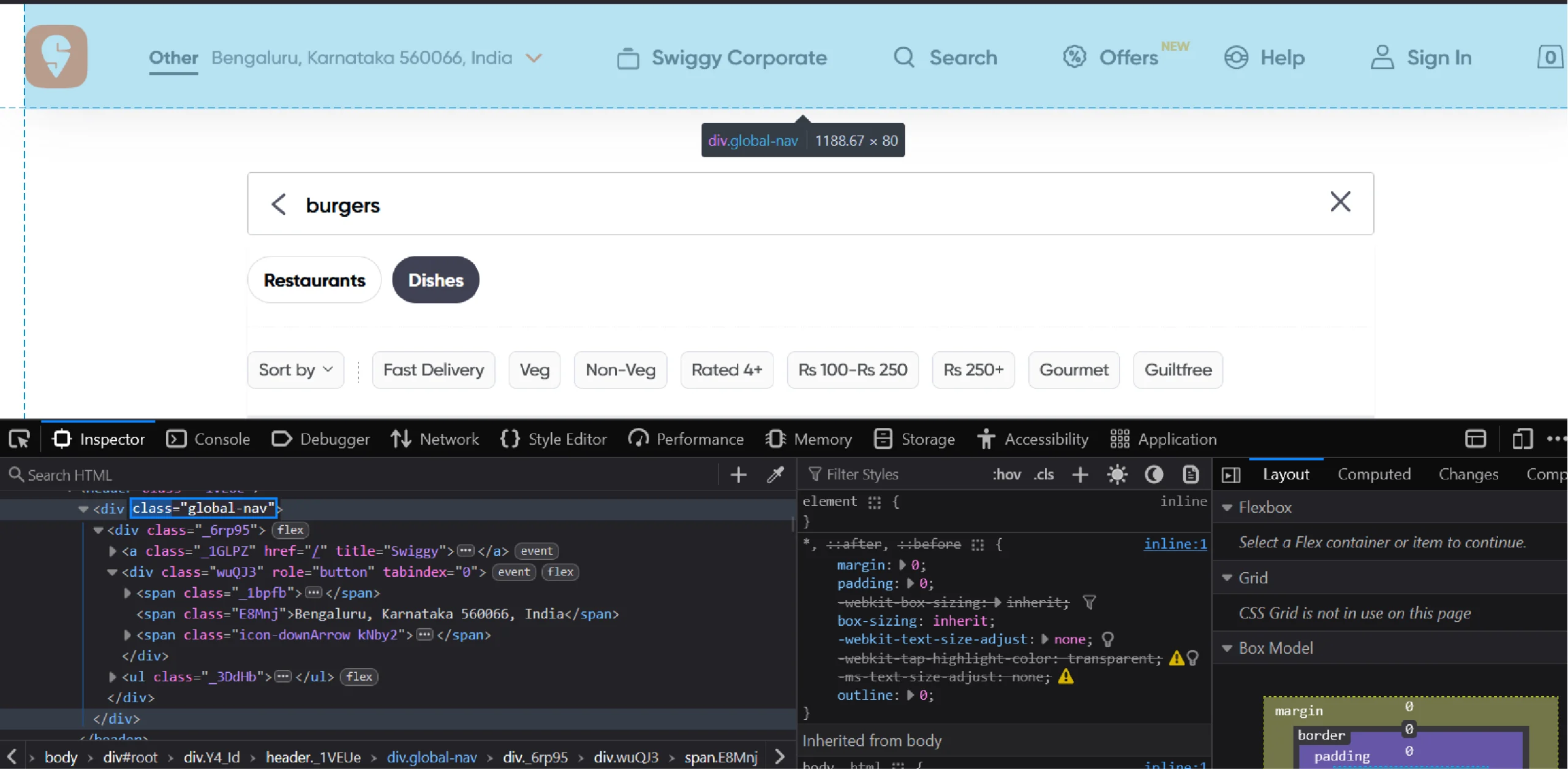
Inspecting the button shows that it is a div element with the role “button” inside another div element that has the class “global-nav.” Therefore, the XPath will be “//div[@class=”global-nav”]//div[@role=”button”]”.
Use find_element() with this XPath to select the button. Then, click on the button using click().
location_button = browser.find_element(By.XPATH,'//div[@class="global-nav"]//div[@role="button"]')
location_button.click()
sleep(3)
Clicking the button provides access to an input box where you can enter the location. This input box has a placeholder that contains the text “Search for area.” 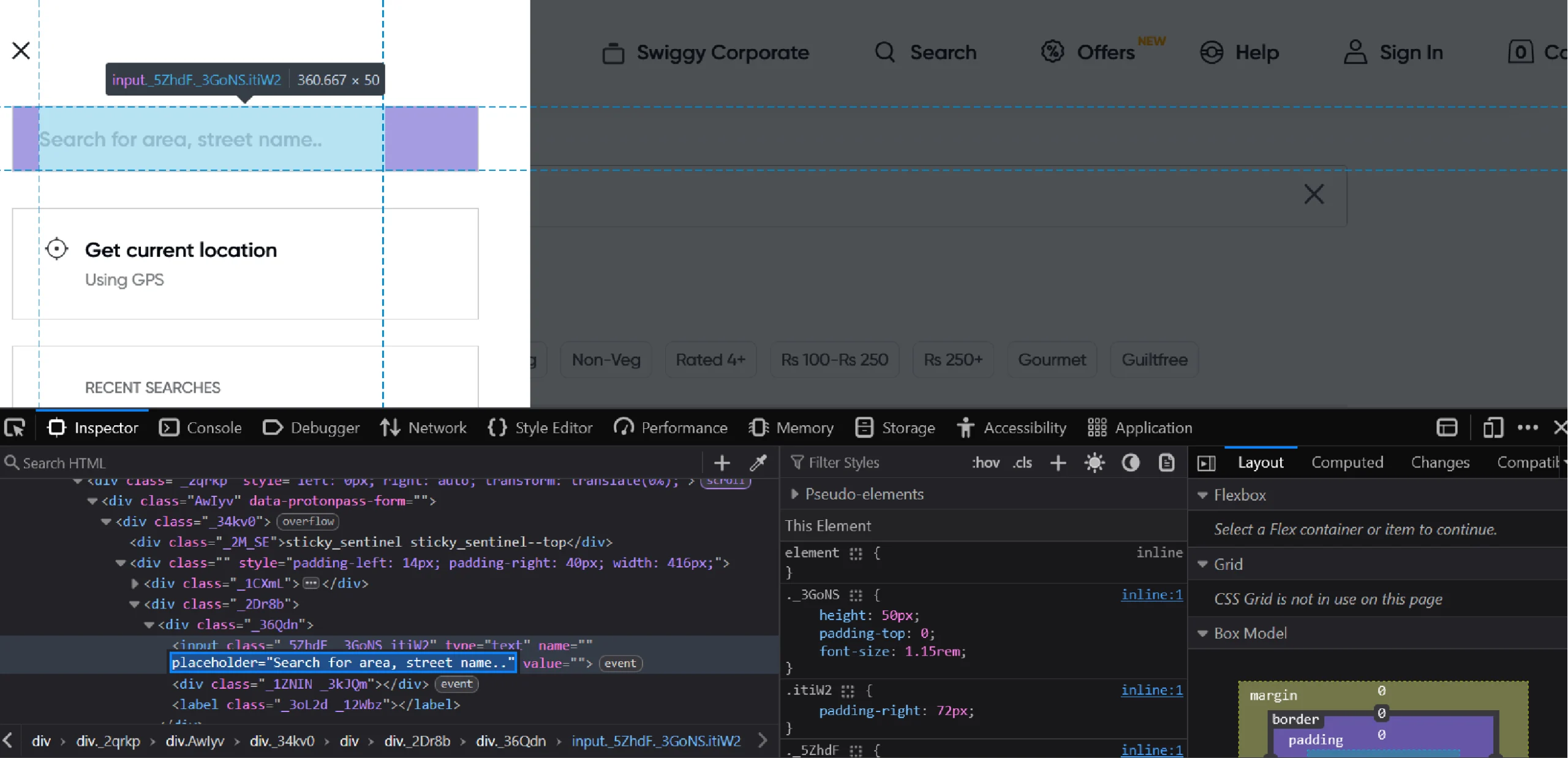
That means you can use the XPath “//input[contains(@placeholder,”Search for area”)]” to select it.
location_input = browser.find_element(By.XPATH,'//input[contains(@placeholder,"Search for area")]')
Then, use send_keys() to enter the term.
location_input.send_keys(location)
sleep(3)Entering the term will list a bunch of locations. As before,
- Inspect the element you want to click
- Build its XPath
- Use find_element() to select it
- Use click() to click on it
location_item = browser.find_element(By.XPATH,'//div[contains(@class,"icon-location")]')
location_item.click()
sleep(3)
Although the above process sets the location, the search results won’t correspond to that location, which means you need to reload the search results.
Simply use send_keys() and simulate the “Enter” key on an input element that has the value of your search term. Then, wait for three seconds.
browser.find_element(By.XPATH,f"//input[@value='{search_term}']").send_keys(Keys.ENTER)
sleep(3)After the results load, you need to extract them.
How Do You Extract Elements from Swiggy Search Results?
To extract the elements on the Swiggy search results page:
- Inspect one of them
- Extract its data-testid
- Build an XPath to target the element
- Use find_elements() with the XPath as an argument
dishes = browser.find_elements(By.XPATH, '//div[@data-testid="search-pl-dish-first-v2-card"]')
The find_elements() method gives a list of elements that fit the XPath’s criteria. So iterate through them and extract the product details from their text content.
Start by defining an empty array to store the details.
dish_details = []
Then, iterate through the list returned by find_elements(). In each iteration:
- Extract the text content and split the string at newline characters
- Use the correct indices to separate product details
- Store them in a dictionary
- Append the dictionary to the array defined earlier
for item in dishes:
details = item.text.split('\n')
food_info = details[3].split('.')
try:
dish_details.append(
{
'Name':details[4],
'Restaurant': details[0].replace('By ',''),
'Rating':details[1],
'Delivery Time':details[2],
'Category': food_info[0],
'Description': food_info[2].split('Description:')[1].split('Swipe right')[0],
'Price': details[5],
}
)
except:
continue
Finally, you can save the dictionary in a JSON file using the json.dump() method.
with open('swiggy_dishes.json','w') as f:
json.dump(dish_details,f,indent=4,ensure_ascii=False)This code saves the data in ‘swiggy_dishes.json’.
The results of Swiggy data extraction will look like this:
{
"Name": "Crispy Chicken Burger",
"Restaurant": "Burger King",
"Rating": "4.6",
"Delivery Time": "45-50 MINS",
"Category": "Non-veg item",
"Description": " Crispy Chicken Patty, Onion & Our Signature Tomato Herby Sauce",
"Price": "99"
}
And here’s the complete code to scrape Swiggy data.
#import packages
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from time import sleep
import json
#launch selenium browser
browser = webdriver.Chrome()
search_term = "burgers"
browser.get(f'https://www.swiggy.com/search?query={search_term}')
#set the location
location_button = browser.find_element(By.XPATH,'//div[@class="global-nav"]//div[@role="button"]')
location_button.click()
sleep(3)
location_input = browser.find_element(By.XPATH,'//input[contains(@placeholder,"Search for area")]')
location = "679121"
location_input.send_keys(location)
sleep(3)
location_item = browser.find_element(By.XPATH,'//div[contains(@class,"icon-location")]')
location_item.click()
sleep(3)
# reload search results
browser.find_element(By.XPATH,f"//input[@value='{search_term}']").send_keys(Keys.ENTER)
sleep(3)
#extract dishes
dishes = browser.find_elements(By.XPATH, '//div[@data-testid="search-pl-dish-first-v2-card"]')
dish_details = []
for item in dishes:
details = item.text.split('\n')
food_info = details[3].split('.')
try:
dish_details.append(
{
'Name':details[4],
'Restaurant': details[0].replace('By ',''),
'Rating':details[1],
'Delivery Time':details[2],
'Category': food_info[0],
'Description': food_info[2].split('Description:')[1].split('Swipe right')[0],
'Price': details[5],
}
)
except:
continue
#save the dishes
with open('swiggy_dishes.json','w') as f:
json.dump(dish_details,f,indent=4,ensure_ascii=False)
What Are the Limitations of This Code to Extract Swiggy Data?
The above code can manage Swiggy web scraping, but it’s not without a couple of limitations:
- The code uses XPaths to extract elements, which depend on the HTML structure. If that changes, the code may break.
- This code doesn’t use any techniques to bypass anti-scraping measures, which makes it unsuitable for large-scale projects.
Why Should You Use a Web Scraping Service?
The Swiggy code shown in this tutorial can work for small-scale scraping projects, but its limitations make it unsuitable for large-scale operations. Moreover, you need to constantly monitor Swiggy’s website for changes in its HTML structure to avoid collecting garbage data as a result of a structure change.
To avoid all this, use a web scraping service.
A web scraping service like ScrapeHero can help you scrape data on a large scale, taking care of anti-scraping measures and website structure changes, which frees up your time and money.
ScrapeHero is an enterprise-grade web scraping service provider capable of building high-quality scrapers and crawlers. Besides data extraction, we can also take care of your entire data pipeline, including building custom RPA and AI models.



