

If you want to monitor products on Kroger.com but aren’t sure how, this article is for you. Learn both no-code and code-based methods to scrape Kroger.com.
For the no-code method, this article uses ScrapeHero Cloud’s Kroger Product Reviews and Ratings Scraper. This is a cloud-based tool that enables you to get product reviews and ratings by simply providing product URLs or IDs as input.
The code-based method uses Playwright and requests to fetch product details and reviews by accessing URLs stored in a file.

How Do You Scrape Kroger.com Using The No-Code Method?
To scrape Kroger.com using the no-code method, use ScrapeHero Cloud’s Kroger Product Review and Rating Scraper. This no-code scraper allows you to get ratings and reviews from Kroger.com within a few steps.
1. Log in to Your ScrapeHero Cloud Account
Begin by logging into your ScrapeHero Cloud account. If you don’t have an account, create one on their website.

2. Navigate to the Kroger Product Reviews Scraper App
Go to the ScrapeHero App Store and locate the Kroger Product Reviews Scraper App.
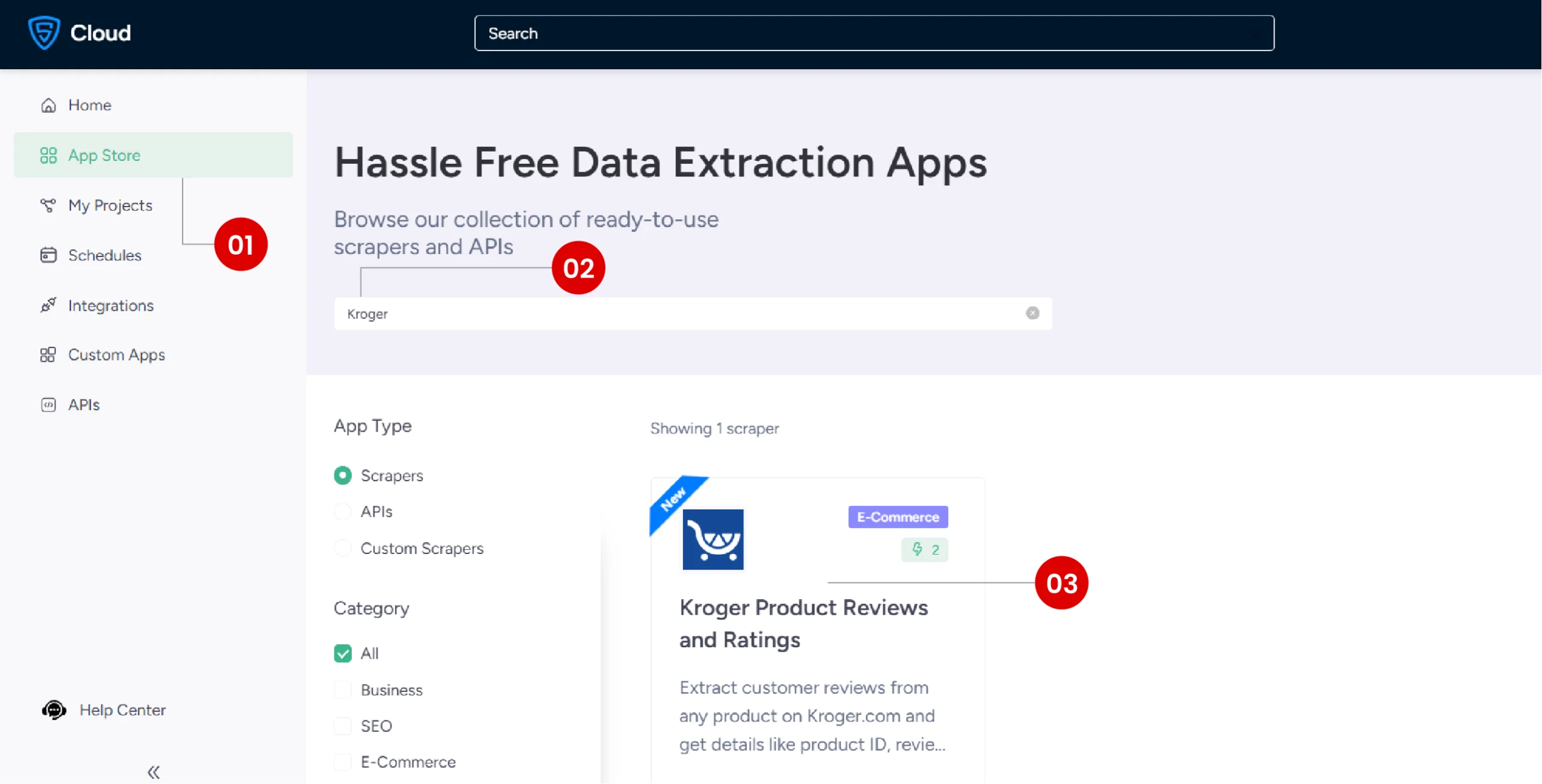
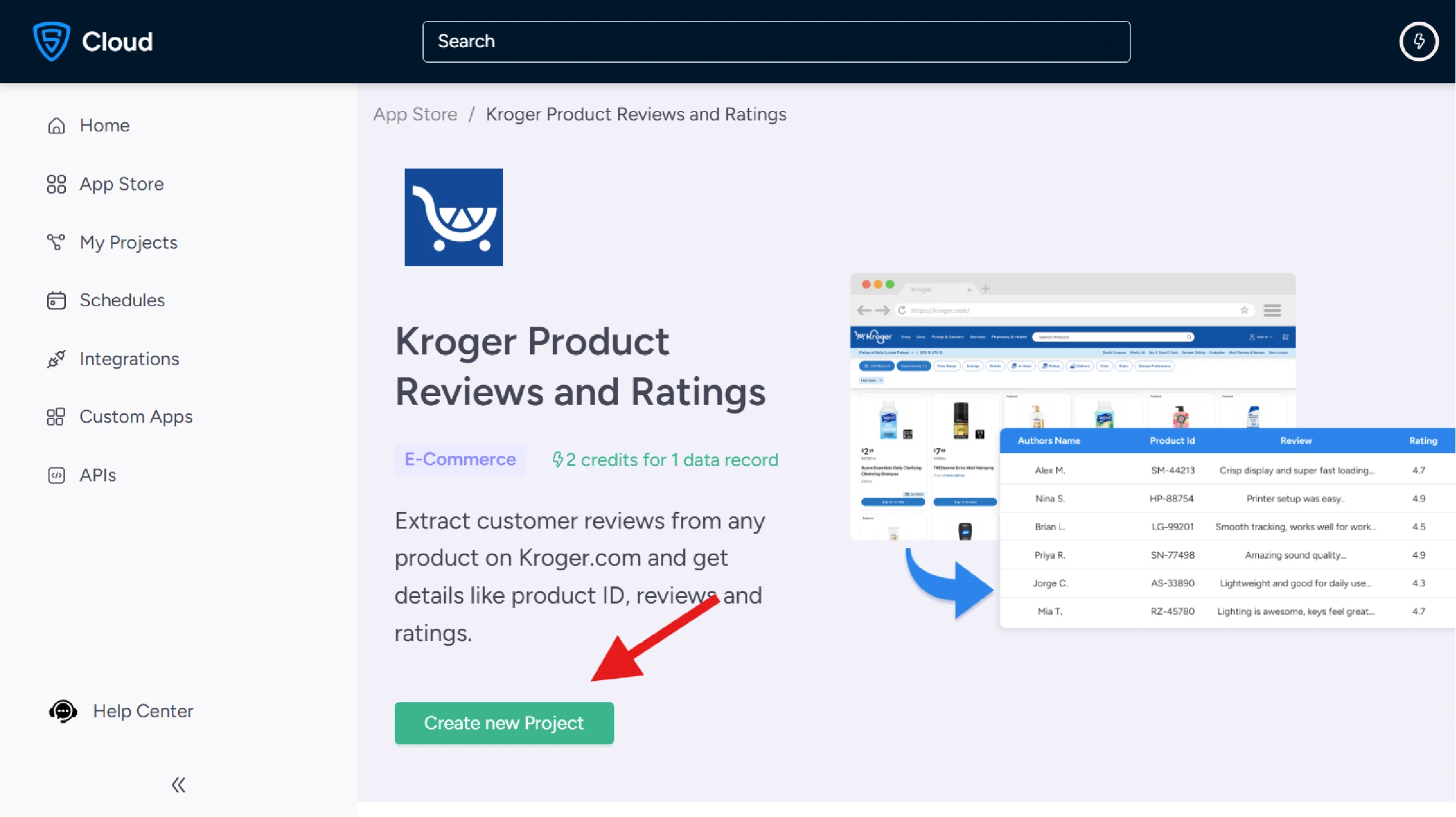
3. Create a New Project
Click on “Create New Project” to start a new scraping session.
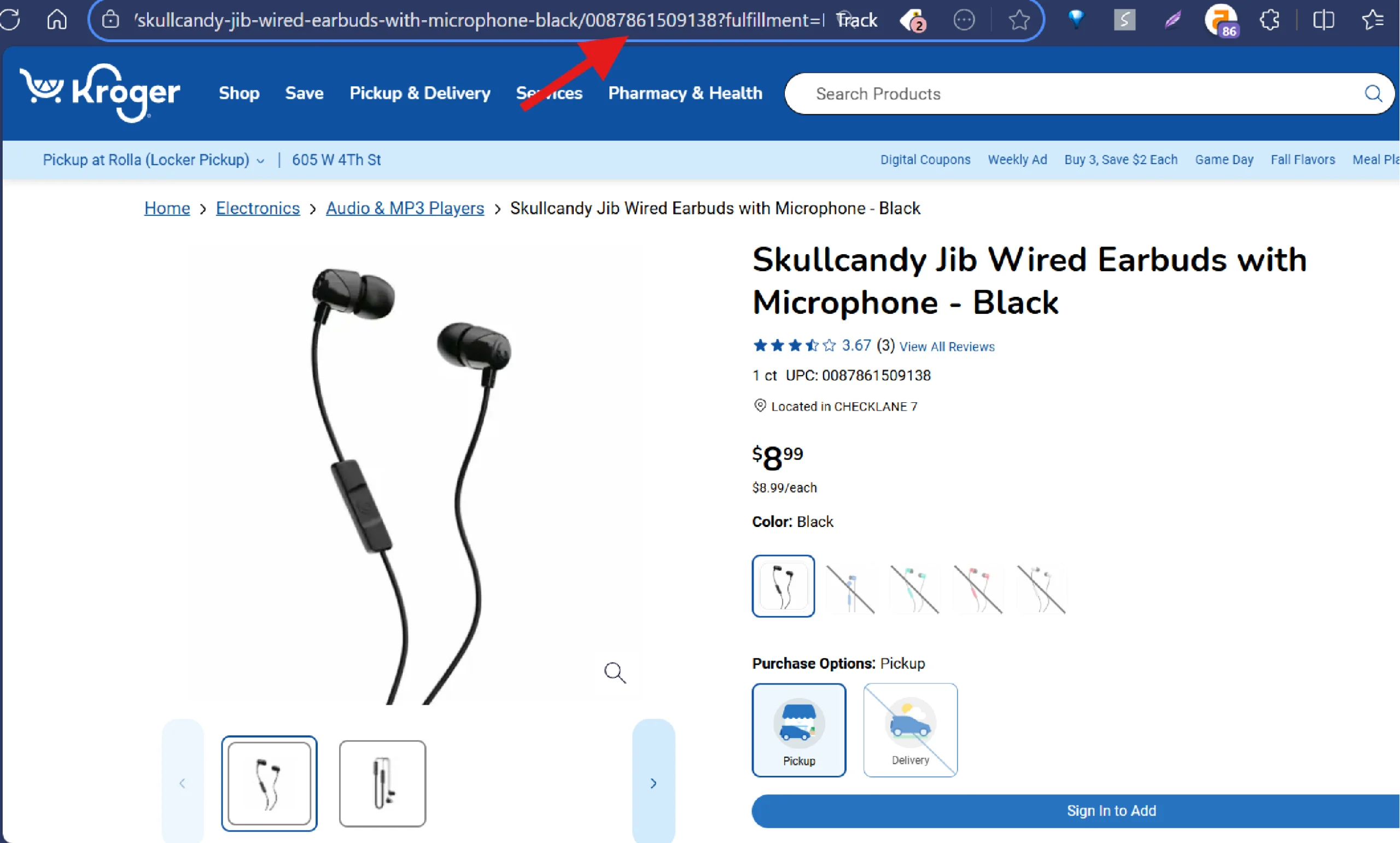
4. Copy the Product URL or Product ID
Visit the product listing page on Kroger.com and copy the URL or product ID from the address bar. Paste this information into the “Product URLs/Product ID” field in the scraper.
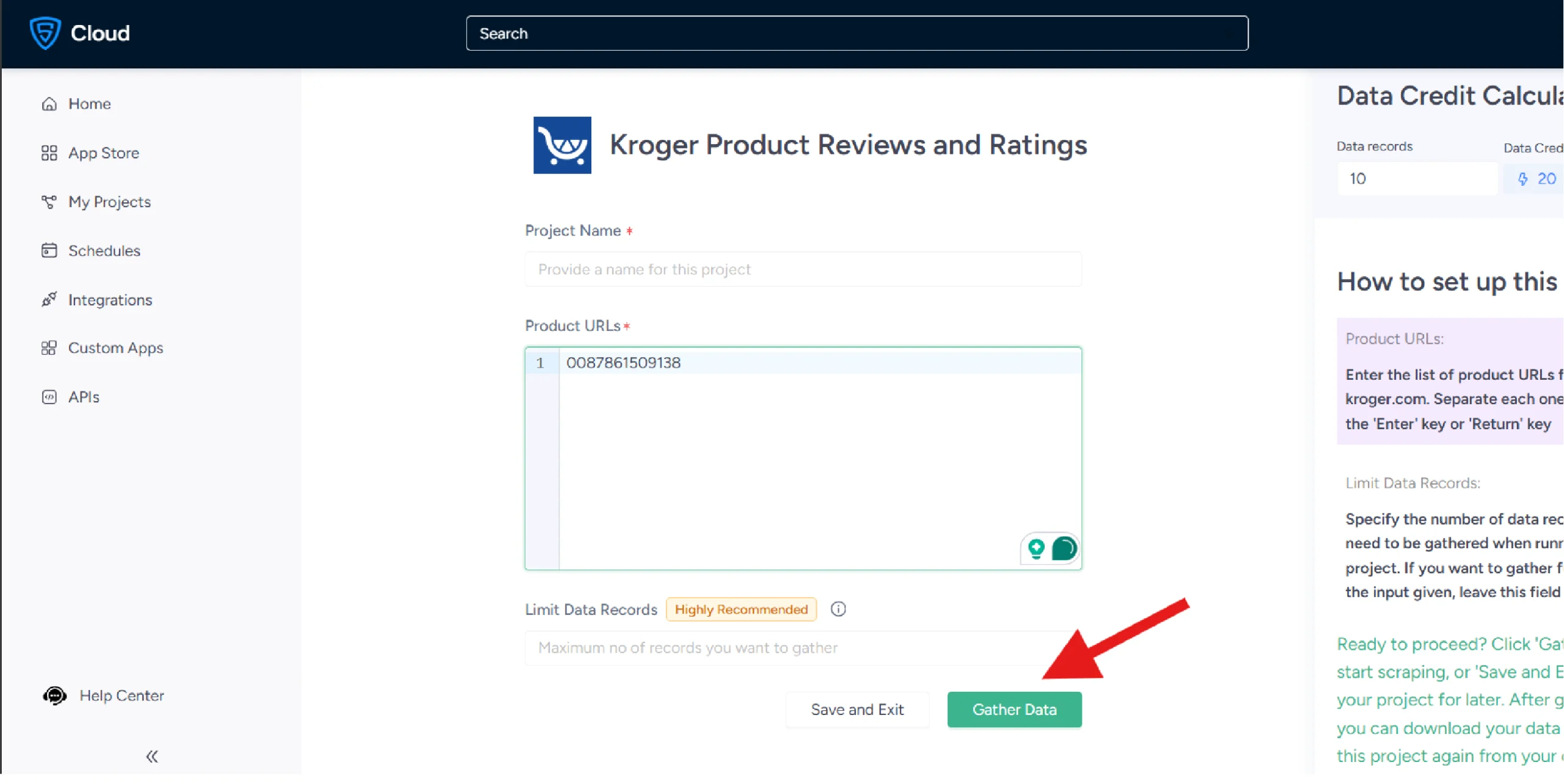
5. Start the Data Extraction Process
Click “Gather Data” to begin the scraping process. The tool will extract the required data from the product page.
6. Download Your Data
After the scraping is complete, you can download the data in your preferred format (CSV, JSON, or Excel).
This no-code method is straightforward and user-friendly, making it an excellent choice for those who want quick results without technical expertise.
Besides letting you easily get product reviews and ratings from Kroger.com, ScrapeHero Cloud’s premium plan allows you to
- Schedule the scraping sessions
- Get the data directly delivered to your preferred cloud storage
- Use the scraper’s API to integrate with your workflow
Next, let’s explore the code-based method. This tutorial shows how to use Python to scrape data from Kroger.com.
How Do You Start Scraping Kroger.com with Python?
Scraping Kroger.com using Python involves examining the HTML structure of the site to identify the selectors for the data points you want to extract. First, you need to set up your environment.
How Do You Set Up the Environment to Scrape Kroger?
Setting up the environment means installing the necessary packages. To run the code shown in this tutorial, you need to install:
- Playwright
- requests
You can install both of them using pip:
pip install requests playwright
Additionally, you need to install the playwright browser.
playwright installHow Do You Write the Code for Kroger Data Scraping?
To write the code, first, determine what your Kroger scraper needs to do.
For instance, this code
- Reads product URLs from a URLs.txt file
- Extracts product details using Playwright
- Extracts reviews using the requests from Kroger’s API
- Saves the data in a JSON file
That means you need to import,
- Playwright API
- requests library
- json
In addition to these, you also need the datetime module to handle timestamps.
from playwright.sync_api import sync_playwright
from time import sleep
import json
from datetime import datetime
import json
How Do You Read Kroger Product URLs from a File?
You can create a function read_urls() to read Krger product URLs from File.
def read_urls():
with open('urls.txt') as f:
urls = f.read().split('\n')
return urls
This function
- Reads the file urls.txt
- Splits the text returned at every newline character
- Returns the list returned by split()
For example, if urls.txt contains:
https://www.kroger.com/p/product/0001111041700
https://www.kroger.com/p/product/0001111085456
The function would return the list:
['https://www.kroger.com/p/product/0001111041700', 'https://www.kroger.com/p/product/0001111085456']
How do You Extract Kroger Reviews?
Write a function extract_reviews() to extract product reviews from Kroger.com. This function takes a product ID and returns a list of dicts containing reviews.
extract_reviews() makes an HTTP request to Kroger’s reviews API directly to get reviews. Get this API endpoint from the network tab of your browser’s DevTools.
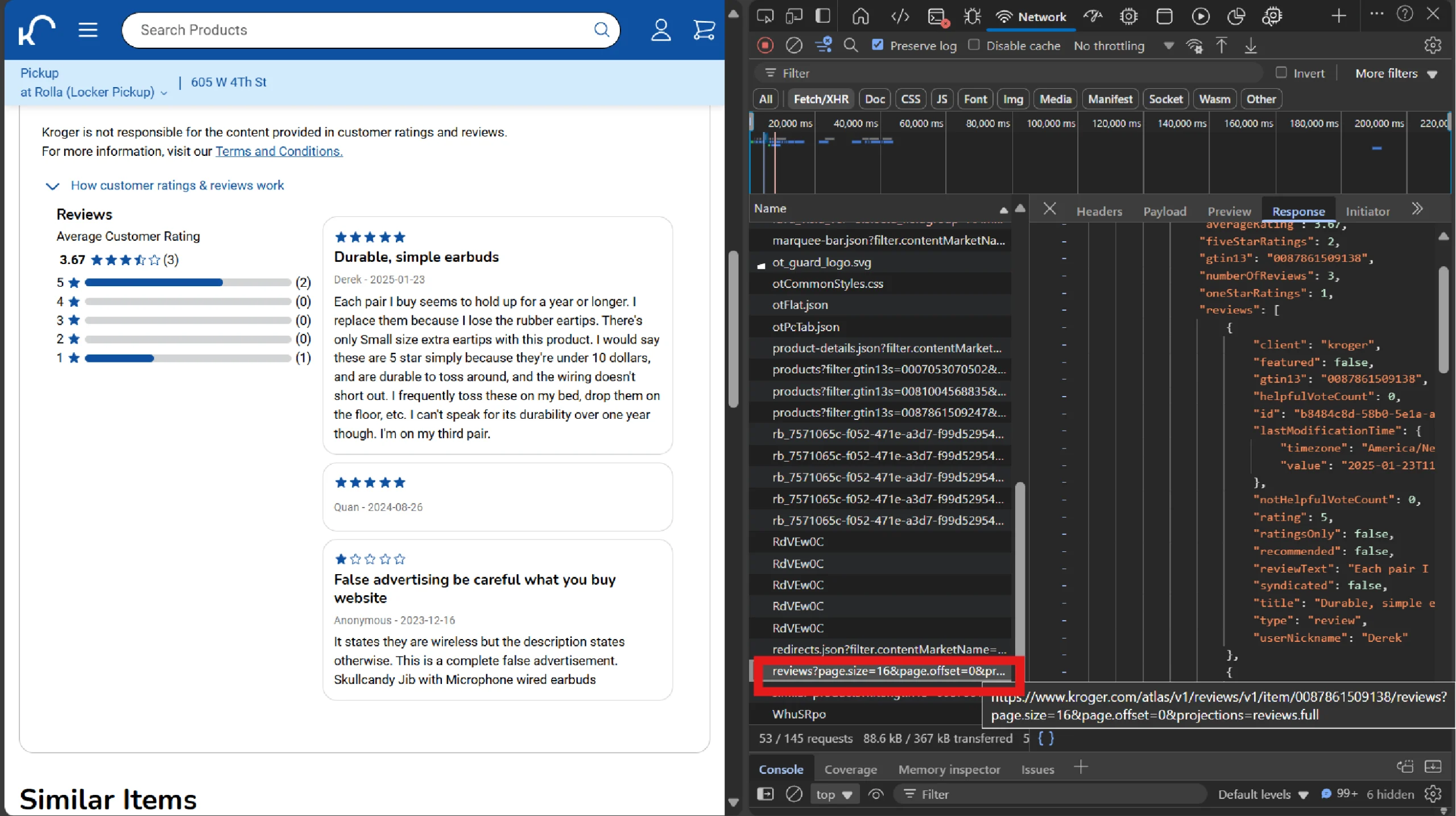
Once you find the API, set up the headers and use Python requests to make the request.
The request returns JSON data; extract the required details, such as review title, author, review text, and so on.
How Do You Extract Product Details?
With a list of URLs, you can now write a function extract_product_details() to visit each page and extract the relevant information.
This function takes a URL as input, uses Playwright to scrape data, such as the product’s name, price, rating, and URL, and returns a dictionary containing the data.
It starts by launching the Playwright browser:
def extract_product_details(url):
with sync_playwright() as p:
browser = p.chromium.launch()
page = browser.new_page()
page.goto(url)
Websites sometimes block scrapers, displaying an “Access Denied” message.
Therefore, the code performs a simple check for this. If the message is found, the script reloads the page, which can sometimes bypass anti-scraping measures.
if "Access Denied" in page.text_content('body'):
sleep(1)
page.reload()
Next, initialize an empty dictionary data to hold the scraped information.
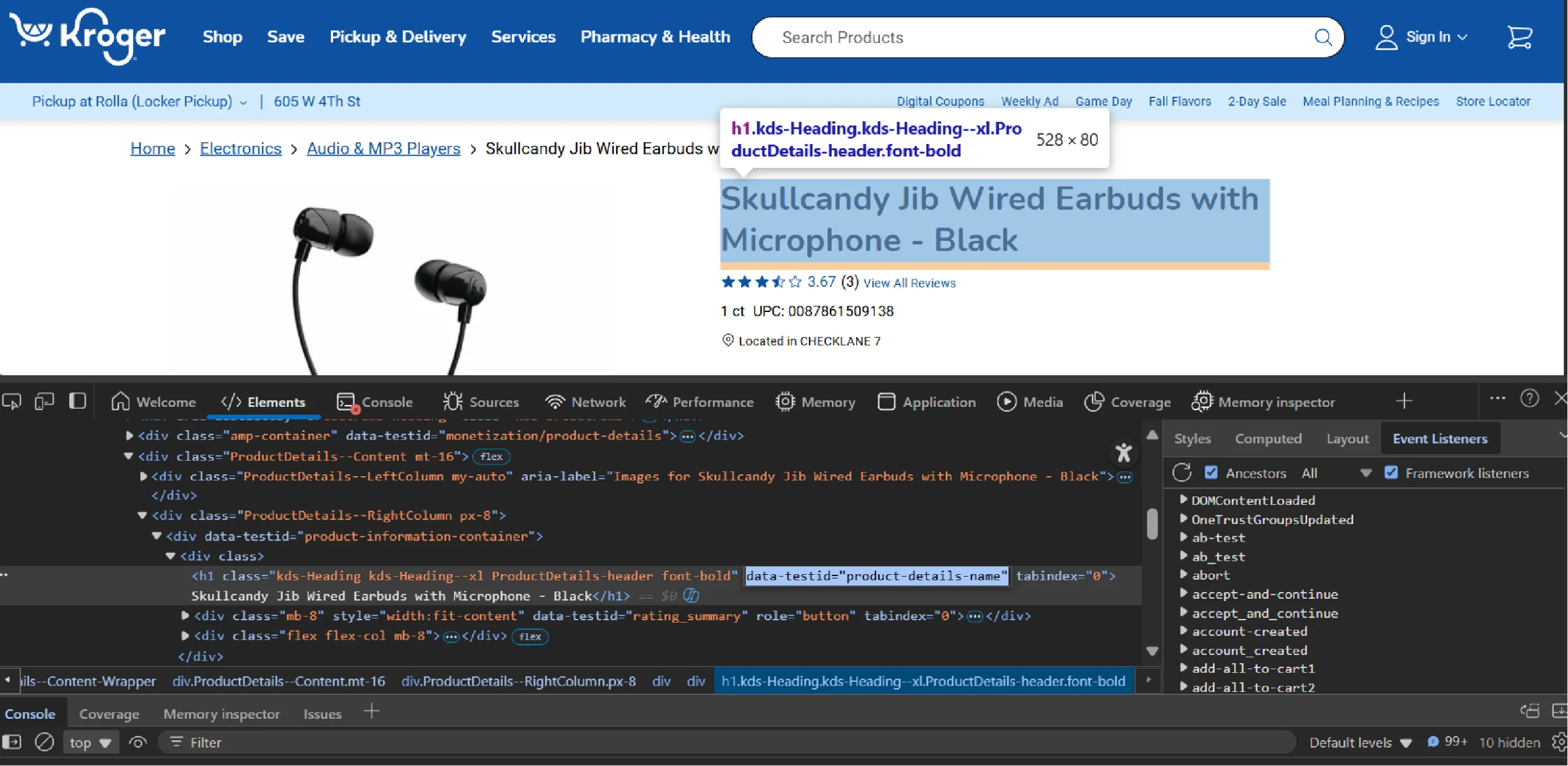
Then extract the product name using its specific data-testid attribute, which is a reliable way to target elements.
data['Name'] = page.query_selector('h1[data-testid="product-details-name"]').text_content()
Not all products have a rating. To prevent our script from crashing if a rating is not found, the code wraps the extraction logic in a try-except block. If the rating element exists, we extract its text; otherwise, we assign “NA”.
try:
data['Average Rating'] = page.query_selector('span[aria-label*="average rating"]').text_content()
except:
data['Average Rating'] = "NA"
Similarly, extract the price. The price is stored in a value attribute of a <data> tag. Use an XPath selector to find this element and get its attribute.
This code is also within a try-except block in case the price isn’t available.
try:
data['Price'] = page.locator('//data[@typeof="Price"]').get_attribute('value')
except:
data['Price'] = "NA"
To extract reviews, the code calls the extract_reviews() function in a try-except block:
try:
product_id = url.split('/')[-1]
data['Reviews'] = extract_reviews(product_id)
except Exception as e:
data['Reviews'] = 'NA'
print(e)The above code splits the URL to get the product ID, which is used as the argument when calling extract_reviews().
Finally, add the product’s URL to the dictionary, close the browser to free up resources, and return the data dictionary.
data['URL'] = url
return data
You can now tie everything up by calling the above functions. First, read_urls() to get the URLs from urls.txt as a list.
urls = read_urls()
Then, iterate through the list and in each iteration, call extract_product_details() for each URL.
product_details = []
for url in urls:
if len(product_details) >= 5:
break
try:
details = extract_product_details(url)
if details.get('Reviews') != []:
product_details.append(details)
else:
continue
except Exception as e:
print(f"Failed to process {url}: {e}")
Note: This code uses if-blocks to limit the number of products to a maximum of five and saves the data only if product reviews are available.
How Do You Save the Data Extracted from Kroger.com?
Finally, the json.dump() function writes the list of product details into a nicely formatted file named product_details.json.
with open('product_details.json', 'w', encoding='utf-8') as f:
json.dump(product_details, f, indent=4, ensure_ascii=False)Below is a sample of the data that has been extracted.
[
{
"URL": "https://www.kroger.com/p/14-hands-cabernet-sauvignon-washington-red-wine/0008858600189",
"Name": "14 Hands® Cabernet Sauvignon Washington Red Wine",
"Average Rating": "4.7",
"Price": "8.99",
"Reviews": [
{
"rating": 5,
"title": "Wise winer",
"userNickname": null,
"timezone": "16-10-2020",
"reviewText": "I had no problems. A little more expensive than the store because of shipping."
},
{
"rating": 3,
"title": "It was Okay",
"userNickname": "Really Dry Cab",
"timezone": "04-08-2020",
"reviewText": "[This review was collected as part of a promotion.] This wine was good, it did end up giving me some serious heart burn though"
}
]
}
]Here’s the complete code for Kroger web scraping.
from playwright.sync_api import sync_playwright
import requests
from datetime import datetime
import json
def extract_reviews(product_id):
headers = {
"accept": "application/json, text/plain, */*",
"device-memory": "8",
"sec-ch-ua": '"Not;A=Brand";v="99", "Microsoft Edge";v="139", "Chromium";v="139"',
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": '"Windows"',
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36 Edg/139.0.0.0",
"x-call-origin": '{"page":"pdp","component":"productDetails"}',
"x-kroger-channel": "WEB",
"x-modality-type": "PICKUP"
}
data = requests.get(f'https://www.kroger.com/atlas/v1/reviews/v1/item/{product_id}/reviews?page.size=16&page.offset=1&projections=reviews.full',headers=headers).json()
reviews = data['data']['reviews']['product']['reviews']
extracted_reviews = [
{
'rating': review['rating'],
'title': review['title'],
'userNickname': review['userNickname'],
'timezone': datetime.strptime(review['lastModificationTime']['value'], "%Y-%m-%dT%H:%M:%S.%fZ").strftime("%d-%m-%Y"),
'reviewText': review['reviewText']
}
for review in reviews
]
if extracted_reviews == []:
extracted_reviews = 'NA'
return extracted_reviews
def extract_product_details(url):
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
context = browser.new_context()
page = context.new_page()
page.goto(url)
if "Access Denied" in page.text_content('body'):
page.reload()
data = {}
data['URL'] = url
data['Name'] = page.query_selector('h1[data-testid="product-details-name"]').text_content()
try:
data['Average Rating'] = page.query_selector('span[aria-label*="average rating"]').text_content()
except Exception as e:
print(e)
try:
data['Price'] = page.locator('//data[@typeof="Price"]').get_attribute('value')
except:
data['Price'] = "NA"
try:
product_id = url.split('/')[-1]
data['Reviews'] = extract_reviews(product_id)
except Exception as e:
data['Reviews'] = 'NA'
print(e)
return data
def read_urls():
with open('urls.txt') as f:
urls = f.read().split('\n')
return urls
urls = read_urls()
product_details = []
for url in urls:
if len(product_details) >= 5:
break
try:
details = extract_product_details(url)
if details.get('Reviews') != []:
product_details.append(details)
else:
continue
except Exception as e:
print(f"Failed to process {url}: {e}")
with open('product_details.json', 'w', encoding='utf-8') as f:
json.dump(product_details, f, indent=4, ensure_ascii=False)
Are There Any Limitations to this Kroger Scraper?
While the code-based method provides flexibility, it comes with certain limitations:
- Website Changes
Websites like Kroger frequently update their structure, which can break your scraping script. Regular maintenance is necessary to keep the code functional. - Anti-Scraping Measures
Many websites implement anti-scraping mechanisms, such as CAPTCHA, IP blocking, or dynamic content loading. Overcoming these challenges requires additional effort and resources. - Time-Consuming
Writing and debugging a scraping script can be time-intensive, especially for complex websites.
Why Is It Better to Use a Web Scraping Service?
Despite the flexibility of the code-based method, using a web scraping service can save time and effort. Web scraping services like ScrapeHero can handle the complexities of scraping, such as:
- Managing proxies
- Bypassing anti-scraping measures
- Maintaining the scraper when websites change
ScrapeHero is among the top three full-service web scraping service providers. Connect with ScrapeHero to get the data you need. We provide ready-to-use data in various formats, allowing you to focus on analyzing the data rather than extracting it.



