

Scraping dynamic websites can be a complex task, especially when dealing with dynamic content. Websites like Instamart use JavaScript to display location-based products, which makes scraping with request-based methods challenging. However, you can still easily scrape Instamart using browser automation libraries.
These libraries enable you to interact with websites like a regular browser, allowing you to scrape dynamic content.
However, if you don’t want to code yourself, check out ScrapeHero’s q-commerce data scraping service.
Otherwise, keep reading to learn how Instamart web scraping works.
This article explores Swiggy Instamart scraping using Selenium to collect useful product details like name, price, and quantity.

Scrape Instamart: Setting Up The Environment
To set up the environment, you only need to install Selenium for web scraping. Do this using PIP.
pip install seleniumAdditionally, you’ll need
- sleep from Python’s time module to add pauses between interactions
- json for saving your scraped data into a file
But these modules are built into Python, so there’s no need to install them separately.
Data Scraped from Instamart
The code extracts four details from each product on the search results page:
- Name: The product’s name.
- Price: The current price of the product.
- Description: A brief description of the product.
- Quantity: The quantity or size of the product being offered.
These data points are crucial for businesses looking to monitor inventory, pricing strategies, or competitors in the market.
Scrape Instamart: The Code
Begin by importing the necessary libraries to help you interact with the webpage, manage timing, and save your scraped data.
Import Necessary Packages
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import json
from time import sleep
Here,
- The webdriver module from Selenium allows automating the browser
- The By class helps locate elements on the page
- Keys lets you simulate key presses, like hitting the “Enter” key.
- json has methods to save the scraped data.
- sleep can add delays between actions, ensuring the page has enough time to load before we interact with it.
After importing the libraries, launch the Selenium browser using webdriver.Chrome() and navigate to the Instamart webpage using get().
Launch the Selenium Browser
browser = webdriver.Chrome()
browser.get("https://www.swiggy.com/instamart")
sleep(3)
Once the webpage loads, you’ll need to enter a location. To do so,
1. Get the data-testid of the search location button
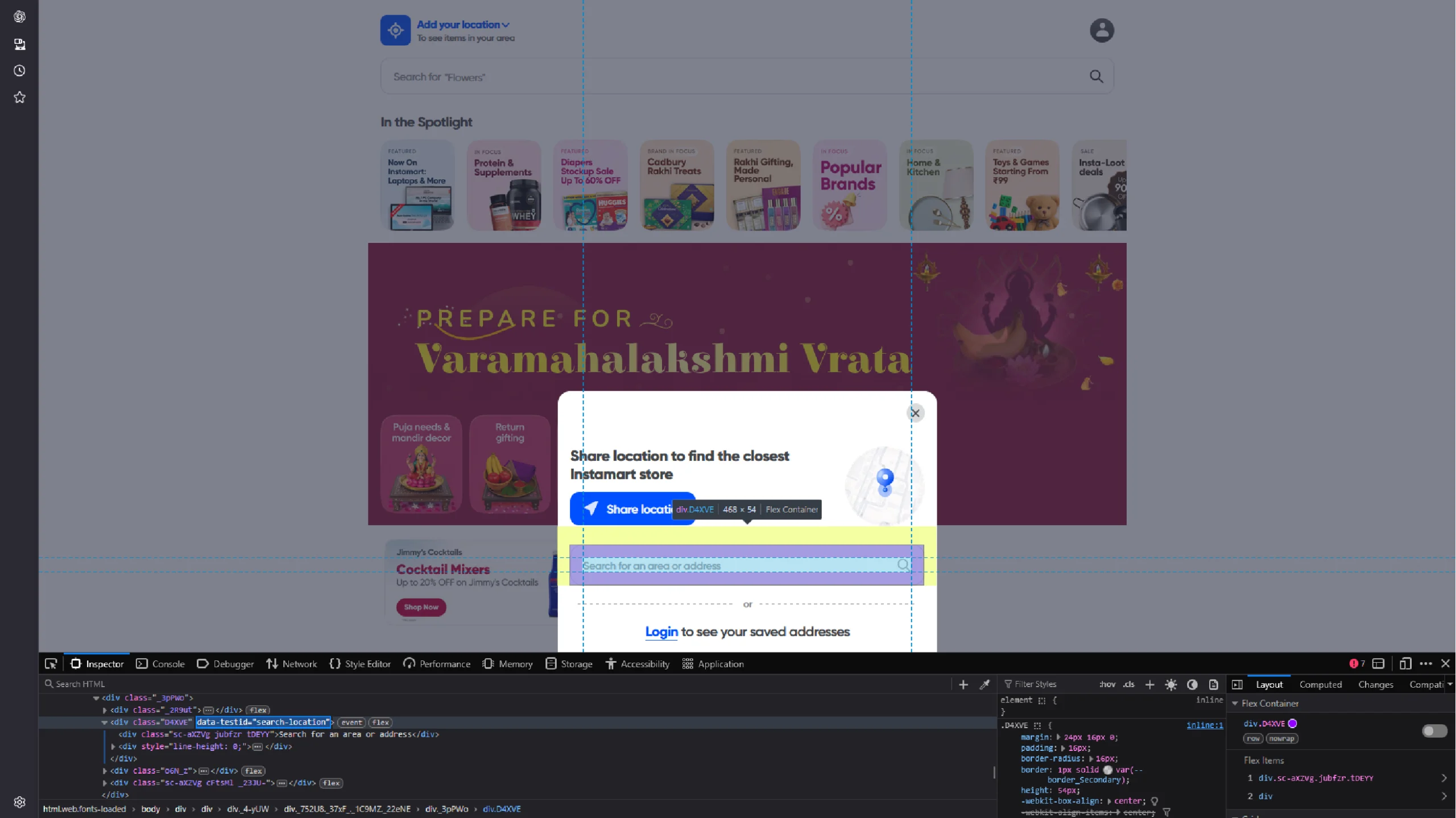
2. Select the button using find_element()
3. Click it using click()
Entering a Location
location_input_div = browser.find_element(By.XPATH, '//div[@data-testid="search-location"]')
location_input_div.click()
sleep(2)
This will open a window with an input box.
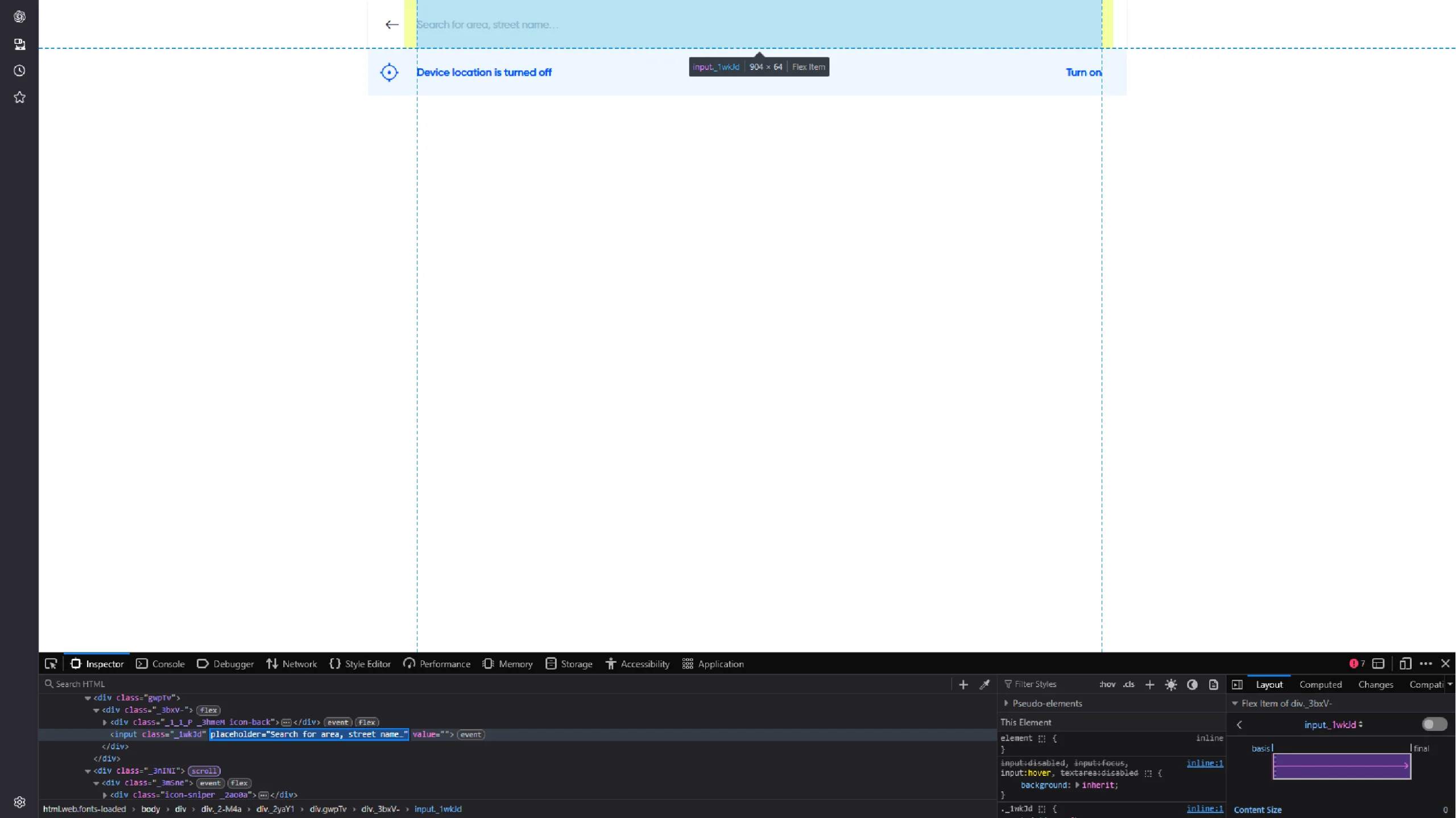
Get its placeholder, select it using find_element(), and use send_keys() to enter a location.
location = “Banglore”
location_input = browser.find_element(By.XPATH, '//input[contains(@placeholder,"Search for area")]')
location_input.send_keys(location)
sleep(2)
Entering the location will list multiple locations.
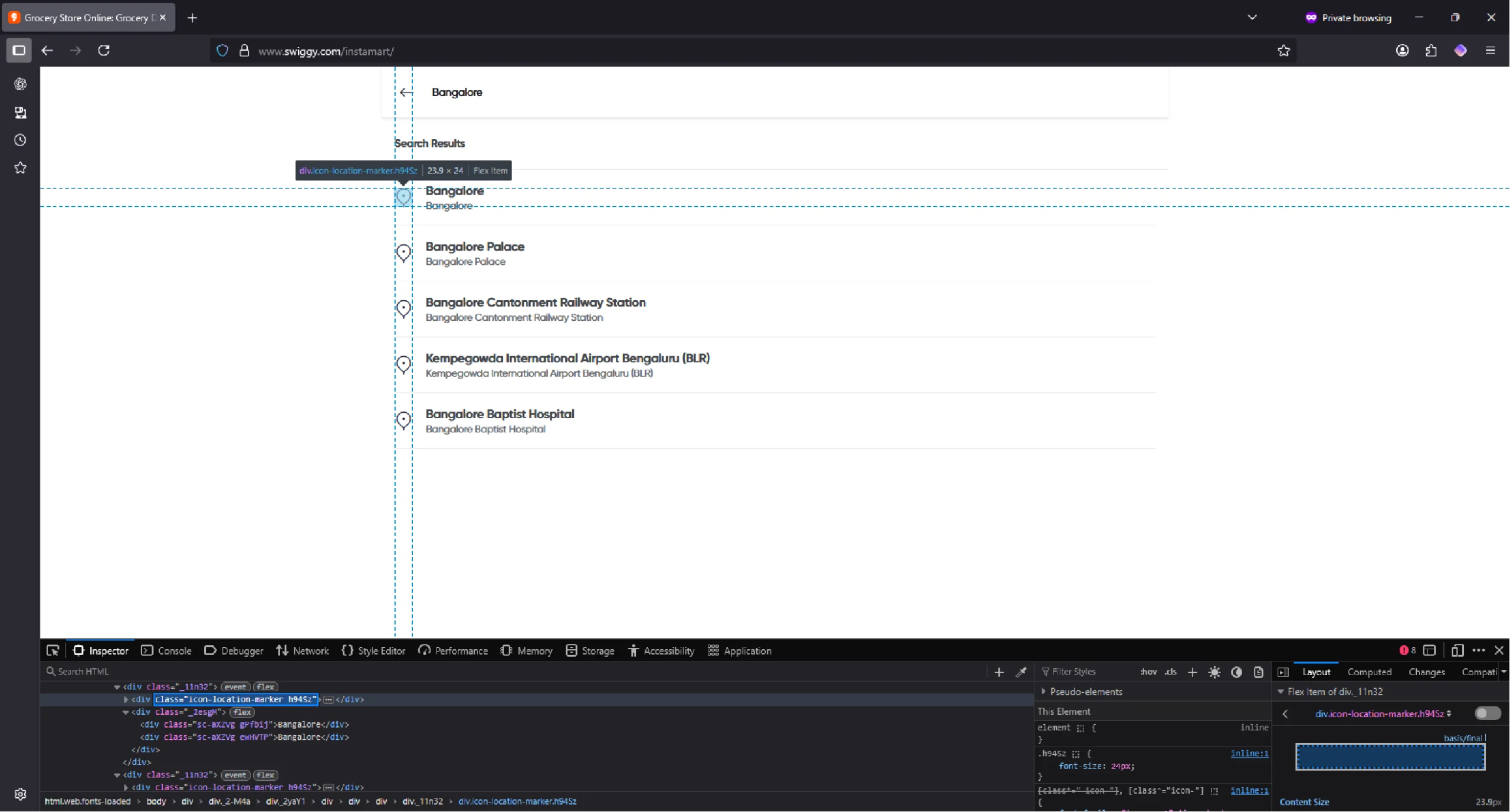
Select the top one by clicking on a div element with the class “icon-location-marker.”
location_div = browser.find_element(By.XPATH, '//div[contains(@class,"icon-location-marker")]')
location_div.click()
sleep(3)
Doing this will open a window containing a confirm button.
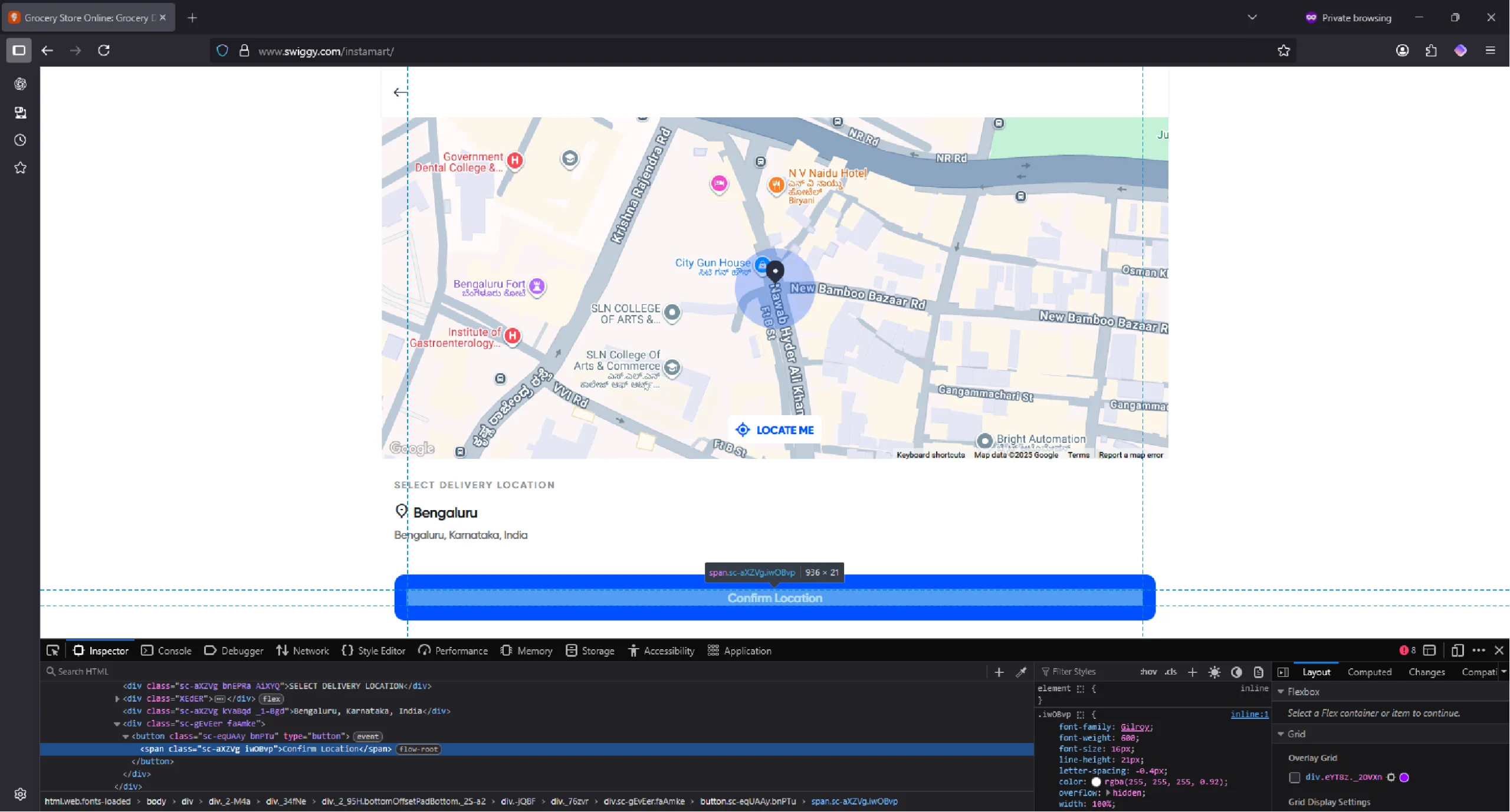
Select the button by targeting a button with the text “Confirm” in it. Then, click on the confirm button using click().
confirm_button = browser.find_element(By.XPATH, '//button/span[contains(text(),"Confirm")]')
confirm_button.click()
sleep(3)
Clicking the confirm button takes you to the product results page.
However, a tooltip will appear, which you need to dismiss before continuing with the search. Do this by using JavaScript to programmatically click the dismiss button.
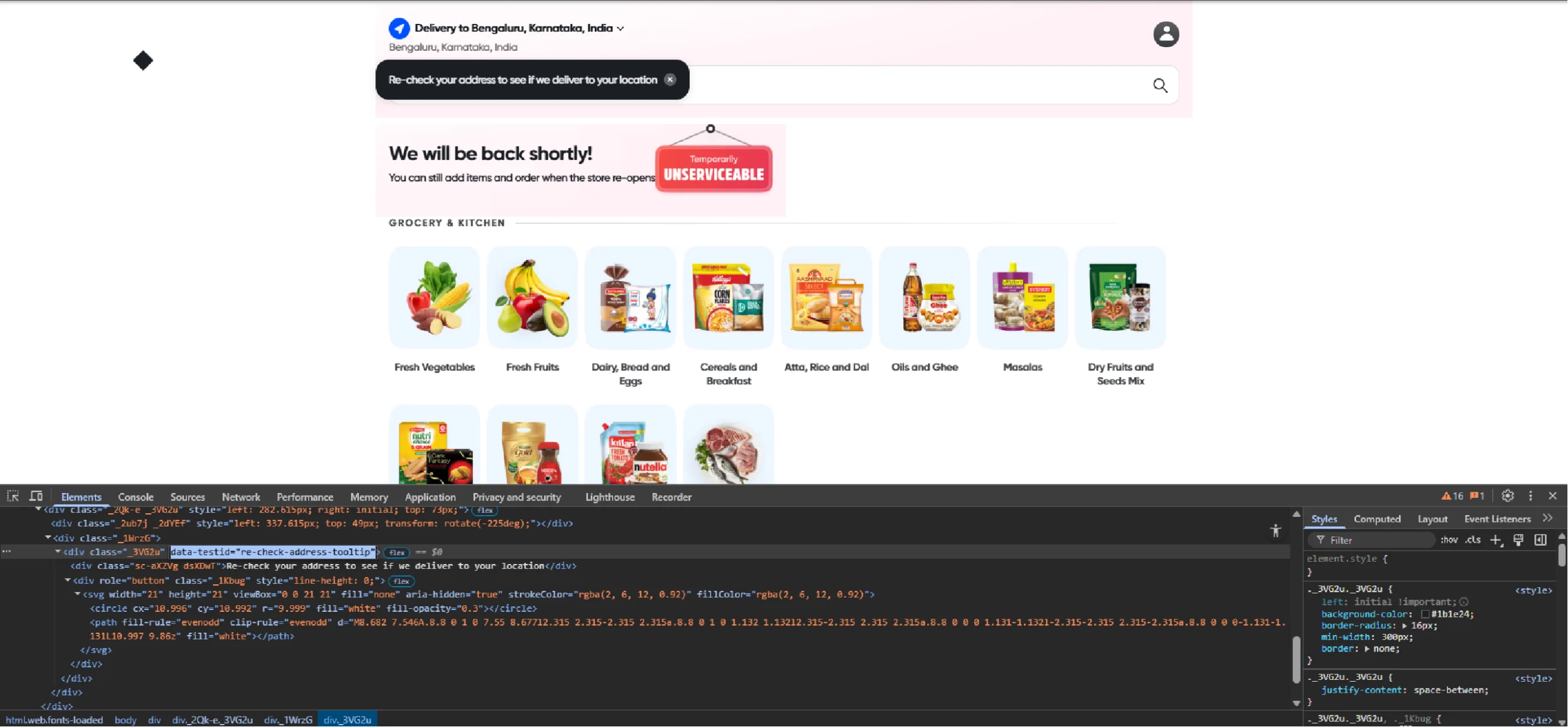
Selenium couldn’t interact with the tooltip’s button directly. So the code uses Selenium’s execute_script() method to run a JavaScript that clicks the button.
browser.execute_script("document.querySelector('div[data-testid=\"re-check-address-tooltip\"] > div[role=\"button\"]').click()")
Here, the code executes a small JavaScript snippet using execute_script() to simulate clicking the dismiss button (find the data-testid attribute first).
Extracting Product Details
With the location set and the page ready, the next task is to search for a specific product.
First, inspect the search bar and find its data-testid.
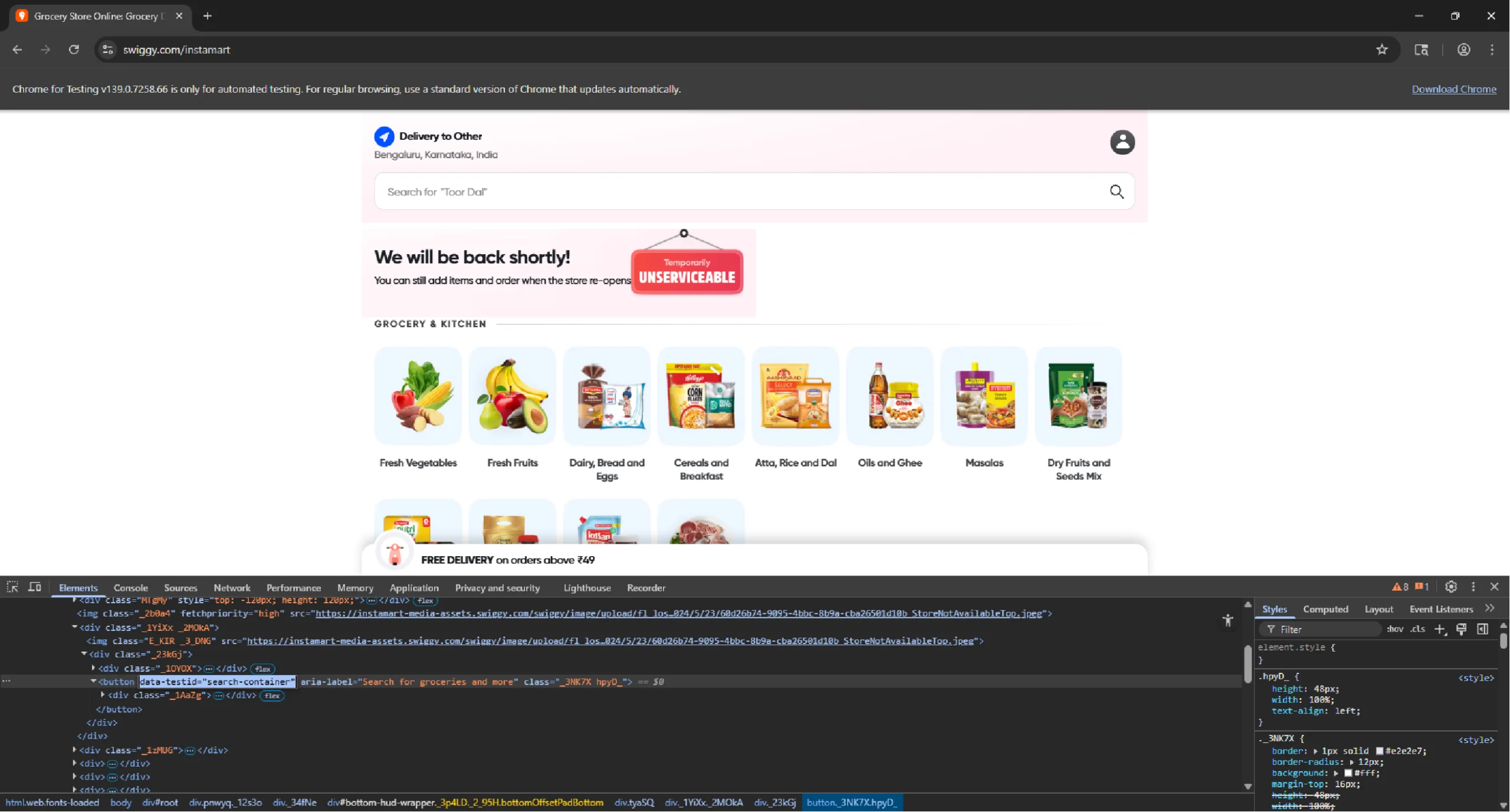
Then, select and click the search button.
search_button = browser.find_element(By.XPATH, '//button[@data-testid="search-container"]')
search_button.click()
sleep(2)
Next, get the type attribute of the search input box and enter the search term.
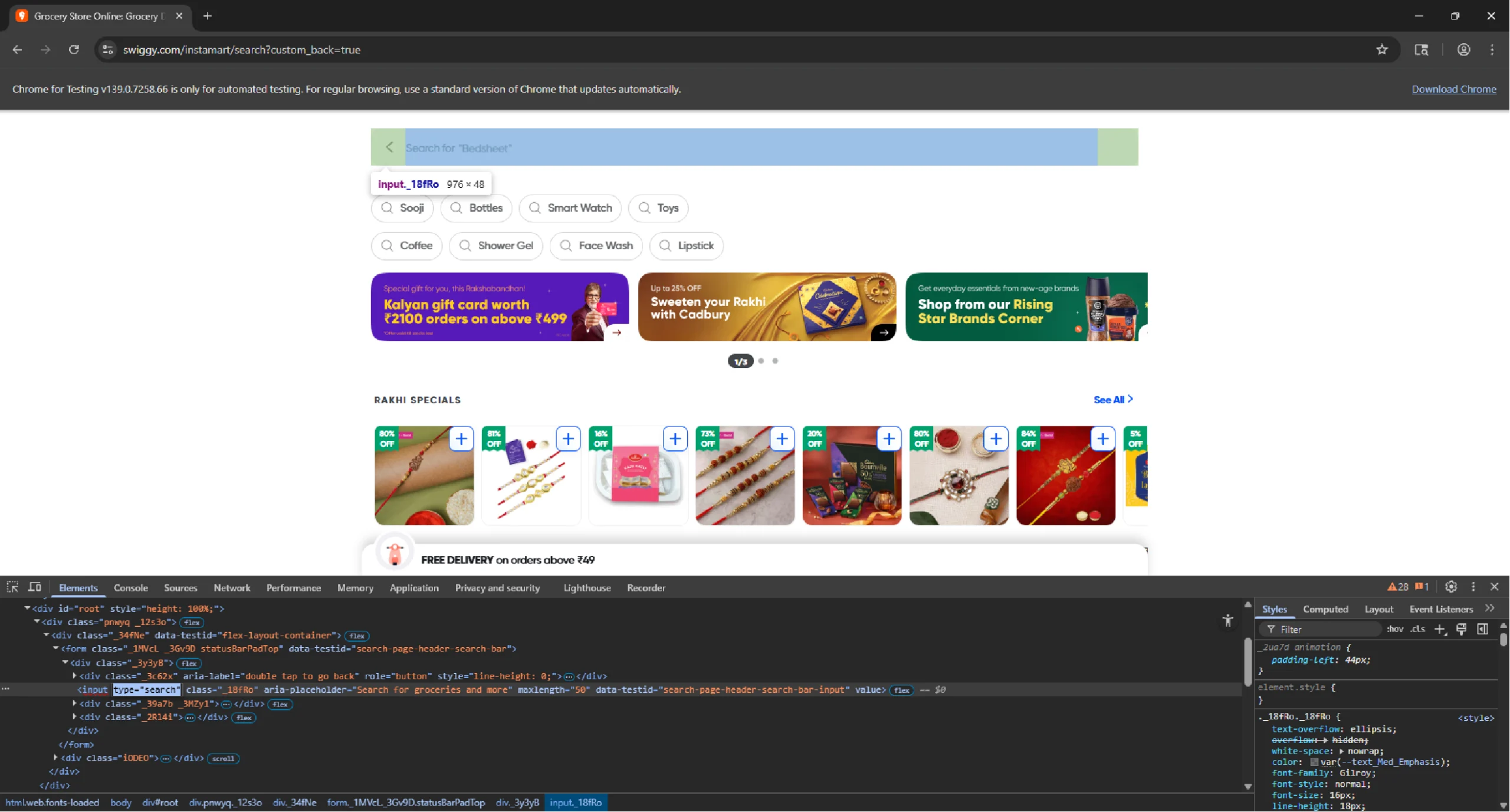
search_input = browser.find_element(By.XPATH, '//input[@type="search"]')
search_input.send_keys('chocolates')
sleep(1)Finally, use send keys to simulate pressing the Enter key, which will load the search results.
search_input.send_keys(Keys.ENTER)
sleep(3)After the search results load, it’s time to extract the product details. Locate all the product containers and loop through them to gather the required information: product name, price, description, and quantity.
Store each product’s details in a dictionary and append the dictionary to a list.
products = browser.find_elements(By.XPATH, '//div[contains(@data-testid,"default_container")]')
product_details = []
for product in products:
details = product.text.split('\n')
n = 1 if "% OFF" in details[0] else 0
n = n + 1 if 'Ad' in details[0] else n
product_details.append({
"Product Name": details[n + 1],
"Price": details[5],
"Description": details[3],
"Quantity": details[4]
})
Here, the find_elements() method locates all the product containers on the page.
Inside the loop,
- Split the product’s information (such as name, price, description, etc.) by newlines using product.text.split(‘\n’)
- Adjust the index based on whether the listing has a discount, is an Ad, or is handpicked.
- Store the product details in a dictionary and append to the product_details list.
Saving Data to JSON
After gathering all the product details, save them in a file for later.
with open("instamart.json", "w") as f:
json.dump(product_details, f, indent=4, ensure_ascii=False)
Here, the code
- Opens a file called instamart.json in write mode.
- Saves the product_details list into the file using json.dump(), with an indentation of 4 spaces for readability
The results of Swiggy Instamart scraping look like this:
{
"Product Name": "NOICE Fluffy White Bread (Freshly made)",
"Price": "39",
"Description": "Rich, dense & palm oil-free",
"Quantity": "250 g"
}
Here’s the complete code:
#import packages
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import json
from time import sleep
# launch the web browser
browser = webdriver.Chrome()
browser.get("https://www.swiggy.com/instamart")
sleep(3)
# set location
location_input_div = browser.find_element(By.XPATH,'//div[@data-testid="search-location"]')
location_input_div.click()
sleep(2)
location = "Banglore"
location_input = browser.find_element(By.XPATH, '//input[contains(@placeholder,"Search for area")]')
location_input.send_keys(location)
sleep(2)
location_div = browser.find_element(By.XPATH, '//div[contains(@class,"icon-location-marker")]')
location_div.click()
sleep(3)
confirm_button = browser.find_element(By.XPATH, '//button/span[contains(text(),"Confirm")]')
confirm_button.click()
sleep(3)
# search a product
browser.execute_script("document.querySelector('div[data-testid=\"re-check-address-tooltip\"] > div[role=\"button\"]').click()")
search_button = browser.find_element(By.XPATH, '//button[@data-testid="search-container"]')
search_button.click()
sleep(2)
search_input = browser.find_element(By.XPATH, '//input[@type="search"]')
search_input.send_keys('bread')
sleep(1)
search_input.send_keys(Keys.ENTER)
sleep(3)
# extract product details
products = browser.find_elements(By.XPATH,'//div[contains(@data-testid,"default_container")]')
product_details = []
for product in products:
details = product.text.split('\n')
print(details)
n = 1 if "% OFF" in details[0] else 0
n = n+1 if 'Ad' in details else n
n = n+1 if 'Handpicked' in details else n
product_details.append({
"Product Name": details[n+1],
"Price": details[n+5],
"Description": details[n+3],
"Quantity": details[n+4]
})
# save the details in a JSON file
with open("instamart.json","w") as f:
json.dump(product_details,f,indent=4,ensure_ascii=False)
browser.quit()
Code Limitations
While this code is functional for small-scale scraping, it has several limitations that make it less suitable for large-scale data extraction:
- Error Handling: The script lacks error handling, so if the scraper didn’t find any elements or the page structure changed, it may crash or produce incomplete data.
- Dynamic Elements: The code relies heavily on static XPath expressions. If Instamart changes its website structure or layout, the script will likely break.
- IP Blocking: Continuous scraping from the same IP can lead to temporary or permanent blocks from the website, requiring you to implement proxy rotation.
- Scalability: The current code is designed for a single search term (“chocolates”) and doesn’t account for iterating through different categories or handling large datasets efficiently.
Wrapping Up: Why You Need a Web Scraping Service
While Selenium provides an excellent solution for scraping dynamic websites like Instamart, its limitations can become apparent when scaling up. Headless browsers, frequent delays, and manual code maintenance can be time-consuming and unreliable for high-volume projects. That’s where a web scraping service like ScrapeHero comes in.
Using a professional service helps you avoid the common pitfalls of DIY scraping, including managing infrastructure, handling CAPTCHAs, ensuring legal compliance, and scaling operations. ScrapeHero provides a robust, reliable solution for gathering data from a wide range of websites, including Instamart, with minimal hassle and maximum efficiency.
ScrapeHero is an enterprise-grade web scraping solution capable of building high-quality scrapers and crawlers. Contact ScrapeHero to forget about scraping and focus more on your core business.



