
Real Estate data available online is rife with quality issues and lack of inconsistency. In this post we will demonstrate some of the issues with examples and describe some of the challenges associated with real estate data management – collecting, cleaning, and standardizing real estate data. We will be focusing on the United States market primarily, while some of the challenges may apply to other countries as well.
Data Sources
There are a lot of data sources for real estate data in the US. You have the well known online sources such as Zillow.com, Trulia.com, Redfin.com, Realtor.com which started out to list “Properties for Sale” and some also have “Properties for Rent”.
We also have specialized “Properties for Rent” sources such as Apartments.com, ForRent.com, Zumper.com, Apartmentlist.com, Hotpads.com etc. While most of these websites are countrywide, there are also many niche local sources.
There is also the old and main source of data called the MLS. This “source” is actually is not one source or one company or one website but is rather a collection of various regional companies, data sources, and websites. In addition, there are some data aggregators and integrators that attempt to merge and provide data from multiple MLSs across the country.
You can read about it more at Wikipedia which states that as of 2019, there were 640 MLSs in the US. That actually translates to more than 12 MLSs on average in a US State!
Most of these MLSs have their own databases, schemas, and taxonomies and there is no universal definition of what a bedroom or full vs half bath means or what is considered the usable square footage of a property! Fundamentally, there is no real agreement on even the address of a property. In older areas of the country there is no agreement on even basic facts, such as the number of bedrooms in a property or the square footage and their sources.
The actual sources of data to any of these MLSs are the individual real estate professionals (or their office staff) who enter the data about each listing by hand. These hardworking individuals further rely on various antiquated sources of information for data points such as number of (legal) bedrooms, square footage etc on various town/city/county assessor departments, registry of deeds or word of mouth and hundred year old listings with invalid data passed down over time. This data is barely ever verified or corrected, if found to be inaccurate.
According to the NAR (The National Association of REALTORS®), their total membership for February 2020 is 1,374,774, so you have at least a million people performing data entry every day and all that is supposed to be of high quality and accurate all the time while there is no standard schema for the data fields or any data validation or verification.
The current state described above is so distributed, uncoordinated, and chaotic that it is bound to be dirty and inconsistent.
Zillow started as a real estate company and they have gone a bit deeper into the issues with real estate data management in their 2016 article which is still relevant and probably will stay so for decades.
Let’s discuss one of the key data points (the property address) and explore the current state of the data and the issues we commonly see.
Address or Location
One of the key data points for a property is the location or the address. Real Estate is a tangible asset and has to have a fixed address (even for mobile homes, they do have to be placed on a land with an address). The address is usually the “unique key” most people want to use to match data between various datasets. Properties cannot exist in space (yet) so they need a physical address on this earth.
Addresses in the United States mainland are supposed to be fairly standard. There are many variations in non-mainland states and territories which you can read more at the USPS website.
They usually have an Address Line 1, Address Line 2, City, State, Zip or in more detail, here is what the USPS considers to be a standard
Complete Address Elements
- Addressee name or other identifier and/or firm name where applicable.
- Private mail box designator and number (PMB 300 or #300).
- Urbanization name (Puerto Rico only, ZIP Code prefixes 006 to 009, if area is so designated).
- Street number and name (including predirectional, suffix, and postdirectional as shown in USPS ZIP+4 Product for the delivery address or rural route and box number (RR 5 BOX 10), highway contract route and box number (HC 4 BOX 45), or Post Office box number (PO BOX 458), as shown in USPS ZIP+4 Product for the delivery address). (“PO Box” is used incorrectly if preceding a private box number, e.g., a college mailroom.)
- Secondary address unit designator and number (such as an apartment or suite number (APT 202, STE 100)).
- City and state (or authorized two-letter state abbreviation).
- Correct 5-digit ZIP Code or ZIP+4 code. If a firm name is assigned a unique ZIP+4 code in the USPS ZIP+4 Product, the unique ZIP+4 code must be used in the delivery address.
A logical and immediate question that comes to mind is
If the address is fairly standard then what is the problem?
Here are some examples of the problems in the real world
Mistakes in data entry
- Simple spelling mistakes on any of the lines
- Wrong Street Names – 13 Mapel St vs 13 Maple St
- Wrong numbers 1234 Main St (which doesn’t even exist) instead of 123 Main St
- Wrong City Names Bolton vs Boston (yes both are in MA)
- Wrong Zip Code 02134 vs 01234
Any of these mistakes are not easy to detect or use to compare data sets
e.g. Is 13 Mapel St actually the same property as 13 Maple St or are they really two different properties?
Is the data for Bolton and not Boston or is it the other way around?
Intentionally erroneous data
One common reason for wrong/fake data in this industry is because real estate agents try to skirt the rules in place at various MLSs. MLSs have various rules for their members and some of those rules are also automatically enforced in their technology systems. One of the easy rules to keep data clean is by preventing “duplicate listings”.
MLS systems have a quick and basic check for the address of each listed property that do not allow agents to list the same exact property twice or more. For various reasons, agents enter duplicate listings and thereby create new and fake listings.
Here is a typical scenario:
In a competitive real estate market such as Boston, a unit has 2 legal bedrooms and due to the scarcity of housing a former study has been “converted” to a bedroom which may be acceptable to some renters but other renters may be turned off by the small bedroom or the increased rent (more bedrooms have more rent).
Some agents create two MLS listings in such cases. Let’s say there is only one unit for rent and the address of the property and unit is 12 Main St Unit 1, Boston, MA
An agent may create two slightly different MLS listings such as:
- 12 Main St Unit 1, Boston MA – 3 Bedroom 1 bath for $2500
- 12 Main St Unit 1A Boston MA – 2 Bedroom 1 bath for $2000
This helps the realtor cater to two groups of renters at two different budgets – one group looking for a 3 bedroom and having a higher budget (preferable to the realtor and owner) and as a backup listing for the group that wants two real bedrooms for a lower budget (not preferable to the realtor or owner BUT a good backup strategy in case the 3rd bedroom is not liked by any potential tenants and the property stays unrented).
Here is some recent listings from Zillow which demonstrate some of these data issues. The listings are from the same realtor and we cant tell if they are for the same property or not. The address is not a valid address, the type is also apartment vs townhouse. The pictures for the first listing also seem off for the neighborhood, the finishes are upscale but the image resolution is terrible. It seems like one or both of this listings are fake or they could also be real and therein lies the data problem.
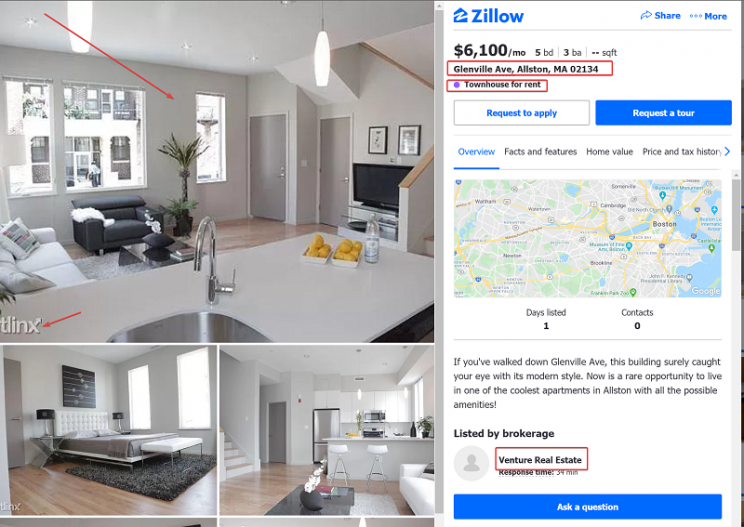
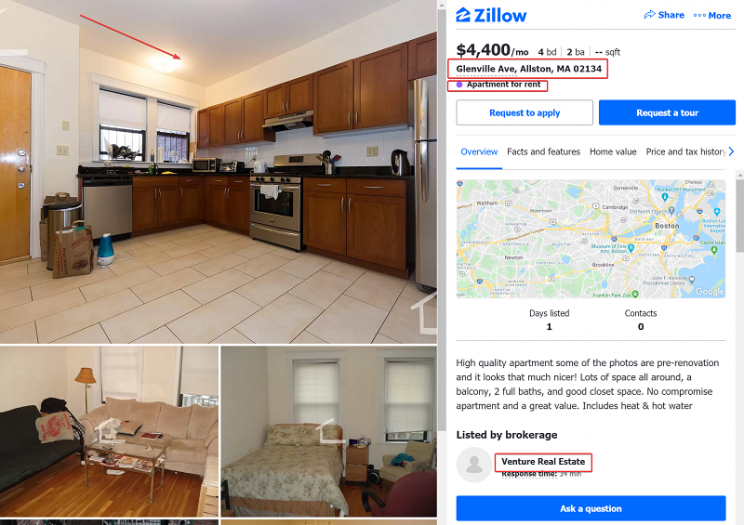
We have seen Zillow unit numbers in Boston to be something like 2OJ, TH3L etc – which are very unlikely in a very old city with traditional and old naming conventions.
Here is an example of 4 variations on the same property in Boston that only has 3 units Unit 1, 2 and 3 and not units 2OJ, X1 and U1 or TH3L. The neighborhood Brighton is also used synonymously with the city Boston which adds to the data mismatch.
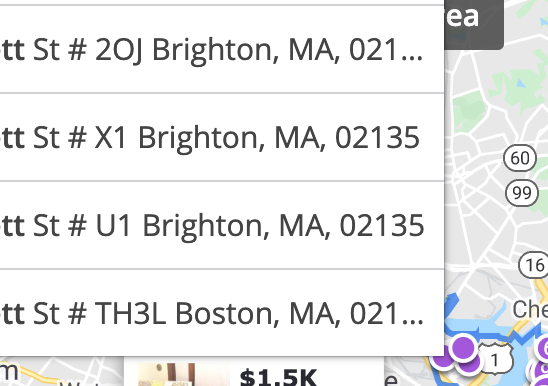
As you can see, it is not an easy task for even a multi-billion dollar company such as Zillow to address data quality in just their own data let alone try to clean up data from so many more disparate sources. There are inherent real estate data management issues in the source data and then there are people trying to game the system for their own gain.
Address Normalization
One of the first steps when you gather real estate data from one or more sources is the ability to identify and compare two properties.
The data needs to be cleaned and normalized to some standard format to check whether a listing for sale or rent is a duplicate listing or a unique listing in one website and then also be able to compare if it is the same listing across multiple websites.
One of the best approaches to perform address normalization and real estate data management is to use companies that have dedicated a lot of time and effort to make the process easier and one of those companies is Google and its universally used Google Maps. The Google Geocoding API is a great place to start.
Their API is easy (but expensive for large volumes) to use and once each address is normalized, then it can realistically be compared. e.g in the above example trying to compare 13 Mapel St to 13 Maple St isn’t conclusive because it could be the same property or two different properties.
Address normalization will clean up the data in most cases and if this was just a data entry mistake and there is no 13 Mapel St, we will know that after the normalization process. The Google API may be able to correct the address to 13 Maple St in some cases and in some cases it may not which leads to issues with address correction (if at all possible).
The real estate data management issues discussed above and examples provided are a small subset of what we encounter in the real life, but after reading this article, you should be better educated about the challenges that exist and understand that there is no easy or magical solution to this problem.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data



