
Web scraping is a faster and efficient way to get details of store locations for a particular website rather than taking the time to gather details manually. This tutorial is about scraping store locations and contact details available on Target.com, one of the largest discount store retailers in the U.S.
For this tutorial, our scraper will extract the details of store information by a given zip code.
Here is a list of fields we will be extracting:
- Store Name
- Address
- Week Day
- Hours Open
- Phone Number
Below is a screenshot of the data that will be extracted as part of this tutorial.
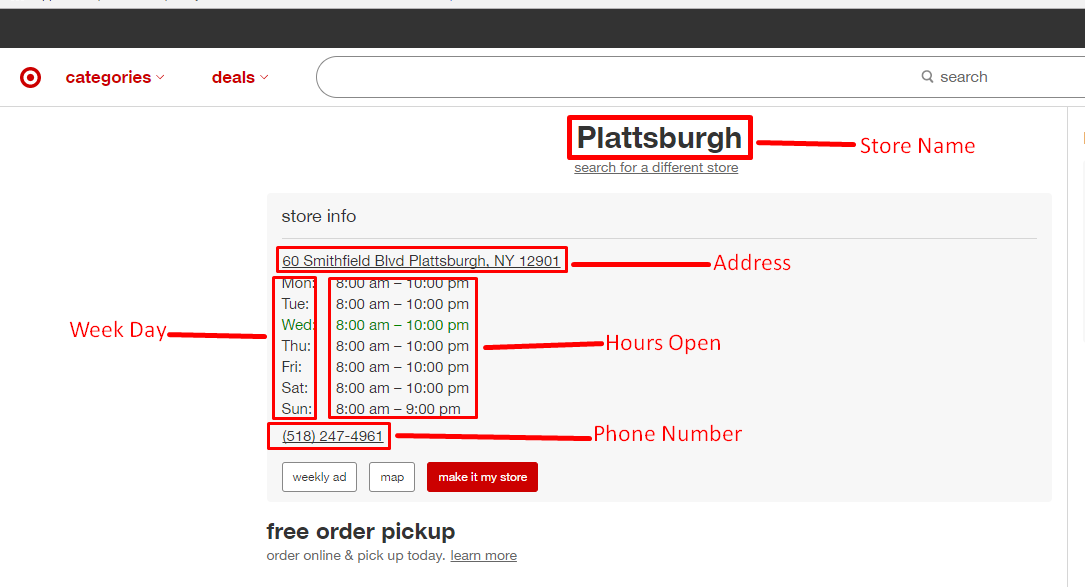
There is a lot more data we could scrape from the store detail page on Target such as pharmacy and grocery timings, but for now, we’ll stick to these.
Scraping Logic
- Construct the URL of the search results page from Target. Let’s take the location Clinton, New York. We’ll have to create this URL manually to scrape results from that page-https://www.target.com/store-locator/find-stores?address=12901&capabilities=&concept=
- Download HTML of the search result page using Python Requests – Quite easy, once you have the URL. We use Python requests to download the entire HTML of this page.
- Save the data to a JSON file.
Requirements
For this web scraping tutorial using Python 3, we will need some packages for downloading and parsing the HTML. Below are the package requirements.
Install Python 3 and Pip
Here is a guide to install Python 3 in Linux – http://docs.python-guide.org/en/latest/starting/install3/linux/
Mac Users can follow this guide – http://docs.python-guide.org/en/latest/starting/install3/osx/
Windows Users go here – https://www.scrapehero.com/how-to-install-python3-in-windows-10/
Install Packages
- PIP to install the following packages in Python (https://pip.pypa.io/en/stable/installing/)
- Python Requests, to make requests and download the HTML content of the pages ( http://docs.python-requests.org/en/master/user/install/).
- UnicodeCSV for handling Unicode characters in the output file. Install it using pip install unicodecsv.

The Code
https://gist.github.com/scrapehero/28189c8aef53e75921cfea49c5ced053
https://gist.github.com/scrapehero/41a1db90abb835e5b6c516fb90126747
If you would like the code in Python 2.7 you can check out the link here https://gist.github.com/scrapehero/fbf04332e2a26c326dab9b53e23a8dee
Running the Scraper
Assuming the scraper is named target.py. If you type in the script name in command prompt along with a -h
usage: target.py [-h] zipcode positional arguments: zipcode Zip code optional arguments: -h, --help show this help message and exit
The argument zip code is the zip code to find the stores near the particular location.
As an example, to find all the target stores in and near Clinton, New York we would put the argument as 12901 for zip code:
python target.py 12901
This will create a JSON output file called 12901-locations.json that will be in the same folder as the script.
The output file will look similar to this.
{
"County": "Clinton",
"Store_Name": "Plattsburgh",
"State": "NY",
"Street": "60 Smithfield Blvd",
"Stores_Open": [
"Monday-Friday",
"Saturday",
"Sunday"
],
"Contact": "(518) 247-4961",
"City": "Plattsburgh",
"Country": "United States",
"Zipcode": "12901-2151",
"Timings": [
{
"Week Day": "Monday-Friday",
"Open Hours": "8:00 a.m.-10:00 p.m."
},
{
"Week Day": "Saturday",
"Open Hours": "8:00 a.m.-10:00 p.m."
},
{
"Week Day": "Sunday",
"Open Hours": "8:00 a.m.-9:00 p.m."
}
]
}
You can download the code at https://gist.github.com/scrapehero/28189c8aef53e75921cfea49c5ced053
Let us know in the comments below how this scraper worked for you.
Known Limitations
This code should work for extracting details of Target stores for all zip codes available on Target.com. If you want to scrape the details of thousands of pages you should read Scalable do-it-yourself scraping – How to build and run scrapers on a large scale and How to prevent getting blacklisted while scraping.
If you need professional help with scraping complex websites, contact us by filling up the form below.
Tell us about your complex web scraping projects
Turn the Internet into meaningful, structured and usable data
Disclaimer: Any code provided in our tutorials is for illustration and learning purposes only. We are not responsible for how it is used and assume no liability for any detrimental usage of the source code. The mere presence of this code on our site does not imply that we encourage scraping or scrape the websites referenced in the code and accompanying tutorial. The tutorials only help illustrate the technique of programming web scrapers for popular internet websites. We are not obligated to provide any support for the code, however, if you add your questions in the comments section, we may periodically address them.



