
Accessing data from social media feeds can be useful in conducting sentiments analysis and understanding user behavior towards a particular event, product, or statement. With the right infrastructure, you can scrape twitter for keywords or based on a time frame. This tutorial shows you how to scrape tweet data from Twitter’s advanced search for free using the Twitter Scraper available on ScrapeHero Cloud and help you scrape Twitter data easily without any coding.
Here are the steps to scrape Twitter Data:
- Create a ScrapeHero Cloud account and select the Twitter Crawler.
- Input the Twitter Advanced search URLs and filters to be scraped.
- Setup and run the Twitter scraper.
- Download the scraped tweet data from Twitter (CSV, JSON, XML).
The ScrapeHero Cloud has pre-built scrapers that in addition to gathering social media data from the web, can Scrape Google, Scrape Job data, Scrape Real Estate Data and more. The tool is easy to use and does not require any coding skills to run, it also provides a free plan to test the speed, accuracy, and quality of the data before signing up for a paid plan. These scrapers are pre-built and cloud-based, you need not worry about selecting the fields to be scraped nor download any software in order to run the scraper. The scraper can run from any browser and can deliver the data directly to Dropbox.

The crawler scrapes the data without logging in, so the actual number of pages crawled might differ in ScrapeHero Cloud.
Data Fields to Extract
These are the data fields we can extract using the Twitter Crawler based on the input URLs.
- Handle
- Content
- Name
- Replies
- Retweets
- Favorite
- Date
- Hashtag
- URL
Step 1: Create an account
First, we will create an account in ScrapeHero Marketplace. To sign up go to the link – https://cloud.scrapehero.com/accounts/login/ and create an account with your email address.
Step 2: Input the Details for the Twitter Scraper
There are two ways you can provide input URL for the Twitter crawler in two ways:
– Getting the input URL from Twitters Advanced Search
Twitter Advanced Search lets you find historical tweets that you can filter based on parameters like Words, People, and Dates. In order to scrape historical tweet data, use the advanced search in Twitter by going to this URL
https://twitter.com/search-advanced?lang=en
and filter the data based on your needs. For now, we will do a search for all tweets which has the text “tesla” and was made between October 1 to October 5, 2018. Copy the search result URL. Our link looks like this:
https://twitter.com/search?l=&q=tesla%20since%3A2018-10-01%20until%3A2018-10-05&src=typd&lang=en
– Providing a Hashtag or Twitter Profile as an input URL
You can provide the URL of a Twitter Profile like this:
https://twitter.com/NatGeo
Or based on a search hashtag like this:
https://twitter.com/hashtag/ElonMusk?src=hashtag_click&f=live
Step 3: Setting up Twitter Scraper and Running it
This advanced Twitter scraper allows you to input filters based on which you would like to scrape tweets from Twitter. Choose the date filter to limit the tweets from a certain time and the number of tweets to collect. If do not want any original or referenced quotes and hashtags, you have the option to exclude them. After you have input all your URLs and filters click on ‘Continue’.
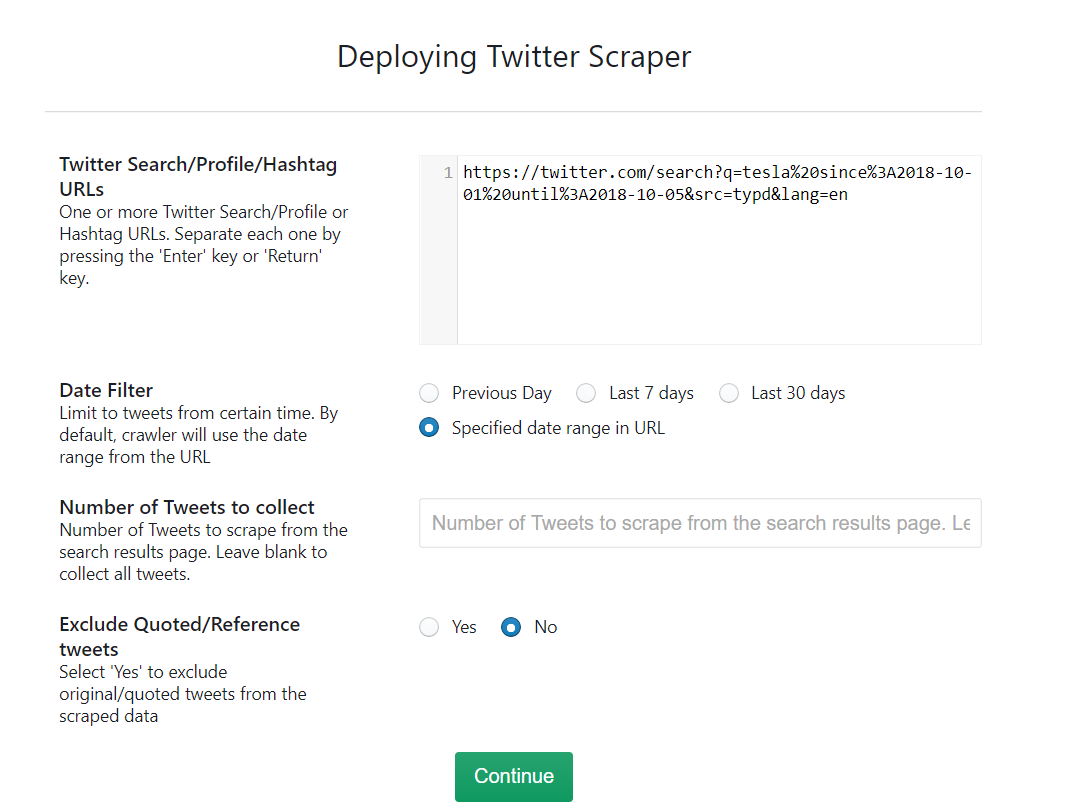
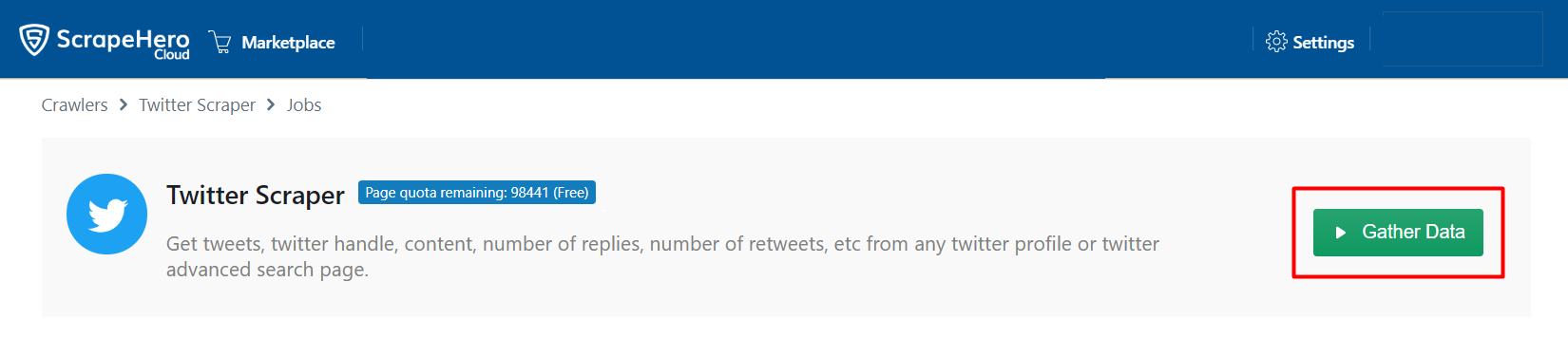
The Twitter crawler page will open up and you will see the option to gather the data. Once you have click it, the scraper will start scraping tweets from Twitter.
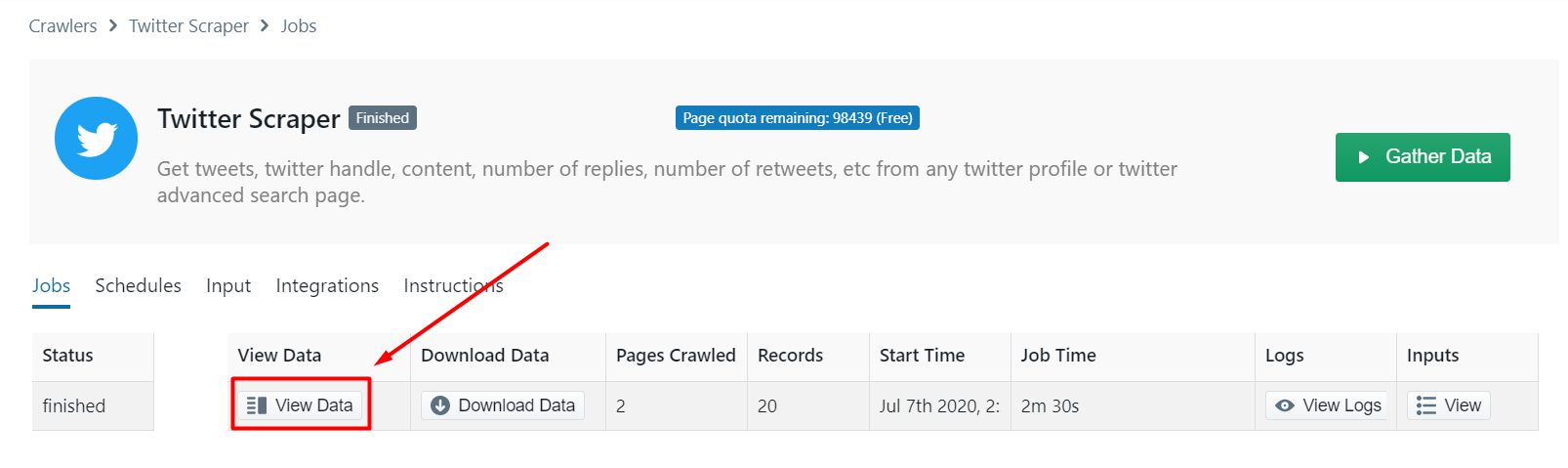
After the scrape is complete the ‘Status’ of the crawler will change from ‘Started’ to ‘Finished’. Click on ‘View Data’ to view the scraped Twitter data.
Step 4: Download Twitter Data
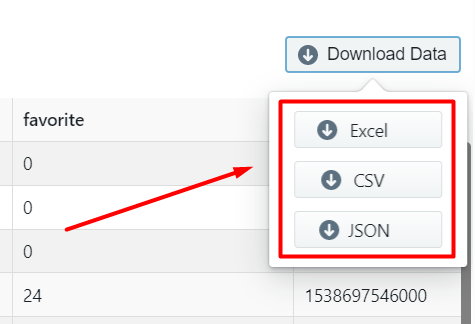
You can see all the scraped tweets on this page. To download the scraped tweet data click on ‘Download Data’.
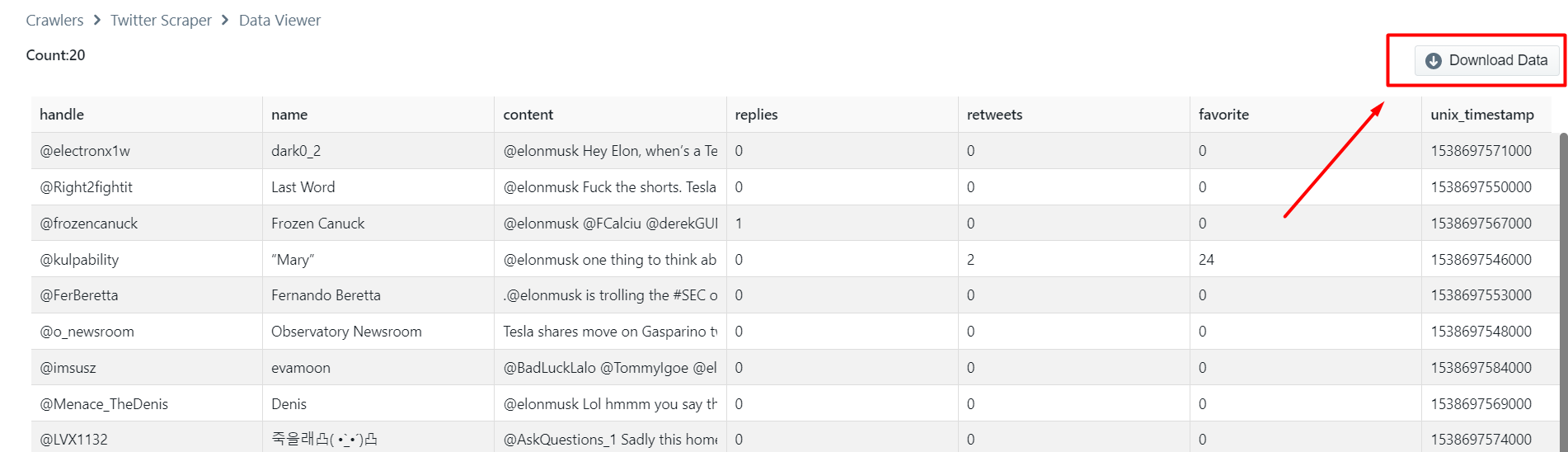
A drop down to select a data format will appear. You can choose between CSV, JSON and XML formats. After clicking on the data format option, a file will soon be downloaded with all the scraped Twitter data.
You can get data delivered to Dropbox if you integrate the crawler account to your Dropbox account. You also have the option to schedule the data if you want to scrape twitter data on a timely basis.
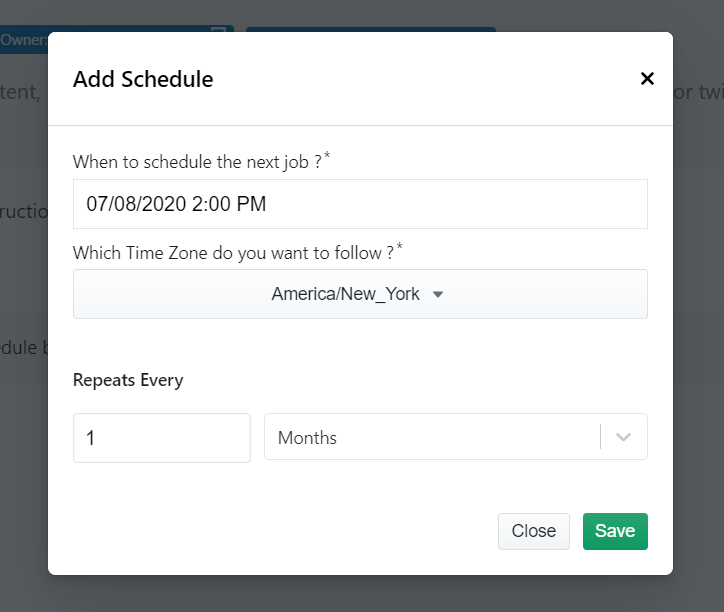
Go to the tab ‘Schedule’ in the table and click on the button ‘Add Schedule’. There are the options to choose the date, time and time zone along with the options to repeat the run as often as you want – hourly, weekly or daily.
Update: In 2023, X (formerly known as Twitter) updated its terms to prohibit crawling and scraping without prior consent. Following the introduction of these new guidelines, we have removed our Twitter crawler from ScrapeHero Cloud.
The crawler scrapes the data without logging in, so the actual number of pages crawled might differ in ScrapeHero Cloud.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data
Disclaimer: Any code provided in our tutorials is for illustration and learning purposes only. We are not responsible for how it is used and assume no liability for any detrimental usage of the source code. The mere presence of this code on our site does not imply that we encourage scraping or scrape the websites referenced in the code and accompanying tutorial. The tutorials only help illustrate the technique of programming web scrapers for popular internet websites. We are not obligated to provide any support for the code, however, if you add your questions in the comments section, we may periodically address them.



