

The e-commerce industry moves too fast for guesswork. Prices shift, inventory moves, and competitors react — all before you’ve had your second coffee. If you’re serious about data quality in web scraping, you need data you can actually trust to keep up.
But here’s what most data vendors won’t tell you: clean data is harder to deliver than it looks. A lot of providers will promise accuracy, hand you a dashboard that looks great, and quietly hope you don’t dig too deep. Our entire business model depends on you digging deep.

That’s not a marketing line — it’s how we’ve kept 98% of our clients for over a decade. If you’re evaluating us right now, here’s exactly how our process works.
How Does ScrapeHero Ensure Data Accuracy?
Most people assume web scraping is simple. Write a script, point it at a website, and let it run. And honestly? For a one-off project, that’s fine.
But you’re not running a one-off project. You’re managing thousands of SKUs across multiple platforms, and that’s where the “just write a script” approach completely falls apart.
Here’s what nobody tells you: scrapers break silently. A site changes its structure overnight, your scraper keeps running as if nothing happened, and your team spends weeks making decisions on data that was never accurate to begin with. By the time anyone notices, the damage is done.
That’s the problem we built our infrastructure to solve.
Our professional data extraction services go far beyond pointing a script at a page. Our specialists design custom extraction strategies tailored to your specific needs — including competitor pricing, stock monitoring, and product aggregation across dozens of platforms.
Our systems crawl thousands of pages per second and handle the hard stuff — JavaScript, AJAX sites, CAPTCHA, and blacklisting, without your team ever having to think about it. And when a website changes its structure, our self-healing technology adjusts automatically. So, your data keeps flowing.
There’s a real difference between a script someone wrote and a system someone built. Scripts break under pressure. Ours is designed for it.

Here’s exactly how ScrapeHero delivers on that promise, through 5 non-negotiable steps built into every pipeline.
- Schema Design: The Foundation of Clean Data
- Data Normalization: Making Data Actually Comparable
- QA Processes That Catch Errors Before They Cost You
- Scaling with Reliability: Monitoring and Retries
- Built-In Ethical, Compliant Data Collection
1. Schema Design: The Foundation of Clean Data
Raw data can look perfectly fine until you actually try to use it.
That’s when the problems show up. A price field that’s text in one source and a number in another. Product categories that don’t match across platforms. An AI model is throwing errors because the input data isn’t consistent. None of it is obvious upfront. All of it is expensive to fix later.
This is where most data vendors quietly drop the ball. They deliver the data. What you do with the formatting mess is your problem.
We don’t work that way.
Before we pull a single data point, we build a custom schema for your business. This is a core part of how we approach data quality in web scraping. Every source we pull from, regardless of how it’s structured on their end, delivers data that speaks the same language as yours. Product categories, pricing formats, units of measurement, date structures, all of it standardized, all of it consistent.
The result?
Data that plugs directly into your pricing automation tools, inventory systems, or AI models. No reformatting. No manual cleanup. No surprises.
Most people think data quality is about the scraping. It’s not. It starts with the schema, and that’s exactly where we start.
2. Data Normalization: Making Data Actually Comparable
When you’re pulling data from dozens of websites, it almost never arrives in the same format. Prices in different currencies. Dimensions in different units. Category names that mean the same thing but look completely different across platforms.
Without normalization, you’re not comparing data. You’re comparing chaos.
Our experts apply advanced normalization techniques across hundreds, sometimes thousands, of SKUs. Currencies get converted. Dimensions get standardized. Category taxonomies get aligned. By the time the data reaches you, it’s always apples-to-apples regardless of where it came from.
For brand monitoring, maintaining data quality in web scraping isn’t a nice-to-have. If you’re tracking competitor pricing across multiple markets, inconsistent data doesn’t just slow you down — it gives you a false picture of the competitive landscape. And decisions made on a false picture are worse than no decision at all.
3. QA Processes That Catch Errors Before They Cost You
One bad data point in the wrong place can throw off a pricing decision, corrupt a product listing, or skew a competitive analysis. At scale, even a small error rate compounds quickly into a real revenue problem.
Here’s how we catch it before it reaches you.
Think of it like quality control on a factory line — it happens in stages.
First, automated syntax validation checks the basics. Are all data points in the correct format? No missing commas, no misplaced decimals.
Then, semantic validation asks the smarter questions. Does this price actually make sense? A luxury handbag listed for $3 probably isn’t right — even if the format is perfect.
Finally, cross-source consistency checks compare data across platforms to make sure everything adds up.
And before we ever run a full scrape, our team manually verifies that everything meets your specs. Automation handles the volume. Humans catch what automation misses. Errors get flagged right away, so your team never has to second-guess your dashboards.
Most QA processes are designed to explain errors after they happen. Ours is designed to make sure they don’t.
4. Scaling with Reliability: Monitoring and Retries
Growth sounds like a good problem to have. And it isn’t until your data infrastructure can’t keep up.
Here’s what usually happens. A brand scales quickly, enters new markets, and expands its catalog. The data volume doubles, then triples. And suddenly there are gaps. Downtime and inconsistencies that weren’t there before. Not because the scraping stopped working — but because the infrastructure was never built to handle that kind of pressure.
Ours was.
As a reliable web scraping company, we’ve built our infrastructure specifically for the pressure that comes with scale.
Our monitoring systems track the health of every pipeline in real time. Connection errors, unexpected site structure changes, and timeouts are automatically detected and addressed. When something goes wrong, retry mechanisms kick in right away without anyone having to lift a finger. Critical failures trigger instant alerts so your team can act before they ever affect your operations or customers.
Whether you’re monitoring hundreds of SKUs or tens of thousands across multiple regions and languages, the quality doesn’t dip as the volume climbs. That’s not a promise — it’s how the infrastructure is built.
5. Built-In Ethical, Compliant Data Collection
Here’s something most data vendors hope you don’t ask about: compliance.
Data privacy regulations are tightening globally. Platforms are getting more protective of their content. And the brands that cut corners to get data faster are quietly accumulating legal risk, platform bans, and reputational damage that no competitive advantage is worth.
We don’t cut corners. Our extraction processes are built around publicly available data, operating within platform terms of service, and pipelines that are responsible at scale. Compliance isn’t something we bolt on at the end — it’s built in from day one.
For e-commerce brands serious about long-term growth, this matters more than most people realize. You’re not just choosing a data vendor. You’re choosing a partner whose methods become your liability if they get it wrong. We make sure they don’t.
You get the competitive intelligence you need without the risk that comes with shortcuts.
What Our Customers Actually Say
You can read all the process documentation you want. At some point, the only thing that actually answers “can I trust these people?” is what their long-term clients say.
So here’s the honest version.
We maintain a 98% customer retention rate. In an industry where switching vendors is common and overpromising is practically a business model, that number means something.
But what’s behind it is more telling than the number itself.
Clients who stay with us long-term consistently point to ScrapeHero’s data quality as the defining factor, along with the quality of support and the honesty rare in this space.
One client, after six years of working with us, said what sets us apart beyond the technical capabilities is our genuine commitment to understanding their specific business needs. Not just delivering data. Actually understanding what they’re trying to do with it.
That’s the difference between a vendor and a partner.
We also keep things transparent. No long-term contracts. No hidden fees. And when we spot a potential issue, we flag it before you ever notice it — not after it’s already cost you something.

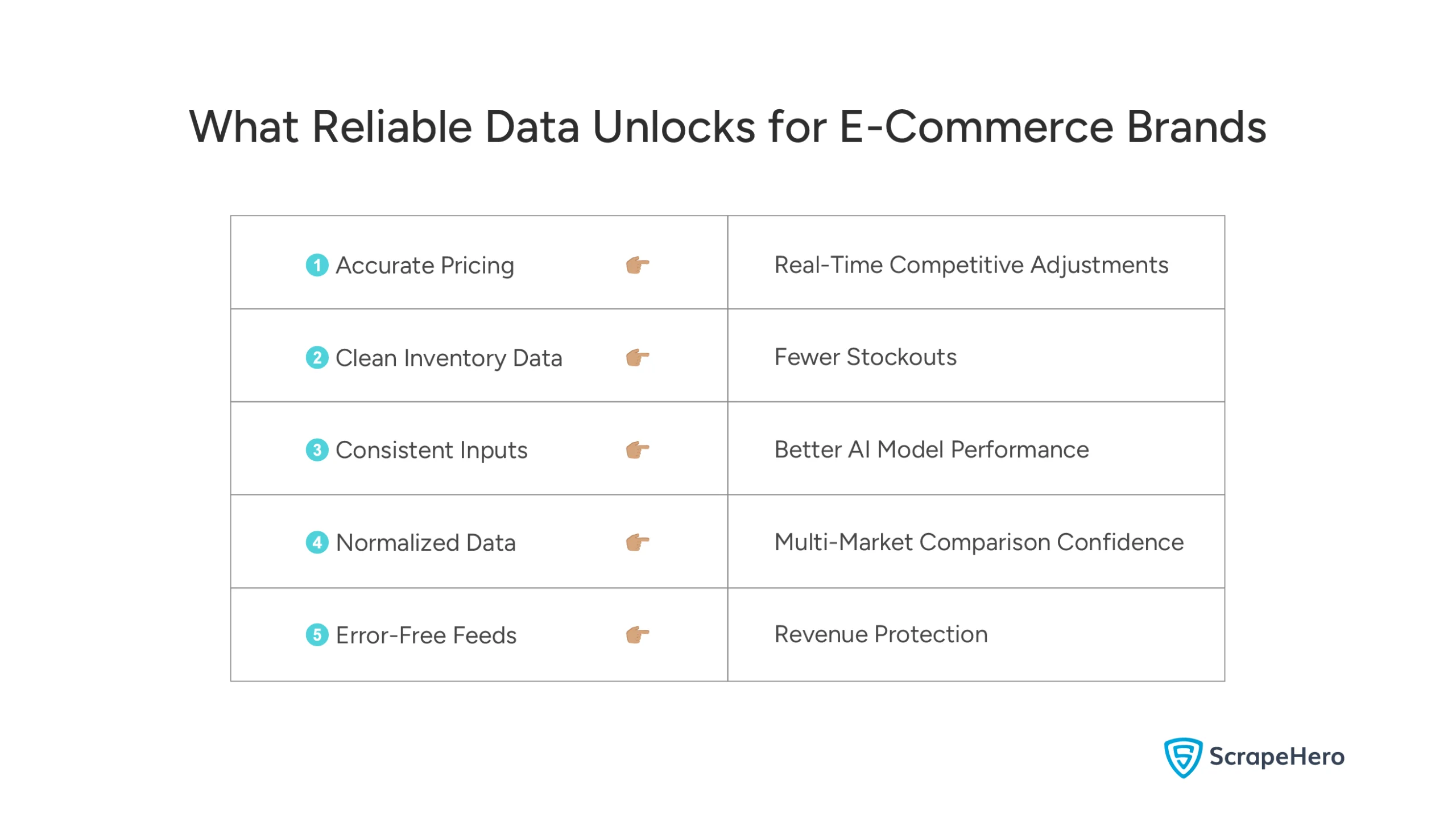
What Reliable Data Actually Unlocks for Your Business
When your data is trustworthy, everything downstream gets easier.
You can adjust pricing in real time without second-guessing the numbers. You can avoid stockouts without overstocking because your inventory data actually reflects reality. You can monitor competitors with confidence and respond to market shifts before they hit your bottom line — not after.
Here’s the thing most people get wrong about data: more isn’t better. Reliability is better.
The brands winning in e-commerce right now aren’t the ones with the most data. They’re the ones with data they can actually act on. That’s the edge our commitment to data quality in web scraping is built to give you — backed by over a decade of experience and a team that treats quality as non-negotiable.
Choosing us isn’t just a decision about data extraction. It’s a decision to stop operating on assumptions. To stop second-guessing your dashboards. To start making moves backed by numbers you actually trust, with a partner that’s as invested in your outcomes as you are.
Join the Brands That Rely on ScrapeHero for Data They Can Actually Trust
From startups to Fortune 50 companies, our clients don’t settle for unreliable data. Neither should you. Let’s talk about how ScrapeHero’s web scraping service can build a data pipeline that scales with your business — without the headaches.
FAQs
Data quality is guaranteed by implementing a robust schema design, consistent data normalization, and thorough QA processes to detect errors before they impact decision-making.
We ensure high-quality data collection through custom extraction strategies, automated error detection, and continuous monitoring of data pipelines, along with manual validation to meet specific business needs.



