

Zomato’s restaurant listings depend on your selected location. Since the address bar doesn’t show any query parameters indicating locations, you can’t use a simple GET request for Zomato web scraping.
A workaround is to use browser automation libraries. They enable you to perform actions such as clicking and filling in forms.
If you’d rather skip the code, you can use ScrapeHero’s Q-commerce data scraping service.
Otherwise, read on. This article discusses how to extract Zomato data using Selenium.

How Do You Set Up the Environment for Zomato Web Scraping?
You can set up the environment to scrape Zomato by installing Selenium using pip:
pip install seleniumThe environment for Zomato data scraping also includes json, re, and time (for sleep), but these modules come pre-installed with Python.
What Data Does the Code Scrape from Zomato?
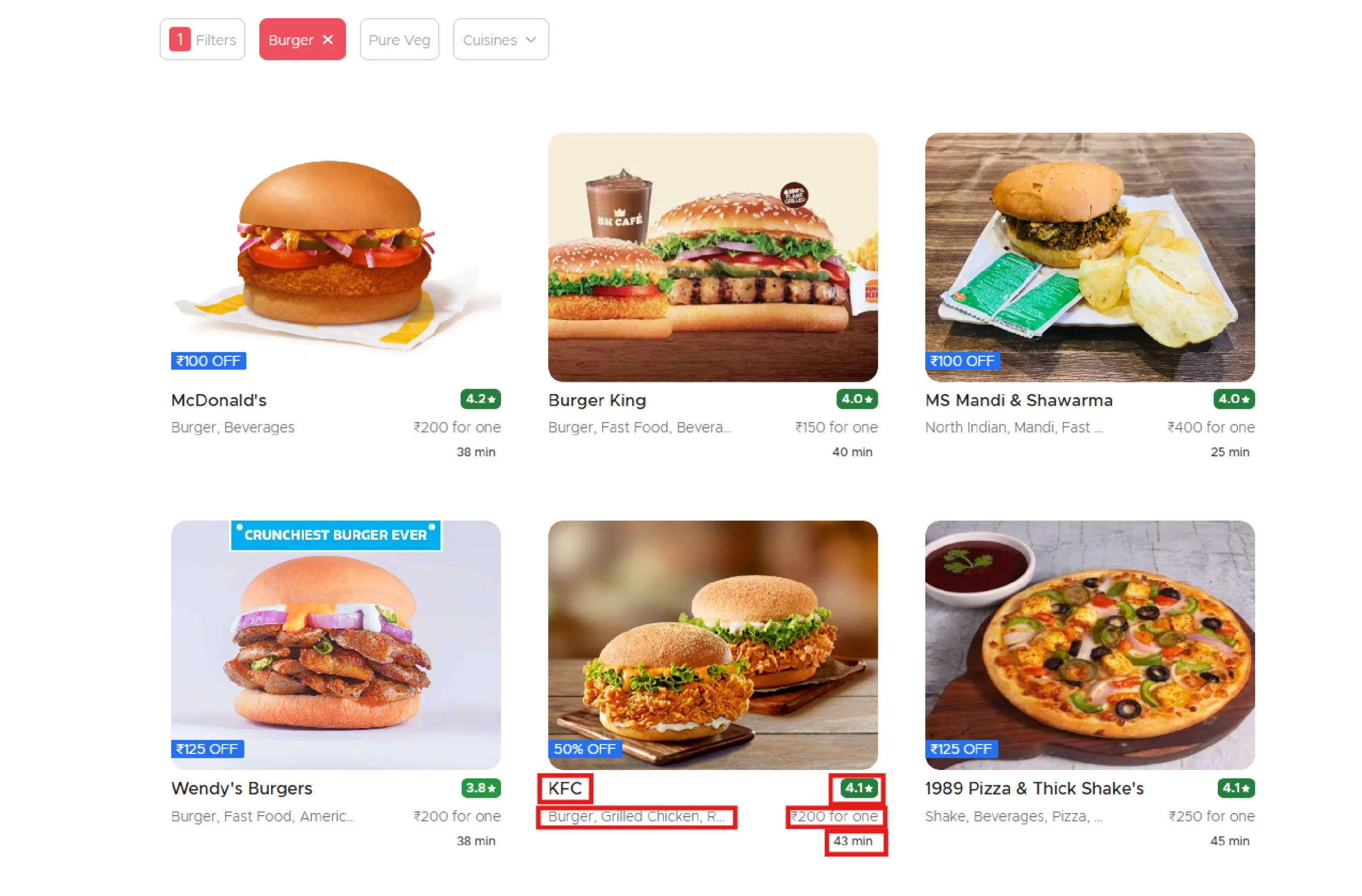
The code shown in this tutorial for Zomato data extraction using Selenium pulls five details from the search results:
- Restaurant Name
- Rating
- Cuisines Offered
- Price Estimate
- Delivery Time
How Do You Write the Code to Scrape Zomato?
Write the code for Zomato web scraping to perform these steps:
- Open Zomato’s delivery cities page
- Select a location
- Search for a dish
- Scroll through results
- Extract restaurant details
- Save results in JSON
You need six modules to perform the above steps:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from time import sleep
import json
The above code imports:
- The webdriver module to control the browser
- The By module to specify element selectors
- The Keys module to send keyboard strokes
- The sleep module to set delays between interactions
- The json module to save extracted data to a JSON file
How Do You Open Zomato’s Delivery Cities Page?
You can open the required Zomato page using the webdriver’s get method.
browser = webdriver.Chrome()
browser.get('https://www.zomato.com/delivery-cities')
How Do You Set the Location on Zomato.com?
To set the location, check if the desired city exists in the “Cities We Deliver To” section. If found, click directly. If not, enter the location in the search bar.
Upon inspecting the list, you can see that the anchor tags are inside a div that is a sibling to the h1 element containing the text “Cities We Deliver To.”
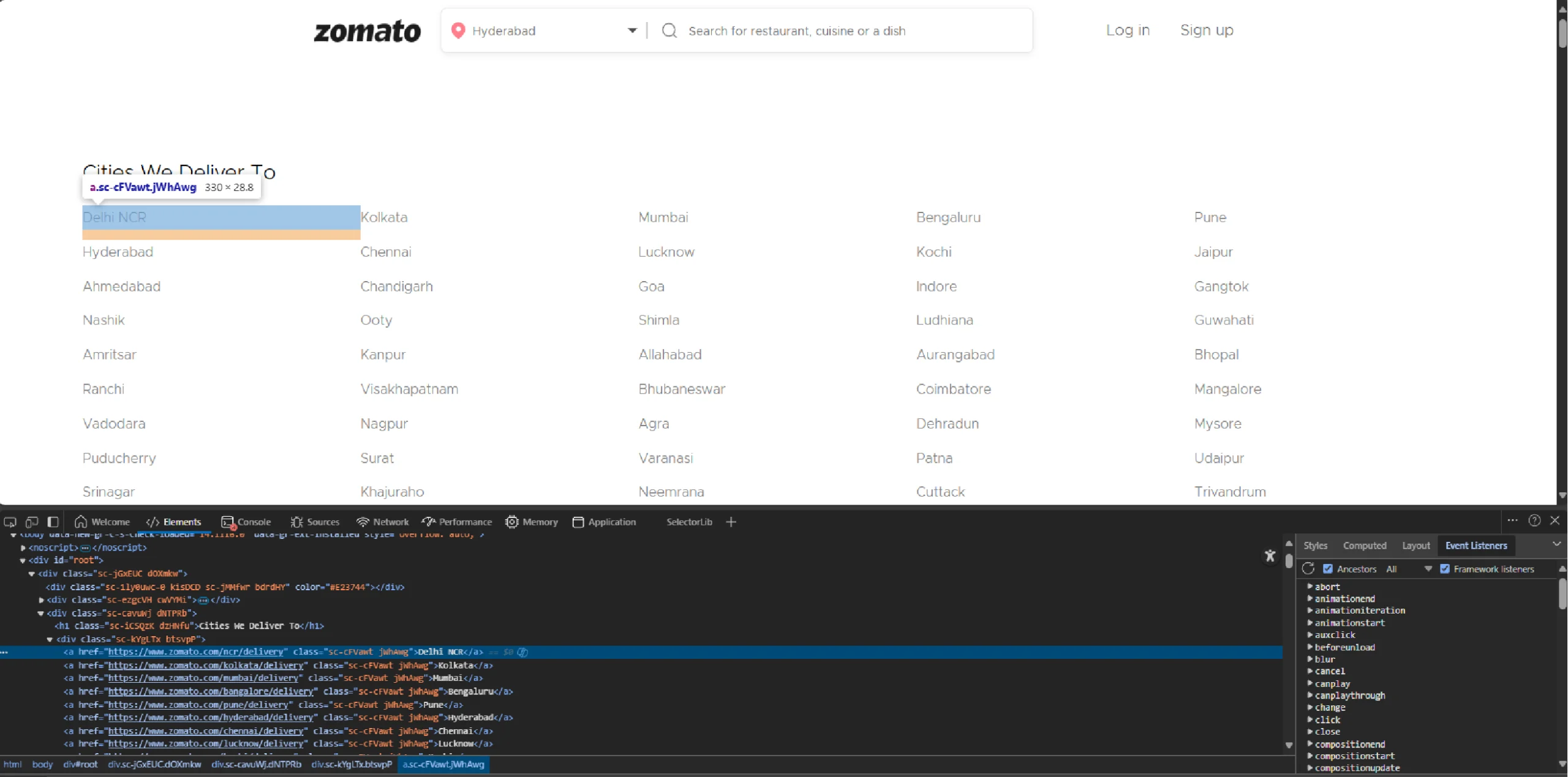
Use find_elements() to extract all these anchor tags.
cities = browser.find_elements(By.XPATH,'//h1[contains(text(),"Cities We Deliver To")]/following::div/a')
Then, iterate through the list returned by find_elements() and check if your preferred city is in it.
location = "Bengaluru"
for city in cities:
city_exists = False
if location.lower() == city.text.lower():
city_exists = True
city.click()
break
The above code uses a Boolean variable, “city_exists”, to track whether Zomato delivers to that city. The variable becomes true when the code finds the city.
If city_exists remains false, directly enter the location in the search bar.
The location input box lacks unique identifiers, but it is the only input without the placeholder ‘Search for restaurant.’
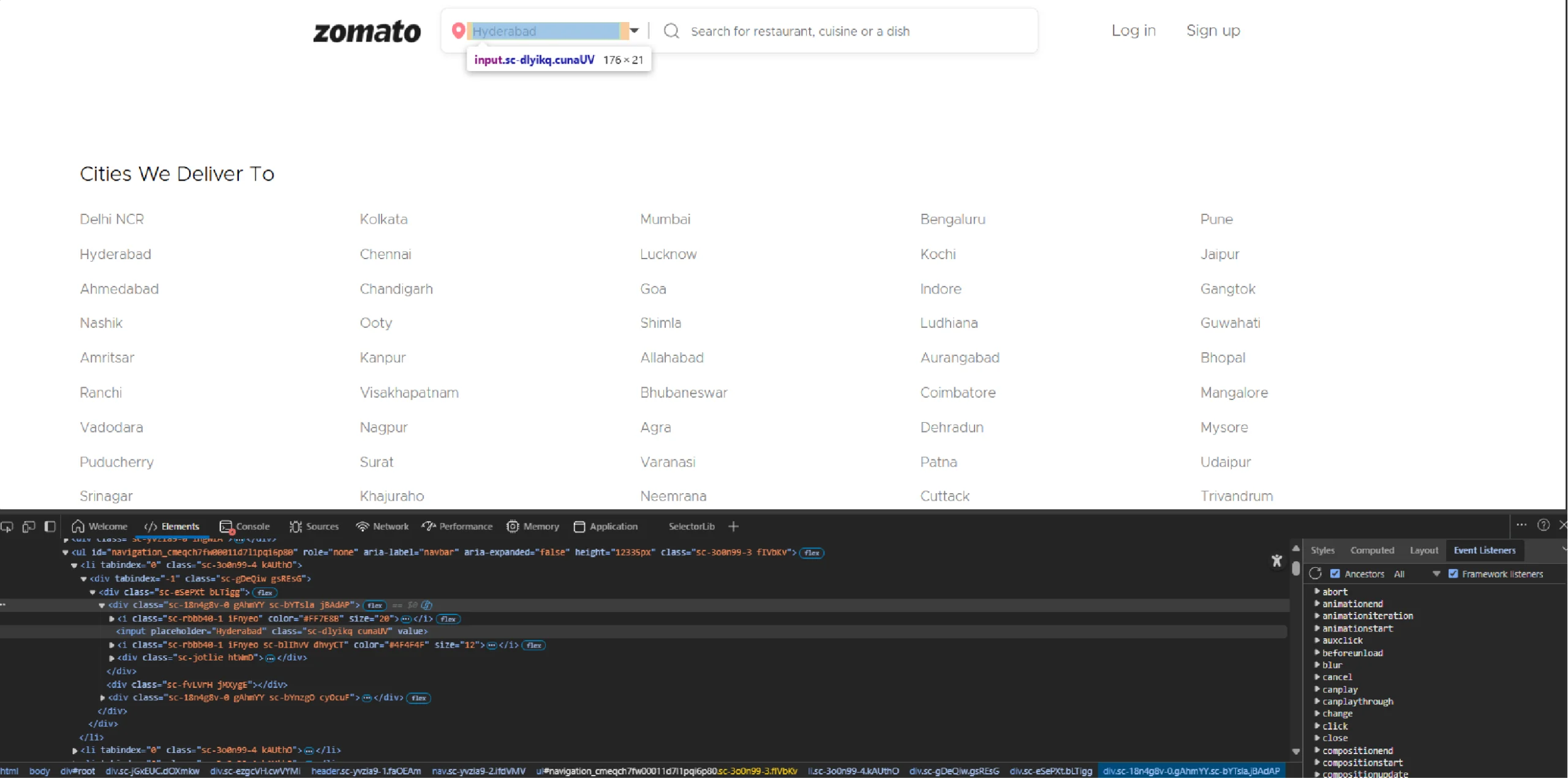
That means you can use an XPath that avoids the input box with the placeholder “Search for restaurant.”
if city_exists == False:
location_input = browser.find_element(By.XPATH,'//input[not(contains(@placeholder,"Search for restaurant"))]')
You can then use send_keys() to enter the location and click() to click on it.
location_input.send_keys(location)
sleep(3)
location_input.click()
sleep(2)
Clicking reveals a list of locations.
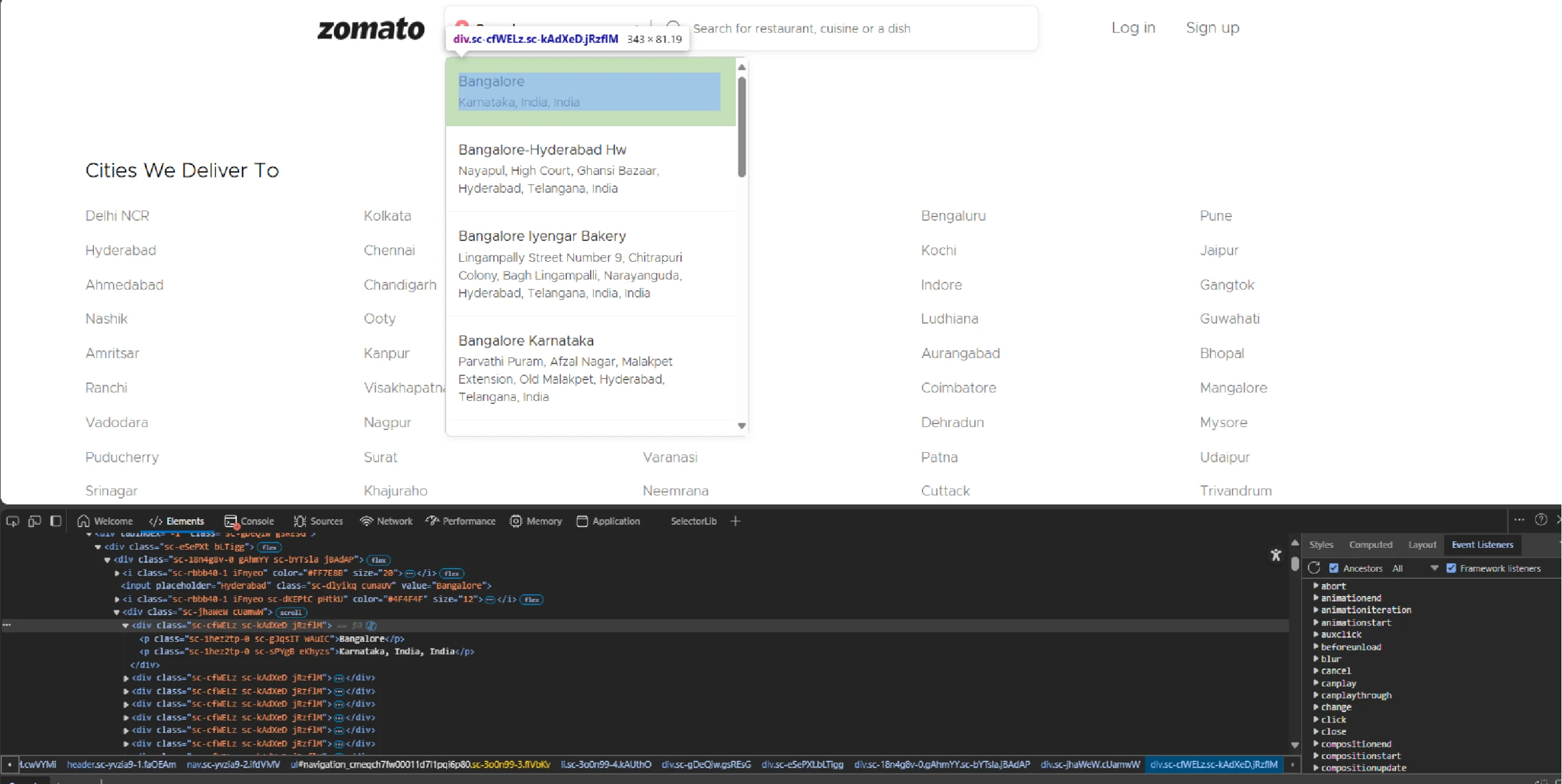
The code then selects the one matching your input.
location_item = browser.find_element(By.XPATH, f"//ul[@aria-label='navbar']//p[contains(translate(text(), 'ABCDEFGHIJKLMNOPQRSTUVWXYZ', 'abcdefghijklmnopqrstuvwxyz'),'{location.lower()}')]")
sleep(3)
location_item.click()
The above code uses the translate function in XPath to handle case sensitivity.
How Do You Search for a Dish on Zomato Using Code?
To search for a location, the code must locate the input box. Zomato’s input box for searching dishes or restaurants contains the placeholder text “Search for restaurant.”
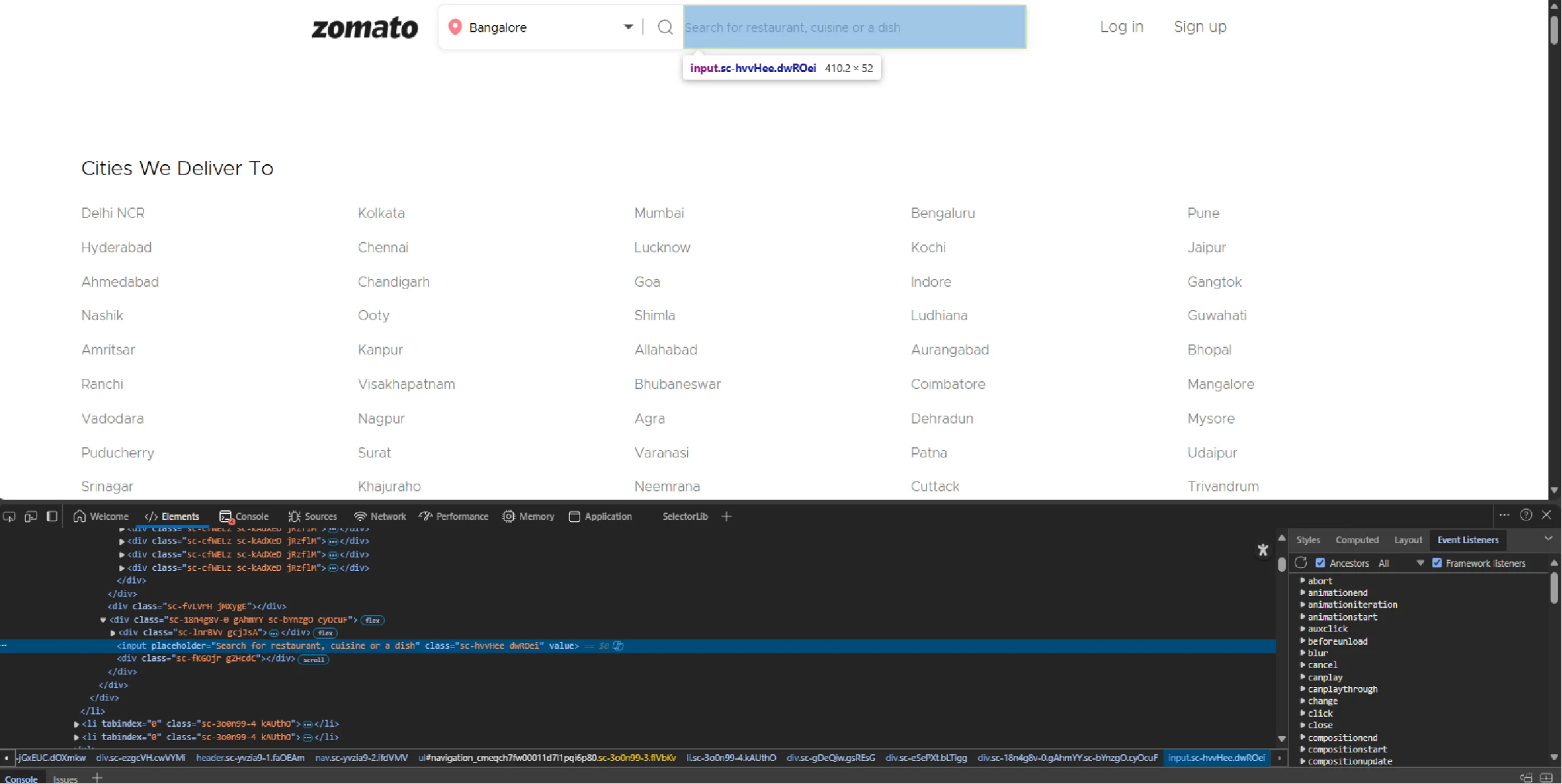
So its XPath will be “//input[contains(@placeholder), ‘Search for restaurant’]”
dish = "noodles"
search_bar = browser.find_element(By.XPATH, '//input[contains(@placeholder,"Search for restaurant")]')
search_bar.send_keys(dish)
search_bar.click()
sleep(3)
dish_item = browser.find_element(By.XPATH, f"//ul[@aria-label='navbar']//p[contains(translate(text(), 'ABCDEFGHIJKLMNOPQRSTUVWXYZ', 'abcdefghijklmnopqrstuvwxyz'),'{dish.lower()}')]")
dish_item.click()
sleep(3)
Clicking a dish from the list in the above method starts loading results. Zomato loads results dynamically, meaning you’ll need to scroll to load more elements.
How Do You Scroll Programmatically to Load More Results?
You can scroll through Zomato’s search results using Selenium’s execute_script() method.
for _ in range(5):
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);")
sleep(2)
How Do You Extract Restaurant Details from Zomato’s Search Results?
To extract restaurant details, locate each listing and extract the text from it.
Inspecting Zomato’s search results reveals they are inside div[@class=’jumbo-tracker’].
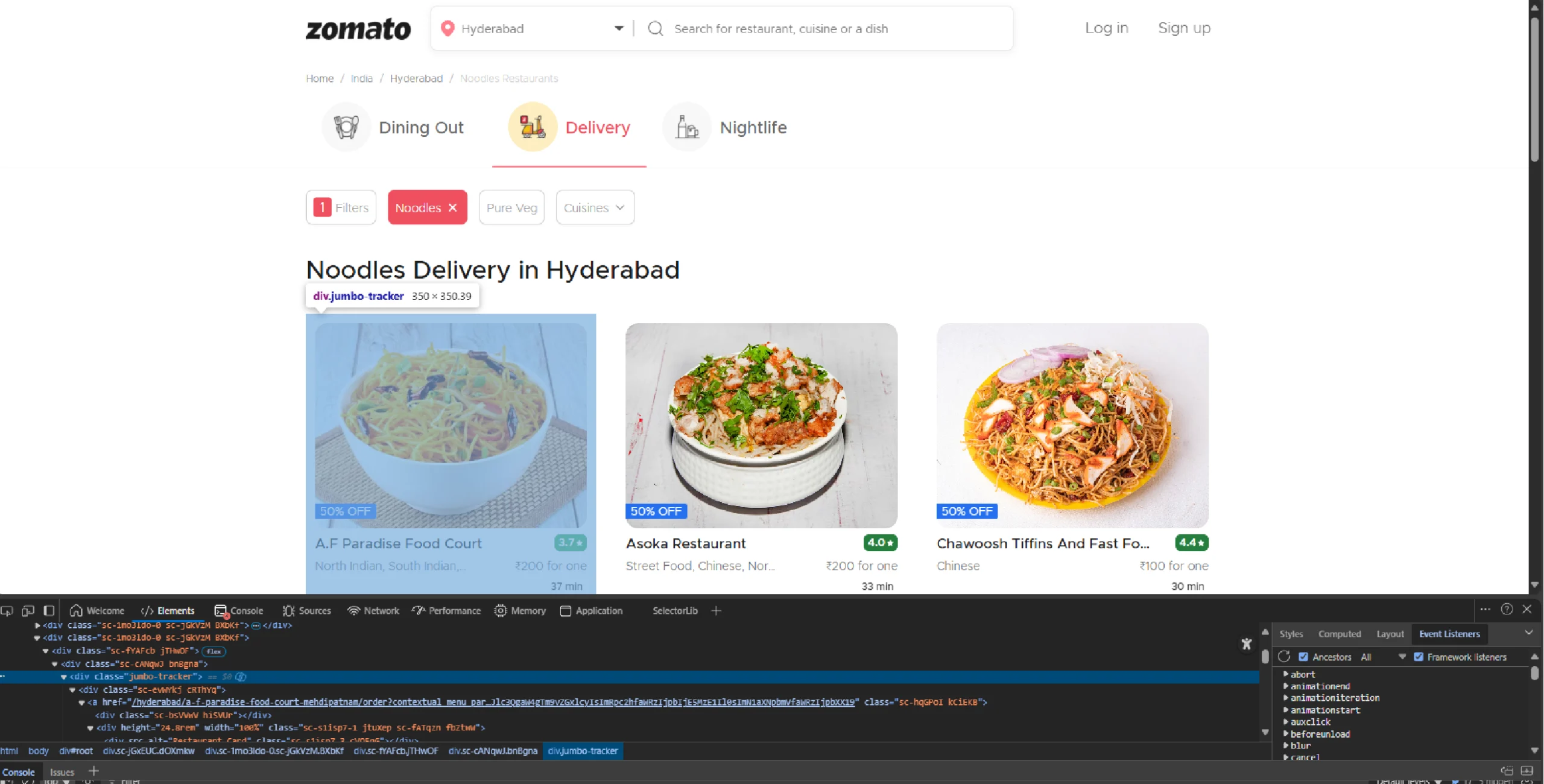
That means you can:
1. Find all the listings using find_elements(), which returns a list.
2. Create an empty list to store the details
3. Loop through the list, and in each iteration:
- Extract the text
- Split it at each newline character
- Break the loop if the array returned after splitting text has fewer than two elements
- Extract the details and store them in a dict
- Append the dict to the list created earlier
products = browser.find_elements(By.XPATH,"//div[@class='jumbo-tracker']")
product_details = []
for product in products:
details = product.text.split('\n')
if len(details) < 2:
break
n = 1 if "OFF" in details[0] else 0
product_details.append(
{
'Restaurant Name': details[n+0],
'Rating': details[n+1],
'Cuisines Offered': details[n+2],
'Price Estimate': details[n+3],
'Delivery Time': details[n+4]
}
)
The code includes a break condition because some div elements with the class “jumbo-tracker” may not represent the actual search results.
How Do You Save the Results Scraped from Zomato?
You can save the extracted data using json.dump().
with open('zomato.json','w') as f:
json.dump(product_details,f,indent=4,ensure_ascii=False)
This creates a file zomato.json with structured data like this.
{
"Restaurant Name": "Chopstix",
"Rating": "4.3",
"Cusines Offered": "Chinese, Thai, Seafood, Desserts, Beverages, Asian",
"Price Estimate": "₹400 for one",
"Delivery Time": "28 min"
}
Here’s the complete code for Zomato web scraping:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from time import sleep
import json
import re
browser = webdriver.Chrome()
browser.get('https://www.zomato.com/delivery-cities')
cities = browser.find_elements(By.XPATH,'//h1[contains(text(),"Cities We Deliver To")]/following::div/a')
location = "Bengaluru"
for city in cities:
city_exists = False
if location.lower() == city.text.lower():
city_exists = True
city.click()
break
if city_exists == False:
location_input = browser.find_element(By.XPATH,'//input[not(contains(@placeholder,"Search for restaurant"))]')
location_input.send_keys(location)
location_input.click()
sleep(3)
location_item = browser.find_element(By.XPATH, f"//ul[@aria-label='navbar']//p[contains(translate(text(), 'ABCDEFGHIJKLMNOPQRSTUVWXYZ', 'abcdefghijklmnopqrstuvwxyz'),'{location.lower()}')]")
location_item.click()
dish = "noodles"
search_bar = browser.find_element(By.XPATH, '//input[contains(@placeholder,"Search for restaurant")]')
search_bar.send_keys(dish)
search_bar.click()
sleep(3)
dish_item = browser.find_element(By.XPATH, f"//ul[@aria-label='navbar']//p[contains(translate(text(), 'ABCDEFGHIJKLMNOPQRSTUVWXYZ', 'abcdefghijklmnopqrstuvwxyz'),'{dish.lower()}')]")
dish_item.click()
for _ in range(5):
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);")
sleep(2)
products = browser.find_elements(By.XPATH,"//div[@class='jumbo-tracker']")
product_details = []
for product in products:
details = product.text.split('\n')
if len(details) < 2:
break
n = 1 if "OFF" in details[0] else 0
product_details.append(
{
'Restaurant Name': details[n+0],
'Rating': details[n+1],
'Cusines Offered': details[n+2],
'Price Estimate': details[n+3],
'Delivery Time': details[n+4]
}
)
browser.quit()
with open('zomato.json','w') as f:
json.dump(product_details,f,indent=4,ensure_ascii=False)What are the Limitations of this Zomato Scraper?
The limitations of this Zomato Scraper include:
- Fragile XPaths: If Zomato updates its HTML structure, the scraper may break because the code relies on XPaths. You then need to find new XPaths.
- Anti-bot measures: This script doesn’t handle rate limits, CAPTCHA, or IP blocking, which become more prominent when scraping on a large scale.
- Dynamic content: A heavy reliance on scrolling and waiting may miss results if network latency is high.
When Should You Use a Web Scraping Service?
The code provided in this tutorial is suitable for small-scale scraping, where anti-scraping measures are unlikely to be triggered. However, for large-scale projects, outsourcing to a web scraping service would be a better choice.
A web scraping service like ScrapeHero can handle all the technicalities, including handling anti-scraping measures and HTML changes.
ScrapeHero is an enterprise-grade web scraping service provider. We handle everything from extraction to delivery. Connect with ScrapeHero. Let us help you focus more on using data instead of extracting it.



