
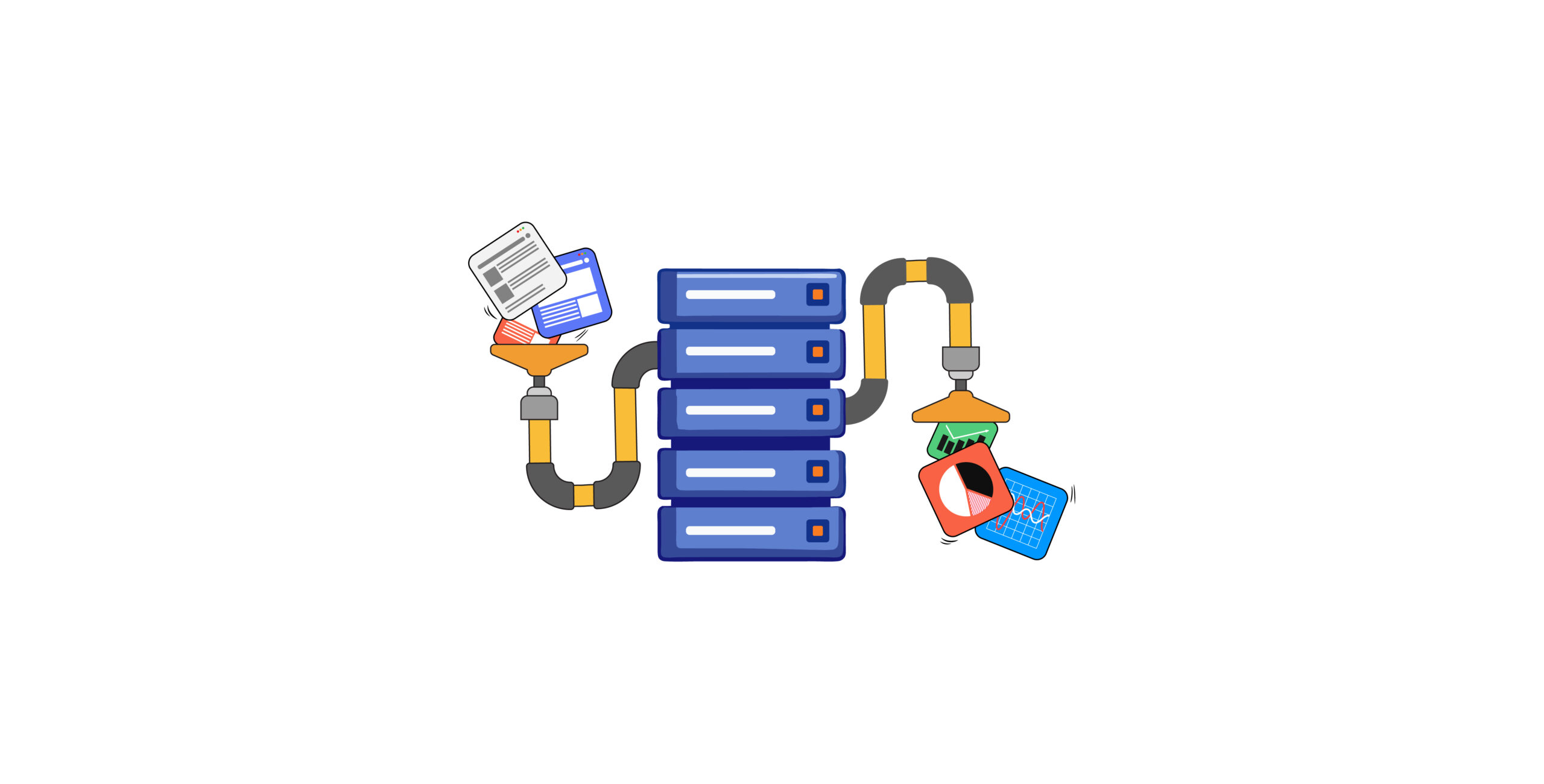
Web scraping is just one method for collecting data; others include APIs and IoT devices. However, gathering data is only the first step. To get insights, you need to perform several other steps, making a data pipeline essential. But what is a data pipeline?
Read on to learn about data pipelines, including their components, types, benefits, and real-world applications.
What is a Data Pipeline?
A data pipeline constitutes a series of steps to prepare enterprise data for analysis.
It generally involves
- Extracting data from various sources
- Transforming it into a usable format
- Loading it into a data storage system
- Analyzing data to derive insights
- Delivering the insights to end users
The second and third steps may switch positions as it’s also possible to load the data into a data storage system before transforming it.
Primary Elements of a Data Pipeline
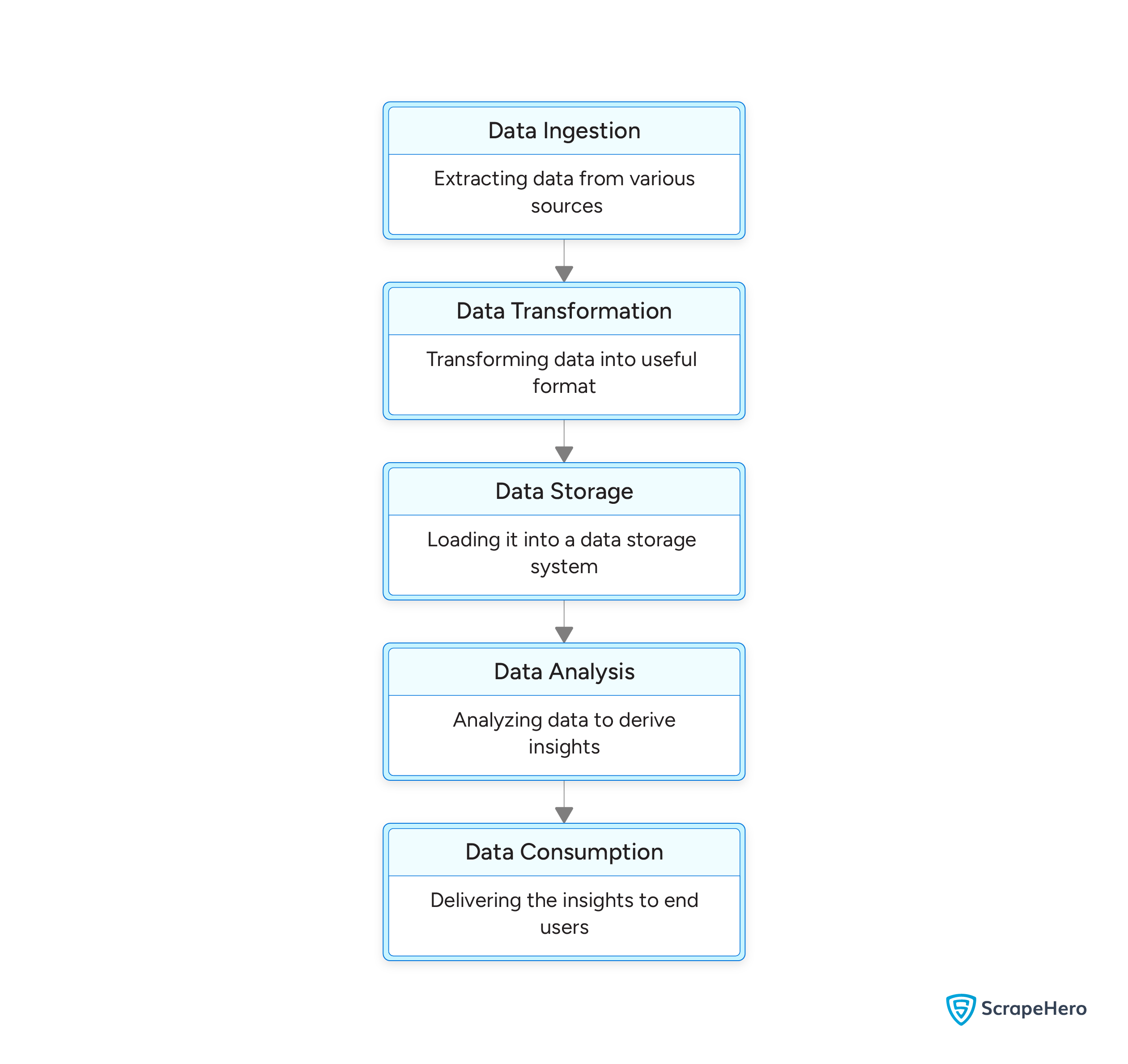
Data Ingestion
Data ingestion refers to collecting data from various sources, including
- Websites: Pipelines can get data from websites. You can get data using either APIs or web scraping.
- IoT devices: IoT devices can also provide a large amount of data. There are various methods to get data from IoT devices, but the most common method is to use an API.
This step may involve real-time data streaming or scheduled batch uploads. Batch uploads are more suitable when collecting data from websites, as you need to make periodic requests. However, IoT devices can send data in real time, making streaming preferable.
You can learn about batch processing and streaming below.
Data Transformation
Data pipeline steps after web scraping begins with data transformation. Data transformation makes data appropriate for analysis. This step performs
- Aggregation: Collecting data from multiple sources into a single format.
- Normalization: Removing duplicates and inconsistencies
- Data Cleaning: Removing irrelevant or corrupt data
- Generalization: Grouping individual data points based on the similarity
- Discretization: Making continuous data discrete
Data transformation maintains data quality and consistency across the organization.
Data Storage
In this step, data gets stored in an appropriate destination, such as
- Data warehouses: A data warehouse offers structured data storage. It is primarily used during standard data analysis.
- Data lakes: Data lakes can store any type of data and are more suitable for big data analytics as they support unstructured data.
Learn more about data storage in the article “Data Storage and Management”
This ensures data availability for analysis and reporting.
Data Analysis
Data analysis involves using various statistical and machine-learning techniques to derive insights.
Its techniques include
- Clustering: Grouping together data based on similarities of their various features represented as numbers, such as segmenting customers based on purchase patterns.
- Classification: Labeling data based on specific characteristics, such as classifying a set of images based on whether or not they are handwritten.
- Regression: Predicting a continuous variable based on input variables, such as predicting the salary of a person based on experience and education level.
Data Consumption
In this step, the insights are delivered to the end users via methods like
- Dashboards: Representing the results of the analysis in an app or a web page that updates when the results change
- Reports: Sending the results as static files, including PDFs and images
ETL vs ELT
You must have noticed in the above-mentioned elements of the data pipeline that data transformation comes before data storage. However, their order may differ, and it is better illustrated with the acronyms ETL and ELT.
ETL and ELT are two processes that highlight the main three stages of a data pipeline. ETL stands for Extract, Transform, and Load, while ELT stands for Extract, Load, and Transform.
In ETL, data transformation comes before data storage; in ETL, data storage comes after data transformation.
Learn more about these operations (Extract, Transform, and Load) in the article on web scraping and ETL.
Types of Data Pipelines
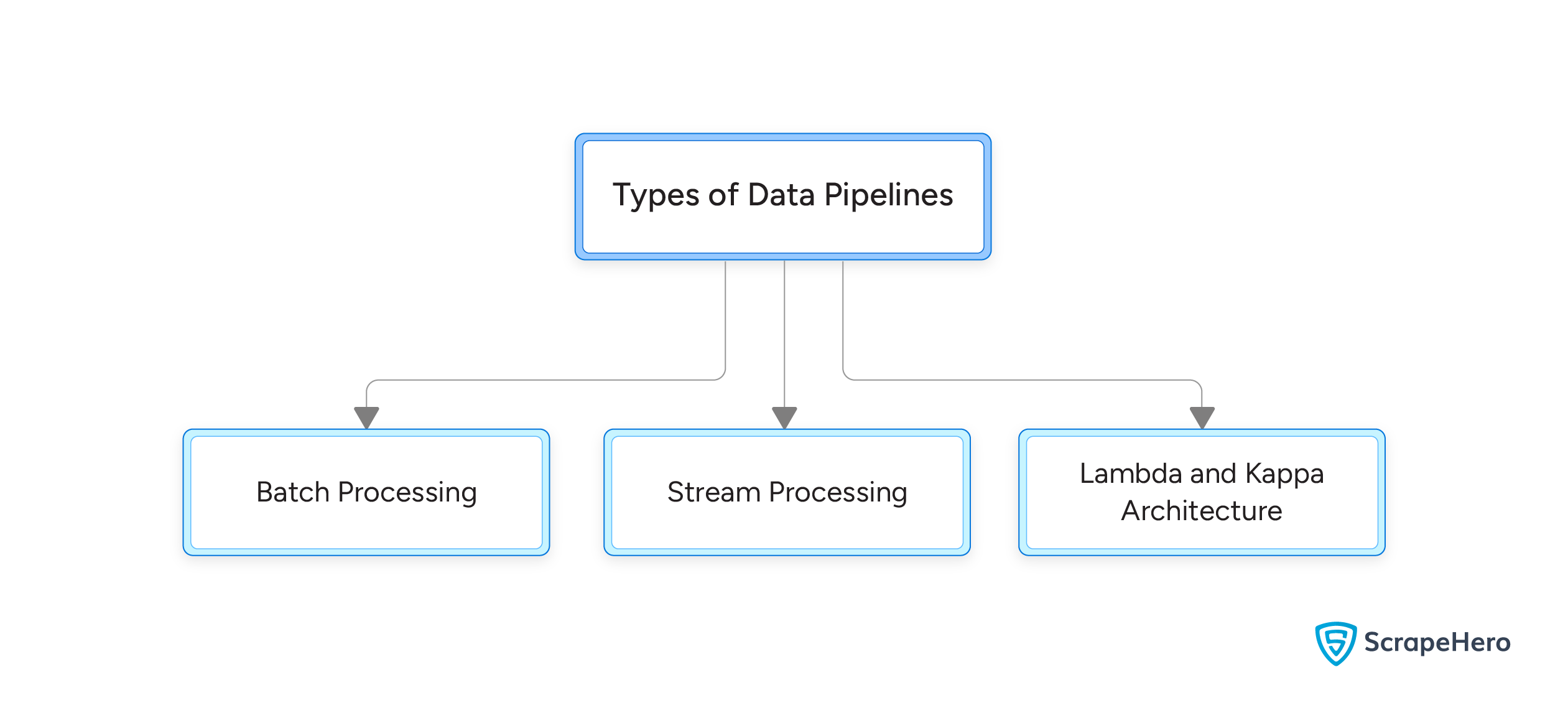
Batch Processing
Batch processing pipelines handle large volumes of data collected over a specific period. For example, a retail company may analyze sales data collected daily or weekly. Batch processing usually uses reports to deliver the results to end users.
Stream Processing
Stream processing pipelines handle continuous data flows in real time. For instance, social media platforms analyze user interactions to provide instant feedback and insights. Because of their dynamic nature, dashboards are more suitable for stream processing.
Lambda and Kappa Architectures
- Lambda Architecture combines batch and stream processing, allowing for both real-time and historical data analysis.
- Kappa Architecture simplifies Lambda architecture by considering both real-time and historical data as streams.
Benefits of Data Pipelines
Now that you can answer the question, ‘what is a data pipeline?,’ let’s explore some of its benefits.
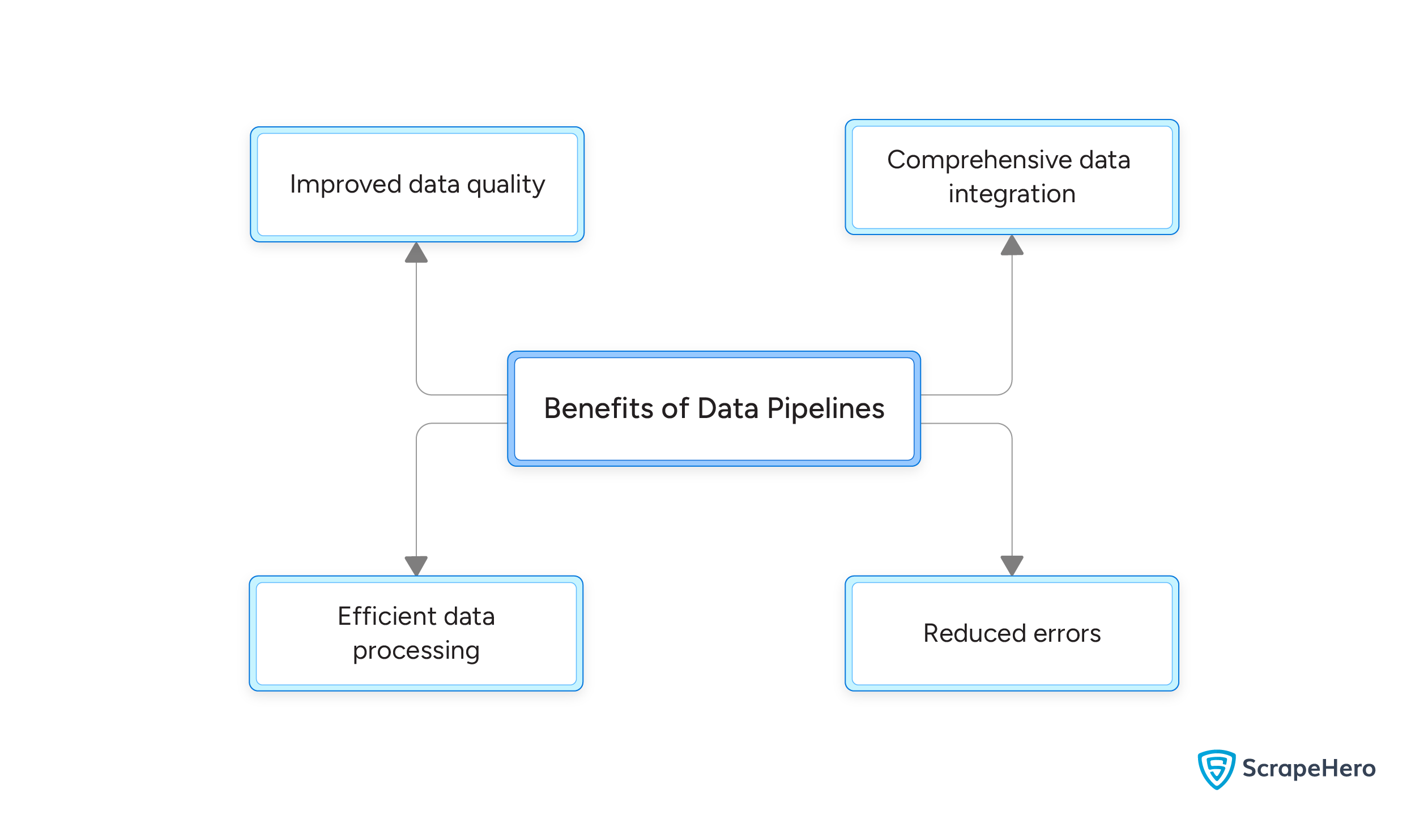
Improved Data Quality
Data pipelines ensure high-quality data by cleaning and refining raw data, ensuring it is accurate and consistent for end users.
Efficient Data Processing
Automating data transformation tasks allows data engineers to focus on deriving insights rather than repetitive tasks, thus improving overall efficiency.
Reduced Errors
Automation, standardization, and consistency provided by data pipelines reduce errors that are possible due to human intervention.
Comprehensive Data Integration
Data pipelines facilitate the integration of data from disparate sources, creating a unified view to improve decision-making processes.
Real-World Applications
Finally, understanding its use cases is essential for answering the question, ‘What is a data pipeline?’
Here are some areas where data pipelines are used significantly.
- E-commerce: Companies like Amazon use data pipelines to manage vast amounts of customer data, transaction logs, and inventory information in real-time, enabling personalized shopping experiences.
- Finance: Financial institutions leverage data pipelines for real-time fraud detection and risk analysis, ensuring secure transactions.
- Healthcare: Hospitals utilize data pipelines to process and analyze patient records and sensor data, improving diagnostics and patient care.
- Machine Learning: Machine learning requires a large amount of training data, making data pipelines necessary.
- Social Media: Social media sites use data pipelines to collect and analyze user interactions to improve user experience.
How Can ScrapeHero’s Web Scraping Service Help?
In conclusion, a data pipeline significantly improves the efficiency of data analysis, from data collection to insight delivery. The first step to creating a robust data pipeline is to determine your data sources, and web scraping is an effective method to acquire large volumes of data.
ScrapeHero’s web scraping service can help you with that.
ScrapeHero is a fully managed web scraping service provider. We can build high-quality, enterprise-grade web scrapers and crawlers customized to integrate with your data pipeline seamlessly.
We can help with your data or automation needs
Turn the Internet into meaningful, structured and usable data



