

Your data pipeline looks fine on the screen. However, there’s a hidden problem under those clean dashboards: web scraping downtime. It’s a constant drain on resources that most companies ignore.
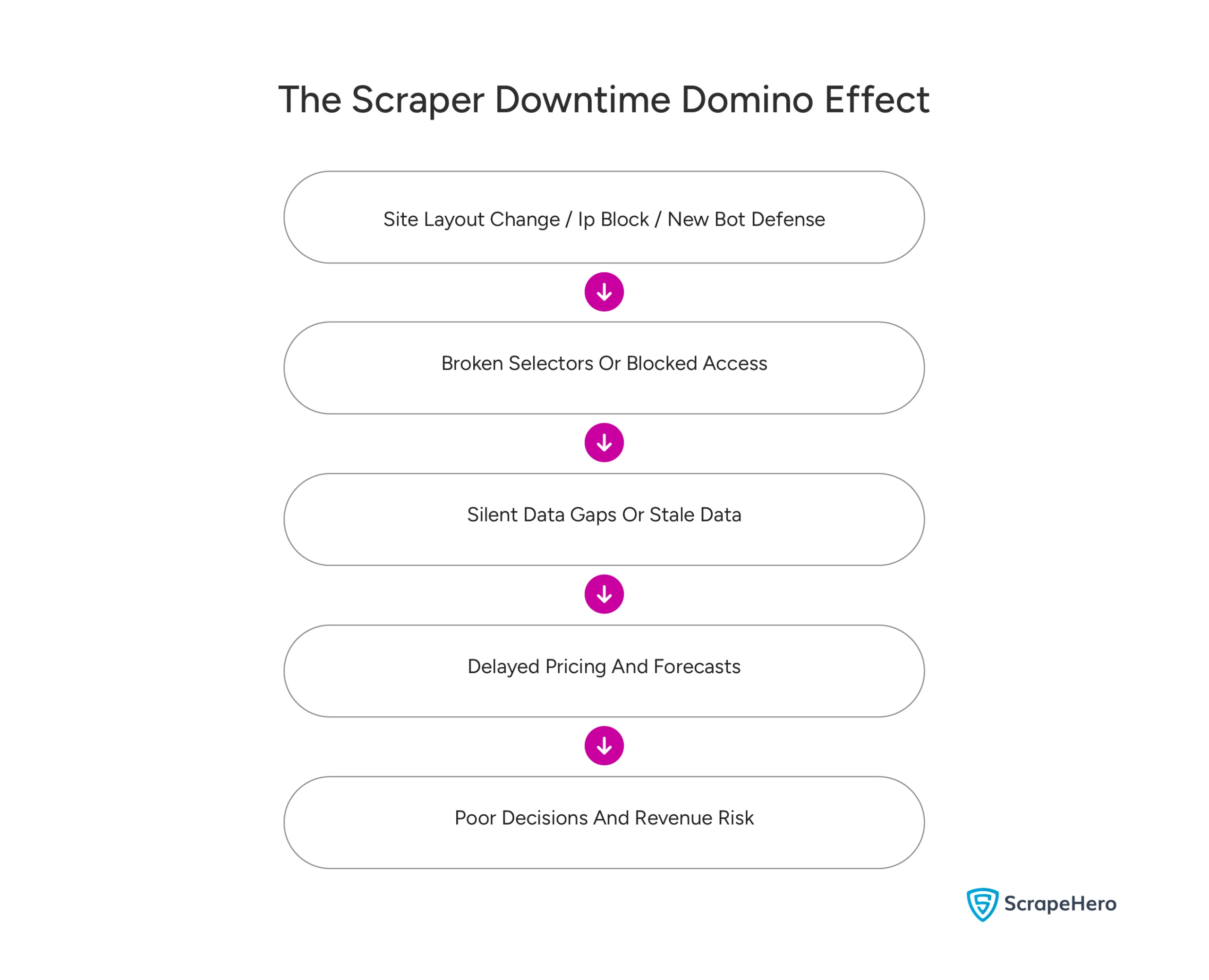
When a target website alters its structure, blocks your IP range, or enhances its bot defenses, your entire data extraction setup breaks. The immediate result is a halted data flow, which triggers team panic, delays critical decisions, and ultimately increases revenue risk.
For companies that depend on web data for pricing, competitor tracking, or market signals, these small failures add up fast. In fact, what starts as a “minor glitch” becomes missed insights, late forecasts, and hours of manual cleanup.

The primary costs and risks of web scraping lie in ongoing maintenance, not in initial development. Yet, this burden is often overlooked. It consumes significant budget and engineering resources by diverting them from strategic projects. At the same time, it quietly increases infrastructure costs and exposes the business to data-quality failures.
Let’s examine where these hidden costs come from, what downtime truly costs your business, and why outsourcing web scraping makes better business sense.

Understanding Scraper Downtime and Its Causes
Your biggest challenge isn’t getting data once. It’s collecting it reliably on a massive scale every day. However, achieving this reliability comes down to solving four persistent challenges.
- The Instability of Web Data Sources
- The Unpredictability of Modern Blocking
- The Unsustainable Cost of Scale
- The Toll on Team Productivity
1. The Instability of Web Data Sources
Websites change constantly, shifting layouts and moving HTML elements. These updates, even minor ones, break the selectors that drive extraction and cause silent failures. Pipelines continue to run, but they deliver empty or outdated data. By the time the problem is noticed, inaccurate information has already compromised business reports.
2. The Unpredictability of Modern Blocking
Blocking adds another critical layer of instability. IP bans can happen instantly, CAPTCHA walls appear without warning, and TLS fingerprinting can identify bots in a flash. What functioned yesterday often fails today, forcing engineers to spend hours rotating proxies and tuning headless browsers merely to maintain a basic connection.
3. The Unsustainable Cost of Scale
Moreover, the problem intensifies with scale. As demand grows from thousands to millions of URLs, the infrastructure becomes both fragile and prohibitively expensive. Headless browsers consume massive computing power, and aggressive retry logic multiplies cloud costs.
4. The Toll on Team Productivity
Ultimately, your team pays the price. Data engineers are trapped fighting broken jobs instead of building valuable analytics or systems. This constant firefighting lowers their output, crashes morale, and drives talented people away. Understanding how scraper downtime affects businesses is crucial for leadership to recognize the actual operational burden.
The True Cost of Maintenance
- Downtime is a Direct Threat to Revenue
- The Hidden Annual Expenses
- The Financial Penalty of Bad Data
The huge costs start after launch, not on day one. In fact, industry studies show that 50 to 80 percent of total software cost happens during maintenance. Web scraping feels this pain even more acutely because your pipelines operate in a space you don’t control. Every site redesign, new anti-bot rule, or traffic surge forces updates. As a result, a project that looked like a one-time task becomes a permanent maintenance job.
Downtime is a Direct Threat to Revenue
When scrapers break, your business goes blind. Global 2000 companies lose over $400 billion annually due to system downtime. 90% of medium and large organizations lose upwards of $300,000 during a 1-hour data disruption. Data scraping downtime losses can quickly cascade, affecting pricing moves, inventory updates, and competitive responses.
The Hidden Annual Expenses
Beyond engineer salaries, you pay for proxy networks, CAPTCHA solvers, headless browsers, monitoring tools, and infrastructure scaling. Typically, annual operating costs range from $50,000 to $100,000 for many in-house teams. These recurring bills appear quietly in tech budgets, rarely marked as scraping expenses.
The Financial Penalty of Bad Data
Failure isn’t always obvious. Sometimes, scrapers might run but return incomplete or stale data. Gartner estimates that poor data quality costs organizations an average of $12.9 million per year. When flawed data hits dashboards, leadership decisions suffer, sales forecasts drift, pricing models misfire, and marketing budgets get wasted.
In short, the real cost of scraping isn’t development. It’s constant maintenance, exposure to web scraping downtime, and the invisible risk of bad data.
The Human Cost of Maintenance
- Salary Burn with Zero Strategic Return
- Burnout from Constant Reactive Work
- Growth Work Gets Pushed Aside
Your data engineers aren’t building value most of the week. Monte Carlo Data reports that engineers spend 40 percent of their time fighting broken feeds and reprocessing missing data. That’s two full working days lost every week to upkeep.
Salary Burn with Zero Strategic Return
When 40 percent of a senior engineer’s salary goes to recovery and maintenance, that’s wasted money with no new features, products, or insights. You’re paying premium rates for cleanup work.
Burnout from Constant Reactive Work
A constant cycle of maintenance forces data teams into a purely reactive mode. Engineers who signed up to build systems end up babysitting fragile pipelines. Naturally, job satisfaction drops fast.
Growth Work Gets Pushed Aside
Every hour spent fixing breaks is time away from forecasting models, AI projects, or key business analytics. The cost isn’t just operational; it’s the cost of missed innovation. Your team stays busy, but your company stops moving forward.
The Battle for Data Access
- Modern defenses go far past simple IP bans
- Headless Browsers Drive Up Costs
Over 51 percent of global web traffic comes from automated bots. Consequently, every serious website now uses strong detection systems built to block automated access like yours.
Modern defenses go far past simple IP bans
Sites scan TLS fingerprints, browser consistency, mouse patterns, and session behavior to instantly spot automation. Even with rotating proxies, basic scripts get flagged immediately. What worked last quarter barely functions today. These enterprise data scraping challenges grow more sophisticated as anti-bot technologies evolve.
Headless Browsers Drive Up Costs
To look human, your team must run headless browsers like Playwright or Puppeteer that fully mimic user actions. Unfortunately, these tools multiply infrastructure needs and compute usage.
Every new detection method demands changes to scraping rules, browser setups, proxy plans, and scaling models. This isn’t a one-time project. It’s an ongoing war where standing still means losing access to data.
Choose a Managed Web Scraping Service
As a business leader, your main goal is continuity. A managed scraping service guarantees it. Dedicated operations teams monitor jobs 24/7, react instantly to layout changes and blocks, and validate every data delivery before it reaches your systems. Your decision dashboards stay live, even when target sites update overnight.
- Predictable Costs and Controlled Risk
- Battle-Tested Infrastructure at Scale
- Data Quality You Can Trust
- Move Talent Back to Growth
Predictable Costs and Controlled Risk
In-house scraping becomes open-ended spending. Infrastructure spikes, emergency fixes, and proxy overages quietly push budgets around $100,000 annually. In contrast, managed services replace this with fixed, clear pricing tied to volume rather than chaos. You gain stable financials while transferring downtime risk to a provider built to handle it.
Battle-Tested Infrastructure at Scale
Web Scraping Providers invest in bypass systems your internal team can’t afford to build or maintain: dynamic TLS fingerprint rotation, residential proxy pools, browser behavior simulation, automated retry setups, and traffic shaping. These defenses serve hundreds of clients daily and adapt to new blocks faster than any single team could. Ultimately, you benefit from shared knowledge without having to build the tech yourself.
Data Quality You Can Trust
Managed services implement checks for freshness, completeness, and accuracy before delivery. This protects you from the consequences of bad data. Your leadership receives decision-ready data, not fragile feeds that silently decay.
Move Talent Back to Growth
Instead of wasting 40 percent of engineers’ time on maintenance fixes, a managed solution frees that talent for analytics, AI projects, and revenue-generating systems. Your workforce moves from protecting assets to creating value.
Overall, a managed service turns scraping from a fragile job into a reliable data channel that scales with your ambition, not your technical headaches.

How ScrapeHero Solves the Maintenance Problem
- Proactive Maintenance, Not Reactive Fixes
- The Advantage of Advanced Anti-Blocking.
- Quality-Assured, Business-Ready Data
- A Dedicated Team
The managed web scraping service of ScrapeHero enables large, always-on data operations from day one. You get a production-grade system that processes millions of URLs daily across difficult target sites without downtime surprises. Our systems are constantly tuned for speed, stability, and scale.
Proactive Maintenance, Not Reactive Fixes
Unlike internal teams that only react after failures, ScrapeHero fixes things before they break. We monitor site changes in real time, update broken selectors immediately, dynamically rotate proxy plans, and adjust rendering flows before issues spread. This keeps data delivery smooth and eliminates reactive maintenance from your workload.
The Advantage of Advanced Anti-Blocking.
Your projects are protected by a complete anti-blocking stack, including:
- Global proxy networks using residential and mobile IPs
- Modern TLS fingerprint rotation to avoid detection
- Human-behavior browser simulation via Playwright and Puppeteer
- Automated CAPTCHA-solving flows
- Adaptive retry orchestration for maximum reliability
Quality-Assured, Business-Ready Data
Every dataset passes validation checks for completeness, freshness, schema consistency, and anomaly detection before delivery. You get clean, analysis-ready data you can immediately feed into pricing systems, analytics stacks, or AI pipelines with full confidence.
A Dedicated Team
ScrapeHero assigns an expert data team to your account, who manages end-to-end extraction performance and accuracy. Your business receives clear Service Level Agreements (SLAs), firm delivery schedules, and quick escalation support. You will get End-to-end visibility with proactive alerts.
In essence, ScrapeHero handles your entire web data pipeline, letting your team focus on strategic growth instead of technical cleanup.
Final Thoughts
Your business relies on accurate, timely web data, but the reality of maintaining scrapers in-house quietly drains budgets and diverts engineering talent. While building a scraper is straightforward, ensuring its reliability at scale is a constant battle against site changes and anti-bot defenses.
This forces teams to spend more time fixing pipelines than leveraging data, leading to higher costs and stalled innovation. The web scraper failure impact extends beyond immediate technical problems to affect strategic decision-making and competitive positioning.
Fortunately, a managed web scraping service eliminates this burden by guaranteeing reliability, stabilizing costs, and maintaining high data quality. This allows your engineers to finally shift their focus from endless repairs to driving growth.
Contact ScrapeHero to gain access to dependable, enterprise-grade data—without the maintenance headache caused by web scraping downtime.
FAQs
Large enterprises can lose hundreds of thousands to millions of dollars annually due to data downtime, driven by missed revenue, delayed pricing actions, and manual recovery efforts.
Downtime disrupts data flows, delays insights, and forces teams into manual work. This leads to slower decisions, higher operational costs, and increased risk across pricing, inventory, and strategy.
Downtime refers to periods when systems, data pipelines, or tools are unavailable or unreliable. In data-driven businesses, it means operating with blind spots instead of real-time signals.



