

Scraping data from websites like Zepto can be complex due to the dynamic nature of their web content. Tools like Selenium make this easier by automating browsers to extract required data efficiently. This tutorial explains how to scrape Zepto data using Selenium.
Want to skip coding entirely? Check out ScrapeHero’s Q-commerce data scraping service.

Scrape Zepto Data: The Environment
This tutorial uses Selenium for web scraping. However, you need to install it using PIP as it is an external Python library.
pip install selenium
The code also uses two other modules: json and time. However, these come pre-installed with Python, so no action is required.
Scrape Zepto Data: The Data Points Extracted
The code shown in this tutorial scrapes these seven data points:
- Product Name
- Price
- Discount
- Premium Tag
- Amount
- Ratings and Reviews
- Delivery Time
To identify the XPaths for these data points:
- Open the Zepto website
- Use the Inspect tool (right-click → Inspect)
- Navigate through the HTML elements.
This helps determine the correct XPath expressions. For instance, inspecting the “Select Location” text tells you that it is a button element with the aria-label attribute “Select Location.”
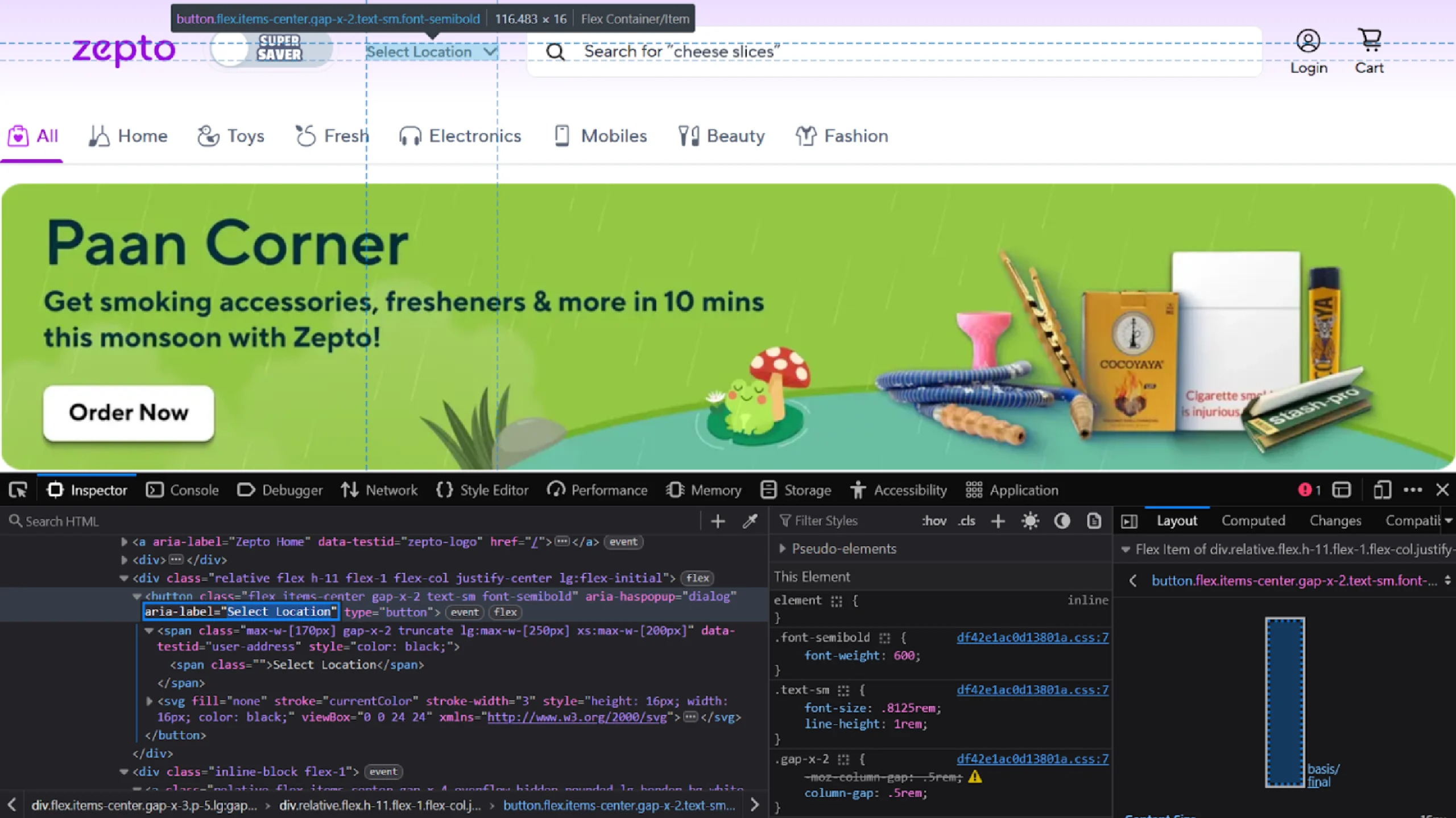
That means its XPath would be ‘//button[@aria-label=”Select Location”].’
Scrape Zepto Data: The Code
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import json
from time import sleep
This code imports
- webdriver module to control the Selenium browser
- By module to identify the HTML elements
- Keys to interact with the web page using keys such as Enter and End.
- WebDriverWait and expected_conditions to check for the presence of a specific element
- json to save the data to a JSON file
- sleep to delay script execution
Next, launch Selenium Chrome and open Zepto’s search results for “bread.”
driver = webdriver.Chrome()
driver.get('https://www.zeptonow.com/search?query=bread')
sleep(2)
Here, the sleep function ensures the page fully loads; use the function whenever you expect the webpage elements to change.
Once the page loads, select the Select Location button by using its XPath with the find_element() method. Then, use the click() method to click on it.
location_button = driver.find_element(By.XPATH,'//button[@aria-label="Select Location"]')
location_button.click()
sleep(3)
Clicking on the button will open a window with an input box. Inspecting the box will reveal that it is an input element with the placeholder attribute set to “Search a new address.”
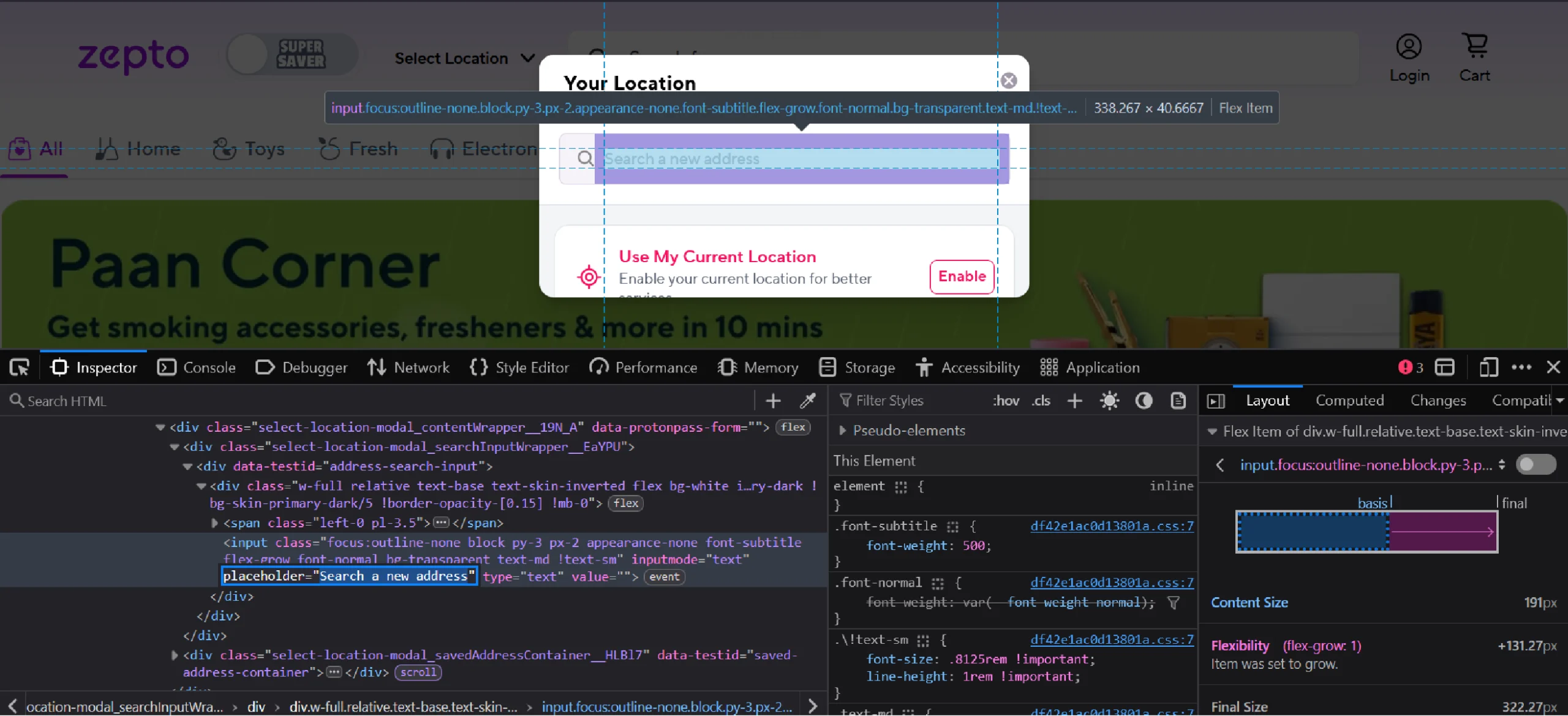
So use the XPath “//input[@placeholder= ‘Search a new address’]” with find_element() to select the input box and use send_keys() to enter a PIN.
location_input = driver.find_element(By.XPATH,"//input[@placeholder='Search a new address']")
location_input.send_keys("560004")
sleep(4)
Entering the PIN will list a number of locations. Inspecting the topmost one shows that it has a data-testid attribute ‘address-search-item’.
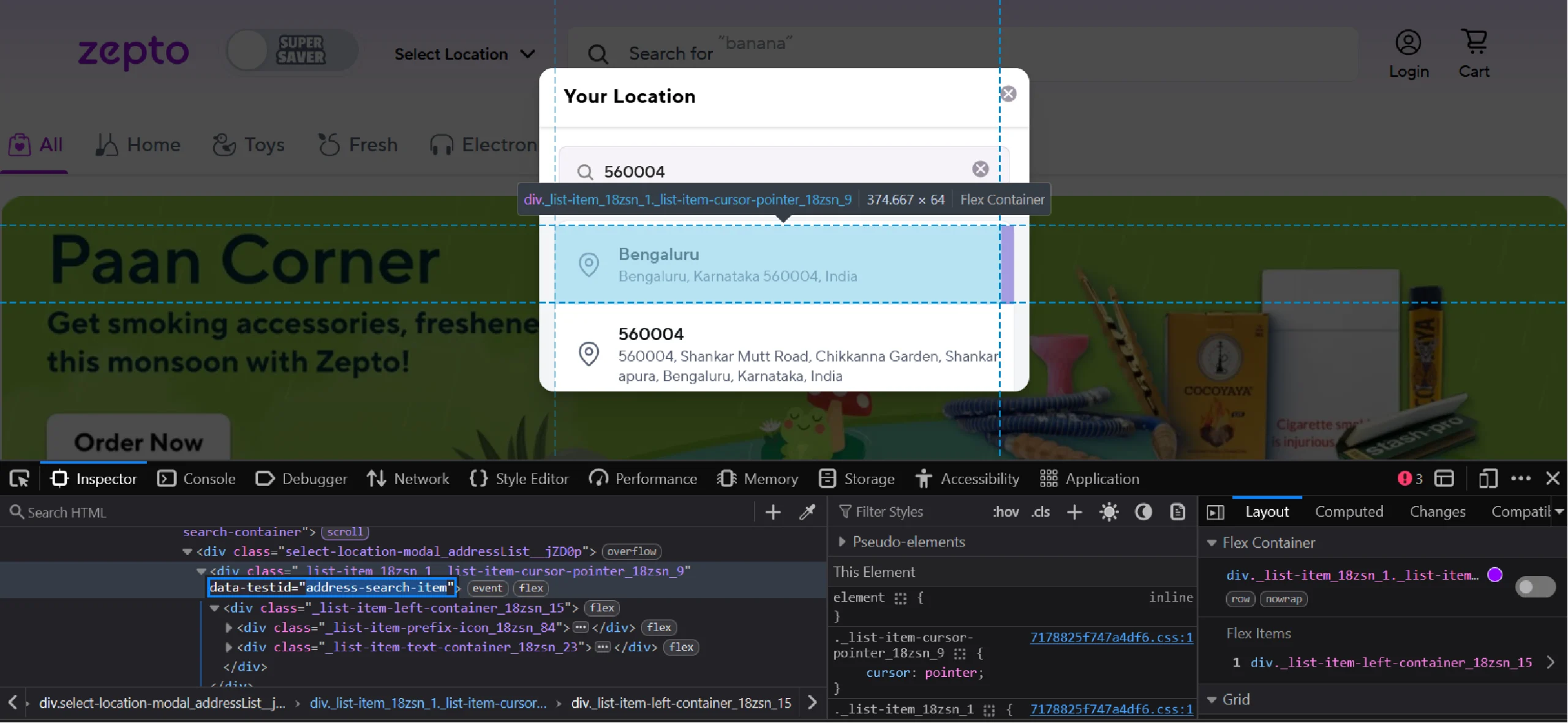
Again, use the find_element() and click() methods to click on the location.
location_item = driver.find_element(By.XPATH,"//div[@data-testid='address-search-item']") location_item.click()
Clicking will take you to another window that prompts you to confirm the location.
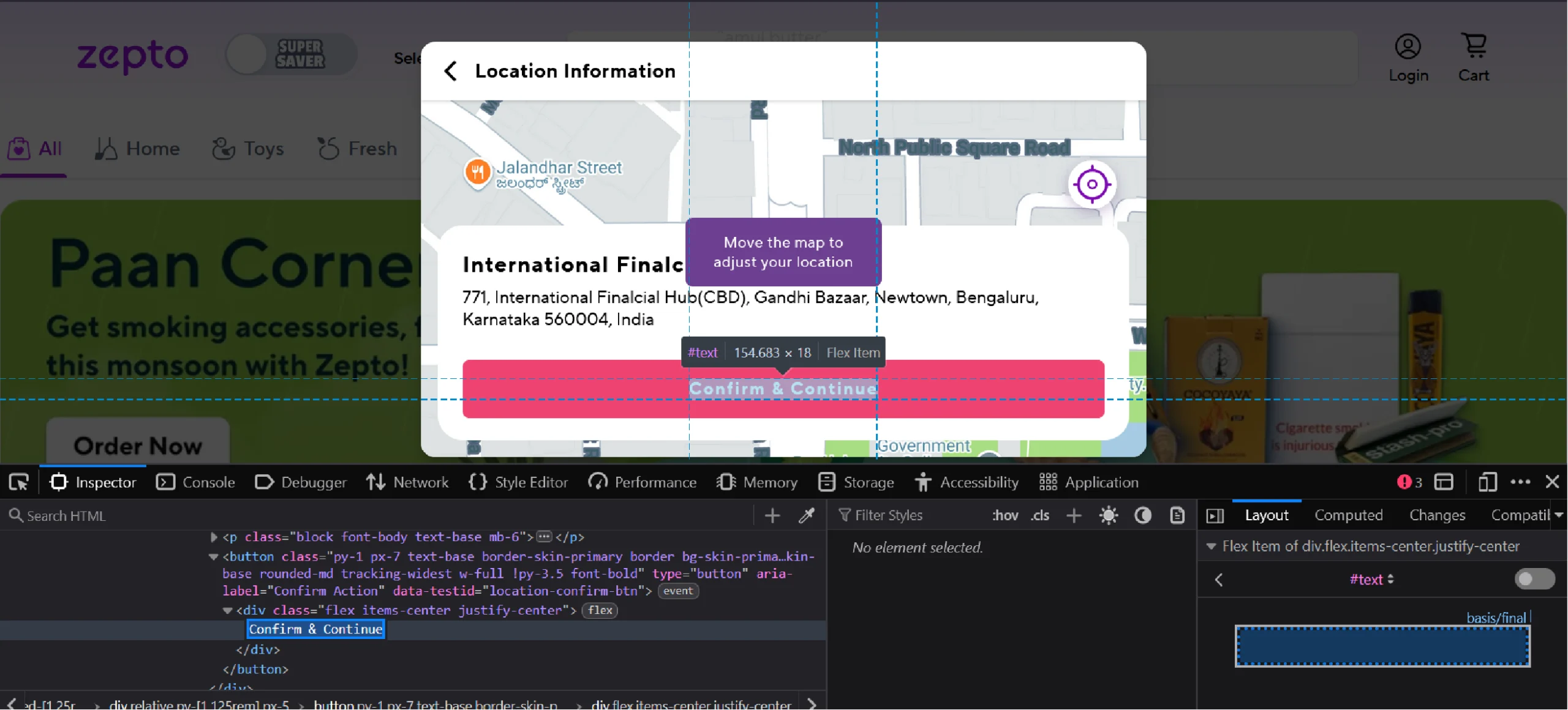
This button may take some time to load, so use WebDriverWait() to check for the element’s presence before clicking on the button.
confirm_button = WebDriverWait(driver,10).until(EC.presence_of_element_located((By.XPATH,'//button[contains(@aria-label,"Confirm")]')))
confirm_button.click()
sleep(4)
This code targets a button that has the text ‘Confirm’ in its aria-lable property and then uses click() to click on it.
Clicking on the Confirm button loads a list of products. Zepto loads the products lazily, which means you need to scroll to load more.
for _ in range(5):
driver.find_element(By.TAG_NAME, 'body').send_keys(Keys.END)
sleep(2)
This code scrolls down repeatedly, mimicking user scrolling. Keys.END sends a “scroll down” command, and sleep allows the page to load completely.
Now, you can extract the product details. Inspecting a product reveals that the details are inside anchor tags, which do not have unique attributes to locate them.
However, all the product details have a text “ADD”. That means you need to select all the anchor tag elements that have the text “ADD” inside any of their descendants.
products = driver.find_elements(By.XPATH,"//a[descendant::*[contains(text(),'ADD')]]")
This XPath expression identifies products listed with an “ADD” button, indicating availability.
Next, initialize a list and extract the product details.
product_details = []
for item in products:
try:
details = item.text.split('\n')
print(details)
n = 4 if "SAVE" in details else 0
p = 1 if 'Premium' in details else 0
product_details.append(
{
"Name": details[n+4],
"Price": details[1]+details[2],
"Discount": details[6] if n==4 else None,
"Premium": True if p==1 else False,
"Amount": details[n+3],
"Rating": details[p+n+5],
"Review Count": details[p+n+6].replace('(','').replace(')',''),
"Delivery Time": details[p+n+7]
}
)
except Exception as e:
print(e)
Here, the code
- Splits each product element’s text by newlines.
- Checks for keywords like “SAVE” (indicating discounts) or “Premium” to adjust data extraction indices accordingly.
- Extracts and stores the product details in a dictionary format.
Finally, close the browser and save the scraped data into a JSON file (zepto_products.json) in a readable format.
driver.quit()
with open('zepto_products.json','w') as f:
json.dump(product_details,f,indent=4,ensure_ascii=False)
The results of Zepto data extraction will look like this:
{
"Name": "Modern Sandwich Supreme White Bread 800 g Combo",
"Price": "₹176",
"Discount": "₹14",
"Premium": false,
"Amount": "800 g X 2",
"Rating": "4.7",
"Review Count": "951",
"Delivery Time": "4 mins"
}
And here’s the complete code for Zepto data scraping:
#import packages
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import json
from time import sleep
#launch Selenium
driver = webdriver.Chrome()
driver.get('https://www.zeptonow.com/search?query=bread')
sleep(2)
#select location
location_button = driver.find_element(By.XPATH,'//button[@aria-label="Select Location"]')
location_button.click()
sleep(3)
location_input = driver.find_element(By.XPATH,"//input[@placeholder='Search a new address']")
location_input.send_keys("560004")
sleep(4)
location_item = driver.find_element(By.XPATH,"//div[@data-testid='address-search-item']")
location_item.click()
confirm_button = WebDriverWait(driver,10).until(EC.presence_of_element_located((By.XPATH,'//button[contains(@aria-label,"Confirm")]')))
confirm_button.click()
sleep(4)
#load more elements
for _ in range(5):
driver.find_element(By.TAG_NAME, 'body').send_keys(Keys.END)
sleep(2)
#extract loaded elements
products = driver.find_elements(By.XPATH,"//a[descendant::*[contains(text(),'ADD')]]")
product_details = []
for item in products:
try:
details = item.text.split('\n')
print(details)
n = 4 if "SAVE" in details else 0
p = 1 if 'Premium' in details else 0
product_details.append(
{
"Name": details[n+4],
"Price": details[1]+details[2],
"Discount":details[6] if n==4 else None,
"Premium": True if p==1 else False,
"Amount": details[n+3],
"Rating": details[p+n+5],
"Review Count": details[p+n+6].replace('(','').replace(')',''),
"Delivery Time": details[p+n+7]
}
)
except Exception as e:
print(e)
#save the data to a JSON file
driver.quit()
with open('zepto_products.json','w') as f:
json.dump(product_details,f,indent=4,ensure_ascii=False)
Code Limitations
Despite its utility, this code to scrape Zepto data has several limitations:
- Performance: Selenium browser automation is slower compared to direct HTTP requests or API-based scraping.
- Scalability: Repeated scrolling and manual waits significantly slow down data collection, making large-scale scraping inefficient.
- Website Changes: Selenium scripts depend heavily on webpage structure. Any change in Zepto’s frontend can break the script.
- CAPTCHA and Blocks: Websites often detect automated browsing, imposing blocks or CAPTCHAs that require additional techniques to bypass these anti-scraping measures.
Why Opt for a Web Scraping Service
While Selenium offers a good starting point for small-scale web scraping, it can be a real challenge to manage a reliable web scraper at scale. If data is your only goal, it’s better to reach out to web scraping services.
A web scraping service like ScrapeHero can handle anti-scraping measures and website changes to ensure that you get high-quality results consistently.
ScrapeHero is an enterprise-grade web scraping service. We can deliver high-quality, custom data tailored to your specific requirements. Forget about web scraping technicalities, and let ScrapeHero help you focus more on data analysis and less on data extraction.



