

Are you in search of the top cloud web scraping providers in 2025?
But with countless cloud-based web scraping solutions available, how do you choose the right one for your needs?
Fret not; this article is for you.
In this blog, we present the top cloud web scraper providers in 2025, along with their pros and cons. This cloud web scraping provider comparison will help you identify the best option for your needs in cloud web scraping.

7 Top Cloud Web Scraping Providers in 2025
The following are the best cloud-based web scraping solutions in 2025:
1. ScrapeHero Cloud

ScrapeHero Cloud is a cloud-based web scraping solution designed to help users easily collect data from various websites without needing advanced technical skills.
It offers pre-built crawlers and APIs that can gather information from popular sites like Amazon, Google Maps, and Walmart.
Following are the steps involved in scraping data using a scraper on ScrapeHero Cloud:
1. Go to the scraper’s homepage, log in/sign up
2. Click ‘Create New Project’
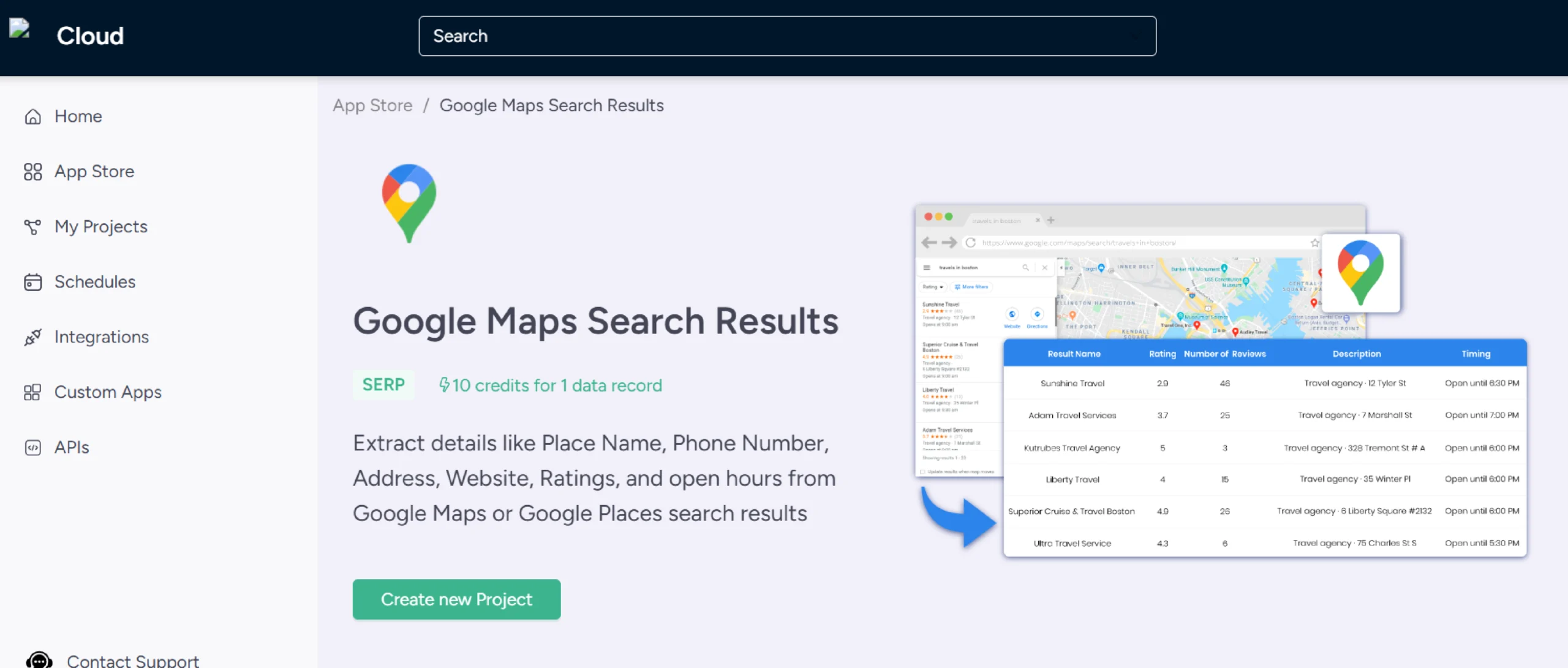
3. Enter the project’s name and the search queries
4. Specify the maximum number of search results to gather
5. Click ‘Gather Data’
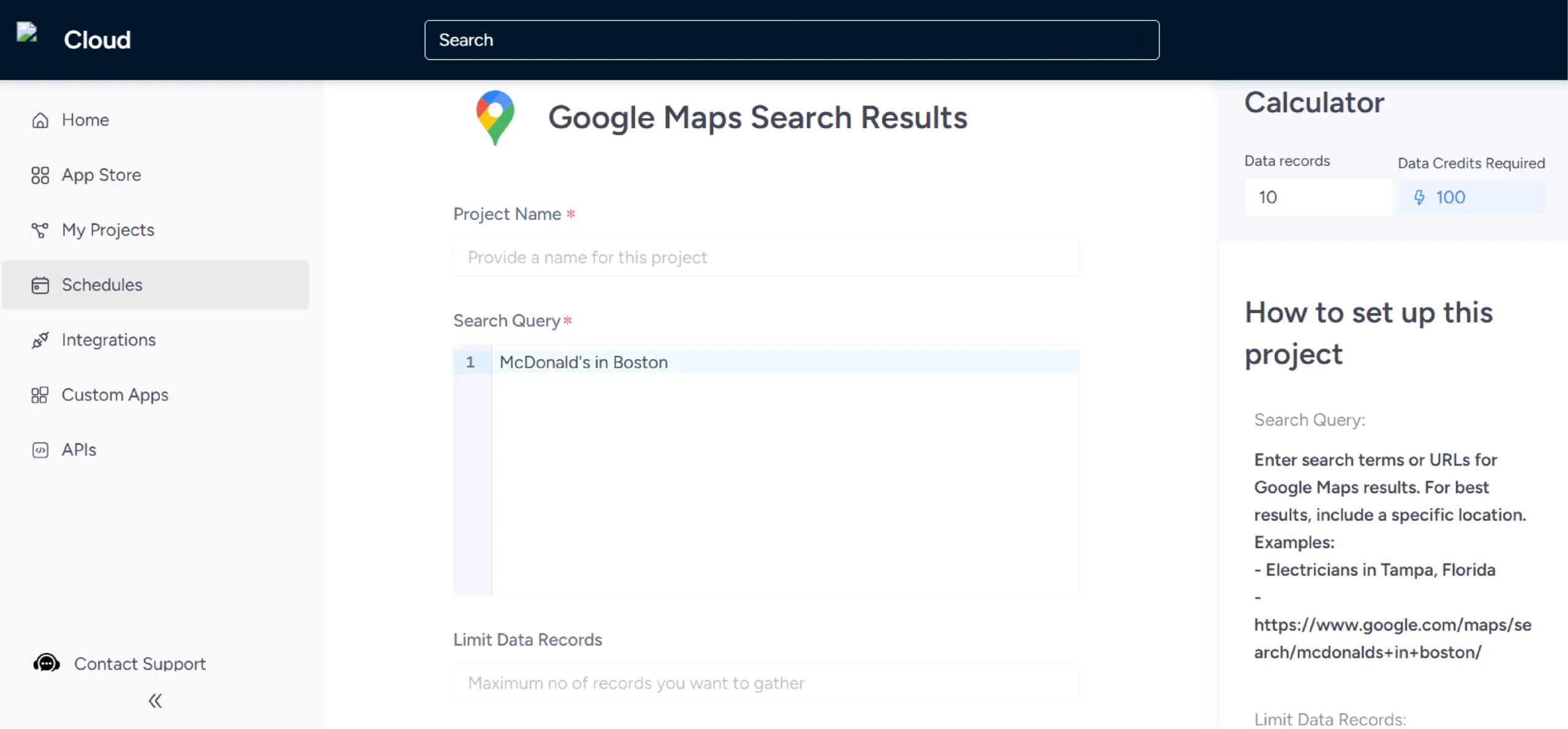 6. You can download the scraped data from ‘My Projects.’
6. You can download the scraped data from ‘My Projects.’
Data Export
- Supported file formats – CSV, JSON, and XML
- Integrates with Dropbox
Pros
- User-Friendly: The scrapers are easy to use, requiring no coding skills; users can simply copy and paste URLs to start scraping.
- Free to Try: Offers 400 credits for free for those wanting to test the scrapers on the platform.
- Comprehensive Data Extraction: Can extract multiple data points from different websites.
- Scheduled Scraping: Users can set up periodic scraping schedules (hourly, daily, or weekly) for continuous data collection.
- Zero Maintenance: ScrapeHero manages updates and maintenance, ensuring the scrapers remain functional even if the website changes its site structure.

Cons
- Limited website support: While ScrapeHero Cloud supports many popular sites, it may not cover all websites.
Want to scrape a different website customized to your specific requirements?

Pricing
- Offers a tiered subscription model.
- Starts as low as $5/month.
2. Scrapy Cloud

Scrapy Cloud is a cloud-based platform developed by Zyte that allows users to host, manage, and automate their web scraping projects using the Scrapy framework.
It provides a user-friendly interface for running and monitoring web crawlers to extract data from websites without dealing with the complexities of infrastructure management.
Data Export
- File Formats – CSV, JSON, XML
- Scrapy Cloud API
- Users can write scraped data to different databases or storage locations by utilizing ItemPipelines.
Pros
- Integration with Zyte API: The platform seamlessly integrates with the Zyte API.
- No Vendor Lock-In: Users can develop their code using Scrapy and easily migrate it to other hosting solutions if needed.
- A decent user interface that lets you see all sorts of logs a developer would need.
Cons
- Technical Difficulties: No point-and-click utility. You still need to “code” scrapers.
- Can Get Expensive: Large-scale crawls can get expensive as you move up to higher pricing tiers.
- Dependency on Scrapy Framework: Users must be familiar with the Scrapy framework to fully utilize Scrapy Cloud’s capabilities, which may be a barrier for those unfamiliar with it.
Pricing
- Follows a pay-as-you-go and priced-per-request pricing policy.
3. Cloud Scraper

Cloud Scraper is a cloud-based web scraping solution by Web Scraper.
It lets you deploy scrapers made with the free Webscraper.io Chrome Extension. Using this extension, you can create “sitemaps” that show how to navigate and extract data from websites.
This tool is handy for those looking to automate data collection from dynamic websites that require JavaScript execution.
Data Export
- You can write the data directly in CouchDB or download it as a CSV file.
Pros
- Flexible Scheduling: Users can run scraping jobs on an hourly, daily, or weekly basis, making it easy to automate data collection.
- API Management: The platform allows users to manage their scrapers and access data through an API.
- Supports javascript-heavy websites.
- The extension is open source, so you will not be locked in with the vendor if the service shuts down.
Cons
- Learning Curve: While powerful, the tool may require some time to learn and master all its features effectively.
- Free Plan Limitations: The free version has restrictions on cloud credits and parallel tasks, which may not suffice for larger projects.
- Not ideal for large-scale scrapes, as it is based on a chrome extension. Once the number of pages you need to scrape goes beyond a few thousand, there is a chance that the scrapes will be stuck or fail.
Pricing
- Starts at $50 per month.
4. ParseHub
ParseHub is a web scraping tool with a user-friendly interface that lets you point and click to select the data you want to scrape.
ParseHub can handle complex websites, including those that use JavaScript.
Data Export
- File Formats – CSV, JSON
- Integrates with Google Sheets and Tableau
- ParseHub API
Pros
- User-Friendly: The point-and-click interface makes it easy for anyone to use, even without coding skills.
- Handles Dynamic Content: ParseHub can scrape data from websites that load content dynamically using JavaScript.
Cons
- Vendor Lock-In: Users are locked into the ParseHub ecosystem since scrapers can only run in their cloud. There is no option to export scrapers to other platforms or tools.
- Cannot Write Directly to Any Database: ParseHub does not allow users to write scraped data directly to databases, requiring additional steps for data storage.
Pricing
- Offers a free plan.
- Paid plans include Standard ($189/month), Professional ($599/month), and ParseHub Plus (custom pricing).
5. Octoparse
Octoparse is a no-code, cloud-based web scraping platform that allows users to extract data from websites without needing to write any code.
It uses a point-and-click interface and AI-powered features to simplify the scraping process.
Data Export
- XLS, CSV, XLSX, TSV, JSON, and to databases (SQL Server, MySQL, etc.).
Pros
- No-code interface: User-friendly point-and-click interface makes it accessible to users without programming skills.
- AI-powered: Includes an AI web scraping assistant for faster setup.
- Templates: Offers pre-built templates for popular websites.
- Scheduling: Ability to schedule scraping tasks to run automatically at set intervals.
Cons
- Data Volume and Complexity: Extracting large volumes of data from complex sites can still be challenging and may require careful configuration.
- Learning curve: Although no coding is required, understanding the software’s features and designing efficient scraping workflows takes time and practice.
- Pricing: Can become expensive for large-scale or frequent scraping needs.
Pricing
- Octoparse offers a free plan with limited features.
- Paid plans are subscription-based and vary based on scraping needs (number of concurrent tasks, cloud servers, etc.). Common plans include Standard and Professional.
6. DiffBot
Diffbot is a cloud-based web scraping solution that lets you configure crawlers to index websites and process them using its automatic APIs for data extraction. If the automatic data extraction API doesn’t work for the websites you need, you can also write a custom extractor.
Data Export
- File Formats – CSV, JSON, Excel
- Cannot write directly to databases
- Integrates with many cloud services through Zapier
- Diffbot APIs
Pros
- Most of the websites do not usually need much setup as the automatic APIs do a lot of the heavy lifting for you.
- No Rules Required: Diffbot automatically extracts data without needing predefined rules.
- Supports Multiple Languages: The tool can read and extract data from websites in any human language.
Cons
- Vendor Lock-In: You will be locked in the Diffbot ecosystem as the tool only lets you run scrapers in their environment platform.
- Relatively Expensive.
Pricing
- Starts at $299/month.
7. Apify
Apify is among our list of the top cloud web scraping providers in 2025.
Apify is a cloud platform that enables you to build, run, and manage web scrapers and automation tasks.
It’s a developer-focused, full-stack web scraping and automation cloud-based platform.
Data Export
- CSV, JSON, Excel, HTML, XML, or RSS Feed
Pros
- Versatile Templates: Offers a variety of pre-built scrapers (called Actors) customized for specific tasks. Offers templates for Requests, Beautiful Soup, Scrapy, Playwright, and Selenium.
- Smooth Integration: Works well with popular libraries like Puppeteer, Playwright, and Scrapy.
- Integrations and Task Automation: Actors can be integrated with third-party applications and triggered manually.
Cons
- Cost for Heavy Users: Costs can add up quickly for large-scale scraping projects.
Pricing
- Has a limited free plan.
- Subscription plans start at $49/month.
Which is the Best Cloud-Based Web Scraping Solution in 2025?
This blog compared seven top cloud web scraping providers in 2025: ScrapeHero Cloud, Scrapy Cloud, Cloud Scraper, ParseHub, Octoparse, Diffbot, and Apify.
We evaluated each provider based on its ease of use, data export capabilities, and integration options.
The pros and cons of each service were also analyzed, focusing on factors such as coding requirements, pricing, and vendor lock-in.
Our aim was to help readers select the best web scraping solution for their needs, considering factors such as technical expertise and project scale.
However, if you lack programming skills, whether in visual tools or traditional coding and have complex requirements for scraping large volumes of data, the wise choice would be to partner with a web scraping service like ScrapeHero.
By using ScrapeHero, you can save time while obtaining clean and structured data. Simply communicate your specific needs, and you will receive high-quality, well-organized data without the hassle.



