

The increase in data requirements has led to an exponential rise in scale and complexity of web scraping. A solution? Distributed scraping with serverless functions.
This article gives an overview of distributed scraping with serverless functions on Amazon Web Services (AWS), Google Cloud Platform (GCP), and Microsoft Azure.
Architecture for Distributed Scraping
Here’s a common web scraping architecture that you can use for AWS, Azure, or GCP:
- Scheduler: A scheduler triggers the entire scraping process on a predefined schedule (e.g., daily).
- Orchestrator Function: The scheduler invokes an orchestrator function. This function identifies the scraping tasks (e.g., a list of URLs to scrape) and dispatches them to a task queue.
- Task Queue: A task queue connects the orchestrator and the serverless functions. Each message in the queue represents a task.
- Serverless Functions: A pool of serverless functions subscribes to the task queue. Each function
- Pulls a message from the queue
- Performs the scraping task
- Stores the extracted data
- Data Store: The scraped data is stored in a durable and scalable data store.

Distributed Scraping With AWS
You can implement the scraping architecture on AWS using:
- Step Functions
- Simple Queue Service (SQS)
- Lambda functions
- Simple Storage Service (S3)
Scheduling and Orchestrating with AWS Step Functions
Step Functions allows you to define complex, multi-step workflows visually. This means you can string together various Lambda functions, SQS queues, and other AWS services into a seamless operation. It also provides built-in capabilities for
- State management
- Retries
- Error handling
Example JSON schema for Step Functions:
{
"Comment": "Distributed Scraping Workflow",
"StartAt": "DispatchTasks",
"States": {
"DispatchTasks": {
"Type": "Task",
"Resource": "arn:aws:lambda:region:account-id:function:DispatchTasksFunction",
"Next": "WaitForCompletion"
},
"WaitForCompletion": {
"Type": "Wait",
"Seconds": 60,
"End": true
}
}
}
Message Queues with Amazon SQS
To manage and distribute scraping tasks asynchronously, Amazon SQS (Simple Queue Service) is excellent. SQS is a highly scalable and reliable message queuing service where you can place requests, such as URLs to scrape. Lambda functions can then consume messages from this queue to execute scraping tasks in parallel, which is crucial for handling variable loads.
Example code:
import boto3
import json
sqs = boto3.client('sqs')
QUEUE_URL = 'https://sqs.region.amazonaws.com/account-id/ScrapingQueue'
def lambda_handler(event, context):
urls = ['https://example.com/page1', 'https://example.com/page2']
for url in urls:
sqs.send_message(
QueueUrl=QUEUE_URL,
MessageBody=json.dumps({'url': url})
)
return {'statusCode': 200, 'body': 'Tasks dispatched'}
Scraping with Lambda Functions
The foundational component for serverless web scraping on AWS is AWS Lambda. This service executes scraping code in response to various events. In a scraping project, these workers will be responsible for pulling data from websites. And because they can scale automatically, the functions can handle variable scraping loads.
Example code:
import boto3
import requests
from bs4 import BeautifulSoup
import json
s3 = boto3.client('s3')
BUCKET_NAME = 'scraped-data-bucket'
def lambda_handler(event, context):
for record in event['Records']:
message = json.loads(record['body'])
url = message['url']
# Perform scraping
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
title = soup.find('title').text
# Store result in S3
s3.put_object(
Bucket=BUCKET_NAME,
Key=f'results/{url.split('/')[-1]}.txt',
Body=title.encode('utf-8')
)
return {'statusCode': 200, 'body': 'Scraping complete'}Storage with Amazon S3
For storing raw scraped output, Amazon S3 (Simple Storage Service) is the go-to choice. S3 provides highly scalable, durable, and cost-effective object storage. For instance, S3 is ideal for storing raw HTML content, images, or large data files.
Here is a general workflow of the distributed scraping project on AWS.
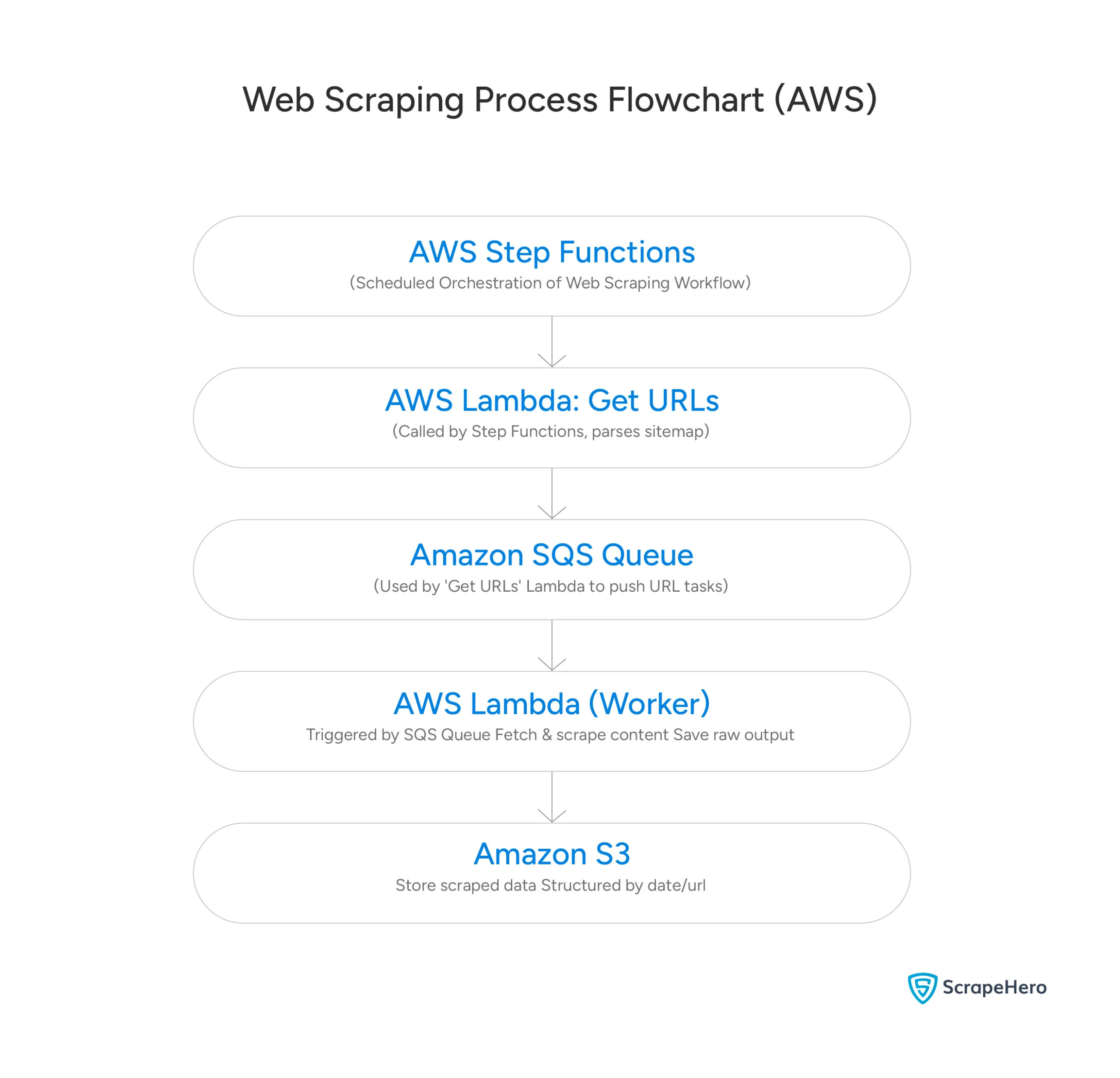
Distributed Scraping with Azure
In Azure, you can use these products to implement the architecture:
- Logic Apps
- Service Bus
- Azure Functions
- Blob Storage
Scheduling and Orchestrating with Azure Logic Apps
Azure Logic Apps can schedule and orchestrate distributed scraping workflows by coordinating
- Multiple scraping agents
- Data transformation processes
- Storage systems
Logic apps use visual designers, providing built-in connectors for seamless integration. They automatically scale to accommodate varying workloads with robust error handling.
Example JSON schema for Logic Apps workflow:
{
"definition": {
"$schema": "https://schema.management.azure.com/providers/Microsoft.Logic/schemas/2016-06-01/workflowdefinition.json#",
"triggers": {
"Recurrence": {
"type": "Recurrence",
"recurrence": {
"frequency": "Day",
"interval": 1
}
}
},
"actions": {
"DispatchTasks": {
"type": "Http",
"inputs": {
"method": "POST",
"uri": "https:///api/DispatchTasks",
"body": {
"urls": ["https://example.com/page1", "https://example.com/page2"]
}
}
}
}
}
}
Message Queues with Azure Service Bus
Azure Service Bus can manage distributed job queues for scraping. It coordinates work distribution among multiple scraper instances, which makes message delivery more reliable. Logic Apps further ensures a fault-tolerant scraping architecture with advanced features, such as dead-letter queues and priority-based task distribution.
Example code:
import azure.functions as func
from azure.servicebus import ServiceBusClient, ServiceBusMessage
import json
CONNECTION_STR = ""
QUEUE_NAME = "scraping-queue"
def main(req: func.HttpRequest) -> func.HttpResponse:
urls = req.get_json().get('urls', [])
servicebus_client = ServiceBusClient.from_connection_string(CONNECTION_STR)
with servicebus_client:
sender = servicebus_client.get_queue_sender(QUEUE_NAME)
with sender:
for url in urls:
message = ServiceBusMessage(json.dumps({'url': url}))
sender.send_messages(message)
return func.HttpResponse("Tasks dispatched", status_code=200)
Scraping with Azure Functions
Azure Functions provides serverless execution for distributed scraping tasks. They automatically scale scraper instances based on load, and you only have to pay for the actual execution time. The functions support event-driven triggers from timers or message queues and include built-in mechanisms to monitor and retry, making scraping more reliable.
import azure.functions as func
from azure.storage.blob import BlobServiceClient
import requests
from bs4 import BeautifulSoup
import json
CONNECTION_STR = ""
CONTAINER_NAME = "scraped-data"
def main(msg: func.ServiceBusMessage):
message = json.loads(msg.get_body().decode('utf-8'))
url = message['url']
# Perform scraping
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
title = soup.find('title').text
# Store result in Blob Storage
blob_service_client = BlobServiceClient.from_connection_string(CONNECTION_STR)
blob_client = blob_service_client.get_blob_client(CONTAINER_NAME, f"results/{url.split('/')[-1]}.txt")
blob_client.upload_blob(title, overwrite=True)Storage with Azure Blob Storage
Azure Blob Storage serves as a scalable storage for scraped data. It is scalable because you don’t have to pre-provision it; Azure automatically expands storage as needed. Moreover, Azure Blob Storage can integrate with scraping pipelines through REST APIs, which also support parallel uploads from multiple instances.
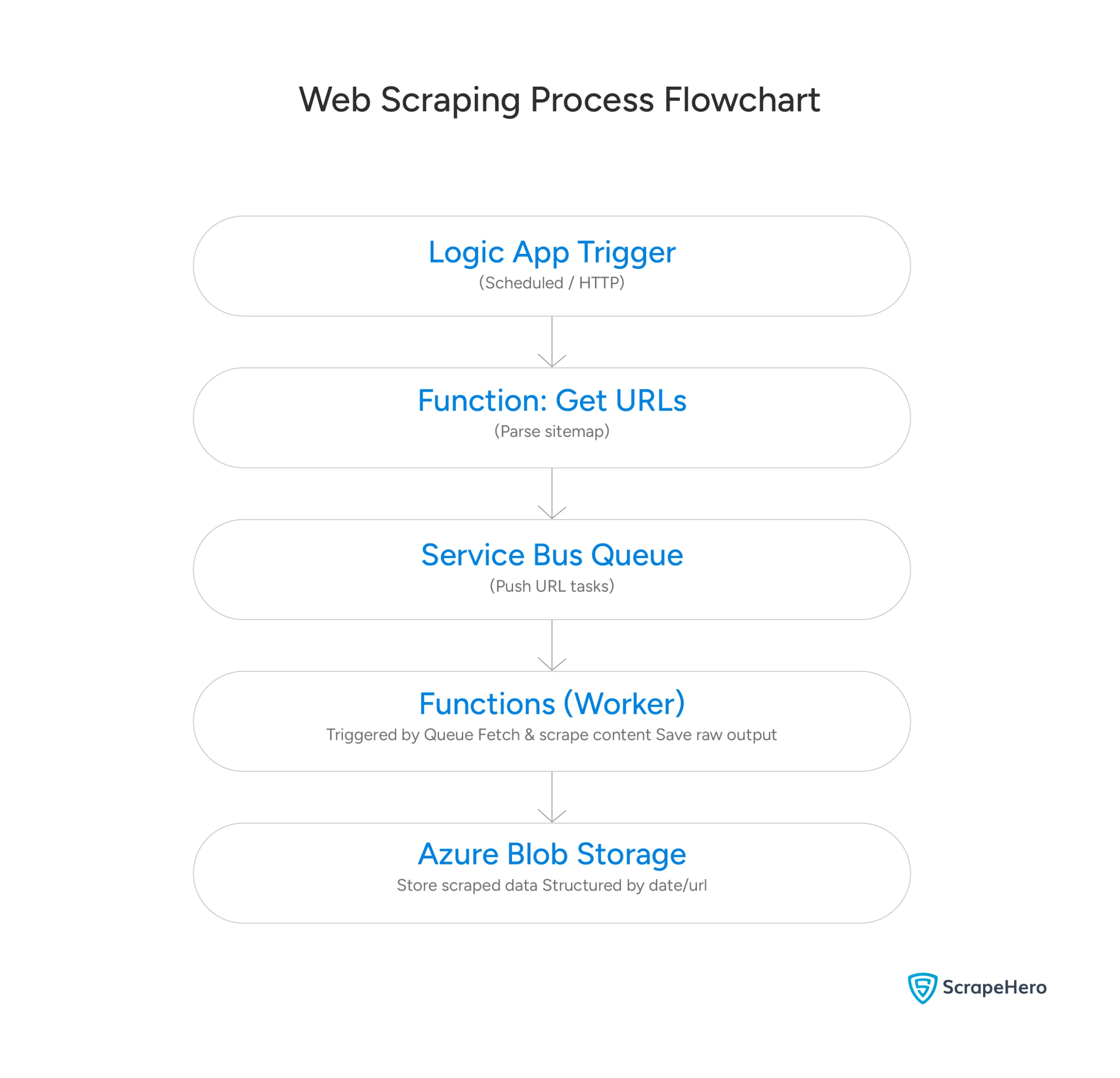
Distributed Scraping with Google Cloud Platform
You can use these products to implement the architecture on GCP:
- Google Cloud Workflows
- Google Cloud Pub/Sub
- Google Cloud Functions
- Google Cloud Storage
Scheduling and Orchestrating with Google Cloud Workflows
Google Workflows can schedule and orchestrate complex, distributed scraping pipelines by defining multi-step processes. These processes coordinate scraper instances, data validation, and storage operations, according to a configuration provided in YAML or JSON. Google Workflows provides built-in:
- Error handling
- Retry logic
- Conditional branching
Example YAML workflow:
- dispatchTasks:
call: http.post
args:
url: https:///dispatchTasks
body:
urls:
- https://example.com/page1
- https://example.com/page2
result: dispatchResult
- complete:
return: dispatchResult
Message Queues with Google Cloud Pub/Sub
Google Pub/Sub manages asynchronous communication in distributed scraping architectures. It coordinates message queues among scraping schedulers, worker instances, and data processors, and makes scraping jobs more reliable and fault-tolerant with
- Automatic scaling
- Dead-letter queues
- Exactly-once delivery guarantees
Example code:
from google.cloud import pubsub_v1
import json
PROJECT_ID = ""
TOPIC_NAME = "scraping-topic"
def dispatchTasks(request):
request_json = request.get_json(silent=True)
urls = request_json.get('urls', [])
publisher = pubsub_v1.PublisherClient()
topic_path = publisher.topic_path(PROJECT_ID, TOPIC_NAME)
for url in urls:
data = json.dumps({'url': url}).encode('utf-8')
publisher.publish(topic_path, data)
return 'Tasks dispatched', 200
Scraping with Cloud Functions
Google Cloud Functions executes distributed scraping tasks in a serverless environment. Like Azure and AWS Lambda functions, Google Cloud Functions automatically scale based on the demand for scraping. These support event-driven triggers from
- Pub/Sub messages
- HTTP requests
- Cloud Storage events
Example code:
from google.cloud import storage
import requests
from bs4 import BeautifulSoup
import base64
import json
BUCKET_NAME = "scraped-data-bucket"
def scrape(event, context):
message_data = base64.b64decode(event['data']).decode('utf-8')
message = json.loads(message_data)
url = message['url']
# Perform scraping
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
title = soup.find('title').text
# Store result in Cloud Storage
storage_client = storage.Client()
bucket = storage_client.bucket(BUCKET_NAME)
blob = bucket.blob(f"results/{url.split('/')[-1]}.txt")
blob.upload_from_string(title)
return 'Scraping complete', 200
Storage with Google Cloud Storage
Google Cloud Storage is also a scalable storage that can expand based on the storage demand. Its features include:
- Multiple storage classes
- Lifecycle management
- Versioning
- Parallel uploads

Challenges of Distributed Scraping with Serverless Functions
Although distributed scraping with serverless functions is a convenient way to begin your scraping project, consider these challenges:
- Execution Time Constraints: Serverless setups cap runtime at 9-15 minutes, so you have to split tasks into intricate, coordinated workflows.
- Cold Start Latency: These functions experience sluggish startup times, which slow down time-critical scraping and reduce efficiency.
- Memory Limitations: Cloud functions skimp on memory allocation, limiting your ability to handle browser automation and big data processing.
- IP Management: Serverless platforms lack built-in IP rotation, requiring you to rely on external proxies to avoid blocks and rate caps.
- State Management: These environments operate statelessly, making it challenging to maintain session persistence and data flow across requests.
- Cost Optimization: Serverless models charge per invocation, prompting you to closely monitor costs that can exceed those of dedicated servers for heavy scraping.
- Debugging Complexity: Distributed functions operate in spread-out systems, creating headaches for real-time debugging and error tracking.
- Coordination Overhead: Concurrent functions demand juggling tons of tasks, forcing you to ensure data consistency and smooth task sequencing.
- Rate Limiting: Cloud-based functions hit provider throttling, restricting high-volume scraping throughput.
- Data Persistence: Serverless storage stays temporary, so you need external tools to manage data storage and result stitching.
- Network Reliability: These systems often encounter network hiccups or timeouts, which means you need robust retry and error-handling mechanisms.
- Compliance Constraints: Multi-region functions run into data residency rules, complicating compliance across regions.
Wrapping Up: Why Use a Web Scraping Service
Building a distributed web crawling or scraping system requires striking a balance between scalability and reliability. AWS, Azure, and GCP each bring unique strengths to the table, but they share the exact core blueprint.
Your choice of platform depends on your specific needs, existing tech stack, and budget. AWS offers the most mature and feature-rich ecosystem, Google Cloud excels in simplicity and event-driven architectures, and Azure delivers a powerful, developer-friendly experience, especially for those in the Microsoft ecosystem.
However, if you just need data, why bother researching and choosing the right cloud platform for your scraping project? A web scraping service might be a smarter choice.
An enterprise-grade web scraping service like ScrapeHero handles all the technical complexities of scraping. You don’t need to worry about cold starts, memory limitations, or network reliability issues. Simply share your data requirements, and we’ll deliver high-quality results.



