

Blinkit’s dynamic nature makes scraping data using Python requests difficult. For instance, it shows results based on your location. But you can still perform Blinkit data scraping using a browser automation library. These libraries let you perform actions, such as clicking to interact with dynamic elements.
Read on to learn how to extract data from Blinkit. This article guides you through the process of building a Blinkit scraper using Selenium.
Prefer to skip the code entirely? Check out ScrapeHero’s q-commerce data scraping service.

Blinkit Data Scraping: The Environment
This project uses Selenium for web scraping. It enables you to programmatically control a browser and interact with the web pages as a user would.
Install Selenium using PIP.
pip install selenium
The code also needs the sleep and json modules:
- The sleep module allows you to pause the script, which ensures that the website has loaded the elements before Selenium attempts to extract them.
- The json module allows you to save the extracted data to a JSON file.
But, these come with the standard Python library, so you don’t need to install them.
Data Scraped from Blinkit.com
The code in this tutorial extracts product details from Blinkit’s search results page for a specific PIN code:
- Delivery Time
- Product Name
- Quantity
- Time
Here’s a video showing how to extract these details.
Blinkit Data Scraping: The Code
Start by importing the modules required to scrape Blinkit products.
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from time import sleep
import json
This code imports three modules from Selenium:
- webdriver is the main module that controls the browser
- By can select HTML elements using selectors such as XPath, tag name, ID, etc.
- Keys lets you send various key strokes, including Ctrl and Enter.
Next, launch the browser using the webdriver module and go to blinkit.com. Although this code launches Chrome, you can use other browsers, including Firefox and Safari.
browser = webdriver.Chrome()
browser.get('https://blinkit.com/')
Blinkit asks you to enter a PIN code into the input box to show results based on a specific location. Use the browser’s inspect feature to figure out a unique attribute of this input element.
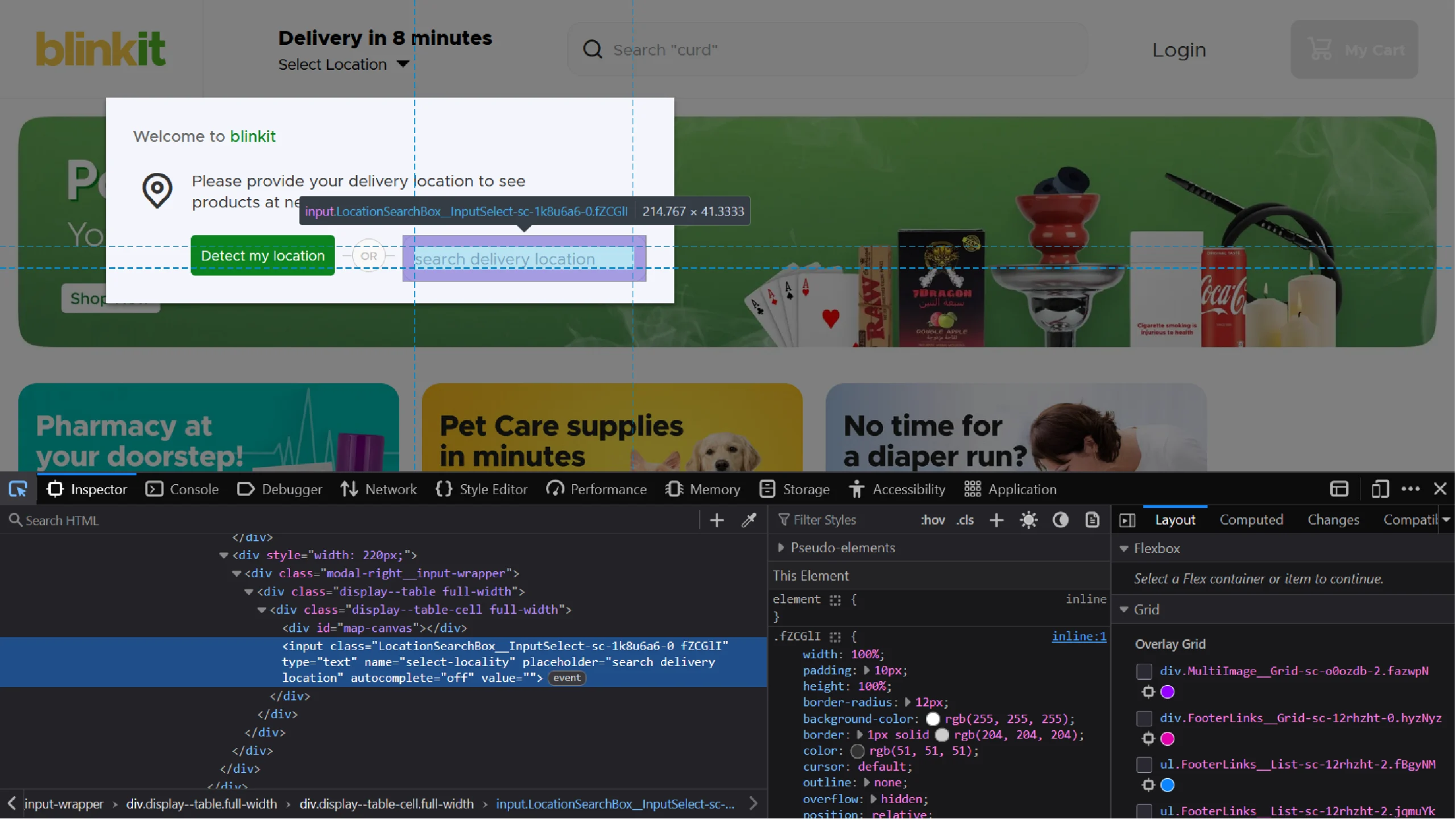
Inspecting the input box shows that it has a placeholder attribute; you can use this value to build the XPath. Selenium’s find_element() method can then use this XPath to select the input box.
location_box = browser.find_element(By.XPATH,'//input[@placeholder="search delivery location"]')After selecting the input box, use send_keys() to enter the PIN code, which loads a list of locations.
location_box.send_keys("110001")
Click on the first item in the list. To do so,
- Use your browser’s inspect feature again.
- Determine the unique attribute to target the first item.
- Select the element using find_element()
location_container = browser.find_element(By.XPATH,'//div[contains(@class,"LocationSearchList__LocationDetailContainer")]')
- Click on it using the click() method.
location_container.click()
This will direct you to the homepage, which features a search bar. Clicking on the search bar will take you to the search input box.
That means, first, get the search bar’s class, build an XPath, and click on the element, giving you access to the search input box.
search_input = browser.find_element(By.XPATH,'//div[contains(@class,"SearchBar__AnimationWrapper")]')
search_input.click()
Then, get the input box’s class, build an XPath as before, and use send_keys() to enter the search term.
search_input = browser.find_element(By.XPATH,'//input[contains(@class,"SearchBarContainer__Input")]')
search_input.send_keys("milk")
Entering the search term loads a list of products. To extract their details, determine the XPath of the listings using the Inspect feature.
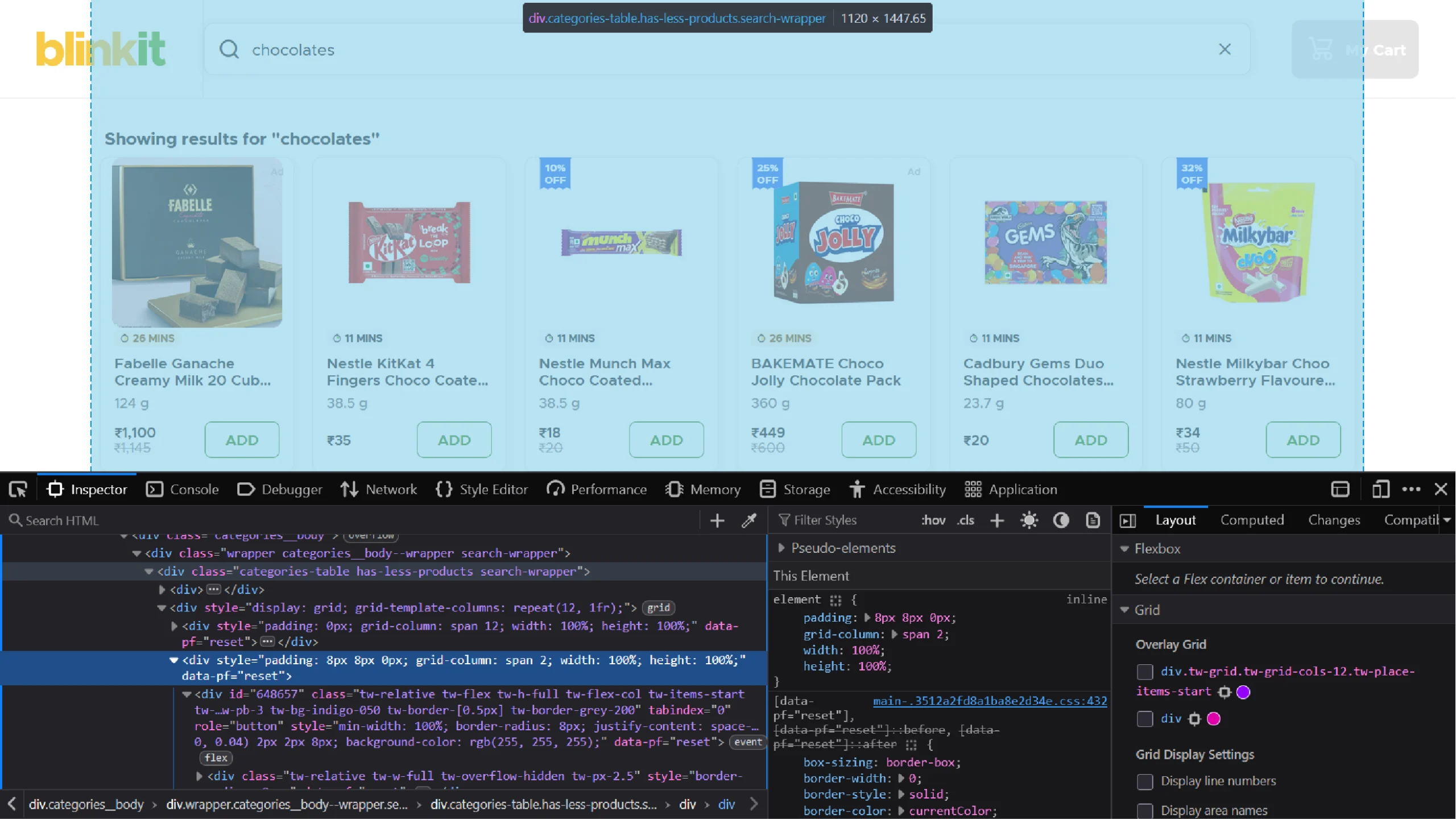
The product listings are div elements inside a div element that is inside another div element with the class “categories table.” So the XPath will be ‘//div[‘categories table’]/div/div/’, which you can use with the find_elements() method.
products = browser.find_elements(By.XPATH,'//div[contains(@class,"categories-table")]/div/div')
Unlike the find_element() method, the find_elements() method selects all the elements targeted by the XPath and gives a list.
Next, loop through div elements in the list and extract the product details.
In each loop,
- Check if the div element contains the string “ADD” to ensure that you’re extracting from the correct element.
- Extract the text.
- Split the text at newline characters.
- Append the extracted data to a list declared outside the loop.
- Save the list in a JSON file using the json module.
product_details = []
for product in products:
if "ADD" in product.text:
details = product.text.split('\n')
product_details.append({
"Delivery Time": details[0],
"Product Name": details[1],
"Quantity": details[2],
"Price": details[3],
})
Finally, save the extracted details in a JSON file. Use the ensure_ascii=False argument to correctly display the currency in the JSON file.
with open('blinkit_products.json', 'w') as f:
json.dump(product_details, f, indent=4,ensure_ascii=False)Extracted details will look like these.
[
{
"Delivery Time": "8 MINS",
"Product Name": "Country Delight Cow Fresh Milk",
"Quantity": "450 ml",
"Price": "₹47"
},
{
"Delivery Time": "8 MINS",
"Product Name": "Amul Taaza Toned Milk",
"Quantity": "500 ml",
"Price": "₹29"
}
]
Here’s the complete’s code:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from time import sleep
import json
browser = webdriver.Chrome()
browser.get('https://blinkit.com/')
sleep(2)
location_box = browser.find_element(By.XPATH,'//input[@placeholder="search delivery location"]')
location_box.send_keys("110001")
sleep(2)
location_container = browser.find_element(By.XPATH,'//div[contains(@class,"LocationSearchList__LocationDetailContainer")]')
location_container.click()
sleep(3)
search_input = browser.find_element(By.XPATH,'//div[contains(@class,"SearchBar__AnimationWrapper")]')
search_input.click()
sleep(2)
search_input = browser.find_element(By.XPATH,'//input[contains(@class,"SearchBarContainer__Input")]')
search_input.send_keys("milk")
sleep(3)
products = browser.find_elements(By.XPATH,'//div[contains(@class,"categories-table")]/div/div')
product_details = []
for product in products:
if "ADD" in product.text:
details = product.text.split('\n')
product_details.append({
"Delivery Time": details[0],
"Product Name": details[1],
"Quantity": details[2],
"Price": details[3],
})
with open('blinkit_products.json', 'w') as f:
json.dump(product_details, f, indent=4,ensure_ascii=False)
Code Limitations
Although the code shown in this tutorial can scrape Blinkit products, consider these code limitations:
- The code will work until Blinkit changes the HTML structure. When that happens, the scraper may fail to extract the data because the elements targeted by the XPaths may not exist; this means you need to determine new XPaths.
- The code lacks the techniques to bypass anti-scraping measures, which will be apparent in large-scale projects.
Wrapping Up: Why Use a Web Scraping Service
You can scrape Blinkit using browser automation libraries. You just need to determine the XPaths to relevant elements and write some code. The code shown in this tutorial can work for a small-scale scraping project, but if you want to scrape on a large scale, it’s better to use a web scraping service.
A web scraping service like ScrapeHero can handle the technical aspects of scraping. This involves monitoring the website for changes in the HTML structure and implementing anti-scraping measures.
ScrapeHero is an enterprise-grade web scraping service that delivers high-quality data customized to your preferences. We’ll take care of your data needs so that you can focus less on data collection and more on data analysis.



