

Minor changes in HTML or CSS may cause your scraper to collect garbage data without raising an error. These are called silent failures. Although visual changes exist in the web page during these scenarios, an automated visual regression test for your web scrapers may not be the best choice for addressing these failures.
Here’s why.
Understanding Automated Visual Regression for Web Scrapers
Visual regression testing checks the pixels, rather than checking the code. The core principle is simple:
- Establish a Baseline: Take a screenshot of the relevant parts of a webpage when your scraper is known to be working correctly. This is your baseline image.
- Capture and Compare: During subsequent test runs, take a new screenshot of the same page section.
- Highlight Differences: Perform a pixel-by-pixel analysis of the new screenshot against the baseline to find the differences.
This method determines whether the website appears the same, rather than whether its code is the same. Its primary advantage is the ability to detect visual changes.
However, web scrapers are primarily concerned with the underlying data.
Consider a scenario where you’re scraping product information from an e-commerce site. An automated visual regression test for your web scraper would fail if:
- The product grid changes from three columns to four, altering the layout
- An icon replaces the “Add to Cart” button
- A new promotional banner above product details shifts everything down
- The font size changed
- New products are added
In all these cases, the underlying class or ID can remain the same, and the scraper may still work:
- The products might still have the class “product-item”
- The icon may still have the ID “add-to-cart”
- Adding the banner only adds another element to the code and may not change the existing one
- The element holding the text may still have the exact attributes
- The new products may have the same class
Automated Visual Regression Testing for Web Scrapers: An Example
Still not convinced? Here’s an example that shows the inefficiency of visual regression testing during data extraction. This example uses Playwright.
To get started, install the Playwright Test package. This package is standalone, and you don’t need to install the playwright browser separately.
npm install @playwright/testThen, create a folder named ‘tests.’ This folder holds all the test scripts.
The next step is to write the test script itself:
- Import test() and expect() from @playwright/test
- Call test() with a function as an argument. This function
- Navigate to the target page (Arxiv’s search results page in this case).
- Call expect().toHaveScreenshot() to compare the current screenshot with an image.
const {test, expect} = require( '@playwright/test');
test('vrt', async ({page}) => {
// Navigate to the page
await page.goto('https://arxiv.org/search/?query=astronomy&searchtype=all&source=header');
await page.waitForLoadState('networkidle');
await expect(page).toHaveScreenshot('testing.png');
})On the first run, use the ‘–update-snapshots’ argument; this creates the baseline screenshots.
npx playwright test --update-snapshotsOn the subsequent runs, just use
npx playwright test
Every time the command runs, the test script
- Grabs a fresh screenshot from the URL
- Compares it with the baseline screenshot
- Generates a ‘diff’ image if the test fails, which shows the difference between the two screenshots
You can use any URL, but the example here uses the URL of Arxiv’s search results page.
Suppose the scraper extracts the math articles listed on the search results page. Here’s the baseline screenshot of the page.
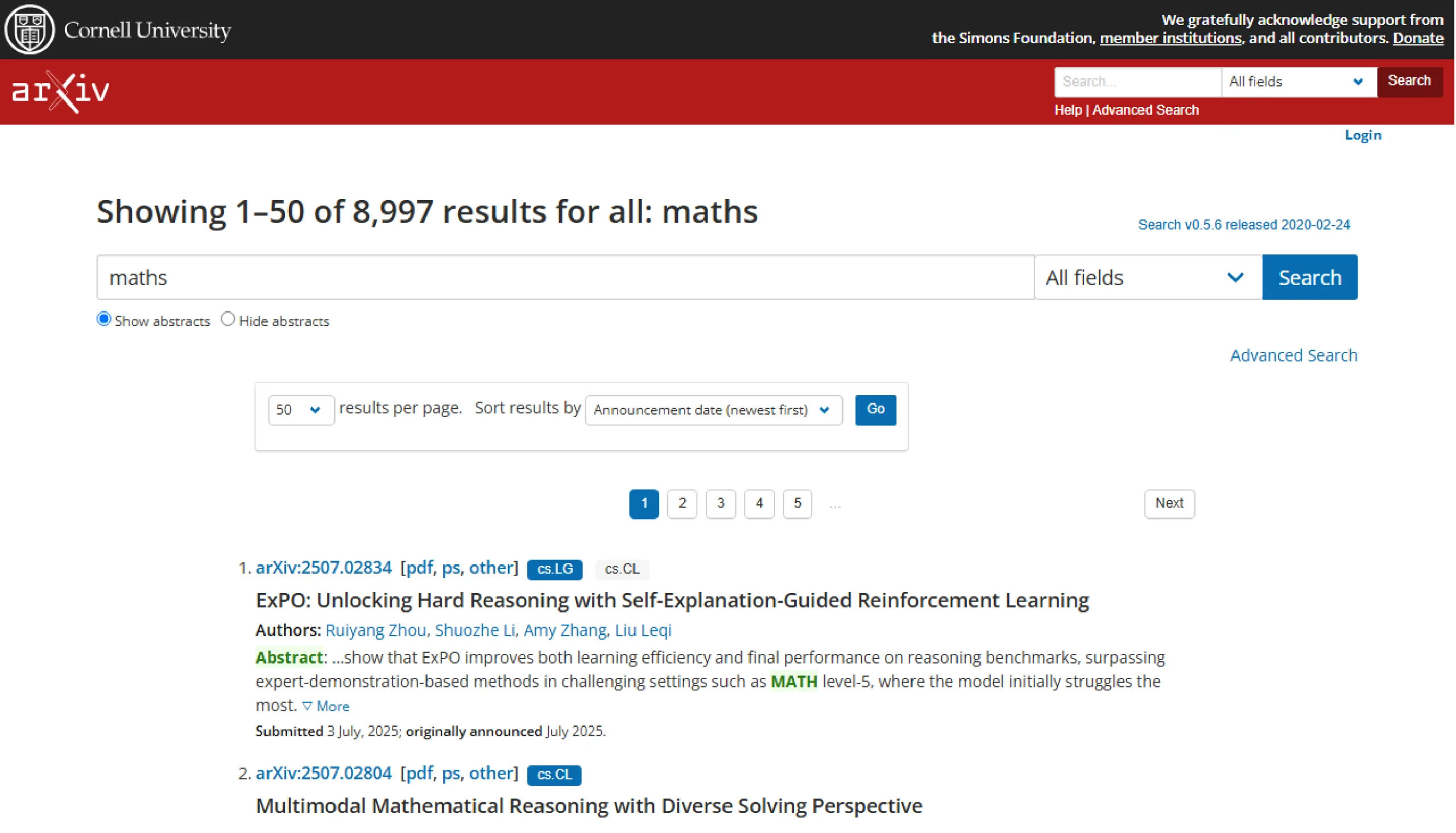
The scraper can also retrieve math articles using the search term “mathematics,” which will result in a screenshot like this.
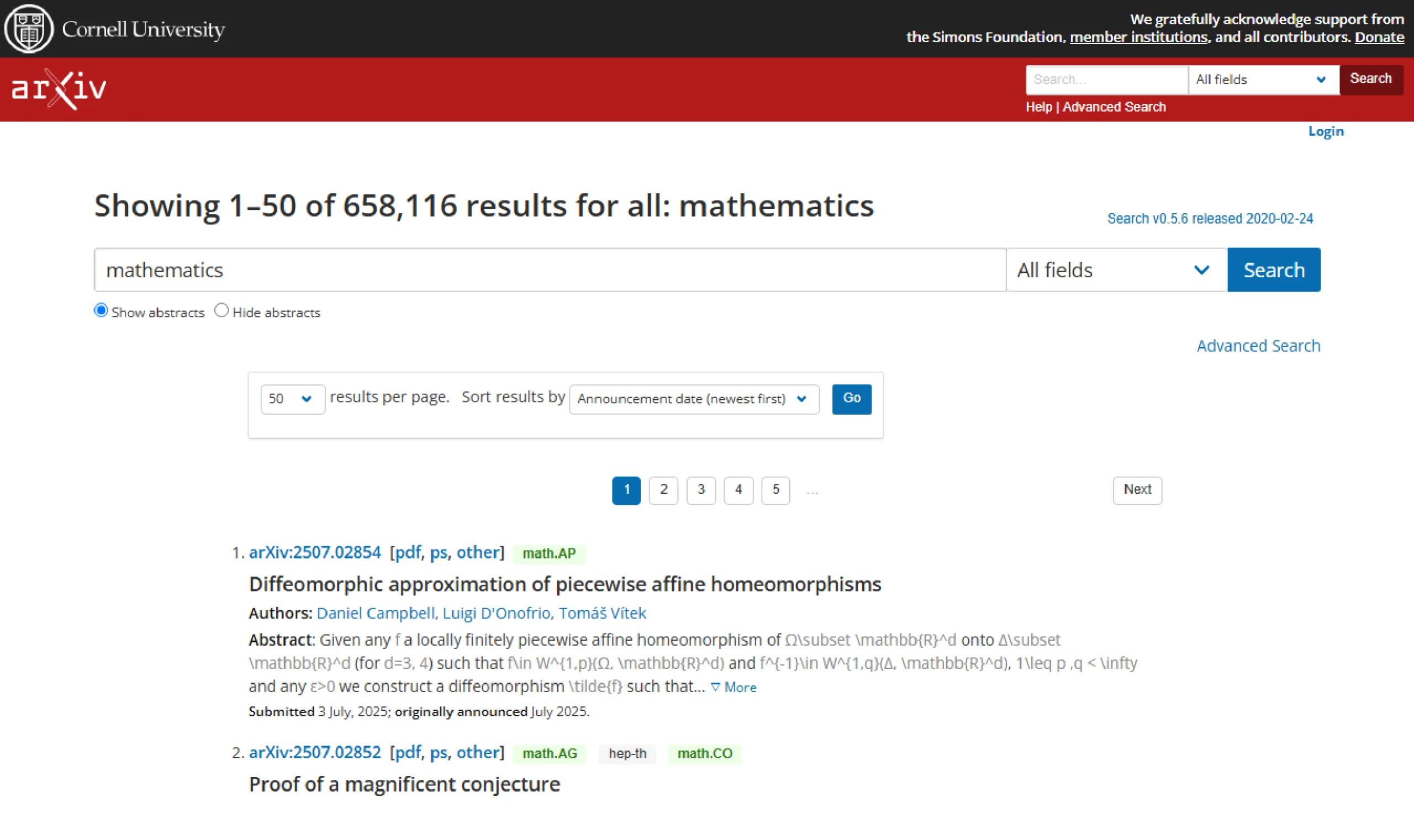
This change doesn’t mean the scraper wouldn’t be able to access the data because the attributes of the elements may not have changed at all.
However, the visual regression test will find the screenshots as different and raise an error.
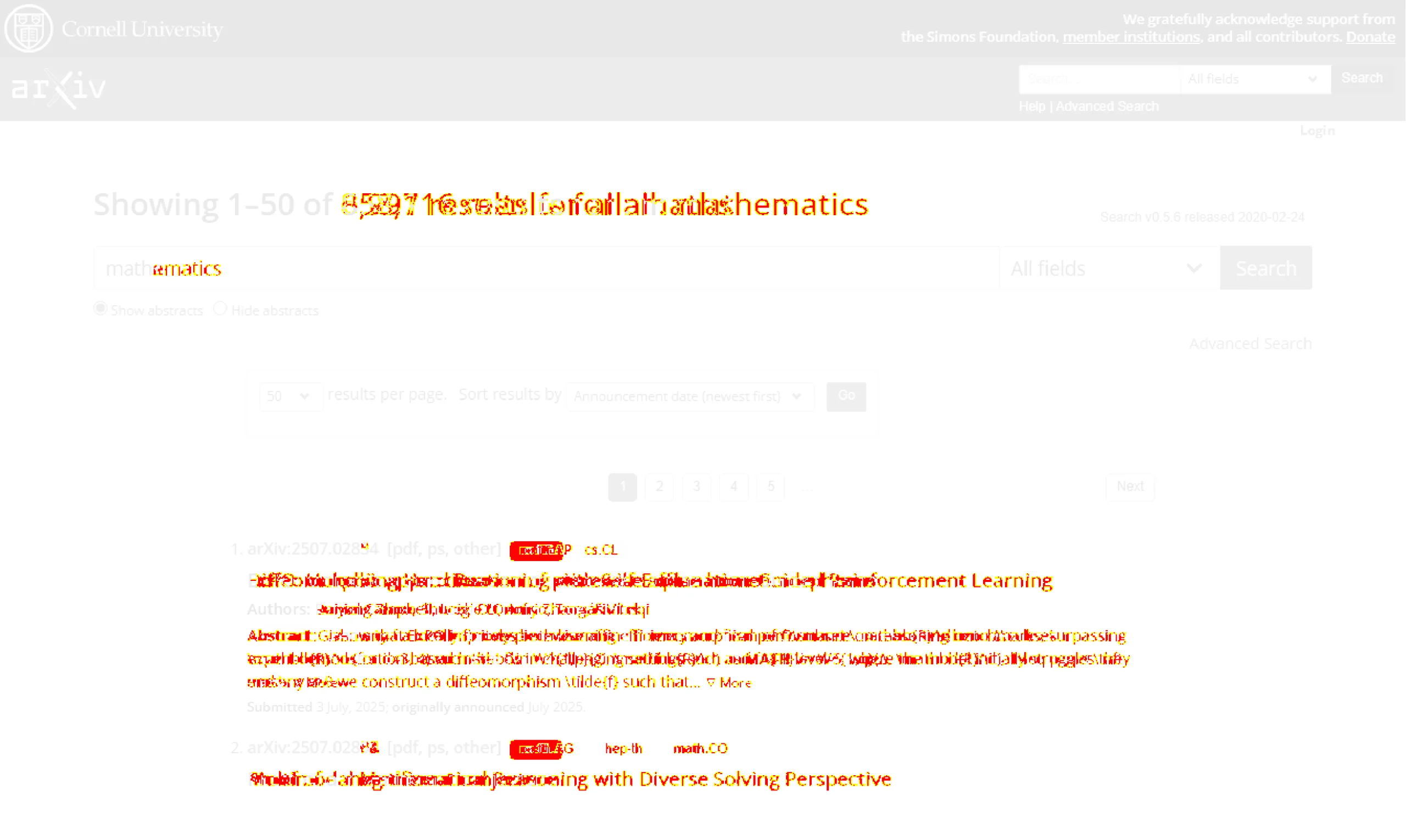
Although you can mask the changes you want the test to ignore, it still may not be enough for every scenario.
For instance, you can mask the elements holding the text, which means the test will ignore any changes in the masked region.
To mask elements:
- Figure out the selectors of the elements you want to mask
- Use the mask argument
const {test, expect} = require( '@playwright/test');
test('vrt', async ({page}) => {
// Navigate to the page
await page.goto('https://arxiv.org/search/?query=astronomy&searchtype=all&source=header');
await page.waitForLoadState('networkidle');
const title = page.locator('h1.title')
const input = page.locator('input[name="query"]')
const results = page.locator('ol.breathe-horizontal')
await expect(page).toHaveScreenshot('testing.png',{mask: [title, input, results]});
})
Note: You need to use the –update-snapshots argument after adding the code to mask elements.
Masking will alter your baseline screenshot by adding a colored overlay on the elements. However, the test still fails because the div elements holding “math” and “mathematics” have different sizes.
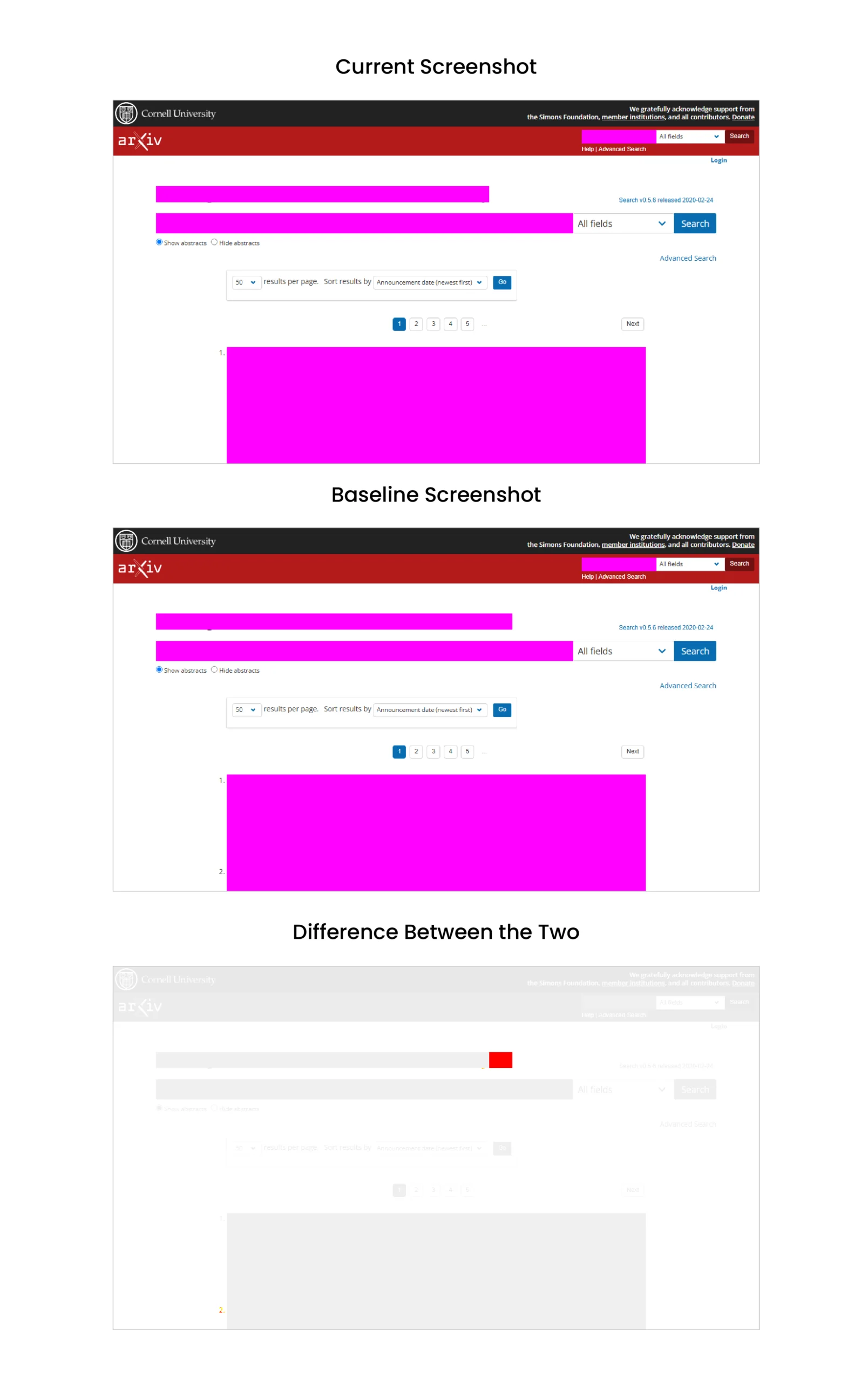 Now, the argument ‘maxDiffPixelRatio’ can further instruct the test to ignore this difference.
Now, the argument ‘maxDiffPixelRatio’ can further instruct the test to ignore this difference.
await expect(page).toHaveScreenshot('testing.png',{mask: [title, input, results],maxDiffPixelRatio:0.005});Yet, even this method may give a false positive if the change in pixel ratio exceeds the specified amount.
An Alternative to Automated Visual Regression Testing for Web Scrapers
As an alternative, check whether or not the HTML has changed enough to break the scraper. Playwright has several built-in methods to do so. For example:
- Use toHaveText() to check that a particular element has a specific text or matches a RegEx pattern.
- Use toBeGreaterThan() to compare the value of something, such as the length of a string or an array.
- Use toHaveAttribute() to check if an element has a specific attribute
These methods can significantly reduce the chances of extracting unwanted text.
const {test, expect} = require( '@playwright/test');
test('dom_variation', async ({page}) => {
// Navigate to the page
await page.goto('https://arxiv.org/search/?query=astronomy&searchtype=all&source=header');
await page.waitForLoadState('networkidle');
//checking text
const title = page.locator('h1.title');
await expect(title).toHaveText(/Showing\s+\d+[\u2013-]\d+\s+of\s+[\d,]+\s+results\s+for\s+all:\s+\w+/i
);
//checking length
const results = await page.locator('ol.breathe-horizontal').count();
await expect(results).toBeGreaterThan(0);
//checking attributes
const result_element = await page.locator('ol.breathe-horizontal > li').first()
await expect(result_element).toHaveAttribute('class','arxiv-result')
})
Wrapping Up: Why Use a Web Scraping Service
In conclusion, automated visual testing for scrapers is generally ineffective. The test can fail for slight visual changes that don’t affect the scraper, so it’s better to check the DOM elements to determine if something significant has changed.
However, you don’t have to build or test scrapers yourself; a web scraping service can take care of all that.
A web scraping service like ScrapeHero can build enterprise-grade web scrapers and crawlers. We deliver high-quality data customized to your needs. You don’t have to worry about building or testing web scrapers. Contact ScrapeHero, and stop worrying about data collection.


