

Scraping shorts allows you to research market research, analyze content, and understand the competition. Want to learn how? Read on. This article breaks down a Python script that scrapes YouTube Shorts video results from Google search.
The code uses Playwright to
- Search for videos on Google
- Filter for short-form content
- Scroll through results
- Extracts video titles, channel names, URLs
Let’s start with setting up the environment.
Scrape YouTube Shorts Video Results: The Environment
The script requires Playwright, a browser automation library; you need to install it.
Install Playwright using PIP from your terminal or command prompt.
pip install playwright
After installing the library, you also need to install the Playwright browser. Run this install command.
playwright installThe code also uses the json and os modules from Python’s standard library, which handle JSON file operations and operating system interactions. These modules require no separate installation.
Data Scraped from YouTube Shorts Search Results
The script extracts three data points from each YouTube Shorts video found in Google Search results:
- Video Title – The name of the video, extracted by parsing the aria-label attribute from a button element within each video’s heading.
- Channel Name – The creator’s channel name, also parsed from the same aria-label attribute.
- Video URL – The complete YouTube link to the short video, retrieved from a data-curl attribute on a descendant div element, enabling seamless integration with text to video workflows.
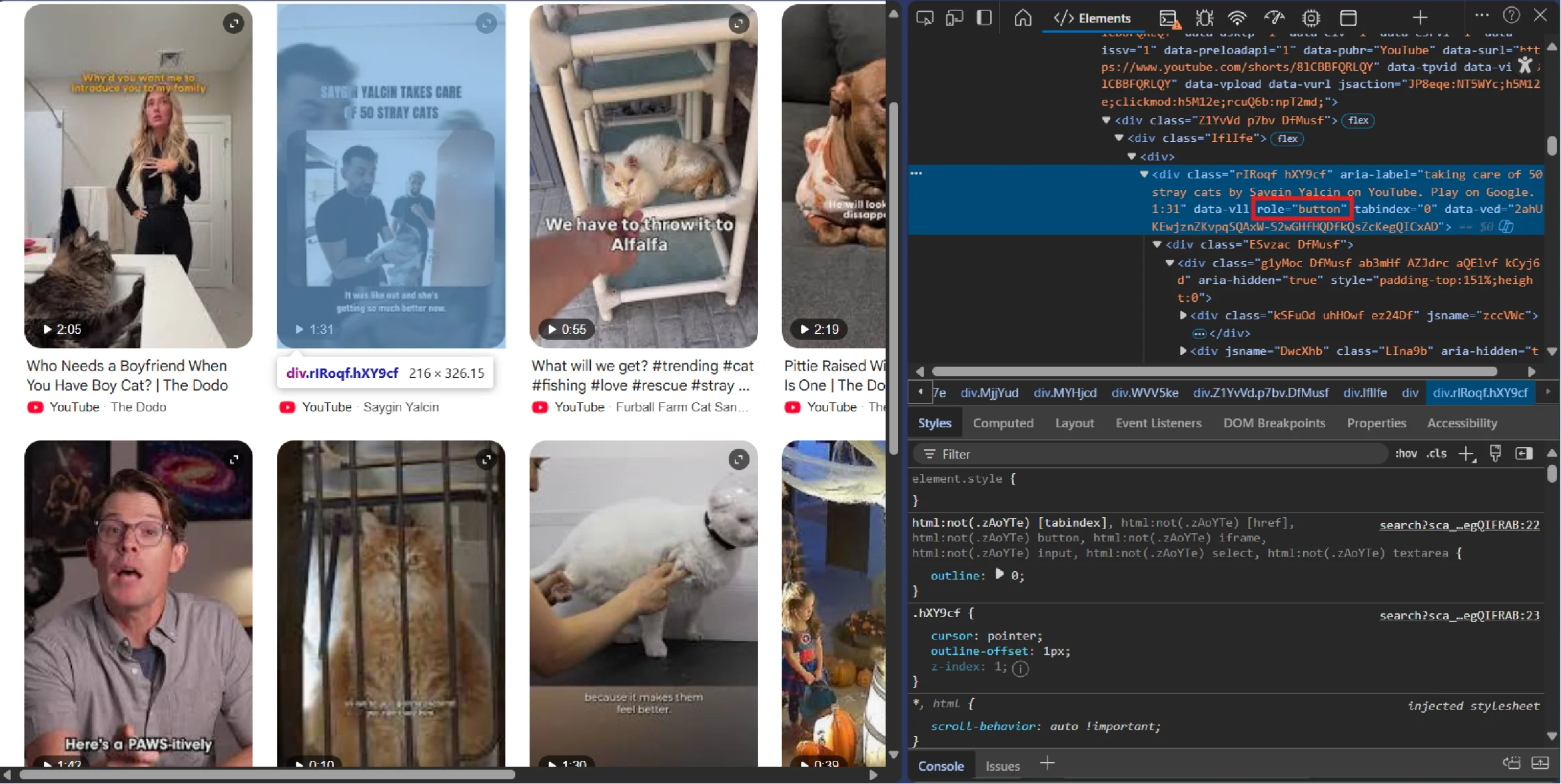
To know which attributes and elements to target, use your browser’s inspect feature.
For instance, to know about the element holding video:
- Right-click any video result in Google Search
- Select “Inspect,” locate the heading element containing the video
- Find the nested button with an aria-label attribute that contains text formatted as “<Title> by <Channel> on YouTube”.
Scrape YouTube Shorts Video Results: The Code
Here’s the complete code scrape YouTube Shorts video results if you’re in a hurry.
from playwright.sync_api import sync_playwright
import os, json
user_data_dir = os.path.join(os.getcwd(), "user_data")
if not os.path.exists(user_data_dir):
os.makedirs(user_data_dir)
with sync_playwright() as p:
user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
context = p.chromium.launch_persistent_context(
headless=False,
user_agent=user_agent,
user_data_dir=user_data_dir,
viewport={'width': 1920, 'height': 1080},
java_script_enabled=True,
locale='en-US',
timezone_id='America/New_York',
permissions=['geolocation'],
# Mask automation
bypass_csp=True,
ignore_https_errors=True,
channel="msedge",
args=[
'--disable-dev-shm-usage',
'--no-sandbox',
'--disable-setuid-sandbox',
# '--disable-gpu',
'--disable-blink-features=AutomationControlled'
]
)
page = context.new_page()
page.set_extra_http_headers({
'Accept-Language': 'en-US,en;q=0.9',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Connection': 'keep-alive'
})
search_term = 'site:youtube.com cats'
search_url = 'https://www.google.com'
page.goto(search_url)
page.wait_for_timeout(5000)
search_box = page.get_by_role('combobox', name='Search')
search_box.fill(f'{search_term}')
page.wait_for_timeout(1000)
search_box.press('Enter')
page.wait_for_timeout(3000)
short_videos_button = page.get_by_role('link', name='Short videos')
short_videos_button.click()
page.wait_for_timeout(3000)
for _ in range(5):
page.mouse.wheel(0, 300)
page.wait_for_timeout(1000)
video_div = page.get_by_role('heading', name='Short videos')
videos = video_div.get_by_role('heading').all()
video_details = []
for video in videos:
try:
description = video.get_by_role('button').get_attribute('aria-label')
title = description.split('by')[0]
channel = description.split('by')[1].split('on')[0]
url = None
descendant_div = video.locator('xpath=.//div[@data-curl]')
if descendant_div.count() > 0:
url = descendant_div.first.get_attribute('data-curl')
if url and title and channel:
video_details.append(
{
'title':title,
'channel':channel,
'url':url
}
)
except:
continue
print(f"Found {len(video_details)} YouTube short videos")
with open('scrapeShorts.json', 'w', encoding='utf-8') as f:
json.dump(video_details, f, ensure_ascii=False, indent=4)
print("Results saved to scrapeShorts.json")
Now, let’s understand this script.
The script begins by importing required libraries and setting up the environment for browser automation. The Playwright library provides the sync_playwright context manager, while os and json handle file operations.
from playwright.sync_api import sync_playwright
import os, json
The code then creates a dedicated directory to store browser user data, which maintains session state, cookies, and cache between runs. This directory prevents the script from appearing as an incognito browser instance on every execution.
user_data_dir = os.path.join(os.getcwd(), "user_data")
if not os.path.exists(user_data_dir):
os.makedirs(user_data_dir)
Next, the script initializes a Playwright context manager that controls the browser lifecycle. The sync_playwright() function returns a manager object that launches and terminates browsers.
with sync_playwright() as p:
Before launching the browser, set a custom user agent string that identifies the browser to web servers. The script uses a Chrome 120 user agent on Windows 10, which matches a common desktop browser configuration.
user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
The code then launches a browser context with a persistent profile that saves cookies and session data. The configuration includes
- Viewport dimensions
- Timezone
- Locale
context = p.chromium.launch_persistent_context(
headless=False,
user_agent=user_agent,
user_data_dir=user_data_dir,
viewport={'width': 1920, 'height': 1080},
java_script_enabled=True,
locale='en-US',
timezone_id='America/New_York',
permissions=['geolocation'],
bypass_csp=True,
ignore_https_errors=True,
channel="msedge",
args=[
'--disable-blink-features=AutomationControlled',
'--disable-dev-shm-usage',
'--no-sandbox',
'--disable-gpu',
'--disable-setuid-sandbox'
]
)In the above code:
- The headless=False parameter opens a visible browser window for debugging and monitoring
- The channel=”msedge” setting uses Microsoft Edge’s Chromium engine instead of standard Chromium.
- The command-line arguments disable features that websites use to detect automated browsers, such as the navigator.webdriver property.
Next, a new page opens within the browser context, representing a single tab where all subsequent actions occur.
page = context.new_page()
The script then sets custom HTTP headers that browsers send with every request. These headers specify accepted languages, content types, and encoding methods.
page.set_extra_http_headers({
'Accept-Language': 'en-US,en;q=0.9',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Connection': 'keep-alive'
})
The search term combines a site operator with keywords to limit results to YouTube. The site:youtube.com operator instructs Google to return only results from that domain.
search_term = 'site:youtube.com cats'
search_url = 'https://www.google.com'
The browser navigates to Google’s homepage, then waits 5000 milliseconds for the page to load completely. The timeout gives JavaScript time to render the search interface.
page.goto(search_url)
page.wait_for_timeout(5000)The script then locates the search input box using its accessibility role and name attribute. The get_by_role() method finds elements based on ARIA roles, which makes selectors more resilient to HTML structure changes.
search_box = page.get_by_role('combobox', name='Search')
search_box.fill(f'{search_term}')
After filling the search box, the script pauses for 1 second to mimic human typing speed. Then it simulates pressing the Enter key to submit the search query.
page.wait_for_timeout(1000)
search_box.press('Enter')
page.wait_for_timeout(3000)
Once Google displays search results, the script clicks the “Short videos” filter button to show only YouTube Shorts. This button appears in the search filters toolbar below the search box.
short_videos_button = page.get_by_role('link', name='Short videos')
short_videos_button.click()
page.wait_for_timeout(3000)
The search results use lazy loading, meaning you need to scroll to get more results. The code runs a loop 5 times, scrolling down 300 pixels each iteration with 1-second pauses between scrolls.
for _ in range(5):
page.mouse.wheel(0, 300)
page.wait_for_timeout(1000)
Then the script locates the main “Short videos” section by finding the heading element with that specific text. This heading marks the container that holds all video results.
video_div = page.get_by_role('heading', name='Short videos')
Within this section, the code finds all nested heading elements that represent individual video entries. Each video displays as a heading containing the video’s metadata.
videos = video_div.get_by_role('heading').all()
Before extracting the video data, define an empty list to store the extracted data as dictionaries. Each dictionary will contain a title, channel name, and URL for one video.
video_details = []
The code uses a loop to iterate through each video heading, wrapping operations in a try-except block to handle parsing failures. This prevents one malformed video from stopping the entire scraping process.
for video in videos:
try:
Next, the code locates a button element within the video heading and reads its aria-label attribute. This attribute contains formatted text that describes the video for screen readers.
description = video.get_by_role('button').get_attribute('aria-label')
The code then uses a series of string splitting operations to parse the aria-label text to extract the video title. The split operation at “by” returns everything before the channel name.
title = description.split('by')[0]
A second split operation extracts the channel name. The code splits at “by” to get everything after it, then splits the result at “on” to remove trailing YouTube platform text.
channel = description.split('by')[1].split('on')[0]
The script then initializes a URL variable as None, which will store the video link if found.
url = None
An XPath expression locates any descendant div element that contains a data-curl attribute. This attribute holds the actual YouTube URL that users visit when clicking the video.
descendant_div = video.locator('xpath=.//div[@data-curl]')
The code also checks if any matching div elements exist. If found, it extracts the data-curl attribute value from the first matching element.
if descendant_div.count() > 0:
url = descendant_div.first.get_attribute('data-curl')
The conditional statement verifies that all three data points exist before adding the video to the results. Videos missing any field get excluded from the output.
if url and title and channel:
video_details.append(
{
'title':title,
'channel':channel,
'url':url
}
)
Finally, the script saves the collected data to a JSON file with UTF-8 encoding. The indent=4 parameter formats the JSON with readable indentation, while ensure_ascii=False preserves special characters.
with open('scrapeShorts.json', 'w', encoding='utf-8') as f:
json.dump(video_details, f, ensure_ascii=False, indent=4)
print("Results saved to scrapeShorts.json")
Code Limitations
Although, the code shows a basic SERP scraping for YouTube shorts, it has a few limitations:
- The get_by_role() selectors depend on Google maintaining consistent ARIA labels and role attributes. Changes to Google’s HTML structure break the heading detection, button location, or Short videos filter identification.
- The code does not have any techniques to handle anti-scraping measures, which is necessary for large-scale products.
Wrapping Up: Why You Need a Web Scraping Service
While this tutorial shows how to scrape shorts from SERP, if you want production-grade data extraction, you need infrastructure that can handle
- Google’s search algorithms changes
- Detection systems that flag patterns like fixed timeouts, identical user agents, and repetitive scroll behavior
- Multiple headless browsers running at the same time
A web scraping service like ScrapeHero can handle all these technicalities.
ScrapeHero is an enterprise-grade web scraping service. We can deliver clean, structured JSON or CSV data at scale while monitoring for scraping failures.
Contact ScrapeHero to get data without any hassle, so that you can focus more on your business.
FAQ
The get_by_role(‘heading’, name=’Short videos’) selector depends on Google displaying this exact heading text, which might have changed. You need to update the code accordingly.
The filtering condition if url and title and channel eliminates all results when any field extraction fails. Check each extraction step independently by printing values before the conditional: add print(f”Title: {title}, Channel: {channel}, URL: {url}”) after the parsing section. The most common cause is that Google changed the HTML structure, requiring you to determine new selectors.



