

Honeypots can lure cyberattackers, but they may also make web scraping challenging. They act as decoys and are only visible to bots. Therefore, web scrapers can also fall prey to honeypots unless you program measures to avoid honeypot traps in your scraping scripts.
This article discusses honeypots, their types, and how to avoid them.
Understanding Honeypots
 Honeypot traps in web scraping are deceptive elements; humans can’t see them, but scrapers can. Scrapers may extract misleading data or trigger anti-scraping measures upon interacting with honeypots.
Honeypot traps in web scraping are deceptive elements; humans can’t see them, but scrapers can. Scrapers may extract misleading data or trigger anti-scraping measures upon interacting with honeypots.
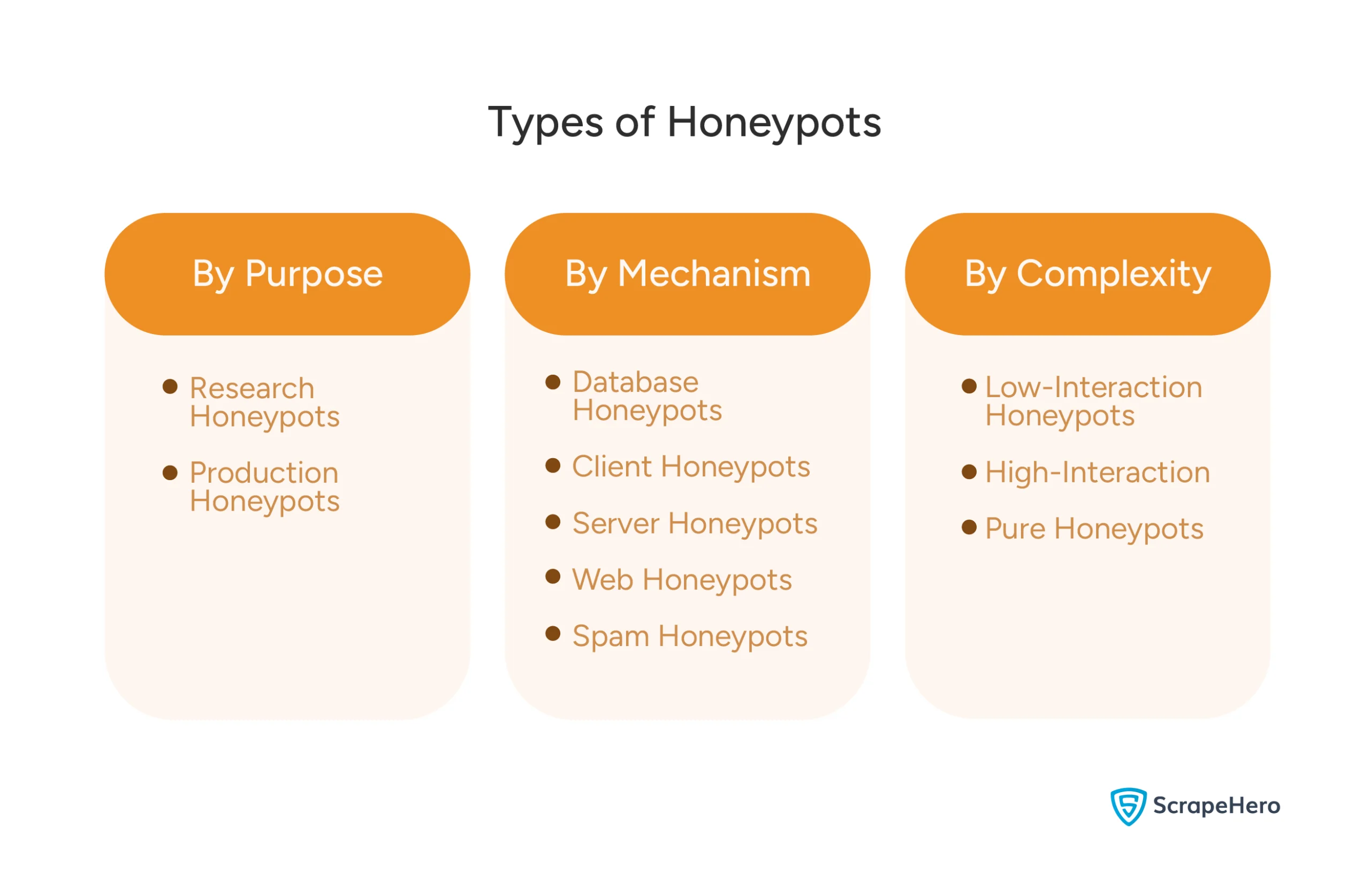
You can classify honeypots based on
- Purpose
- Mechanism
- Complexity
By Purpose
- Research Honeypots: These aim to get extensive data on attacker behavior, making them complex and expensive to set up.
- Production Honeypots: Focused on detecting specific bot types, these are simpler, more cost-effective, and goal-oriented.
By Mechanism
- Database Honeypots: Mimic vulnerable databases to attract attacks like SQL injections.
- Client Honeypots: Pose as clients to identify malicious servers targeting users.
- Server Honeypots: Emulate general-purpose servers with exploitable vulnerabilities.
- Web Honeypots: Simulate specific web applications or websites.
- Spam Honeypots: Disguise as open mail relays to capture spammers’ IP addresses when they attempt to use the service.
By Complexity
- Low-Interaction Honeypots: Emulate limited services, making them easy and inexpensive to deploy but less effective against sophisticated bots that may detect deception.
- High-Interaction Honeypots: Mimic full production systems, often on virtual machines, offering more services to appear legitimate and harder to detect.
- Pure Honeypots: Fully functional production servers with mock data; convincing but also the most costly to maintain.
Strategies to Avoid Honeypot Traps in Web Scraping
To scrape effectively, you must navigate honeypots carefully. Consider these techniques to detect and avoid honeypot traps:
- Detecting Invisible Elements
- Validating URLs
Detecting Invisible Elements
Honeypots often use elements invisible to humans, such as those with display: none or text colored to match the background. You can detect these using Python.
Begin by importing Selenium and re.
from selenium import webdriver
from selenium.webdriver.common.by import By
import re
The code uses Selenium for web scraping. You can use Python requests instead of Selenium if the site doesn’t use JavaScript to generate elements.
You need the re module to use RegEx for detecting numbers from an RGB string.
Next, define a function rgb_to_tuple() that takes an RGB string and converts it to a tuple. It becomes more convenient to compare two colors after the conversion.
def rgb_to_tuple(rgb_string):
"""Convert RGB string to tuple of integers"""
if not rgb_string or rgb_string == 'rgba(0, 0, 0, 0)':
return None
# Handle rgba and rgb formats
print(rgb_string)
numbers = re.findall(r'd+', rgb_string)
print(numbers)
if len(numbers) >= 3:
return (int(numbers[0]), int(numbers[1]), int(numbers[2]))
return None
This code uses the re module’s findall() method to extract the numbers from the RGB string. Then, it puts those numbers into a tuple and returns the tuple.
Now, create another function, compare_colors(), that takes two color tuples and returns True if the difference between the colors is less than 10. Otherwise, the function returns False.
def compare_colors(color1, color2, threshold=10):
"""Check if two RGB colors are similar within a threshold"""
if not color1 or not color2:
return False
# Calculate the difference between each RGB component
diff = sum(abs(a - b) for a, b in zip(color1, color2))
return diff <= threshold
You can now
- Launch Selenium
- Navigate to the target website
- Detect the hidden elements
You can launch Selenium using webdriver.Chrome() and navigate using get().
driver = webdriver.Chrome()
driver.get("https://example.com")To detect hidden elements, check for the elements with
- The attribute “style=’display:none’”
- Identical text and background colors
Check for the “display:none” attribute using Selenium’s find_element method.
hidden_elements = driver.find_elements(By.CSS_SELECTOR, "[style*='display: none']")Compare text and background colors using the functions rgb_to_tuple and compare_colors. Start by extracting all the elements.
all_elements = driver.find_elements(By.CSS_SELECTOR, "*")
Then, iterate through the extracted elements, and in each iteration:
1. Check if the element holds the text and skip the iteration if it doesn’t
if not element.text.strip():
continue
2. Get the text color
text_color = driver.execute_script(
"return window.getComputedStyle(arguments[0]).color;", element
)3. Get the background color
bg_color = driver.execute_script(
"return window.getComputedStyle(arguments[0]).backgroundColor;", element
)
4. Use rgb_to_tuple() to convert the extracted RGB strings to tuples.
text_rgb = rgb_to_tuple(text_color)
bg_rgb = rgb_to_tuple(bg_color)
5. Call compare_colors() with the tuples as the argument.
if compare_colors(text_rgb, bg_rgb):
print(f" The text: '{element.text[:50] if len(element.text) > 50 else element.text}...' seems to be hidden")
print()Here’s the complete code:
from selenium import webdriver
from selenium.webdriver.common.by import By
import re
def rgb_to_tuple(rgb_string):
"""Convert RGB string to tuple of integers"""
if not rgb_string or rgb_string == 'rgba(0, 0, 0, 0)':
return None
# Handle rgba and rgb formats
print(rgb_string)
numbers = re.findall(r'd+', rgb_string)
print(numbers)
if len(numbers) >= 3:
return (int(numbers[0]), int(numbers[1]), int(numbers[2]))
return None
def compare_colors(color1, color2, threshold=10):
"""Check if two RGB colors are similar within a threshold"""
if not color1 or not color2:
return False
# Calculate the difference between each RGB component
diff = sum(abs(a - b) for a, b in zip(color1, color2))
return diff <= threshold driver = webdriver.Chrome() driver.get("https://example.com") # Check for elements with display: none hidden_elements = driver.find_elements(By.CSS_SELECTOR, "[style*='display: none']") # Check for elements with matching text and background colors all_elements = driver.find_elements(By.CSS_SELECTOR, "*") print("=== HIDDEN BY DISPLAY: NONE ===") for element in hidden_elements: print("Invisible element found:", element.get_attribute("outerHTML")[:100] + "...") print("n=== HIDDEN BY COLOR MATCHING ===") for element in all_elements: # Skip elements without text content if not element.text.strip(): continue try: # Get computed styles text_color = driver.execute_script( "return window.getComputedStyle(arguments[0]).color;", element ) bg_color = driver.execute_script( "return window.getComputedStyle(arguments[0]).backgroundColor;", element ) # Convert colors to RGB tuples text_rgb = rgb_to_tuple(text_color) bg_rgb = rgb_to_tuple(bg_color) # Check if colors are similar (potentially hidden text) if compare_colors(text_rgb, bg_rgb): print(f" The text: '{element.text[:50] if len(element.text) > 50 else element.text}...' seems to be hidden")
print()
except Exception as e:
# Skip elements that can't be processed
continue
driver.quit()
Validating URLs
Honeypots may also appear as invalid URLs in the robots.txt file, an area scrapers often check. To verify URLs, you can:
- Search the URLs in the website’s search bar or Google.
- Access them with a lightweight dummy scraper to test their legitimacy.
Best Practices for Ethical Web Scraping
To minimize risks and ensure compliance, follow these guidelines:
- Verify Site Authenticity: Ensure the website itself isn’t a honeypot by checking its legitimacy.
- Avoid Open Wi-Fi: Unencrypted open Wi-Fi networks expose your scraper to interception and security risks.
- Respect Terms of Service and robots.txt: Adhere to the website’s rules to avoid legal or ethical violations.
- Scrape Responsibly: Only extract necessary data and introduce delays (e.g., 1-2 seconds between requests) to avoid overwhelming servers.
- Use Ethical Proxy Services: Choose reputable proxy providers to maintain anonymity and comply with scraping best practices.
Wrapping Up
Avoiding honeypot traps requires carefully configuring your scraper, which consumes a significant amount of time and effort. Moreover, you might need to perform numerous trials to determine whether or not a site uses a honeypot.
For those who primarily want to perform data analysis, professional web scraping services can offer a hassle-free solution. A web scraping service like ScrapeHero can handle all the technical aspects of the extraction process, including avoiding honeypot traps.
ScrapeHero is an enterprise-grade web scraping service, and we can extract data for you. Contact ScrapeHero to stop worrying about data collection and focus on what matters most.


