

WebSockets provide an efficient way to get real-time data streams. That means scraping data from WebSockets allows you to track cryptocurrency prices, stock prices, and live event updates. This guide discusses scraping real-time data from WebSockets using Python.
Getting the WebSocket Endpoint
Before you start scraping real-time data from WebSockets, the first step is to locate the WebSocket URL.
You can get it using your browser’s developer tools:
- Open the Network tab in the developer tools
- Filter for WS (WebSocket) traffic
- Reload the page to capture the WebSocket connection
- Look for the WebSocket URL starting with wss:// and copy it
In this tutorial, the code scrapes from a WebSocket used by CryptoCompare.com. This WebSocket requires you to send a subscription message containing the names of Cryptocurrencies for which you need real-time updates.
You can find this subscription message in the response section.

Installing the Required Libraries
Now that you have the WebSocket URL and subscription message, install the necessary Python libraries to prepare the environment for scraping live data from WebSockets.
You need to install the websocket-client library to interact with WebSocket servers; install it using Python’s package manager pip.
pip install websocket-clientEstablishing the WebSocket Connection
The first part of the code for extracting real-time WebSocket data involves establishing the connection using the URL you copied earlier.
You also need to define the headers, which simulate a browser connection.
from websocket import create_connection
import json
# WebSocket URL (replace with the URL you copied)
websocket_url = "wss://streamer.cryptocompare.com/v2?format=streamer"
# Define the headers for the WebSocket connection
headers = json.dumps({
"Host": "streamer.cryptocompare.com",
"User-Agent": "Mozilla/5.0...",
"Accept": "*/*",
"Sec-WebSocket-Version": "13",
"Upgrade": "websocket"
})
# Create the WebSocket connection
ws = create_connection(websocket_url, headers=headers)
This code snippet:
1. Initializes two variables:
- websocket_url: This is the WebSocket endpoint that you copied from your browser’s developer tools.
- headers: The headers are necessary to simulate a real browser connection, allowing the WebSocket server to accept the connection.
2. Establishes a connection to the WebSocket URL
Sending the Subscription Message
Once you’ve established the connection, send the required subscription message. This message tells the server what you want.
# Send the subscription message to the WebSocket server
ws.send(json.dumps({
"action": "SubAdd",
"subs": [
"5~CCCAGG~BTC~USD",
"5~CCCAGG~ETH~USD",
"5~CCCAGG~SOL~USD"
]
}))
In this code snippet:
- create_connection(websocket_url, headers) establishes the connection to the WebSocket server.
- ws.send() sends the subscription message to the server. This message subscribes to real-time prices for Bitcoin (BTC), Ethereum (ETH), and Solana (SOL) prices in USD.

Receiving and Processing Data
Now that you’re connected and subscribed to the data stream, you need to listen for incoming messages. Each message will contain updates, such as the latest price for the subscribed currencies.
Receive the incoming messages and process them to extract the relevant data.
previous_price= 0
with open('CryptoPrices.csv', 'w') as f:
f.write('Currency,Price(USD)\n')
while True:
try:
# Receive the WebSocket message
message = ws.recv()
# Split the message into components
items = message.split('~')
price_raw = items[5] # Price is at index 5
currency = items[2] # Currency is at index 2
# Convert price to float and round it
price = round(float(price_raw), 2)
# Write to CSV if the price has changed
if previous_price!= price and price != 0:
with open('CryptoPrices.csv', 'a') as f:
f.write(f"{currency},{price}\n")
previous_price = price
except IndexError:
pass
except ValueError:
pass
except Exception as e:
print(e)
break
This code:
- Getting the Message: ws.recv() waits for a message from the WebSocket server. Once a message is received, it’s processed.
- Splitting the message: Each WebSocket message contains multiple pieces of data separated by ~. The code splits the message to extract the relevant parts (e.g., price, currency).
- Price extraction: The price is located at index 5 in the message, and the currency is at index 2. The code converts the price to a float and round it to two decimal places.
- CSV writing: If the price has changed, the code writes it to a CSV file for later analysis.
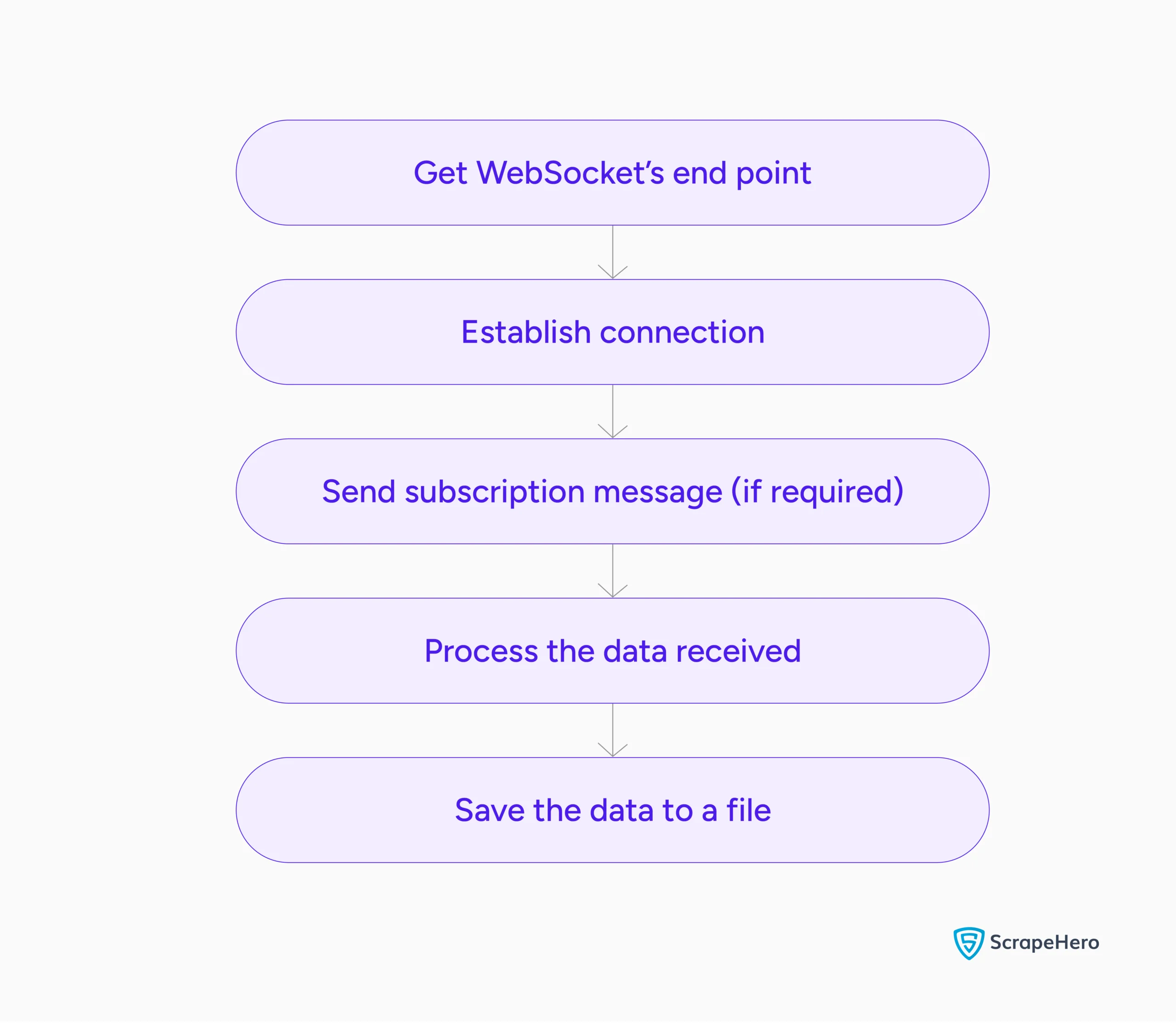
Here’s a flowchart showing the entire process:
Handling Errors and Reconnection
WebSocket connections can sometimes drop, either due to network issues or server problems. To ensure your script keeps running while scraping data from WebSockets, you should implement automatic reconnection in case the connection fails.
Implement a function that automatically reconnects the WebSocket if the connection is lost.
import time
def connect():
while True:
try:
ws = create_connection(websocket_url, headers=headers)
print("Connected to WebSocket")
return ws
except Exception as e:
print(f"Connection failed: {e}. Retrying in 5 seconds...")
time.sleep(5)
ws = connect()
while True:
try:
message = ws.recv()
# Process the message...
except Exception as e:
print(f"Error: {e}. Reconnecting...")
ws.close()
ws = connect()This code:
- Initial Connection: This connect() tries to establish a WebSocket connection. If the connection fails, it waits 5 seconds before retrying.
- Reconnection: If the WebSocket connection drops, the script catches the error, closes the current connection, and calls connect() to re-establish the connection.
Code Limitation
While the provided code works for many real-time data scraping tasks, there are a few limitations:
- Rate Limits: WebSocket servers may limit the number of requests or subscriptions. Be aware of these limits to avoid being blocked.
- Data Volume: High-frequency data streams can result in large amounts of incoming data. Ensure your script can handle the volume efficiently.
- Connection Stability: WebSocket connections can drop due to network issues. Implementing reconnection logic can mitigate this issue.
- Message Format Changes: The structure of incoming data can change. If the WebSocket server updates the message format, you’ll need to modify your data parsing code.
Wrapping Up: Why Use a Web Scraping Service
Scraping real-time data from WebSockets involves establishing a connection to the WebSocket server, subscribing to data streams, and processing the incoming data to store it in a CSV file.
However, keep in mind the limitations, such as data volume handling, connection stability, and rate limits. If you’re dealing with larger-scale scraping or facing connection issues, it might be time-consuming to handle everything manually.
For more complex scraping tasks, a web scraping service like ScrapeHero can help automate the process, scale your scraping efforts, and handle WebSocket connections efficiently.
ScrapeHero is an enterprise-grade web scraping service. We can take care of the heavy lifting, allowing you to focus on analyzing the data.


