

Server-Sent Events (SSE) allow servers to send real-time data to clients over an established HTTP connection. Therefore, you can use them for scraping real-time data streams. Not sure how to get started? Read on.
This tutorial discusses how to scrape data from SSE in Python and JavaScript.
How to Scrape from SSEs
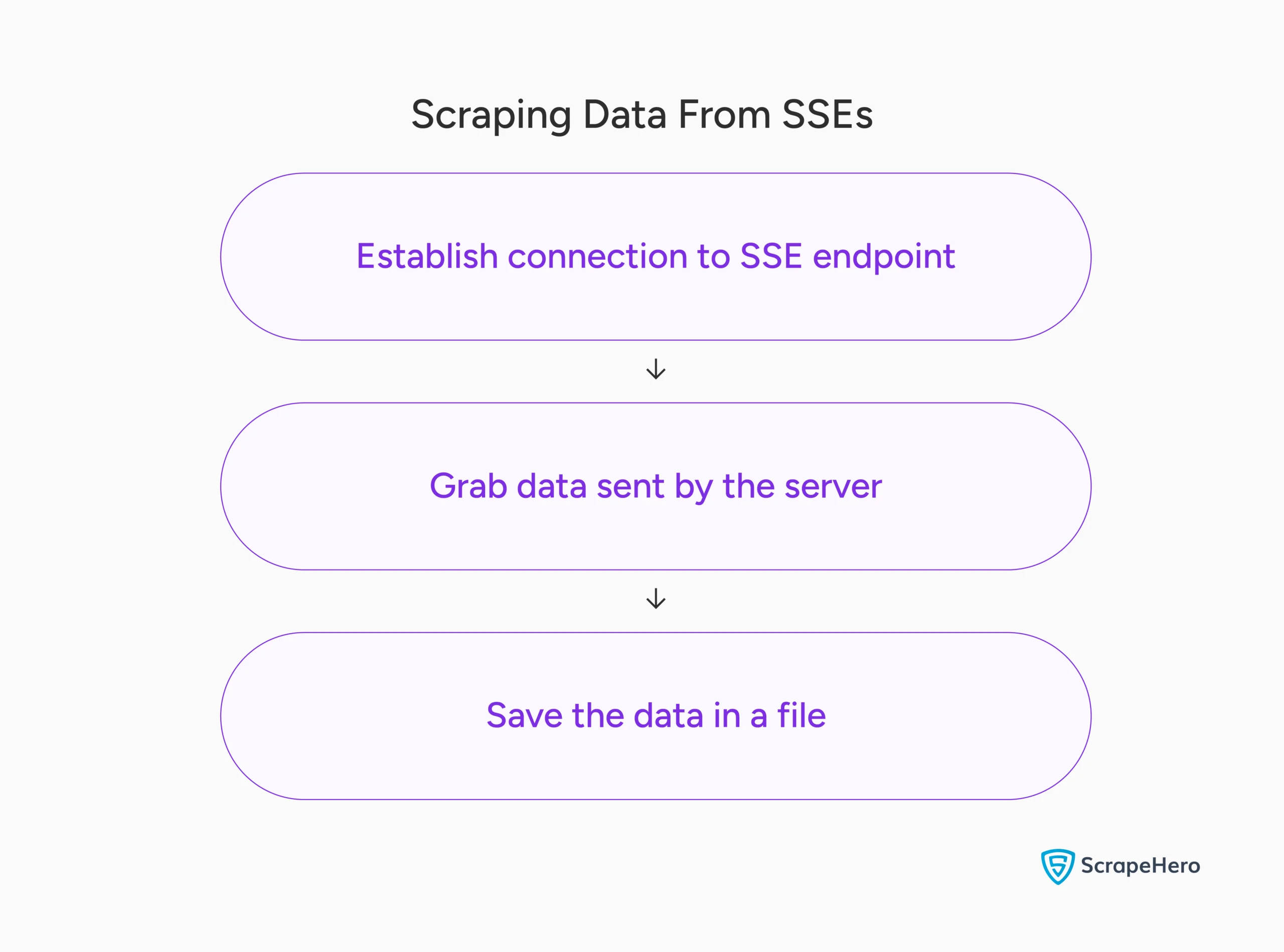
SSEs are unidirectional. Once the client establishes a connection to the SSE endpoint, the client can’t send data to the server. However, the server can send data using the same connection without the client specifically requesting it.
So you need an endpoint for SSEs to work, and scraping live data streams from SSEs starts with locating this endpoint.
After that, you can establish an HTTP connection to that endpoint using a GET request and extract data from the events sent by the server.
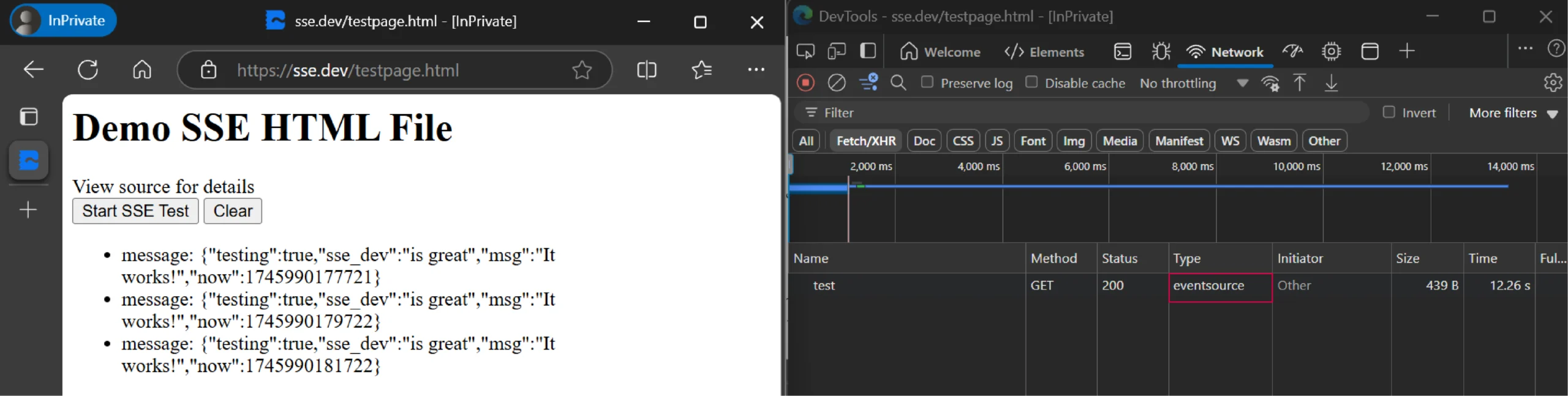
To find the SSE endpoint:
- Go to the target web page
- Open developer tools (right-click anywhere and select ‘Inspect’)
- Select ‘Network’ tab and filter by ‘Fetch/XHR’
- Look for and copy the URL of the GET request with the type ‘eventsource’
Here’s a demo HTML page that uses server-sent events.
Besides using the endpoint directly, you can also extract data from the HTML page. However, this requires you to use a headless browser, which is more resource-intensive. This article on scraping Google’s dynamic search results discusses how to use headless browsers for real-time data scraping.
Scraping Real-Time Data Streams Using JavaScript
In JavaScript, you need to install a module named eventsource to parse data from SSE. You can install it using the node package manager (npm).
After installing the necessary packages, you can start writing code.
Start by importing the EventSource class and the fs module. While the EventSource class enables you to extract SSE data, the fs module allows you to save the extracted data to a file.
const EventSource = require('eventsource').EventSource;
const fs = require('fs')The code shown in this tutorial uses two functions:
- scrape_sse(): Extracts data from an SSE endpoint.
- writeToFile(): Writes the extracted data to a JSON lines file.
scrape_sse()
This function accepts a URL and uses it to create an object of the EventSource class.
const source = new EventSource(url);This object contains methods to grab the data from the SSE endpoint. But first define a variable to store the data.
let data;Next, use the onmessage() method to extract and save the data to a file.
source.onmessage = (event) => {
const time = new Date().toTimeString().split(' ')[0];
data = {[JSON.parse(event.data).msg]: time};
writeToFile(data)
};The above code:
- Builds a dict with the message as the key and the current time as the value
- Calls writeToFile() to save the extracted data to a JSON lines file.
writeToFile()
This function accepts the extracted data as a dict and saves it in a JSON lines file. The code uses fs.appendFileSync() to do so.
function writeToFile(data) {
const logEntry = JSON.stringify(data) + '\n';
fs.appendFileSync('output.jsonl', logEntry, 'utf8');
}After defining the function, you can call scrape_sse() with a URL as the argument.
if(require.main === module) {
scrapeSse('https://sse.dev/test?interval=1');
process.on('SIGINT', () => {
console.log('Streaming stopped');
process.exit();
});
}
Here’s the complete code:
const EventSource = require('eventsource').EventSource;
const fs = require('fs')
function writeToFile(data) {
const logEntry = JSON.stringify(data) + '\n';
fs.appendFileSync('output.jsonl', logEntry, 'utf8');
}
function scrapeSse(url) {
const source = new EventSource(url);
let data;
source.onmessage = (event) => {
const time = new Date().toTimeString().split(' ')[0];
data = {[JSON.parse(event.data).msg]: time};
writeToFile(data)
};
source.onerror = (error) => {
console.error('SSE error:', error);
};
}
if(require.main === module) {
scrapeSse('https://sse.dev/test?interval=1');
process.on('SIGINT', () => {
console.log('Streaming stopped');
process.exit();
});
}

Scraping Real-Time Data Streams Using Python
In Python, you need two modules: sseclient and requests. You can install both of them using PIP.
The requests library connects with the data stream and the sseclient parses the data sent by the server.
Besides these, you’ll also need the json module to save the extracted data in a JSON file.
Start your code to scrape real-time data streams by importing the packages mentioned above.
import sseclient
import requests
from datetime import datetime
import jsonNext, create two functions:
- scrape_sse(): Extracts data from server-sent events
- save_data(): Saves the extracted data
scrape_sse()
This function
- Accepts a URL
- Extracts data from an SSE endpoint
- Saves the data
Begin the function by using Python requests to connect to the SSE endpoint.
headers = {"Accept": "text/event-stream"}
response = requests.get(url, stream=True, headers=headers)Then, pass the response to the class SSEClient, which creates an object.
client = sseclient.SSEClient(response)The created object has a method events() that returns a generator. You can use this generator to process the events sent by the server and extract the required data.
for event in client.events():
date_time = datetime.now()
current_time = str(date_time).split()[1].split('.')[0]
data = json.loads(event.data)
print(data)
string_data = json.dumps({current_time:data['msg']})
save_data(string_data)
The above code:
- Gets the current time
- Extracts the data from the SSE
- Saves it in a JSON file by calling save_data
save_data()
This function accepts the extracted data and saves it in a JSON Lines file.
def save_data(data):
with open("data.jsonl", "a", encoding="utf-8") as f:
f.write(data + "\n")
You can now call scrape_sse() with a URL as the argument.
try:
scrape_sse("https://sse.dev/test")
except KeyboardInterrupt:
print("Streaming has been stopped")
Code Limitations
Although you can use the code shown in this tutorial to scrape data from a real website:
- You need to find the correct SSE endpoint, which can be challenging.
- The structure returned by the endpoint can change, breaking your code; you need to alter your code whenever that happens.
Want a no-hassle solution for gathering real-time data? Try ScrapeHero’s web scraping API.
Wrapping Up: Why Use a Web Scraping Service
You can scrape data from Server-Sent Events using packages like sseclient (Python) or eventsource (JavaScript), provided you have the SSE endpoint.
However, finding the SSE endpoint can be tedious. Moreover, you must monitor the changes to the endpoint yourself. If you want to avoid all this work, consider using a web scraping service.
A web scraping service like ScrapeHero can gather real-time data despite technical hurdles. Their experts can build enterprise-grade web scrapers capable of pulling high-quality data. You can then focus on analyzing the real-time data without worrying about extracting it.


